代码来自 PyTorch1.7.0 官方教程:https://pytorch.org/docs/1.7.0/optim.html
首先我们来回顾一下各类优化算法。
深度学习优化算法经历了 SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam -> AdamW 这样的发展历程。Google一下就可以看到很多的教程文章,详细告诉你这些算法是如何一步一步演变而来的。在这里,我们换一个思路,用一个框架来梳理所有的优化算法,做一个更加高屋建瓴的对比。
统一框架
首先定义:待优化参数:w ,目标函数:f(w) ,初始学习率 α。而后,开始进行迭代优化。在每个epoch 。
1 计算目标函数关于当前参数的梯度:
2 根据历史梯度计算一阶动量和二阶动量: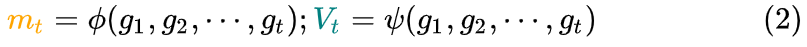
3 计算当前时刻的下降梯度:
4 根据下降梯度进行更新:
我们拿着这个框架,来照一照各种玄乎其玄的优化算法的真身。步骤3, 4对于各个算法都是一致的,主要的差别就体现在1和2上.
在所有优化器的代码里面有一些函数的作用是相通的:
共性的方法有:
- add_param_group(param_group):把参数放进优化器中,这在 Fine-tune 预训练网络时很有用,因为可以使冻结层可训练并随着训练的进行添加到优化器中。
- load_state_dict(state_dict):把优化器的状态加载进去。
- state_dict():返回优化器的状态,以dict的形式返回。
- step(closure=None):优化一步参数。
- zero_grad(set_to_none=False):把所有的梯度值设为0。
使用方法:
for input, target in dataset:def closure():optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()return lossoptimizer.step(closure)
SGD
代入步骤3,可以看到下降梯度就是最简单的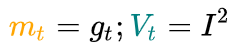
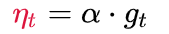
SGD最大的缺点是下降速度慢,而且可能会在沟壑的两边持续震荡,停留在一个局部最优点。
SGD with Momentum
为了抑制SGD的震荡,SGDM认为梯度下降过程可以加入惯性。下坡的时候,如果发现是陡坡,那就利用惯性跑的快一些。SGDM全称是SGD with momentum,在SGD基础上引入了一阶动量: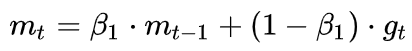
SGD with Nesterov Acceleration
SGD 还有一个问题是困在局部最优的沟壑里面震荡。想象一下你走到一个盆地,四周都是略高的小山,你觉得没有下坡的方向,那就只能待在这里了。可是如果你爬上高地,就会发现外面的世界还很广阔。因此,我们不能停留在当前位置去观察未来的方向,而要向前一步、多看一步、看远一些。
NAG全称Nesterov Accelerated Gradient,是在SGD、SGD-M的基础上的进一步改进,改进点在于步骤1。我们知道在时刻 的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算,那与其看当前梯度方向,不如先看看如果跟着累积动量走了一步,那个时候再怎么走。因此,NAG在步骤1,不计算当前位置的梯度方向,而是计算如果按照累积动量走了一步,那个时候的下降方向: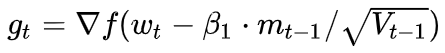
定义优化器:
CLASS torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
参数:
- params (iterable) – 优化器作用的模型参数。
- lr (float) – learning rate,相当于是统一框架中的 α。
- momentum (float, optional) – 动量参数。(默认值:0)
- weight_decay (float, optional) – 权重衰减系数 weight decay (L2 penalty) (默认值:0)
- dampening (float, optional) – dampening for momentum (默认值:0)
- nesterov (bool, optional) – 允许 Nesterov momentum (默认值:False)
AdaGrad
此前我们都没有用到二阶动量。二阶动量的出现,才意味着“自适应学习率”优化算法时代的到来。SGD及其变种以同样的学习率更新每个参数,但深度神经网络往往包含大量的参数,这些参数并不是总会用得到(想想大规模的embedding)。对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。
怎么样去度量历史更新频率呢?那就是二阶动量——该维度上,迄今为止所有梯度值的平方和: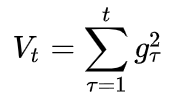
我们再回顾一下步骤3中的下降梯度:
二阶动量越大,学习率就越小。定义优化器
```python CLASS torch.optim.Adagrad(params,lr=0.01,lr_decay=0,weight_decay=0,initial_accumulator_value=0,eps=1e-10)
**参数:**- **params** (iterable) – 优化器作用的模型参数。- **lr** ([float](https://link.zhihu.com/?target=https%3A//docs.python.org/3/library/functions.html%23float)) – learning rate – 相当于是统一框架中的α 。- **lr_decay**([float](https://link.zhihu.com/?target=https%3A//docs.python.org/3/library/functions.html%23float),optional) – 学习率衰减 (默认值:0)- **weight_decay** ([float](https://link.zhihu.com/?target=https%3A//docs.python.org/3/library/functions.html%23float), optional) – 权重衰减系数 weight decay (L2 penalty) (默认值:0)- **eps**([float](https://link.zhihu.com/?target=https%3A//docs.python.org/3/library/functions.html%23float),optional):防止分母为0的一个小数 (默认值:1e-10)<a name="cAAqR"></a># AdaDelta / RMSProp由于AdaGrad单调递减的学习率变化过于激进,我们考虑一个改变二阶动量计算方法的策略:不累积全部历史梯度,而只关注过去一段时间窗口的下降梯度。这也就是AdaDelta名称中Delta的来历。<br />修改的思路很简单。前面我们讲到,指数移动平均值大约就是过去一段时间的平均值,因此我们用这一方法来计算二阶累积动量:<br />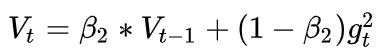<br />接下来还是步骤3:<br />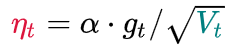<br />这就避免了二阶动量持续累积、导致训练过程提前结束的问题了。<a name="IOxck"></a>## RMSProp定义优化器```pythonCLASS torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
参数:
- params (iterable) – 优化器作用的模型参数。
- lr (float) – learning rate – 相当于是统一框架中的 α 。
- momentum (float, optional) – 动量参数。(默认值:0)。
- alpha(float,optional) – 平滑常数 (默认值:0.99)。
- centered(bool,optional) – ifTrue, compute the centered RMSProp, the gradient is normalized by an estimation of its variance,就是这一项是 True 的话就把方差使用梯度作归一化。
- weight_decay (float, optional) – 权重衰减系数 weight decay (L2 penalty) (默认值:0)
- eps(float,optional):防止分母为0的一个小数 (默认值:1e-10)
Adam
谈到这里,Adam 和 Nadam 的出现就很自然而然了——它们是前述方法的集大成者。我们看到,SGD-M 在SGD 基础上增加了一阶动量,AdaGrad 和 AdaDelta 在 SGD 基础上增加了二阶动量。把一阶动量和二阶动量都用起来,就是 Adam 了——Adaptive + Momentum。
SGD 的一阶动量: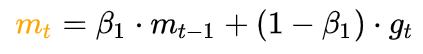
加上 AdaDelta 的二阶动量:
优化算法里最常见的两个超参数 β1和β2 就都在这里了,前者控制一阶动量,后者控制二阶动量。Nadam
最后是Nadam。我们说Adam是集大成者,但它居然遗漏了Nesterov,这还能忍?必须给它加上,按照NAG的步骤1: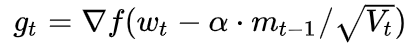
这就是Nesterov + Adam = Nadam了。定义优化器
```python CLASS torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
- **params** (iterable) – 优化器作用的模型参数。- **lr** ([float](https://link.zhihu.com/?target=https%3A//docs.python.org/3/library/functions.html%23float)) – learning rate – 相当于是统一框架中的 α 。- **betas**(Tuple[[float](https://link.zhihu.com/?target=https%3A//docs.python.org/3/library/functions.html%23float),[float](https://link.zhihu.com/?target=https%3A//docs.python.org/3/library/functions.html%23float)],optional) – coefficients used for computing running averages of gradient and its square ((默认值:(0.9, 0.999))- **weight_decay** ([float](https://link.zhihu.com/?target=https%3A//docs.python.org/3/library/functions.html%23float), optional) – 权重衰减系数 weight decay (L2 penalty) (默认值:0)- **eps**([float](https://link.zhihu.com/?target=https%3A//docs.python.org/3/library/functions.html%23float),optional):防止分母为0的一个小数 (默认值:1e-10)<a name="ru1Mv"></a># AdamW下图1所示为Adam的另一个改进版:AdamW。<br />简单来说,AdamW就是Adam优化器加上L2正则,来限制参数值不可太大,这一点属于机器学习入门知识了。以往的L2正则是直接加在损失函数上,比如这样子:加入正则,损失函数就会变成这样子:<br />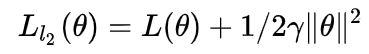<br />所以在计算梯度 gt 时要加上粉色的这一项。<br />但AdamW稍有不同,如下图所示,将正则加在了绿色位置。<br /><a name="cUyDz"></a>## 定义优化器```pythonCLASS torch.optim.AdamW(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.01, amsgrad=False)
参数:
- params (iterable) – 优化器作用的模型参数。
- lr (float) – learning rate – 相当于是统一框架中的 α 。
- betas(Tuple[float,float],optional) – coefficients used for computing running averages of gradient and its square ((默认值:(0.9, 0.999))
- weight_decay (float, optional) – 权重衰减系数 weight decay (L2 penalty) (默认值:0)
eps(float,optional):防止分母为0的一个小数 (默认值:1e-10)
实践
从实践上,很多热门工作使用adamW,例如Bert还有最近的一些vision transformer代表作使用的都是AdamW优化器
- 其他人的经验:训练内容理解模型的时候(例如各种CV,NLP,AUDIO encoder的时候)常用Adam家族的优化器,但是FCN模型(例如推荐系统的信号融合阶段)常用SGD家族的优化器。

若有收获,就点个赞吧
0 人点赞
