- 1 概述
- 2 架构
- 3.安装与启动
- 3 命令
- 4 整合
- 重试次数
- 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
- 批量大小
- 提交延时
- 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
- linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
- 生产端缓冲区大小
- Kafka提供的序列化和反序列化类
- 自定义分区器
- spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
- 默认的消费组ID
- 是否自动提交offset
- 提交offset延时(接收到消息后多久提交offset)
- 当kafka中没有初始offset或offset超出范围时将自动重置offset
- earliest:重置为分区中最小的offset;
- latest:重置为分区中最新的offset(消费分区中新产生的数据);
- none:只要有一个分区不存在已提交的offset,就抛出异常;
- 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
- 消费请求超时时间
- Kafka提供的序列化和反序列化类
- 消费端监听的topic不存在时,项目启动会报错(关掉)
- 设置批量消费
- spring.kafka.listener.type=batch
- 批量消费每次最多消费多少条消息
- spring.kafka.consumer.max-poll-records=50
1 概述
Kafka是一个分布式、跨平台的、伸缩性强、高性能,基于zookeeper 协调的分布式日志系统,也可以作为MQ消息系统。
Kafka的高性能原因:
1.顺序写磁盘(相比磁盘的随机写快很多)。如果你是追加文件末尾按照顺序的方式来写数据的话,那么这种磁盘顺序写的性能基本上可以跟写内存的性能本身也是差不多的。
2.利用Page Cache空中接力的方式来实现高效读写,操作系统本身有一层缓存,叫做page cache,是在内存里的缓存,我们也可以称之为os cache,意思就是操作系统自己管理的缓存。原理就是Page Cache可以把磁盘中的数据缓存到内存中,把对磁盘的访问改为对内存的访问。
3.零拷贝:直接让操作系统的cache中的数据发送到网卡后传输给下游的消费者,直接跳过了两次拷贝数据的步骤,Socket缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到Socket缓存。
2 架构

- Producer:消息生产者,就是向 kafka broker 发消息的客户端;
- Consumer:消息消费者,向 kafka broker 取消息的客户端;
- Consumer Group(CG):消费者组,由多个 consumer 组成。 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。同一个组的消费者之间时竞争关系,一个 partition 被一个消费者消费了,就不会被组内另一个消费者消费;
- Broker:一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
- Topic:可以理解为一个队列, 生产者和消费者面向的都是一个 topic;
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;分区提高 topic 并发,提高负载均衡能力;
- Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
- leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
- follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 follower。
一个主题拥有多个分区
通常情况下消费者是线性消费,可以动态调整offset来重新或者跳过消费消息
一个主题拥有多个分区,可以指定由消费者组的某个消费者消费
3.安装与启动
3 命令
1.kafka启动: ./kafka-server-start.sh ../config/server.properties &
2.创建topic: ./kafka-topics.sh —create —zookeeper localhost:2181 —replication-factor 1 —partitions 1 —topic tes
3.查看kafka的topic:./kafka-topics.sh —zookeeper 192.168.18.14:2181 —list
4.查看kafka某个topic下partition信息: ./kafka-topics.sh —describe —zookeeper master:2181 —topic test-topic
5.查看kafka的指定topic: ./kafka-topics.sh —zookeeper 192.168.18.14:2181 —describe —topic oiltourTest
6.控制台向kafka生产数据: ./kafka-console-producer.sh —broker-list master:9092 —topic jason_20180519
7.控制台消费kafka的数据: ./kafka-console-consumer.sh —zookeeper storm1:2181 —topic jason_20180519 —from-beginning
8.查看topic下某分区偏移量的最小值: ./kafka-run-class.sh kafka.tools.GetOffsetShell —topic test-topic —time -1 —broker-list master:9092 —partitions 0
9.增加topic的partition:/kafka-topics.sh —alter —topic jason_20180519 —zookeeper 10.200.10.24:2181,10.200.10.26:2181,10.200.10.29:2181 —partitions 5
10.删除topic,慎用,只会删除zookeeper中的元数据,消息文件须手动删除: ./kafka-run-class.sh kafka.admin.DeleteTopicCommand —zookeeper master:2181 —topic yq20171220
11.彻底删除topic: rmr /brokers/topics/【topic name】即可
4 整合
- 官网下载kafka压缩文件上传到服务器后解压
- 环境安装java(文章中的配置文件需要修改自己的java安装目录)
-- 先启动zookeeperbin/zookeeper-server-start.sh config/zookeeper.properties-- 再启动kafkabin/kafka-server-start.sh config/server.properties
4.1整合SpringBoot
引入pom依赖
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency>配置 ```java
#####【Kafka集群】
spring.kafka.bootstrap-servers=112.126.74.249:9092,112.126.74.249:9093
#####【初始化生产者配置】
重试次数
spring.kafka.producer.retries=0
应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
spring.kafka.producer.acks=1
批量大小
spring.kafka.producer.batch-size=16384
提交延时
spring.kafka.producer.properties.linger.ms=0
当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
生产端缓冲区大小
spring.kafka.producer.buffer-memory = 33554432
Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
自定义分区器
spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
#####【初始化消费者配置】
默认的消费组ID
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
是否自动提交offset
spring.kafka.consumer.enable-auto-commit=true
提交offset延时(接收到消息后多久提交offset)
spring.kafka.consumer.auto.commit.interval.ms=1000
当kafka中没有初始offset或offset超出范围时将自动重置offset
earliest:重置为分区中最小的offset;
latest:重置为分区中最新的offset(消费分区中新产生的数据);
none:只要有一个分区不存在已提交的offset,就抛出异常;
spring.kafka.consumer.auto-offset-reset=latest
消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
消费请求超时时间
spring.kafka.consumer.properties.request.timeout.ms=180000
Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
消费端监听的topic不存在时,项目启动会报错(关掉)
spring.kafka.listener.missing-topics-fatal=false
设置批量消费
spring.kafka.listener.type=batch
批量消费每次最多消费多少条消息
spring.kafka.consumer.max-poll-records=50
<a name="Ekr5Z"></a>
### 4.2 Hello Kafka
```java
//简单生产者
@RestController
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
@GetMapping("/kafka/normal/{message}")
public void sendMessage1(@PathVariable("message") String normalMessage) {
kafkaTemplate.send("topic1", normalMessage);
}
}
//简单消费者
@Component
public class KafkaConsumer {
// 消费监听
@KafkaListener(topics = {"topic1"})
public void onMessage1(ConsumerRecord<?, ?> record){
// 消费的哪个topic、partition的消息,打印出消息内容
System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
}
5 集群配置
5.1 集群规划

5.2 Zookeeper集群搭建
5.3 虚拟机搭建Kafka步骤
5.3.1 安装虚拟机及Centos系统
5.3.3 安装docker相关
(1)宝塔面板安装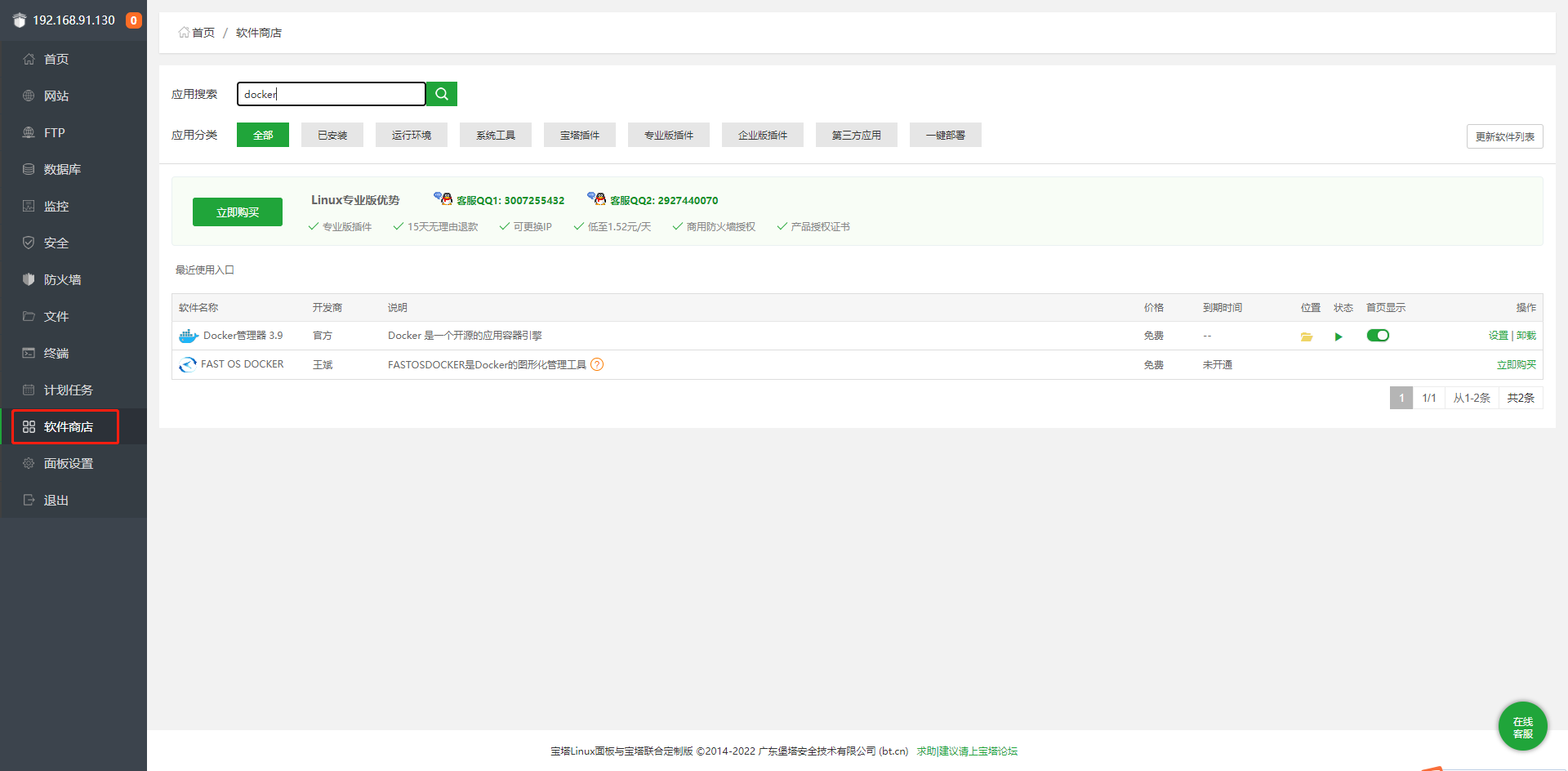
(2)启动docker
systemctl start docker #如果提示"Got permission denied while trying to connect to the Docker daemon socket"执行下面命令
============================
sudo groupadd docker #添加docker用户组
sudo gpasswd -a $XXX docker #检测当前用户是否已经在docker用户组中,其中XXX为用户名
sudo gpasswd -a $USER docker #将当前用户添加至docker用户组
newgrp docker #更新docker用户组
(3)安装docker-compose
#要安装其他版本的 Compose,请替换 1.24.1
sudo curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
#添加可执行权限
sudo chmod +x /usr/local/bin/docker-compose
#检查安装版本
docker-compose --version
5.3.4 使用kafka
(1)编写kafka单机启动脚本
注:新版kafka自带zookeeper,也可以只配置kafka,后面进入kafka镜像修改配置
version: "3.3"
services:
zookeeper:
image: wurstmeister/zookeeper
restart: always
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
restart: always
ports:
- "9092:9092"
depends_on:
- "zookeeper"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.91.130:9092
KAFKA_HEAP_OPTS: "-Xmx256M -Xms128M"
kafdrop:
image: obsidiandynamics/kafdrop
restart: "no"
ports:
- "9000:9000"
environment:
KAFKA_BROKERCONNECT: "kafka:9092"
JVM_OPTS: "-Xms16M -Xmx48M -Xss180K -XX:-TieredCompilation -XX:+UseStringDeduplication -noverify"
depends_on:
- "kafka"
(2)启动命令
docker-compose -f kafka.yml up -d
(3)访问kafka操作界面kafdrop(http://ip:9000)
(5)虚拟机使用cpolar提供内网穿透
5.3.4 安装Kafka-Nginx
(1)安装
注:如果已安装需要备份原来的Nginx(参考资料3)
# 安装依赖
yum install wget git -y
yum install gcc-c++ -y
git clone https://github.com/edenhill/librdkafka
cd librdkafka
./configure
make
sudo make install
# 下载nignx安装包
wget http://nginx.org/download/nginx-1.20.1.tar.gz
tar -zxf nginx-1.20.1.tar.gz
cd nginx-1.20.1
yum install gcc zlib zlib-devel openss1 openss1-devel pcre pcre-devel -y
# 下载ngx_kafka_module安装包(注意install会覆盖原来的install?)
git clone https://github.com/brg-liuwei/ngx_kafka_module.git
cd nginx-1.20.1
./configure --add-module=/root/ngx_kafka_module
make
sudo make install
(2)配置
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
kafka;
kafka_broker_list linux121:9092;
server {
listen 80;
server_name localhost;
#------------kafka相关配置开始------------
location = /kafka/log {
#跨域相关配置
add_header 'Access-Control-Allow-Origin' $http_origin;
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
kafka_topic tp_individual;
}
}
}
参考资料:
资料1:https://blog.csdn.net/hu_lichao/article/details/109972138
资料2:https://github.com/brg-liuwei/ngx_kafka_module
资料3:https://blog.csdn.net/weixin_45716993/article/details/102880755

若有收获,就点个赞吧
0 人点赞
