实现动态sql、多表查询
学习目标
1. 掌握sqlMapConfig.xml中常用标签2. 掌握mybatis框架在DAO层的开发3. 能够完成单表的CRUD操作4. 掌握mybatis框架的输入输出映射5. 掌握MyBatis动态SQL
第一章、动态SQL
MyBatis 的强大特性之一便是它的动态 SQL。如果你有使用 JDBC 或其它类似框架的经验,你就能体会到根据不同条件拼接 SQL 语句的痛苦。例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL 这一特性可以彻底摆脱这种痛苦。
例如,下面需求就会使用到拼接sql语句:
【需求】:查询男性用户,如果输入了用户名,按用户名模糊查询,如果没有输入用户名,就查询所有男性用户。
正常的sql语句:查询男性并且用户名中包含zhang
select * from user where sex = "男" and user_name like '%zhang%'

select * from user where sex = "男"
实现需求时还要判断用户是否输入用户名来做不同的查询要求,而这里似乎没有办法判断是否输入了用户名,因此可以考虑使用动态sql来完成这个功能。动态 SQL 元素和后面学习的 JSTL 或基于之前学习的类似 XML 的文本处理器相似。在 MyBatis 之前的版本中,有很多元素需要花时间了解。MyBatis 3 开始精简了元素种类,现在只需学习原来一半的元素便可。MyBatis 采用功能强大的 OGNL 的表达式来淘汰其它大部分元素。<br />常见标签如下:
if:判断 if(1 gt 2){} choose (when, otherwise):分支判断 switch:多选一 trim (where, set):去除 foreach:循环遍历标签
动态SQL中的业务逻辑判断需要使用到以下运算符: ognl表达式
1. e1 or e2 满足一个即可 2. e1 and e2 都得满足 3. e1 == e2,e1 eq e2 判断是否相等 4. e1 != e2,e1 neq e2 不相等 5. e1 lt e2:小于 lt表示less than 6. e1 lte e2:小于等于,其他gt(大于),gte(大于等于) gt 表示greater than 7. e1 in e2 8. e1 not in e2 9. e1 + e2,e1 * e2,e1/e2,e1 - e2,e1%e2 10. !e,not e:非,求反 11. e.method(args)调用对象方法 13. e1[ e2 ]按索引取值,List,数组和Map
1、if标签
格式:
<if test="判断条件">满足条件执行的代码</if>
说明:
1)if标签:判断语句,用于进行逻辑判断的。如果判断条件为true,则执行if标签的文本内容
2)test属性:用来编写表达式,支持ognl;
【需求】:查询男性用户,如果输入了用户名,按用户名模糊查询,如果没有输入用户名,就查询所有男性用户。
正常的sql语句:查询男性并且用户名中包含zhang
select * from tb_user where sex = "男" and user_name like '%zhang%'

select * from tb_user where sex = "男"
实现需求时还要判断用户是否输入用户名来做不同的查询要求,而这里似乎没有办法判断是否输入了用户名,因此可以考虑使用动态sql来完成这个功能。<br /> 上述动态sql语句部分: and user_name like '%zhang%'
1.1、定义接口方法
在UserMapper接口中,定义如下方法:
/*** 根据用户名模糊查询* @param userName* @return*/List<User> queryLikeUserName(@Param("userName") String userName);
1.2、编写SQL
在UserMapper.xml文件中编写与方法名同名的sql语句:
<select id="queryLikeUserName" resultType="user">select * from user where sex='男'<if test="userName!=null and userName.trim()!=''">and username like '%${userName}%'</if></select>
【注】<if> 判断中:
1、if标签:用来判断;
2、test属性:使用OGNL表达式,完成具体的判断业务逻辑;
3、这里使用的字符串拼接,所以这里不能是#取值,只能使用$取值,否则会报错
4、可以借助concat拼接函数进行拼接 concat(‘%’,#{userName},’%’)
1.3、测试
【userName有值】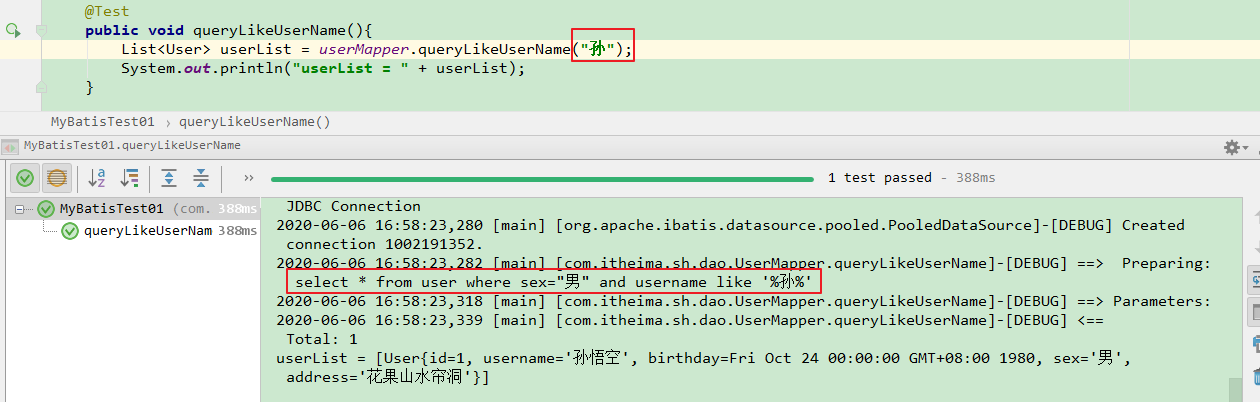
对应的SQL语句是:select * from user where sex=”男” and username like ‘%孙%’
【userName没有值】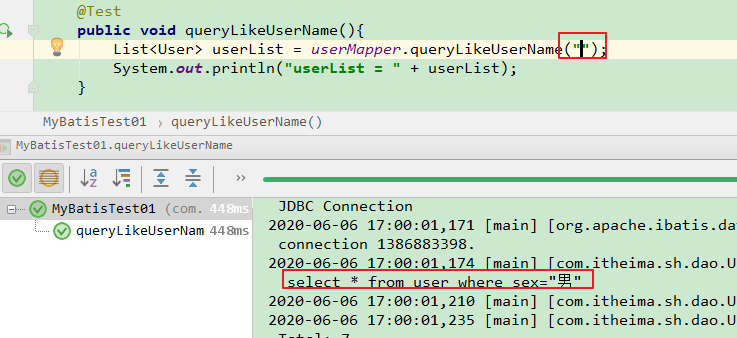
对应的SQL语句是:select * from user where sex=”男”
【小结】
1、if标签:用来在sql中处理判断是否成立的情况;
2、属性:test中书写OGNL表达式,如果结果为true,if标签的文本中的内容会被拼接到SQL中,反之不会被拼接到SQL中;
3、if标签的应用场景:适用于 二选一
2、choose,when,otherwise
choose标签:分支选择(多选一,从上往下遇到成立的条件即停止) when子标签:编写条件,不管有多少个when条件,一旦其中一个条件成立,后面的when条件都不执行。 test属性:编写ognl表达式 otherwise子标签:当所有条件都不满足时,才会执行该条件。 类似java中的switch choose --> switch when ---->case ,break otherwise--->default
案例:
编写一个查询方法,设置两个参数,一个是用户名,一个是住址。 根据用户名或者住址查询所有男性用户: 如果输入了用户名则按照用户名模糊查找, 否则就按照住址查找,两个条件只能成立一个, 如果都不输入就查找用户名为“孙悟空”的用户。
【需求分析】
1、查询所有男性用户,如果输入了用户名则按照用户名模糊查找;
SELECT * FROM user WHERE sex = "男" AND username LIKE '%孙%';
2、查询所有男性用户,如果输入了住址则按照住址查询;
SELECT * FROM user WHERE sex = "男" AND address = "花果山水帘洞";
3、查询所有男性用户,如果都不输入就查找用户名为“孙悟空”的用户。
SELECT * FROM user WHERE sex = "男" AND username = '孙悟空';
2.1、定义接口方法
在UserMapper接口中,定义接口方法:
/*查询用户名或者地址*/List<User> queryByUserNameOrAddress(@Param("userName") String userName, @Param("address") String address);
2.2、编写SQL
在UserMapper.xml中编写对应的SQL语句
<!--根据用户名或者住址查询所有男性用户:如果输入了用户名则按照用户名模糊查找,否则就按照住址查找,两个条件只能成立一个,如果都不输入就查找用户名为“孙悟空”的用户。--><select id="queryByUserNameOrAddress" resultType="user">select * from user where sex='男'<choose><when test="userName!=null and userName.trim()!=''">and user_name like concat('%',#{userName},'%')</when><when test="address!=null and address.trim()!=''">and address = #{address}</when><otherwise>and user_name = '孙悟空'</otherwise></choose></select>
2.3、测试
编写测试类,对这个方法进行测试:
@Test
public void queryByUserNameOrAddress(){
List<User> userList = userMapper.queryByUserNameOrAddress("", null);
System.out.println("userList = " + userList);
}
【小结】
1、choose,when,otherwise 标签组合的作用类似于java中的switch语句,使用于多选一;
3、where
where标签:拼接多条件查询时 添加where关键字能够去除多余的and或者or关键字
案例:按照如下条件查询所有用户,
如果输入了用户名按照用户名进行查询, 如果输入住址,按住址进行查询, 如果两者都输入,两个条件都要成立。
【需求分析】
1、如果输入了用户名按照用户名进行查询,
SELECT * FROM user WHERE user_name = '孙悟空';
2、如果输入住址,按住址进行查询,
SELECT * FROM user WHERE address='花果山水帘洞';
3、如果两者都输入,两个条件都要成立。
SELECT * FROM user WHERE user_name = '孙悟空' AND address='花果山水帘洞';
3.1、定义接口方法
在UserMapper接口中定义如下方法:
List<User> queryByUserNameAndAddress(@Param("userName") String userName, @Param("address") String address);
3.2、编写SQL
在UserMapper.xml中编写SQL
如果不用where标签写多条件
<select id="queryByUserNameAndAddress" resultType="user">
SELECT * FROM user where
<if test="userName != null and userName.trim()!=''">
username = #{userName}
</if>
<if test="address!=null and address.trim()!=''">
AND address = #{address}
</if>
</select>
如果上述查询是userName为null,那么语句会生成如下:
SELECT * FROM user where AND address = ?
这样 where 后的 AND 是多余的
正确写法:
<select id="queryByUserNameAndAddress" resultType="user">
SELECT * FROM user
<where>
<if test="userName != null and userName.trim()!=''">
username = #{userName}
</if>
<if test="address!=null and address.trim()!=''">
AND address = #{address}
</if>
</where>
</select>
假设用户名username是空,那么用户名的sql语句不参与条件,此时sql语句就会变为
SELECT * FROM user WHERE address = ?
子标签将 AND 去掉了
3.3、测试
@Test
public void queryByUserNameAndAge() {
List<User> userList = userMapper.queryByUserNameAndAddress("", "花果山水帘洞");
System.out.println("userList = " + userList);
}
只传入住址,此时where子标签去掉了and.
【小结】
1、
4、set
set标签:在update语句中,可以自动添加一个set关键字,并且会将动态sql最后多余的逗号去除。
案例:
修改用户信息,如果参数user中的某个属性为null,则不修改。
如果在正常编写更新语句时,如下:
<!--选择性地对user数据进行修改-->
<update id="updateSelectiveUser">
update user set
<if test="username != null and username.trim()!=''">
username = #{username},
</if>
<if test="birthday != null">
birthday=#{birthday},
</if>
<if test="sex != null and sex.trim()!=''">
sex=#{sex},
</if>
<if test="address != null and address.trim()!=''">
address=#{address}
</if>
where id = #{id}
</update>
那么一旦在传递的参数中没有address,此时生成的sql语句就会因为多了一个逗号而报错。
update user SET username = ?, birthday=?, sex=?, where id = ?
4.1、定义接口方法
在UserMapper接口中定义如下方法:
int updateSelectiveUser(User user); //返回值表示修改的行数
4.2、编写SQL
在UserMapper.xml文件中编写如下SQL:
<!--选择性地对user数据进行修改-->
<update id="updateSelectiveUser">
update user
<set>
<if test="username != null and username.trim()!=''">
username = #{username},
</if>
<if test="birthday != null">
birthday=#{birthday},
</if>
<if test="sex != null and sex.trim()!=''">
sex=#{sex},
</if>
<if test="address != null and address.trim()!=''">
address=#{address}
</if>
</set>
where id = #{id}
</update>
4.3、测试
@Test
public void updateSelectiveUser() {
User user = new User();
user.setUsername("齐天大圣孙悟空");
user.setBirthday(new Date());
user.setSex("妖");
user.setAddress("花果山");
user.setId(1);
userMapper.updateSelectiveUser(user);
}
【结果】
update user SET username = ?, birthday=?, sex=? where id = ?
【小结】
1、
5、foreach
foreach标签:遍历集合或者数组
<foreach
collection="集合名或者数组名"
item="元素"
separator="标签分隔符"
open="以什么开始"
close="以什么结束">
#{元素}
</foreach>
collection属性:接收的集合或者数组,集合名或者数组名
item属性:集合或者数组参数中的每一个元素
separator属性:标签分隔符
open属性:以什么开始
close属性:以什么结束
案例:
按照id值是1,2,3来查询用户数据;
select * from user where id in (1,2,3);
5.1、定义接口方法
在UserMapper接口中定义如下方法:
List<User> queryByIds(@Param("arrIds") Integer[] arrIds);
这里一定加@Param(“arrIds”),否则报错
5.2、编写SQL
<!--根据多个id值查询-->
<select id="queryByIds" resultType="user">
SELECT * FROM user WHERE id IN
<foreach
collection="arrIds"
item="ID"
separator=","
open="(" close=")" >
#{ID}
</foreach>
</select>
5.3、测试
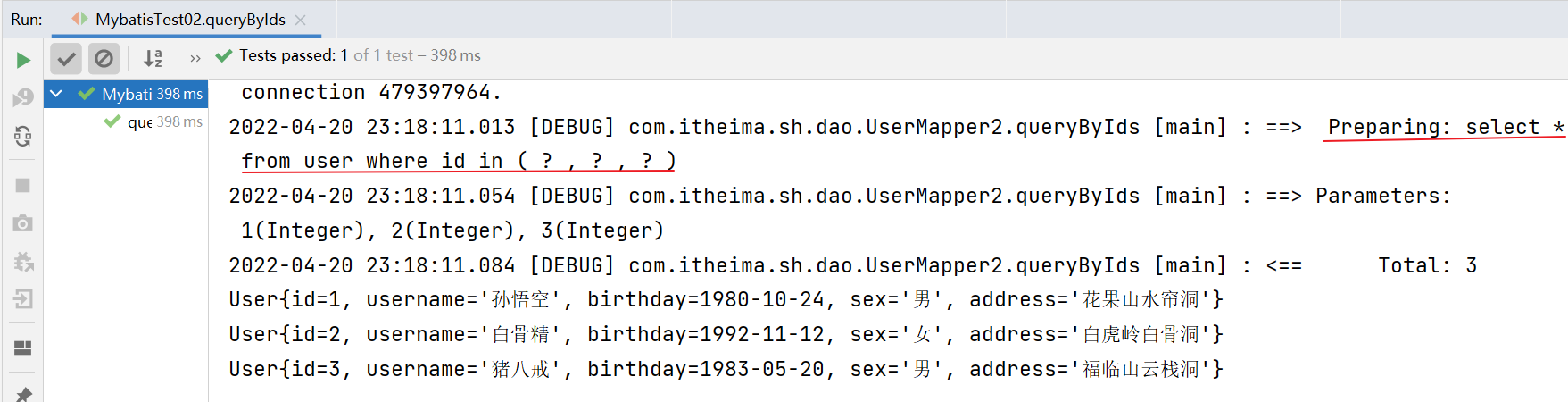
@Test
public void queryByIds() {
Integer[] arrIds = {1,2,3};
List<User> userList = mapper.queryByIds(arrIds);
for (User user : userList) {
System.out.println(user);
}
}
【小结】
6、小结
If标签:条件判断
test属性:编写ognl表达式
choose ,when, otherwise : 类似于java中的switch, 多选一
- where标签:用于sql动态条件拼接,添加where关键字,可以将动态sql多余的第一个and或者or去除。
- set标签: 用于更新语句的拼接,添加set关键字,并可以将动态sql中多余的逗号去除
foreach标签:用于遍历参数中的数组或者集合
collection属性:参数中的数组或者集合
item属性:表示数组或者集合中的某个元素,取出数据使用#{item的属性值}
separator属性:分隔符
open:以什么开始
close:以什么结束
第二章 mybatis多表查询【掌握】
1、准备工作
【1】创建新的maven项目。
创建java项目,导入依赖和配置文件;
mysql驱动依赖,mybatis依赖,Logback依赖,Logback配置文件 mybaitis依赖
pom.xml 依赖部分,将以下代码拷贝到pom文件的 dependencies 标签内
<!--mybatis核心包-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.0</version>
</dependency>
<!--logback日志包-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.26</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<!--mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.18</version>
</dependency>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
logback.xml 配置 放到resources 文件夹中
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- CONSOLE :表示当前的日志信息是可以输出到控制台的。-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--输出流对象 默认 System.out 改为 System.err-->
<target>System.out</target>
<encoder>
<!--格式化输出:
%d表示日期
%-5level:日志级别从左显示5个字符宽度
%c : 取类名
%thread表示线程名
%msg:日志消息,
%n是换行符
-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%-5level] %c [%thread] : %msg%n</pattern>
</encoder>
</appender>
<!-- File是输出的方向通向文件的 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<!--%logger{36}最大字符长度-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<!--日志输出路径-->
<file>D:/code/itheima-data.log</file>
<!--指定日志文件拆分和压缩规则-->
<!--以下配置是文件约等于1MB会以执行的压缩方式进行拆分新的文件-->
<rollingPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--通过指定压缩文件名称,来确定分割文件方式-->
<fileNamePattern>D:/code/itheima-data2-%d{yyyy-MMdd}.log%i.gz</fileNamePattern>
<!--文件拆分大小-->
<maxFileSize>1MB</maxFileSize>
</rollingPolicy>
</appender>
<!--
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF , 默认debug
<root>可以包含零个或多个<appender-ref>元素,标识这个输出位置将会被本日志级别控制。
TRACE : 跟踪
DEBUG : 调试
INFO : 信息
WARN : 警告
ERROR : 错误
-->
<root level="DEBUG">
<!--控制台位置被日志级别控制-->
<appender-ref ref="CONSOLE"/>
<!--文件位置被日志级别控制-->
<appender-ref ref="FILE"/>
</root>
</configuration>
mybatis的配置文件,也是放到resources文件夹中
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="jdbc.properties"/>
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<typeAliases>
<package name="com.itheima"/>
</typeAliases>
<!--mybatis环境的配置-->
<environments default="development">
<!--通常我们只需要配置一个就可以了, id是环境的名字 -->
<environment id="development">
<!--事务管理器:由JDBC来管理-->
<transactionManager type="JDBC"/>
<!--数据源的配置:mybatis自带的连接池-->
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--加载映射文件,放到src下即可-->
<!-- <mapper resource="userMapper.xml"/>-->
<package name="com.itheima.dao"/>
</mappers>
</configuration>
jdbc.username=root
jdbc.password=root
jdbc.url=jdbc:mysql://localhost:3306/day06
jdbc.driver=com.mysql.jdbc.Driver
【2】导入SQL脚本
新建一个数据库使用,将相关的表放进去
运行资料中的sql脚本:mybatis.sql
附件:mybatis.sql 
【3】创建实体来包,导入资料中的pojo
Item.javaOrder.javaOrderdetail.javaUser.java
【4】UserMapper接口 映射文件UserMapper.xml定义
package com.itheima.dao;
import com.itheima.pojo.User;
public interface UserMapper {
//完成根据id查询用户数据;
User selectById(Long id);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.UserMapper">
<!--根据id查询:statement-->
<select id="selectById" resultType="User">
SELECT * FROM tb_user WHERE id=#{id}
</select>
</mapper>
【5】测试
import com.itheima.dao.UserMapper;
import com.itheima.pojo.User;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import java.io.IOException;
import java.io.InputStream;
public class MyBatisTest01 {
public static UserMapper mapper;
public static SqlSession session;
@BeforeClass
public static void init() throws IOException {
// 所有测试方法执行前初始化
//1.从xml文件中构建SqlSessionFactory
//定义核心配置文件路径
String resource = "mybatis-config.xml";
//加载核心配置文件获取输入流
InputStream inputStream = Resources.getResourceAsStream(resource);
//默认的环境
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2.从SqlSessionFactory中获取session
//session = sqlSessionFactory.openSession(); //打开一个与数据库的连接 , 事务是默认提交的
session = sqlSessionFactory.openSession(true); //设置事务为自动提交
//3.使用session获取接口的动态代理对象
mapper = session.getMapper(UserMapper.class);
}
@AfterClass
public static void release() {
// 所有测试方法执行后释放资源
//关闭会话
session.close();
}
@Test
public void selectById() {
User user = mapper.selectById(1L);
System.out.println(user);
}
}
2、表介绍和表关系说明
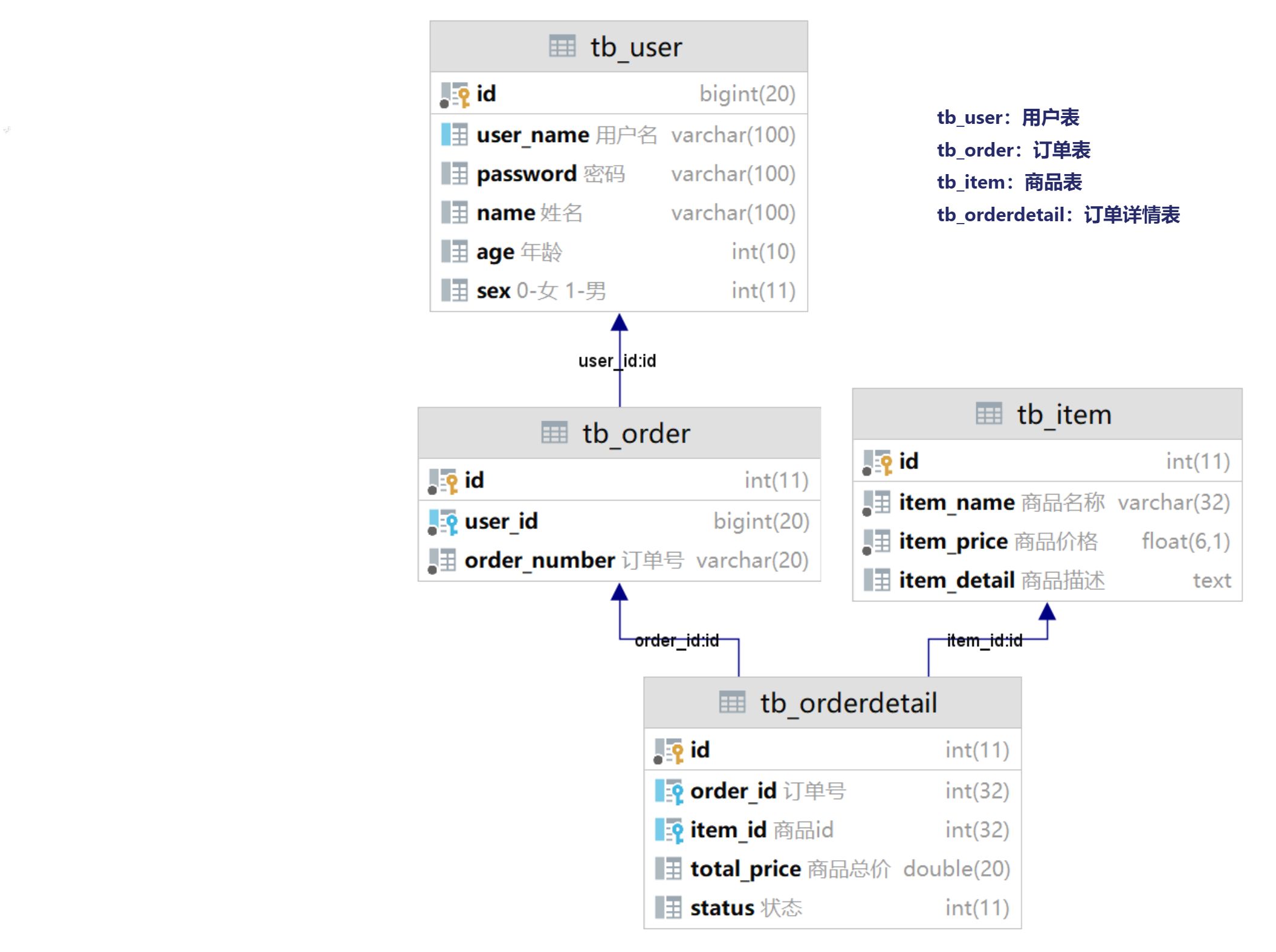
【表关系】
- tb_user 和 tb_order表关系
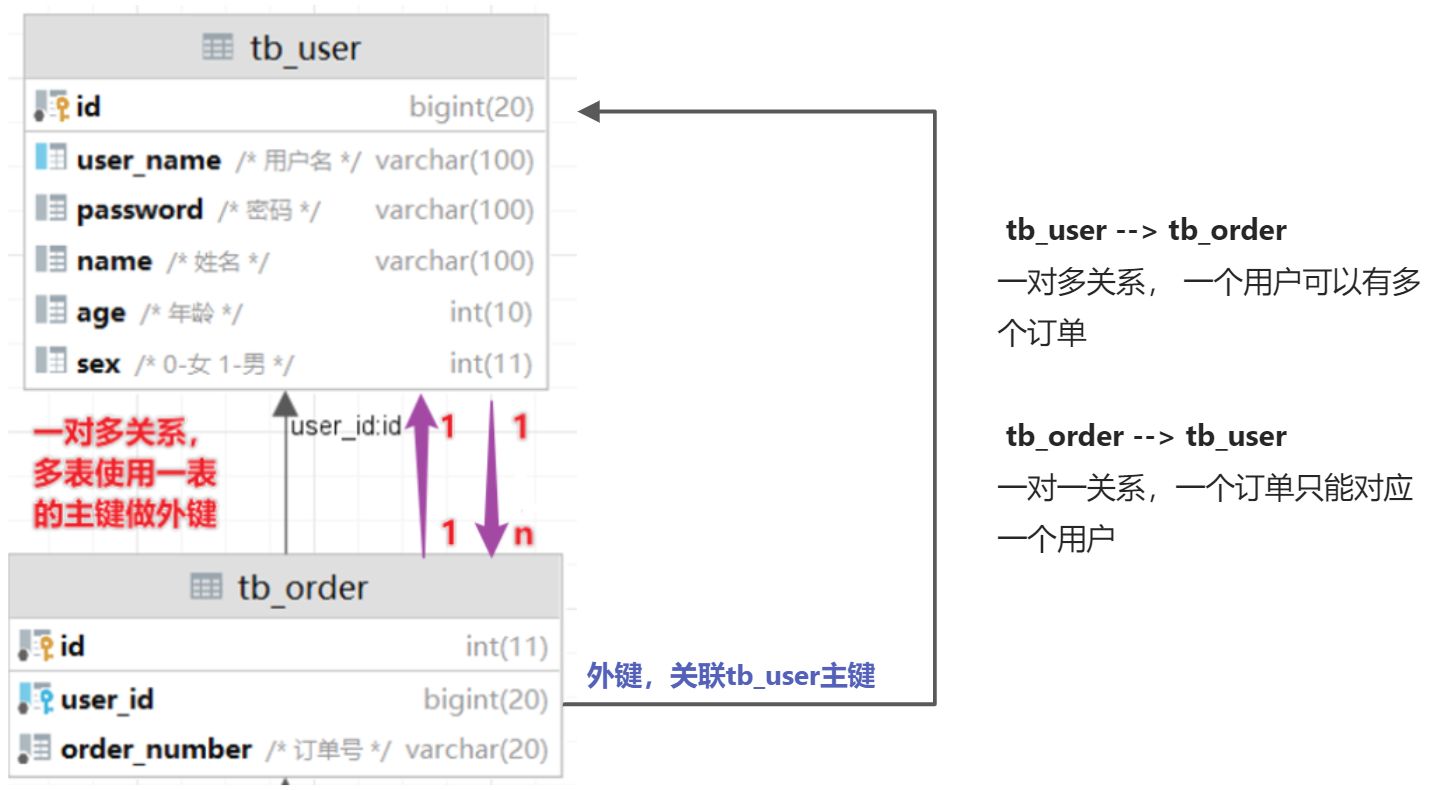
tb_order 和 tb_item 表关系
3、一对一查询
【案例】
使用多表关联查询,完成根据订单号查询订单信息和下单人信息(订单号:20140921003)
【分析】
一个订单编号对应一个订单,一个订单只能属于一个人。所以上述需求实现是一对一的实现。
【步骤】第一步:查询SQL分析; 第二步:添加关联关系; 第三步:编写接口方法; 第四步:编写映射文件; 第五步:测试
第一步:需求分析
编写多表关联查询SQL,根据订单号查询订单信息及下单人信息;
查询语句以及查询结果:
多表查询时:查询的数据涉及到那些表。(tb_order tb_user)
- 关联表查询,去除笛卡尔积 (inner join on)
- 设定条件,筛选结果 (指定订单号)
- 定义查询字段 (订单信息和用户信息都要)
查询结果:#【方式】:多表关联查询,内连接 SELECT * FROM tb_order o inner join tb_user u on o.user_id = u.id where o.order_number='20140921003'
第二步:添加关联关系
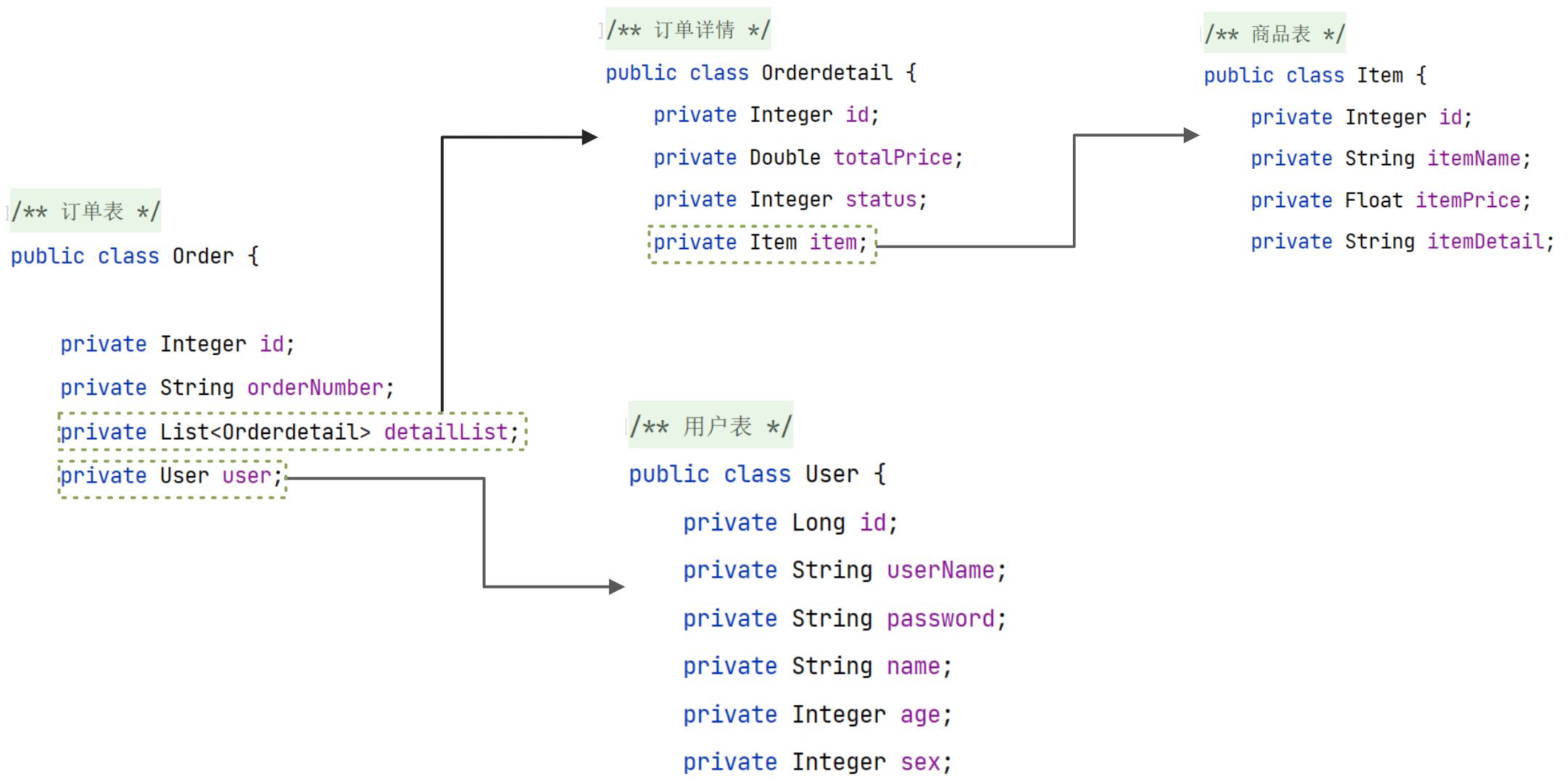
修改Order类,在Order类中,添加关联对象User,并添加getter和setter方法;
package com.itheima.pojo;
/**
* 订单表
*
*/
public class Order {
private Integer id;
private String orderNumber;
//关联User对象
private User user;
//省略id,orderNumber 属性的getter,setter方法
}
第三步:编写接口方法
编写OrderMapper接口
package com.itheima.dao;
import com.itheima.pojo.Order;
import org.apache.ibatis.annotations.Param;
public interface OrderMapper {
/**
* 根据订单号查询订单及下单人的信息
*
* @param orderNumber 订单号
* @return 订单用户信息
*/
Order queryOrderAndUserByOrderNumber(@Param("orderNumber") String orderNumber);
}
第四步:编写SQL映射文件
一对一映射关系中,需要用resultMap,使用其子标签association来表示引用的另一个pojo类的对象。
association标签常用属性:
- property=”user” 表示在Order类中的引用的User类的对象成员变量名
- javaType=”User” 表示引用的user对象属于User类型
- autoMapping=”true” 表示表字段和属性名相同,或者驼峰命名对应经典命名自动映射。
association标签常用子标签:
- id 表主键字段,pojo属性映射配置
- result 表字段,pojo属性映射配置
如下:
<resultMap id="orderUserMap" type="Order" autoMapping="true">
<!--id主表主键-->
<id column="id" property="id"/>
<!--result 表字段和pojo字段映射关系,可以省略-->
<result column="order_number" property="orderNumber"/>
<association property="user" javaType="User" autoMapping="true">
<!--从表主键-->
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
</association>
</resultMap>
在OrderMapper.xml中编写对应的SQL;
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.OrderMapper">
<resultMap id="orderUserMap" type="Order" autoMapping="true">
<!--id主表主键-->
<id column="id" property="id"/>
<!--result 表字段和pojo字段映射关系,可以省略-->
<result column="order_number" property="orderNumber"/>
<association property="user" javaType="User" autoMapping="true">
<!--从表主键-->
<id column="id" property="id"/>
<result column="user_name" property="userName"/>
</association>
</resultMap>
<!--多表关联查询:一对一-->
<select id="queryOrderAndUserByOrderNumber" resultMap="orderUserMap">
SELECT
*
FROM
tb_order o
INNER JOIN tb_user u ON o.user_id = u.id
WHERE
o.order_number = #{orderNumber}
</select>
</mapper>
第五步:测试
//省略导包
public class OrderMapperTest {
static SqlSession sqlSession;
static OrderMapper mapper;
@BeforeClass
public static void initMapper() throws IOException {
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory builder = new SqlSessionFactoryBuilder().build(in);
sqlSession = builder.openSession(true);
mapper = sqlSession.getMapper(OrderMapper.class);
}
@AfterClass
public static void release(){
sqlSession.close();
}
@Test
public void selectByIdTest() {
Order order = mapper.queryOrderAndUserByOrderNumber("20140921003");
System.out.println("order = " + order);
}
}
【测试结果】
SQL:
SELECT * FROM tb_order o INNER JOIN tb_user u ON o.user_id = u.id WHERE o.order_number = ?
结果:
order = Order{id=3, orderNumber='20140921003', user=User{id=3, userName='zhangsan', password='123456', name='张三', age=30, sex=1}}
注意事项
通过上述测试结果,我们发现User的id是错误的,不是3,正确结果是1: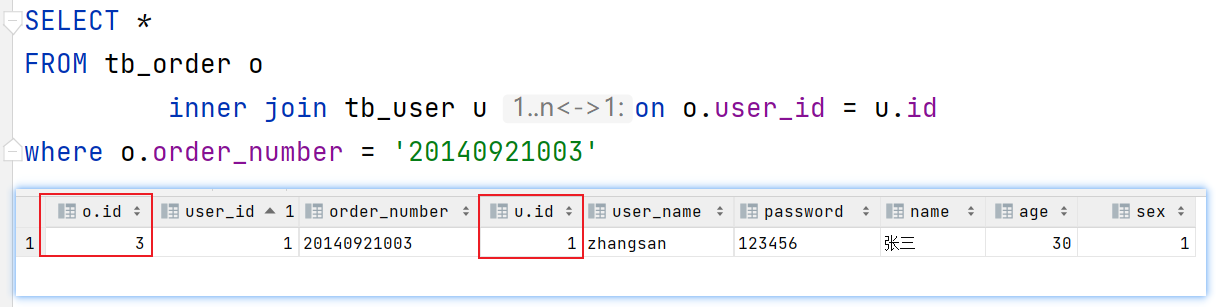
因为tb_user表的主键是id,tb_order的主键也是id。查询的结果中有两列相同的id字段。在将查询结果封装到实体类的过程中就会封装错误。
注意:tb_order和tb_user表查询的是id结果其实名字都是id,只是在图形化工具界面显示时有区别。
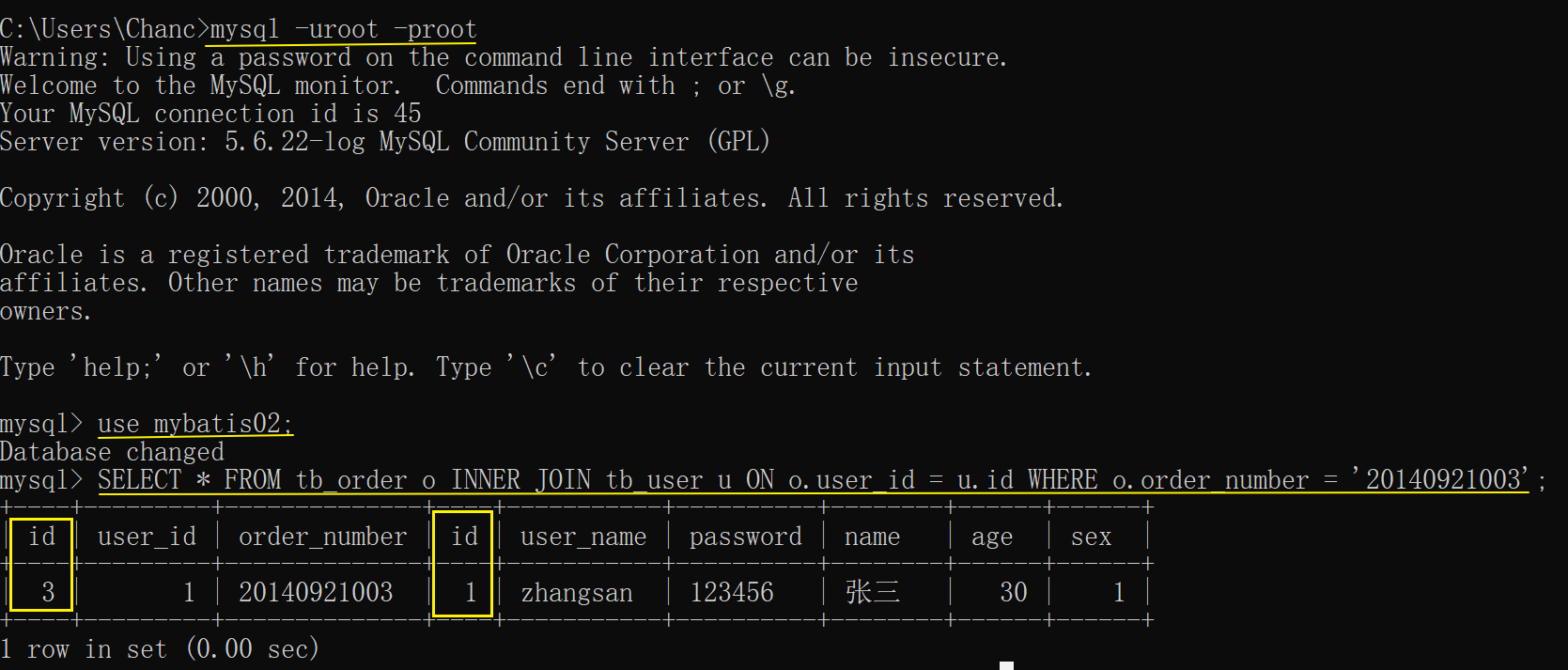
可以在cmd 命令窗口查看原始结果:
SELECT * FROM tb_order o INNER JOIN tb_user u ON o.user_id = u.id WHERE o.order_number = '20140921003';
【解决方案】
1、建议将所要查询的所有字段显示地写出来;
2、将多表关联查询结果中,相同的字段名取不同的别名;
SELECT o.id as oid, -- 订单表的id
order_number,
u.id as uid, -- 用户表的id
user_name,
password,
name,
age,
sex
FROM tb_order o
inner join tb_user u on o.user_id = u.id
where o.order_number = '20140921003'
resultMap中应该如下配置:
column 属性的值使用表查询字段的别名名称,如下:
<resultMap id="orderUserMap" type="Order" autoMapping="true">
<!-- 订单id别名为 oid ,pojo属性名为id-->
<id column="oid" property="id"/>
<association property="user" javaType="User" autoMapping="true">
<!-- 用户id别名为 uid ,pojo属性名为id-->
<id column="uid" property="id"/>
</association>
</resultMap>
【正确结果】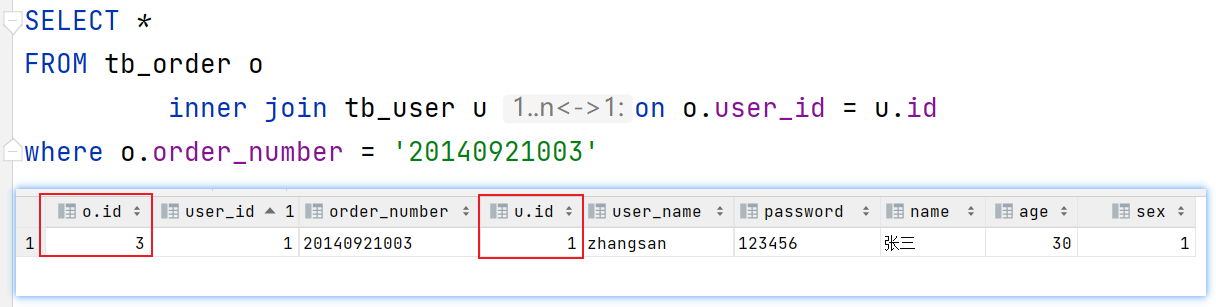
order = Order{id=3, orderNumber='20140921003', user=User{id=1, userName='zhangsan', password='123456', name='张三', age=30, sex=1}}
【小结】
- 多表查询步骤:
第一步:查询SQL分析;
第二步:添加关联关系(修改Pojo(JavaBean)类型);
第三步:编写接口方法;
第四步:编写映射文件;
第五步:测试
- 一对一关系
在Pojo A对象中包含一个Pojo B对象。
在A类定义B类型成员变量。
我们需要在resultMap中定义子标签association关联对象。
<resultMap id="orderUserMap" type="Order" autoMapping="true">
<!-- 订单id别名为 oid ,pojo属性名为id-->
<id column="oid" property="id"/>
<association property="user" javaType="User" autoMapping="true">
<!-- 用户id别名为 uid ,pojo属性名为id-->
<id column="uid" property="id"/>
</association>
</resultMap>
- 查询的字段中有重名字段,可以使用别名区分
4、一对多查询
【案例】
查询id为1的用户及其订单信息
【分析】
一个用户可以有多个订单。
用户(1)-----订单(n)
【步骤】
第一步:查询SQL分析; 第二步:添加关联关系; 第三步:编写接口方法; 第四步:编写映射文件; 第五步:测试
第一步:需求分析
编写SQL实现查询id为1的用户及其订单信息
查询语句及查询结果:
#一对多 内连接查询
select *
from tb_user tbu
inner join tb_order tbo on tbu.id = tbo.user_id
where tbu.id = 1;

第二步:添加关联关系
封装数据:关联对象,一个用户关联多个订单 User (List orderList)
因为一个用户可以拥有多个订单,所以用户和订单是一对多的关系,需要在User类中添加一个List<Order> 属性;
package com.itheima.pojo;
import java.io.Serializable;
import java.util.List;
public class User {
private Long id;
private String userName; // 用户名
private String password; // 密码
private String name; // 姓名
private Integer age; // 年龄
private Integer sex; //0-女 1-男
private List<Order> orders; // 用户对应所有
//此处省略 getter/setter/toString方法
}
第三步:编写接口方法
在UserMapper接口中,添加关联查询;
/**
* 根据用户id查询用户及其订单信息
* @param uid
* @return
*/
User getUserOrders(@Param("uid") Long uid);
第四步:编写SQL
- 一对多在resultMap中使用collection子标签进行关联
<resultMap ... > ... <collection property="类中引用多方的成员变量名" javaType="存放多方容器的类型" ofType="多方类型,就是集合中的类型" autoMapping="true"> ... </collection> </resultMap>
在UserMapper.xml文件中编写SQL语句完成一对多的关联查询;
注意:一定要记住这里给user表的id起别名是uid,order表的id起别名是oid.在resultMap标签的id子标签中的column属性值书写对应的uid和oid.
<!--自定义结果集-->
<resultMap id="userOrders" type="User" autoMapping="true">
<!--User的主键-->
<id column="uid" property="id"/>
<!--Order集合关联映射-->
<collection property="orders" javaType="List" ofType="Order" autoMapping="true">
<!--Order的主键-->
<id column="oid" property="id" />
</collection>
</resultMap>
<!--根据用户ID查询用户及其订单数据-->
<select id="getUserOrders" resultMap="userOrders">
SELECT
tbo.id as oid, -- 别称定义为oid
tbo.order_number,
tbu.id as uid, -- 别称定义为uid
tbu.user_name,
tbu.password,
tbu.name,
tbu.age,
tbu.sex
FROM
tb_user tbu
INNER JOIN tb_order tbo ON tbu.id = tbo.user_id
WHERE
tbu.id = #{uid}
</select>
第五步:测试
在用户的测试类UserMapperTest.java中添加测试方法:
@Test
public void getUserOrdersTest() {
User user = mapper.getUserOrders(1L);
System.out.println("user = " + user);
}
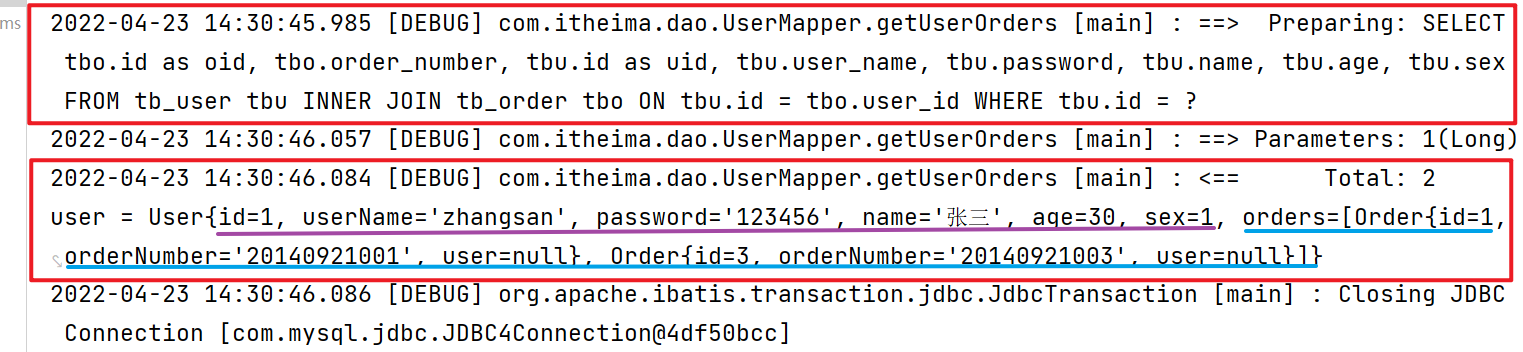
【小结】
1. 在一对多的场景中,一般主表中通过创建一个集合属性来包含从表的数据
例如,user类包含List
5、多对多
【案例】:查询订单号为20140921001的订单的详情信息,即查询订单信息+订单中的商品信息;
第一步:【需求分析】
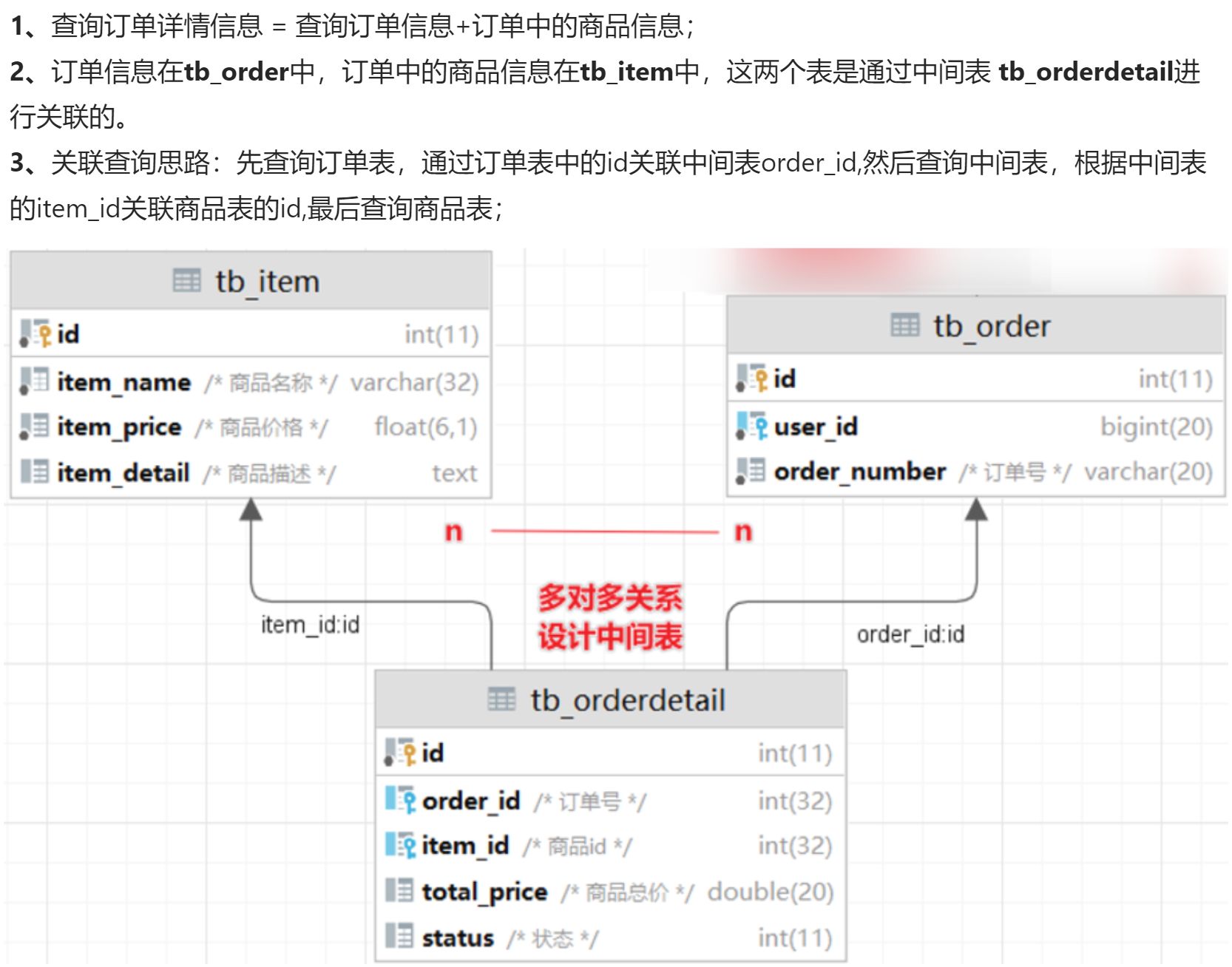
【SQL查询及结果】
# 【需求】:查询订单号为20140921001的订单的详情信息 订单的详情信息 = 订单+商品
SELECT * FROM
tb_order tbo
INNER JOIN tb_orderdetail detail ON tbo.id = detail.order_id
INNER JOIN tb_item item ON detail.item_id = item.id
WHERE
tbo.order_number = '20140921001';
第二步:添加关联关系
【修改Order】
一个订单表中关联了多个订单详情信息,所以在订单表中添加List<Orderdetail>属性:
【修改Orderdetail】
每一条订单详情记录中都包含了一条商品信息,所以需要在Orderdetail中添加一个Item属性;

第三步:编写接口方法
在OrderMapper接口中新增,根据orderNumber查询订单及订单详情的方法:
public interface OrderMapper {
Order getOrderDetail(@Param("orderNumber") String orderNumber);
}
第四步:编写SQL
说明:一定要记住这里给order表的id起别名是oid,订单详情表的id起别名是detailId,商品表item的id起别名是itemId。在resultMap标签的id子标签中的column属性值书写对应的oid、detailId和itemId.
<!--订单及订单详情结果集-->
<resultMap id="orderDetail" type="Order" autoMapping="true">
<!--订单表主键-->
<id property="id" column="oid"/>
<!--1个订单多个订单详情:detailList-->
<collection
property="detailList"
javaType="List"
ofType="Orderdetail"
autoMapping="true">
<!--tb_order_detail表 和 Orderdetail实体类-->
<!--订单详情主键 detailId表示下面sql语句的别名-->
<id property="id" column="detailId"/>
<!--关联商品对象 一对一:orderdetail-Item-->
<association property="item"
javaType="Item"
autoMapping="true">
<!--tb_item表 和 Item实体类 itemId 表示下面的sql语句别名-->
<id property="id" column="itemId"/>
</association>
</collection>
</resultMap>
<!--多对多查询-->
<select id="getOrderDetail" resultMap="orderDetail">
SELECT
tbo.id as oid,
tbo.order_number,
detail.id as detailId,
detail.total_price,
detail.status,
item.id as itemId,
item.item_detail,
item.item_name,
item.item_price
FROM
tb_order tbo
INNER JOIN tb_orderdetail detail ON tbo.id = detail.order_id
INNER JOIN tb_item item ON detail.item_id = item.id
WHERE
tbo.order_number = #{orderNumber};
</select>
第五步:测试
在OrderMapperTest测试类中添加方法
@Test
public void getOrderDetailTest() {
Order order = mapper.getOrderDetail("20140921001");
System.out.println("order = " + order);
}
【结果】
order = Order{id=1, orderNumber='20140921001', user=null, detailList=[Orderdetail{id=1, totalPrice=5288.0, status=1, item=Item{id=1, itemName='iPhone 6', itemPrice=5288.0, itemDetail='苹果公司新发布的手机产品。'}}, Orderdetail{id=2, totalPrice=6288.0, status=1, item=Item{id=2, itemName='iPhone 6 plus', itemPrice=6288.0, itemDetail='苹果公司发布的新大屏手机。'}}]}

6、ResultMap 继承
【需求】根据订单号(20140921001)
查询订单信息
查询订单所属用户信息
查询订单中的详细商品信息
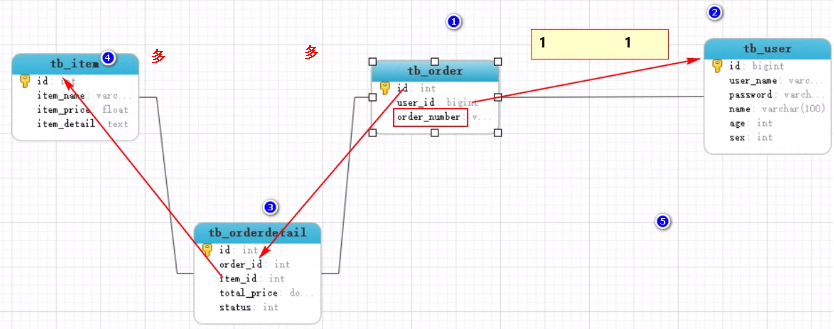
【SQL实现及查询结果】
通过分析,实现这个查询就在上面的查询基础上再关联一个一对一的User信息;
#查询订单详情
SELECT
tbo.id as oid,
tbo.order_number,
detail.id as detailId,
detail.total_price,
detail.status,
item.id as itemId,
item.item_detail,
item.item_name,
item.item_price,
tbu.id as uid,
tbu.age,
tbu.name,
tbu.password,
tbu.sex,
tbu.user_name
FROM
tb_order tbo
INNER JOIN tb_orderdetail detail ON tbo.id = detail.order_id
INNER JOIN tb_item item ON detail.item_id = item.id
INNER JOIN tb_user tbu ON tbo.user_id = tbu.id
WHERE
tbo.order_number = '20140921001';

【添加关联关系】
【编写接口方法】
在OrderMapper接口中再扩展一个方法:getOrderDetailAndUser
/**
* 根据orderNumber查询 订单,详情,商品及用户数据
* @param orderNumber
* @return
*/
Order getOrderDetailAndUser(@Param("orderNumber") String orderNumber);
【编写SQL】
<!--订单及订单详情结果集-->
<resultMap id="orderDetailAndUser" type="Order" autoMapping="true">
<!--tb_order表 和 Order实体类-->
<!--订单表主键-->
<id property="id" column="oid"/>
<!--Order-User:一对一关联-->
<association property="user" javaType="User" autoMapping="true">
<!--User主键-->
<id property="id" column="uid"/>
</association>
<!--多个订单详情 1对多:detailList-->
<collection property="detailList" javaType="List" ofType="Orderdetail" autoMapping="true">
<!--tb_order_detail表 和 Orderdetail实体类-->
<!--订单详情主键-->
<id property="id" column="detailId"/>
<!--关联商品对象 一对一:orderdetail-Item-->
<association property="item" javaType="Item" autoMapping="true">
<!--tb_item表 和 Item实体类-->
<id property="id" column="itemId"/>
</association>
</collection>
</resultMap>
<select id="getOrderDetailAndUser" resultMap="orderDetailAndUser">
SELECT tbo.id as oid,
tbo.order_number,
detail.id as detailId,
detail.total_price,
detail.status,
item.id as itemId,
item.item_detail,
item.item_name,
item.item_price,
tbu.id as uid,
tbu.age,
tbu.name,
tbu.password,
tbu.sex,
tbu.user_name
FROM tb_order tbo
INNER JOIN tb_orderdetail detail ON tbo.id = detail.order_id
INNER JOIN tb_item item ON detail.item_id = item.id
INNER JOIN tb_user tbu ON tbo.user_id = tbu.id
WHERE tbo.order_number = #{orderNumber};
</select>
【测试】
在OrderMapperTest测试类中添加测试方法
@Test
public void getOrderDetailAndUserTest() {
Order order = mapper.getOrderDetailAndUser("20140921001");
System.out.println("order = " + order);
}
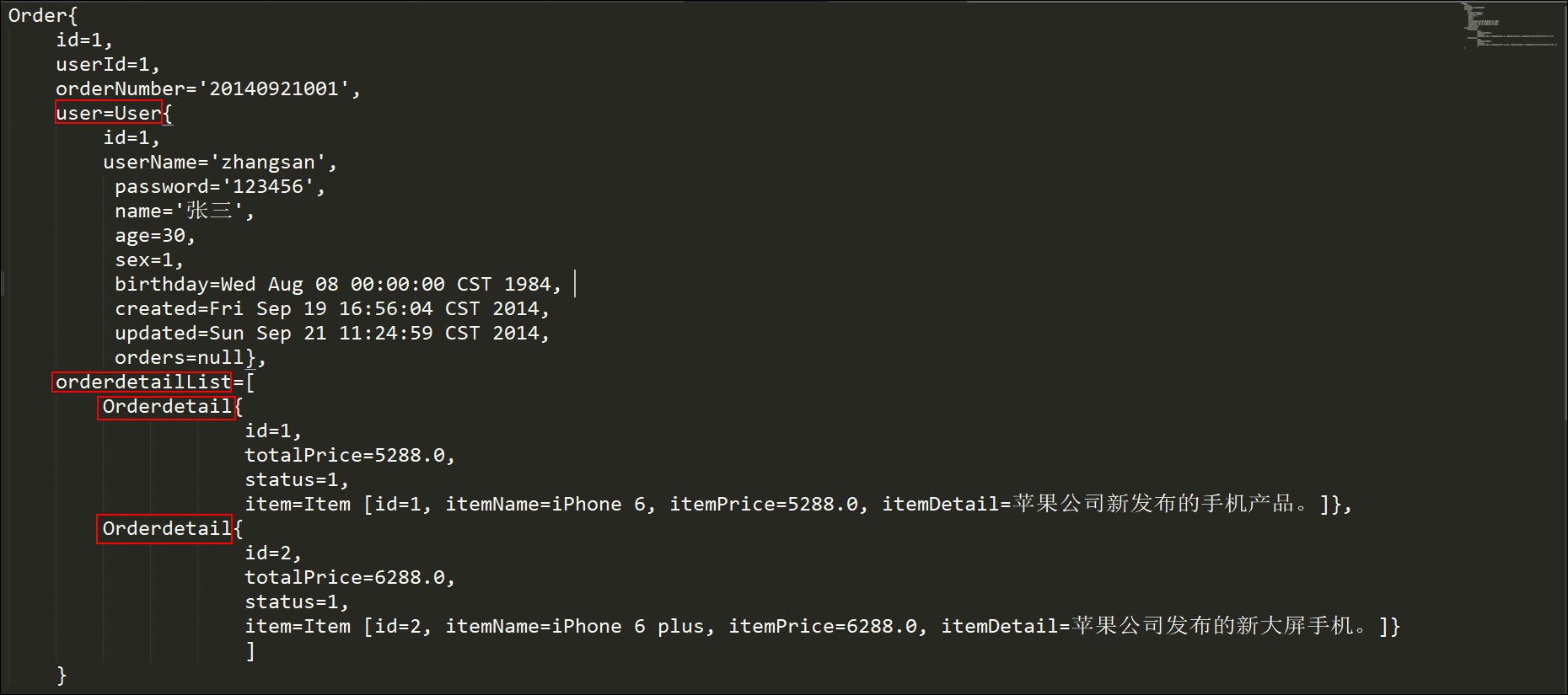
【结果】
order = Order{id=1, orderNumber='20140921001', user=User{id=1, userName='zhangsan', password='123456', name='张三', age=30, sex=1, orders=null}, detailList=[Orderdetail{id=1, totalPrice=5288.0, status=1, item=Item{id=1, itemName='iPhone 6', itemPrice=5288.0, itemDetail='苹果公司新发布的手机产品。'}}, Orderdetail{id=2, totalPrice=6288.0, status=1, item=Item{id=2, itemName='iPhone 6 plus', itemPrice=6288.0, itemDetail='苹果公司发布的新大屏手机。'}}]}
【resultMap继承】
如果两个结果集有重叠的部分,如下图所示。我们可以使用结果集继承来实现重叠的结果集的复用。
orderDetailAndUser结果集可以继承orderDetail结果集。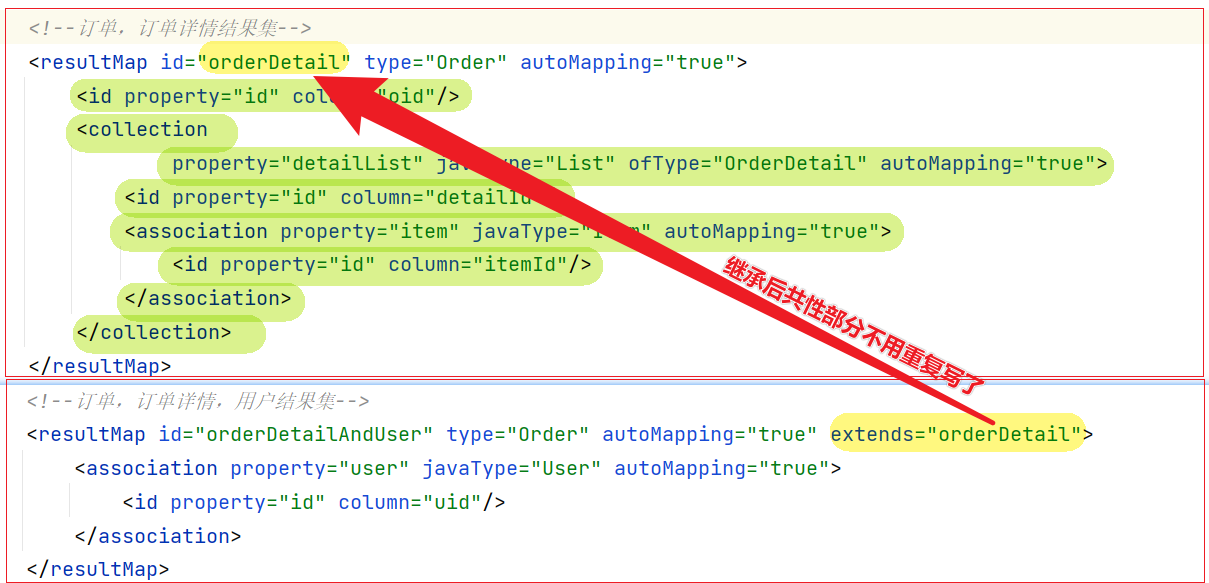
7、多表查询小结
resutlType
只能完成pojo属性名和字段名一样,或者符合驼峰及经典下划线命名转换。
剩余情况,名字不一样,没有驼峰和下划线之间的映射关系,多表查询涉及到数据的关联,只能使用resultMap来手动映射。
resultMap:
属性:
id 唯一标识,被引用的时候,进行指定
type 结果集对应的数据类型 Order
autoMapping 开启自动映射
extends 继承
子标签:
id:配置id属性
result:配置其他属性
association:配置一对一的映射
property 定义对象的属性名
javaType 属性的类型
autoMapping 开启自动映射
collection:配置一对多的映射
property 定义对象的属性名
javaType 集合的类型
ofType 集合中的元素类型 泛型
autoMapping 开启自动映射

若有收获,就点个赞吧
0 人点赞
