1 基础语法
1.1 常量与变量
常量:一般使用 static final 修饰 ,引用名称为英文大写如:public static final String SUNDAY = “SUNDAY”。变量:在其作用域(一对花括号)内可以发生改变的量称为变量。
1.2 数据类型
1.2.1 数据类型分类
数据类型分为基本类型和引用类型。 基本类型分为如下表格,引用类型分为数组 、类、接口。
| 基本类型 | boolean | byte | char | short | Int | long | float | double | void |
|---|---|---|---|---|---|---|---|---|---|
| 二进制位数 | 1 | 8 | 16 | 16 | 32 | 64 | 32 | 64 | — |
| 封装器类 | Boolean | Byte | Character | Short | Integer | Long | Float | Double | Void |
1.2.2 类型转换
自动类型转换:小的类型向大的类型提升,byte、short、char 运算时直接提升为 int 。强制类型转换:大的类型向小的类型提升,如 int a =(int)100L
byte b1 = 10;byte b2 = 11;byte b3 = b1 + b2 //错误,byte运算自动转换成int,int赋给一个byte要强制转换byte b3 = (byte)(b1 + b2); //正确,short s1 = 1;s1 = s1 + 1; //错误,short运算自动转换成int,short赋给一个short要强制转换short s2 = 1;s2 += 1; // 等同于short s2 = (short)(s2 + (short)1); //正确
1.2.3 包装类相关
//自动装箱
Integer total = 99;
//自动拆箱
int totalprim = total;
Interger 类型引用[-128,127]区间中是指向常量池中的,超过该范围才会创建对象。
parseXXX()方法可以把字符串转成基本类型,String类的vauleof()方法基本类型转换成字符串类型。
1.2.4 数组
数组的长度是固定的,不能改变,数组存储的类型必须是设置的存储类型,定义一个数组如下
int[] arr1 =new int[]{1,2,3};//确定内容使用静态初始化,new int[]可以省略
int[] arr2 = new int[3];//不清楚内容使用动态初始化,这时如果不赋值直接取出里面的元素,int类型默认为0
1.3 作用域和权限
| 权限 | private | default(默认) | protected | public |
|---|---|---|---|---|
| 作用域 | 本类 | 本类、子类 | 本类,子类,本包 | 无 |
1.4 运算符
1.4.1 算数运算符
算术运算符用在数学表达式中,它们的作用和在数学中的作用一样分为+,-,*,/,%,++,—
(自增/自减(/—):前变量先+1,再使用(变量+1)运算;后++,直接使用变量运算,之后变量再+1;
1.4.2 关系运算符
关系运算符主要是用来比较两个值的关系,有 == , != , >= , <= , < , >
1.4.3 位运算符
1.4.4 逻辑运算符
逻辑运算符主要是用来做判断
| 名称 | 作用 |
|---|---|
| && | 两边为true,返回true |
| || | 两边一个为true 返回true |
| ! | 为true返回false , 为false返回true |
1.4.5 赋值运算符
赋值运算符是用来赋值的主要有:+= , -= ,*= ,/= ,= 等。
a+ = 1 相当于 a=a+1,但是留意a的类型,+=不改变运算类型;
1.4.6 三元运算符
判断语句 ? 如果真那莫执行这段 : 如果假执行这段 ;
1.5 流程控制语句
1.5.1 if语句
if、if..else、if..else if..else,尽量少的使用
1.5.2 switch语句
case后面的值不可以重复;
swtich后面的数据类型只能是byte/short/char/int 或者是String字符串、enum枚举;
匹配到相应case的case就会往下执行直到break结束(case2没有break就会执行case3到case3的break结束)。
1.5.3 循环语句
for(已知次数使用)while(未知次数使用)do..while(至少会一次,注意最后不能遗漏分号)
1.5.4 循环控制关键字
break执行直接跳出循环;continue执行会跳过当前循环内容直接进行下一次循环;
1.6 方法
1.6.1 方法定义
方法定义在类中,且不能嵌套;
方法定义后需要调用才能执行,单独调用、打印调用、赋值调用;
一个方法的参数可以有多个,但只能有一个可变参数,可变参数必须写在参数列表的最后。
1.6.2 方法传参
方法的参数为基本类型时,传递的是数据值;为引用类型时,传递的是地址值;
1.6.3 方法重载(overload)
方法名称一样,参数不一样(只于参数的个数、类型有关,与方法的返回类型无关);
1.6.4 方法重写(override)
在继承关系中存在,方法名称一样,参数也一样;
子类的返回值必须小于等于父类的返回值;
子类的权限必须大于等于父类的权限(一般只用记住第一条,大多数情况返回值和权限都要相等)。
2 面向对象
2.1 三大特性
封装、继承、多态
2.2 类与对象
2.2.1 性质
类是属性和行为的集合,对一类事物的描述,是抽象的。如猫是一个种类。
对象是类的实例,是具体的。如一只猫。
2.2.2 类
类变量在类中,static修饰;位于方法区的静态区中;随着类的加载而诞生,随着类的消失而消失。成员变量在类中,方法外;位于堆内存中;随着对象的创建而诞生,随着对象垃圾回收而消失。局部变量在方法里;只能在方法里使用;没有默认值;位于栈内存中;随着方法进栈产生,方法出栈消失。成员方法类中声明的方法构造方法 名称与类名一致,没有返回值;通过new关键字创建对象即调用构建方法。
2.2.3 对象
通过new关键字新建对象,对象在堆中分配内存空间,使用变量指向该对象。
创建对象的4种方式:new,反射的newInstance()方法,object的clone()方法,反序列化的writeObject()方法。
Java值传递。
- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)
- 一个方法可以改变一个对象参数的状态。
-
2.2.4 关键字
this
当局部变量和成员变量重名的时候可以使用 this 指定调用成员变量;
- 通过 this 调用另一个构造方法;
- this代表当前对象,当前的这个对象调用了方法,方法里的this就代表了当前对象
super
- 在继承中,在子类的成员方法中,super.可以使用父类的成员变量和成员方法
- 在子类的构造方法中调用父类的构造方法
static
- 静态跟对象没关系,直接跟类挂钩,在类中定义了带static关键字的属性,凡是本类创建的对象都会使用,所有对象共享同一份数据。
- 直接通过类名.的形式直接调用。
- 静态不能访问非静态,因为内存中先有静态内容
- 静态中不能使用this关键之,因为this关键字代表对象
final
- 修饰类上表示该类不可被继承;
- 修饰方法上表示该方法为最终方法不能被重写;
- 修饰成员变量必须手动赋值;
- 修饰局部变量表示该局部变量不能进行更改,如果修饰的是基本类型就是值不能更改,修饰的是引用数据类型就是这个的地址值不能变更,但是里面的值可以变更。
2.3 抽象类与接口
2.3.1 抽象类(abstract)
- 不能实例化
- 不能被 final 修饰;
- 如果一个类中含有抽象方法,那么这个类必须定义成抽象类
如果这个类是抽象的,那么这个类被子类继承,抽象方法必须被重写
2.3.2 接口(interface)
不能实例化
- 一般方法使用 public abstract修饰,但可以省略不写,没有方法体
- 默认方法(为了解决接口升级,因为实现类必须实现接口里的所有抽象方法,如果接口添加了一个新的方法就会影响到所有的实现类)abstract关键改成default,并且有方法体默认方法可以被接口的实现类的对象直接调用,也可以在接口的实现类重写。
- 静态方法abstract关键改成static ,并且有方法体;直接通过接口名调用
私有方法(java9以后才能写在接口里,用于解决默认方法和静态方法代码重复的问题)格式是把默认方法和静态方法的public 改成private,只能接口自己调用,不能给实现类或者其他人使用
2.3.3 区别
抽象类是对本质的抽象,接口是对动作的抽象;
- 一个类只能继承一个抽象类,而一个类却可以实现多个接口;
抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
2.3.4 static、构造方法和父子类的调用顺序
静态代码块先执行,先执行父类然后执行子类;类中按照先后顺序执行;静态代码只会执行一次;
- 然后执行非静态代码块,先执行父类然后执行子类;类中按照先后顺序执行;
- 最后执行构造方法,先执行父类然后执行子类;非静态代码块和构造方法都会执行创建对象的次数
详解:https://www.cnblogs.com/leiqiannian/p/7922824.html
2.3.5 父子类的重名
成员变量和静态方法:编译看左边,运行还看左边;成员方法:编译看左边,运行看右边;
public class Animal{
static String name = "animal";
int num = 1;
public static void sleep() {
System.out.println("animal sleep");
}
public void run() {
System.out.println("animal run");
}
}
public class Cat extends Animal{
static String name = "cat";
int num = 2;
public static void sleep() {
System.out.println("cat sleep");
}
public void run() {
System.out.println("cat run");
}
}
public static void main(String args[]) {
Cat cat = new Cat();
Animal animal = new Cat();
System.out.println(cat.num);//2
System.out.println(animal.num);//1
System.out.println(cat.name);//cat
System.out.println(animal.name);//animal
cat.sleep();//cat sleep
animal.sleep();//animal sleep
cat.run();//cat run
animal.run();//cat run
}
2.4 内部类
2.4.1 内部类的访问规则
- 可以直接访问外部类的成员,包括私有
-
2.4.2 成员内部类
Inner当成Outer的成员存在,即一个事物包含另一个小的事物,如身体和心脏
class Outer { private int age = 20; //成员位置 class Inner { public void show() { System.out.println(age); } } } class Test { public static void main(String[] ages) { //成员内部类是非静态的演示 Outer.Inner oi = new Outer().new Inner(); oi.show(); } } //成员内部类不是静态的: 外部类名.内部类名 对象名 = new 外部类名.new 内部类名(); //成员内部类是静态的: 外部类名.内部类名 对象名 = new 外部类名.内部类名();2.4.3 静态内部类
2.4.4 局部内部类
就是定义在一个方法或者一个作用域里面的类,主要是作用域发生了变化,只能在自身所在方法和属性中被使用。
2.4.5 匿名内部类
接口的实现类或者父类的子类,只使用唯一的一次,为了简化代码。
3 集合框架

3.1 HashMap解析
3.1.1 底层结构
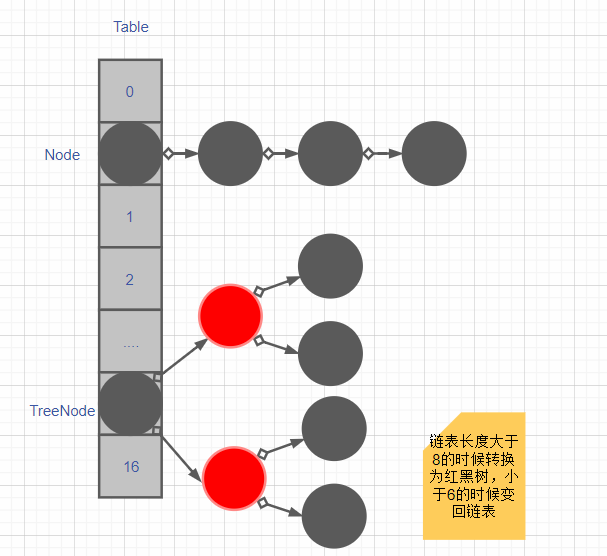
3.1.2 存储原理
- 将k,v封装到Node对象中。
- 根据key计算hash值,得到存放的数组下标。
- 判断下标节点值,为空直接插入,hash冲突则对整个链表(红黑树)进行equal比较。如果为true则进行覆盖,如果都为false则进行尾插。
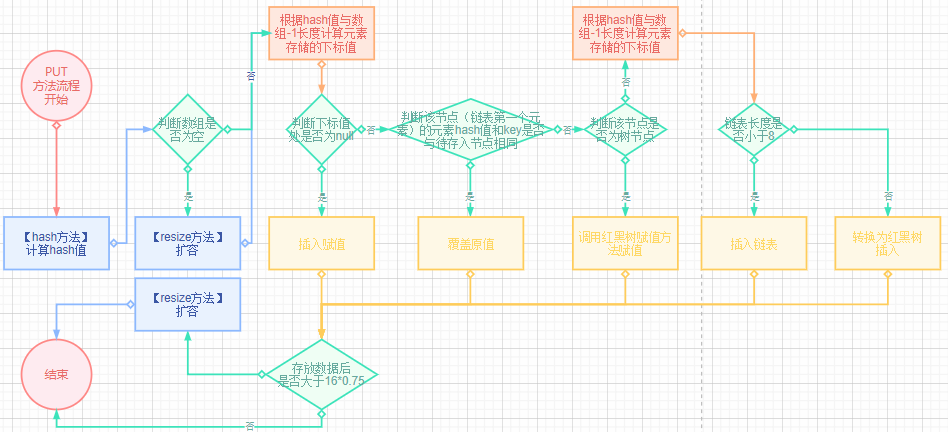
3.1.3 扩容机制
- HashMap默认初始容量为16(太小容易频繁扩容影响性能,太大浪费资源),负载因子为0.75。HashMap的容量必须为2的幂,因为底层进行按位与运算,根据hash值计算存放于哪个桶,假如不是2的幂运算的结果,就是有几个桶永远没数据。
- 当存放的元素大于16*0.75的时候自动扩容,减少hash冲突提高查询效率
3.2 ArrayList解析
3.2.1 扩容机制
- ArrayList默认初始容量为16,每次扩容大小是原来的1.5倍。
- 扩容时会创建一个新数组,将旧数组中的数据复制到新数组。
3.2.2 保证线程安全
List list = Collections.synchronizedList(new ArrayList<>());
List list = new CopyOnWriteArrayList<>();3.2.3 元素遍历与删除
不能在循环中直接使用list的remove方法否则会抛出并发修改异常。一般可以通过获取该list的迭代器,并调用其的remove方法。1.8后可以直接使用removeIf方法。
3.3 ArrayDeque解析
- 底层通过循环数组实现 三个重要属性 head tail elements,
elements存储的是双端队列,head和tail参数表示双端队列的头和尾的索引。 - ArrayDeque 作为栈使用时比 Stack 类效率要高,作为队列使用时比 LinkedList 要快。
- 常用方法比较 | 队列方法(FIFO) | 堆栈方法(FILO) | 双端队列方法 | 说明 | | —- | —- | —- | —- | | add(e) | push(e) | addLast(e)/addFirst(e) | 向队尾(栈顶)插入元素,失败抛出异常 | | offer(e) | 无 | offerLast(e) | 向队尾插入元素,失败返回false | | remove() | pop(e) | removeFirst() | 获取并删除队首(栈顶)元素,失败抛出异常 | | poll() | 无 | pollFirst() | 获取并删除队首元素,失败返回null | | peek() | peek() | peekFirst() | 获取但不删除队首(栈顶)元素,失败抛出异常 | | element() | 无 | getFirst() | 获取但不删除队首元素,失败返回null |
3.4 泛型
3.4.1 定义
泛型本质上就是对类型的参数化,在类的定义中,我们可以把类型当做参数。
- 代码复用
- 泛型中的类型在使用时指定,不需要强制类型转换(编译器会检查类型)
3.4.2 使用
//泛型类(泛型接口类似,实现类也要带着泛型) public class Generic<T>{ private T key;//key这个成员变量的类型为T,T的类型由外部指定 public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定 this.key = key; } public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定 return key; } }3.4.3 通配符
//通配符的使用方式 public void printList(List<?> list ){ 方法体;} //通配符的上限,泛型的类是上限,只能接受该类及其子类 public void printList2(List<? extend 类> list ){ 方法体;} //通配符的下限,泛型的类是下限,只能接受该类及其父类 public void printList3(List<? super 类> list ){ 方法体;}
参数类型(T)与通配符(?)的区别在于,T在声明了类型参数之后只能存储该类型数据,?则可以存放不同类型的数据。
4.常用类
4.1 Object类
常用方法
equals(Object) //equals() 只能比较引用数据类型,equals方法和==号比较引用数据类型无区别,重写后的equals方法比较的是对象中的属性。“==” 是一个比较运算符号,既可以比较基本数据类型,也可以比较引用数据类型,基本数据类型比较的是值,引用数据类型比较的是地址值.
====================================================
hashCode() //返回对象的哈希代码值,如果两个对象的哈希码值不同,那这两个对象一定不等;哈希码值相同,不能确保一定相等。
为什么重写equals()就一定要重写hashCode()?
因为程序判断对象是否位同一个对象,依靠equals()和hashCode()共同合作。
4.2 字符
4.2.1 String
String 类是不可变类,字符串”abc”一旦创建不可改变。只要采用双引号赋值字符串,那么在编译期将会放到方法区中的字符串的常量池里,多次赋值都是指向同一个字符串。如果new 创建的,则是在堆区创建。
常用方法
equals(Object obj)//比较两个字符串是否相等
contains(String str)//是否包含指定字符串
startsWith(String str)//是否以指定的字符串开头
endWith(String str)//是否以指定的字符串结尾
matches(String regex)//判断字符串是否匹配给定的正则表达式。
charAt(int index)//获取指定索引位置处的字符
indexOf(int ch)//获取指定字符第一次出现的索引值(从0开始)
substring(int start)//从指定位置开始一直截取到末尾
byte[] getBytes()//将字符串转成字节数组
concat(String str)//字符连接
4.2.2 StringBuffer 和 StringBuilder
StringBuffer线程安全、StringBuilder 线程不安全。
常用方法
append(int value)//追加。可以追加多种类型
reverse()//元素反转
4.3 数字金额
4.3.1 BigDecimal
用于解决浮点型运算精度损失的问题
常用方法
add(BigDecimal bi)// +
subtract(BigDecimal bi)// -
multiply(BigDecimal bi)// *
divide(BigDecimal bi)// /
4.3.2 DecimalFormat
数字格式化
double pi = 3.1415927;//圆周率
//取一位整数
System.out.println(new DecimalFormat("0").format(pi));//3
//取一位整数和两位小数
System.out.println(new DecimalFormat("0.00").format(pi));//3.14
//取两位整数和三位小数,整数不足部分以0填补。
System.out.println(new DecimalFormat("00.000").format(pi));// 03.142
//取所有整数部分
System.out.println(new DecimalFormat("#").format(pi));//3
//以百分比方式计数,并取两位小数
System.out.println(new DecimalFormat("#.##%").format(pi));//314.16%
System.out.println(new DecimalFormat(",###").format(pi));//千分分隔符
4.4 时间日期
4.4.1 Instant
时间戳,相当于java.util的Date
//Date与Instant的相互转化
Instant instant = Instant.now();
Date date = Date.from(instant);
Instant instant2 = date.toInstant();
4.4.2 LocalDateTime 和 ZonedDateTime
LocalDate:只包含日期,比如:2016-10-20
LocalTime:只包含时间,比如:23:12:10
LocalDateTime:包含日期和时间,比如:2016-10-20 23:14:21
ZonedDateTime:可以得到特定时区的日期/时间
4.4.3 DateTimeFormatter
时间格式化,代替SimpleDateFormat
4.5 数学计算
常用方法
Math.sqrt() : 计算平方根
Math.pow(a, b) : 计算a的b次方
Math.max( , ) : 计算最大值
Math.min( , ) : 计算最小值
Math.abs() : 取绝对值
Math.ceil(): 天花板的意思,就是逢余进一
Math.floor() : 地板的意思,就是逢余舍一
Math.round(): 四舍五入,float时返回int值,double时返回long值
5.异常

5.1 异常处理
5.1.1 抛出异常throw
throw用在方法内,用来抛出一个异常对象,将这个异常对象传递到调用者处,并结 束当前方法的执行。
5.1.2 throws声明异常
声明抛出异常throws,运用于方法声明之上,用于表示当前方法不处理异常,而是提醒该方法的调用者来处理异常
5.1.3 try catch fianlly捕获异常
try catch中来捕获异常,fianlly中不能再里面使用return关键字.
5.2 自定义异常
/**
* 自定义异常类
* 用户不存在异常信息类
*/
public class UserNotExistsException extends RuntimeException{
public UserNotExistsException() {
super();
}
public UserNotExistsException(String message) {
super(message);
}
}
6.IO
6.1 BIO
6.1.1 File
File类主要用于文件和目录的创建、文件的查找和文件的删除等。
文件路径为了兼容,要使用分隔符File.separator
操作示例
public class FileFilter {
public static void main(String[] args) {
File file = new File("E:\\Study\\练习项目");//把这个路径的文件封装成file类对象
if (file.isDirectory()) {//调用对象的方法判断是否时一个文件夹
getFiles(file);
} else {
System.out.println("请选择一个目录");
}
}
/**
递归出一个文件夹里的所有文件,并过滤掉除.jpg文件外的文件
递归必须有限定条件,而且递归次数不能过多,否则会发生栈内存溢出
**/
public static void getFiles(File dir) {
File[] files = dir.listFiles((d, name) -> new File(d, name).isDirectory() || name.toLowerCase().endsWith(".jpg"));//使用lambda表达式代替匿名内部类写过滤规则
for (File file : files) {
if (file.isDirectory()) {
getFiles(file);//使用递归
} else {
System.out.println(file.getName());
}
}
}
}
6.1.2 字节流和字符流
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象父类 | InputStream | OutputStream | Reader | Writer |
| 文件流 | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 数组流 | ByteArrayInputStream | ByteArrayOutpuStream | CharArrayReader | CharArrayWriter |
| 序列化流 | ObjectInputStream | ObjectOutputStream | - | - |
| … | … | … | … | … |
流使用的注意事项:
- 使用FileOutputStream输出内容时,默认是文件内容的覆盖操作。若要进行文件内容的追加,使用如下构造方法:public FileOutputStream(File file ,boolean append)
- 序列化流的对象必须实现Serializable接口才能序列化或反序列化,
Transient关键字修饰的成员变量不能被反序列化(静态不能反序列化) - IO操作属于资源处理,所有资源处理(IO操作,数据库操作、网络操作)在使用后一定要关闭。
6.2 NIO
6.2.1 NIO与BIO的区别
NIO 支持面向缓冲区的、基于通道的 IO 操作。NIO 比BIO更加高效。
| IO | NIO |
|---|---|
| 面向流 | 面向缓冲区 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器 |
6.2.2 缓冲区(Buffer)
NIO 中负责数据的存储。缓冲区本质就是数组。用于存储不同类型的数据,通过allocate()获取缓冲区。
(1)核心属性
capacity容量,表示缓冲区中最大存储数据的容量。一旦声明不能改变。limit界限,表示缓冲区中可以操作数据的大小。(limit后数据不能进行读写)position位置,表示缓冲区中正在操作数据的位置。mark标记,表示记录当前position位置。可以通过reset()恢复到mark的位置。
0<=mark<=position<=limit<=capacity
(2)常用方法
put():存入数据到缓冲区中
get():获取缓存区中的数据
flip():切换读取数据模式
rewind():可重复读
clear():清空缓冲区
(3)直接缓冲区与非直接缓冲区
非直接缓冲区:通过allocate()方法分配缓冲区,将缓冲区建立在JVM的内存中。
直接缓冲区:通过allocateDirect()方法分配直接缓冲区,将缓冲区建立在物理内存中。
(4)示例
public static void main(String[] args) {
//1创建缓冲区
ByteBuffer buffer=ByteBuffer.allocate(1024);
//2向缓冲区中添加内容
buffer.put("helloworld".getBytes());
//3切换为读模式
buffer.flip();
//4获取单个字节
//buffer.get();
//5获取多个字节
byte[] data=new byte[buffer.limit()];
buffer.get(data);
System.out.println(new String(data));
//6清空缓冲区
buffer.clear();
}
6.2.3 通道(Channel)
源节点和目标节点的连接,本身不存储数据与缓冲区结合使用。可以理解管道为铁轨,缓冲区为火车。
(1)常用通道
FileChannel:用于读取、写入、映射和操作文件的通道。
SocketChannel:通过 TCP 读写网络中的数据。
ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建SocketChannel。
DatagramChannel:通过 UDP 读写网络中的数据通道。
(2)获取通道的方式
//第一种,使用一个InputStream、OutputStream或RandomAccessFile来获取一个FileChannel实例。
RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
//第二种,NIO包中的FileChannel.open()方法。StandardOpenOption是一个枚举,里面有可读,可写等方法。
FileChannel inChannel = FileChannel.open(Paths.get("d:\\aaa.txt"),StandardOpenOption.READ);
(3)示例
/**
结合非直接缓冲区
**/
//1创建通道
FileChannel inChannel = FileChannel.open(Paths.get("d:\\003.jpg"),StandardOpenOption.READ);
FileChannel outChannel=FileChannel.open(Paths.get("d:\\haha.jpg"),StandardOpenOption.WRITE,StandardOpenOption.CREATE);
//2创建非直接缓冲区
ByteBuffer buffer=ByteBuffer.allocate(1024);
int len=0;
//3复制
while((len=inChannel.read(buffer))>0){
buffer.flip();
outChannel.write(buffer);
buffer.clear();
}
//4关闭
inChannel.close();
outChannel.close();
System.out.println("复制完毕");
====================================================
/**
结合直接缓冲区
**/
//1创建通道
FileChannel inChannel = new RandomAccessFile("d:\\01.wav", "r").getChannel();
FileChannel outChannel=new RandomAccessFile("d:\\02.wav", "rw").getChannel();
//2使用内存映射缓冲区(直接缓冲区)
MappedByteBuffer map = inChannel.map(MapMode.READ_ONLY, 0,inChannel.size());
outChannel.write(map);
//3关闭
inChannel.close();
outChannel.close();
System.out.println("复制完毕");
6.2.4 选择器(Selector)
Selector 可以同时监控多个 SelectableChannel 的 IO 状况,也就是说,利用 Selector可使一个单独的线程管理多个 Channel。Selector 是非阻塞 IO 的核心。
(1)使用方法
//创建选择器
Selector selector = Selector.open();
////注册Channel到Selector,使用selector必须保证channel是非阻塞的模式
channel.configureBlocking(false);
/* register的第二个参数表示对选择器对什么事件感兴趣。
- 读事件:`SelectionKey.OP_READ`,值是 1
- 写事件:`SelectionKey.OP_WRITE`,值是 4
- 连接事件:`SelectionKey.OP_CONNECT`,值是 8
- 接收事件:`SelectionKey.OP_ACCEPT`,值是 16
如果对不止一种事件感兴趣,使用或运算符即可
*/
SelectionKey key = channel.register(selector, Selectionkey.OP_READ);
(2)示例
selector允许一个单一线程监听多个channel输入。我们可以注册多个channel到selector上,然后然后用一个线程来挑出一个处于可读或者可写状态的channel
Selector selector = Selector.open(); //开启选择器
channel.configureBlocking(false); //非阻塞模式
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);//注册
while(true) {
int readyChannels = selector.select(); //选择通道
if(readyChannels == 0) continue;
Set selectedKeys = selector.selectedKeys(); //获取通道
Iterator keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove(); //需要自己移除处理完的通道
}
}
7.网络编程
7.1 网络编程三要素
7.1.1 IP
IP唯一定位一台网络上的计算机
InetAddress address = InetAddress.getByName("mac");
String hostName = address.getHostName();
String hostAddress = address.getHostAddress();
7.1.2 端口
端口表示计算机上的一个程序的进程
InetSocketAddress inetSocketAddress = new InetSocketAddress("127.0.0.1",8080);
7.1.3 传输协议
(1)TCP(打电话)
面向连接,传输数据之前需要建立连接;<br /> 通过三次握手的方式完成连接,是安全可靠协议;<br /> 传输速度慢,效率低
三次握手
- 第一次:客户端发送请求到服务器,服务器知道客户端发送,自己接收正常。SYN=1,seq=x
- 第二次:服务器发给客户端,客户端知道自己发送、接收正常,服务器接收、发送正常。ACK=1,ack=x+1,SYN=1,seq=y
- 第三次:客户端发给服务器:服务器知道客户端发送,接收正常,自己接收,发送也正常.seq=x+1,ACK=1,ack=y+1
四次挥手
- 第一次:客户端请求断开FIN,seq=u(客:我要走了)
- 第二次:服务器确认客户端的断开请求ACK,ack=u+1,seq=v(服:你要走了吗)
- 第三次:服务器请求断开FIN,seq=w,ACK,ack=u+1(服:再见)
- 第四次:客户端确认服务器的断开ACK,ack=w+1,seq=u+1(客:再见)
(2)UDP(发短信)
面向无连接,传输数据之前源端和目的端不需要建立连接;<br /> 发送数据不进行检测,所以发送不一定可靠;<br /> 传输速度快,效率高
7.2 客户端服务器实例
public static void main(String[] args) throws IOException {
//1.创建一个Serversocket对象
ServerSocket serverSocket = new ServerSocket(8888);
//2.让服务器无限等待
while (true) {
//3.使用Serversocket对象.accept()获取客户的Socket对象
Socket accept = serverSocket.accept();
//4.开启线程
new Thread(new Runnable() {
@Override
public void run() {
try {
//5.创建网络字节输入流
InputStream is = accept.getInputStream();
//6.判断文件夹是否存在
File file = new File("e:\\upload");
if (!file.exists()) {
file.mkdirs();
}
String fileName = "baozi" + System.currentTimeMillis() + new Random().nextInt(9999) + ".jpg"
//7.创建文件输出流
FileOutputStream fos = new FileOutputStream(file + "\\" + fileName);
//8.把客户端的文件写入服务器
int len;
byte[] bytes = new byte[1024];
while ((len = is.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}
//9.创建网络输出流返回结果
accept.getOutputStream().write("上传成功".getBytes());
fos.close();
accept.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
public static void main(String[] args) throws IOException {
//1.创建一个本地字节输入流
FileInputStream fis = new FileInputStream("a.txt");
//2.创建一个socket对象
Socket socket = new Socket("127.0.0.1", 8888);
//3.创建网络字节输出流(socket对象的getOutputStream()方法)
OutputStream os = socket.getOutputStream();
//4.本地输入流对象进行读取并通过网络输出流发送到服务器端
int len;
byte[] bytes = new byte[1024];
while ((len = fis.read(bytes)) != -1) {
os.write(bytes, 0, len);
}
//5.为了防止read()阻塞
socket.shutdownOutput();
//6.创建网络字节输入流(socket对象的getInputStream()方法)
InputStream is = socket.getInputStream();
//7.接受服务器端返回的数据并打印
while ((len = is.read(bytes)) != -1) {
System.out.println(new String(bytes, 0, len));
}
//8.释放资源
fis.close();
socket.close();
}public static void main(String[] args) throws IOException {
//1.创建一个本地字节输入流
FileInputStream fis = new FileInputStream("a.txt");
//2.创建一个socket对象
Socket socket = new Socket("127.0.0.1", 8888);
//3.创建网络字节输出流(socket对象的getOutputStream()方法)
OutputStream os = socket.getOutputStream();
//4.本地输入流对象进行读取并通过网络输出流发送到服务器端
int len;
byte[] bytes = new byte[1024];
while ((len = fis.read(bytes)) != -1) {
os.write(bytes, 0, len);
}
//5.为了防止read()阻塞
socket.shutdownOutput();
//6.创建网络字节输入流(socket对象的getInputStream()方法)
InputStream is = socket.getInputStream();
//7.接受服务器端返回的数据并打印
while ((len = is.read(bytes)) != -1) {
System.out.println(new String(bytes, 0, len));
}
//8.释放资源
fis.close();
socket.close();
}
8.反射和注解
8.1 反射
8.1.1 什么是反射
程序在运行期获取任意一个类或对象的所有属性和方法,并且能调用方法或改变它的属性。
8.1.2 获取类对象方法
通过类名获取:Class c1 = Student.class;
通过对象获取:Class c2 = stu.getClass();
通过全类名获取:Class c3 = Class.forName(“全限定类名”);
8.1.3 常用方法
getName():获得类的完整名字。
getFields():获得类的public类型的属性。
getDeclaredFields():获得类的所有属性。
getMethods():获得类包括父类的public类型的方法。
- invoke() 激活该方法
getDeclaredMethods():获得类的所有方法。
getMethod(String name, Class[] parameterTypes):获得类的特定方法,name参数指定方法的名字,parameterTypes参数指定方法的参数类型。
getConstrutors():获得类的public类型的构造方法。
getConstrutor(Class[] parameterTypes):获得类的特定构造方法,parameterTypes参数指定构造方法的参数类型。
- newInstance():通过类的不带参数的构造方法创建这个类的一个对象。
8.2 注解
8.2.1 使用
注解(Annotation)是Java语言用于工具处理的标注:
注解可以配置参数,没有指定配置的参数使用默认值;
如果参数名称是value,且只有一个参数,那么可以省略参数名称。
8.2.2 自定义注解
自定义注解定义
@Documented
@Inherited
@Retention(RetentionPolicy.RUNTIME) //@Retention一般设置为RUNTIME
@Target({ElementType.METHOD,ElementType.FIELD})
public @interface MyAnnotation { //1.用@interface定义注解
String name() default "jack";//2.添加参数、默认值
int age();
}
注:注解只是一种标记,如果不解析,它是不会实现任何功能的。可以通过反射获取其标注属性
结合AOP来实现逻辑
@Slf4j
@Aspect
@Component
public class MyAspect {
@Pointcut("@annotation(com.example.demo.annotation.MyAnnotation)")
public void pointcut() {}
@After("pointcut()")
public void doAfter(JoinPoint joinPoint) {
Signature signature = joinPoint.getSignature();
MethodSignature methodSignature = (MethodSignature) signature;
Method method = methodSignature.getMethod();
MyAnnotation annotation = method.getAnnotation(MyAnnotation.class);
int age = annotation.age();
final String name = annotation.name();
log.info("自定义注解的属性是age={},name={}",age,name);
}
}
9 新特性
9.1 Lambda表达式
9.1.1 Lambda格式
/* 格式 (参数列表)->{一些重写方法的代码}
():接口中抽象方法的参数列表,没有参数就空着;
-> :传递的意思,把参数传给方法体;
{} : 重写接口的抽象方法的方法体;*/
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("你好");
}
}).start();
//lambda还可以省略书写
new Thread(()->System.out.println("我不好")).start();java
9.1.2 方法引用
是用来直接访问类或者实例对象的已经存在的方法或者构造方法,是一个Lambda表达式,其中方法引用的操作符是双冒号”::”
| 类型 | 示例 |
|---|---|
| 引用静态方法 | ContainingClass::staticMethodName |
| 引用某个对象的实例方法 | containingObject::instanceMethodName |
| 引用某个类型的任意对象的实例方法 | ContainingType::methodName |
| 引用构造方法 | ClassName::new |
例如:Map.merge(),当map中不存在指定的key时,便将传入的value设置为key的值,相当于map.put(key, value);当key存在值时,执行一个方法该方法接收key的旧值和传入的value,执行自定义的方法返回最终结果设置为key的值。
9.2 函数式接口
9.2.1 格式
只定义了单抽象方法的接口称之为FunctionalInterface,用注解@FunctionalInterface标记。
9.2.2 常用的函数式接口
(1)Supplier: 供给型接口
T get(),无参数,有返回值。
Supplier<String> supplier = () -> "我要变的很有钱";
System.out.println(supplier.get());
(2)Consumer: 消费型接口
void accept(T t),接收一个参数进行消费,但无需返回结果。
andThen(Consumer after),先消费然后在消费,先执行调用andThen接口的accept方法,然后在执行andThen方法参数after中的accept方法。
Consumer<String> consumer1 = s -> System.out.print("车名:"+s.split(",")[0]);
Consumer<String> consumer2 = s -> System.out.println("-->颜色:"+s.split(",")[1]);
String[] strings = {"保时捷,白色", "法拉利,红色"};
for (String string : strings) {
consumer1.andThen(consumer2).accept(string);
//输出:车名:保时捷-->颜色:白色车名:法拉利-->颜色:红色
}
(3)Function
R apply(T t),传入一个参数,返回想要的结果。
compose(Function before),先执行compose方法参数before中的apply方法,然后将执行结果传递给调用compose函数中的apply方法在执行。
andThen(Function after),先执行调用andThen函数的apply方法,然后在将执行结果传递给andThen方法after参数中的apply方法在执行。它和compose方法整好是相反的执行顺序。
Function<Integer, Integer> function1 = e -> e * 6;
System.out.println(function1.apply(2));//12
Function<Integer, Integer> function1 = e -> e * 2;
Function<Integer, Integer> function2 = e -> e * e;
System.out.println(function1.compose(function2).apply(3));//18
System.out.println(function1.andThen(function2).apply(3));//36
(4)Predicate: 断言型接口
boolean test(T t),传入一个参数,返回一个布尔值。
and(Predicate other),相当于逻辑运算符中的&&,当两个Predicate函数的返回结果都为true时才返回true。
or(Predicate other) ,相当于逻辑运算符中的||,当两个Predicate函数的返回结果有一个为true则返回true,否则返回false
negate(),这个方法的意思就是取反。
isEqual(Object targetRef),对当前操作进行”=”操作,即取等操作,可以理解为 A == B。
使用方式:
Predicate<Integer> predicate = t -> t > 0;
System.out.println(predicate.test(1));
Predicate<String> predicate1 = s -> s.length() > 0;
Predicate<String> predicate2 = Objects::nonNull;
System.out.println( predicate1.and(predicate2).test("测试"));
System.out.println( predicate1.or(predicate2).test("测试"));
System.out.println( predicate1.negate().test("测试"));
boolean test1 = Predicate.isEqual("test").test("test");
boolean test2 = Predicate.isEqual("test").test("equal");
System.out.println(test1); //true
System.out.println(test2); //false
9.3 Stream流

9.3.1 流的特点
- stream不存储数据
- stream不改变源数据
- stream的延迟执行特性
9.3.2 创建流
```java //1.使用静态方法of() StreamintegerStream = Stream.of(“1”, “2”, “3”, “5”);
//2.通过Collection子类获取Stream
List
//3.文本文件转换获取Stream
Stream
<a name="wN5Ek"></a>
#### 9.3.3 转换流
filter
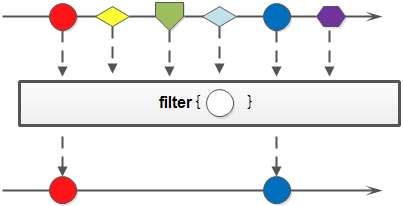
对于Stream中包含的元素使用给定的过滤函数进行过滤操作,新生成的Stream只包含符合条件的元素;
filter函数中lambda表达式为一次性使用的谓词逻辑。
如果我们的谓词逻辑需要被多处、多场景、多代码中使用,通常将它抽取出来单独定义到它所限定的主语实体中。
```java
//将下面的谓词逻辑定义在Employee实体
public static Predicate<Employee> ageGreaterThan70 = x -> x.getAge() >70;
public static Predicate<Employee> genderM = x -> x.getGender().equals("M");
List<Employee> filtered = employees.stream()
.filter(Employee.ageGreaterThan70.and(Employee.genderM))
.collect(Collectors.toList());
map

对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。
map()函数不仅可以处理数据,还可以使用mapToInt方法等转换数据的类型。如下:
List<Integer> lengths = alpha.stream()
.map(String::length)
.collect(Collectors.toList());
System.out.println(lengths); //[6, 4, 7, 5]
------------------------------------------
Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.mapToInt(String::length)
.forEach(System.out::println);//6 4 7 5
处理对象数据格式转换
public static void main(String[] args){
//省略对象创建
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
/*List<Employee> maped = employees.stream()
.map(e -> {
e.setAge(e.getAge() + 1);
e.setGender(e.getGender().equals("M")?"male":"female");
return e;
}).collect(Collectors.toList());*/
List<Employee> maped = employees.stream()
.peek(e -> {
e.setAge(e.getAge() + 1);
e.setGender(e.getGender().equals("M")?"male":"female");
}).collect(Collectors.toList());
System.out.println(maped);
}
由于map的参数e就是返回值,所以可以用peek函数。peek函数是一种特殊的map函数,当函数没有返回值或者参数就是返回值的时候可以使用peek函数。
flatMap处理二维数组及二维集合类
words.stream()
.flatMap(w -> Arrays.stream(w.split(""))) // [h,e,l,l,o,w,o,r,l,d]
.forEach(System.out::println);
distinct

对于Stream中包含的元素进行去重操作(去重逻辑依赖元素的equals方法),新生成的Stream中没有重复的元素。
limit

对一个Stream进行截断操作,获取其前N个元素,如果原Stream中包含的元素个数小于N,那就获取其所有的元素
skip

返回一个丢弃原Stream的前N个元素后剩下元素组成的新Stream,如果原Stream中包含的元素个数小于N,那么返回空Stream
Sorted
List<String> alphabeticOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted()
.collect(Collectors.toList());
默认的情况下,sorted是按照字母的自然顺序进行排序。
sorted()的参数可以接受一个Comparator排序,倒序排序就使用reversed()方法
employees.sort(Comparator.comparing(Employee::getAge).reversed());
Parallel
parallel()函数表示对管道中的元素进行并行处理,而不是串行处理。但是这样就有可能导致管道流中后面的元素先处理,前面的元素后处理,也就是元素的顺序无法保证。
串行的好处是可以保证顺序,但是通常情况下处理速度慢一些
并行的好处是对于元素的处理速度快一些(通常情况下),但是顺序无法保证。这可能会导致进行一些有状态操作的时候,最后得到的不是你想要的结果。
匹配规则函数
.stream().allMatch();//所有元素都符合某一个"匹配规则"
.stream().noneMatch();//所有元素都不符合某一个"匹配规则"
.stream().anyMatch();//是否包含某一个“匹配规则”的元素
元素收集
//收集到Array
String[] toArray = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion") .toArray(String[]::new);
==========================================================
//收集到List
List<String> collectToList = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion").collect(Collectors.toList());
==========================================================
//通用的收集,使用诸如LinkedHashSet::new和PriorityQueue::new将数据元素收集为其他的集合类型
LinkedList<String> collectToCollection = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
).collect(Collectors.toCollection(LinkedList::new));
===========================================================
//收集到Map
//使用Collectors.toMap()方法将数据元素收集到Map里面,但是出现一个问题:那就是管道中的元素是作为key,还是作为value。我们用到了一个Function.identity()方法,该方法很简单就是返回一个“ t -> t ”(输入就是输出的lambda表达式)。另外使用管道流处理函数distinct()来确保Map键值的唯一性。
Map<String, Integer> toMap = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.distinct()
.collect(Collectors.toMap(
Function.identity(), //元素输入就是输出,作为key
s -> (int) s.chars().distinct().count()// 输入元素的不同的字母个数,作为value
));
其他常用方法
long nrOfAnimals = Stream.of("Monkey", "Lion", "Giraffe", "Lemur").count();
// 管道中元素数据总计结果nrOfAnimals: 4
int sum = IntStream.of(1, 2, 3).sum();
// 管道中元素数据累加结果sum: 6
OptionalDouble average = IntStream.of(1, 2, 3).average();
//管道中元素数据平均值average: OptionalDouble[2.0]
int max = IntStream.of(1, 2, 3).max().orElse(0);
//管道中元素数据最大值max: 3
---------------------
IntStream stream = Arrays.stream(1,2,3);
//流中的元素全部装箱,转换为流 ---->int转为Integer
Stream<Integer> integerStream = stream.boxed();
9.4 Optional
9.4.1 定义
使用Optional可以避免代码中的 if (obj != null) { } 这样范式的代码,可以采用链式编程的风格
public static String getGender(Student student){
if(null == student)return "Unkown";
return student.getGender();}
----------------------------------------------------------
//用Optional优化后的方法
public static String getGender(Student student) {
return Optional.ofNullable(student).map(u -> u.getGender()).orElse("Unkown");}
9.4.2 创建
// 1、创建一个包装对象值为空的Optional对象
Optional<String> optStr = Optional.empty();
// 2、创建包装对象值非空的Optional对象
Optional<String> optStr1 = Optional.of("optional");
// 3、创建包装对象值允许为空的Optional对象
Optional<String> optStr2 = Optional.ofNullable(null);
9.4.3 常用用法
ifPresent
调用其他方法返回一个集合,在不通过 if 判断是否为 null 就可以放心的遍历
Optional.ofNullable(List).ifPresent()
orElse
在目标集合对象为 null 的时候可以设定默认值
Optional.ofNullable(userList).orElse()
orElseThrow
如果目标对象为 null, 抛出自定义的异常
Optional.ofNullable().orElseThrow()

若有收获,就点个赞吧
0 人点赞
