RNN
主要用于处理时序序列的神经网络接口,主题结构是一个全连接的神经网络,因为循环使用中间权重矩阵处理隐藏层之间的关系,因此而得名。也因为这种结构,使得能学习到上游信息(优势),但是也有缺陷:一个依赖问题,一个是效率问题。

如果把上面有W的那个带箭头的圈去掉,它就变成了最普通的全连接神经网;现在我们来看看W是什么。循环神经网络的隐藏层的值h不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值h。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
https://zhuanlan.zhihu.com/p/30844905
LSTM的问题
在RNN的基础上加入Cell组件,利用三个门控机制,控制保留信息,解决RNN的长依赖问题。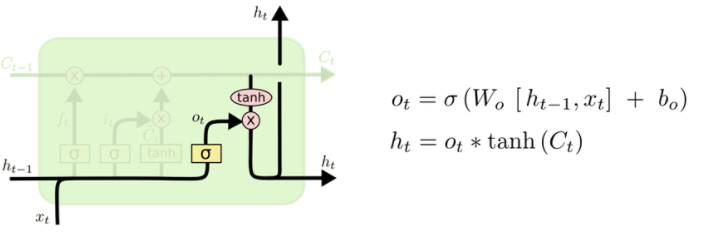
小结:输入门、遗忘门、输出门所对应的函数都是 sigmoid 函数,因此输出的结果是[0, 1],当为0时,门完全关闭,当为1时,门完全打开。输入门控制当前输入值有多少信息流入到计算中,遗忘门控制上一个细胞中有多少信息流入到后续细胞或计算中,在获得了输入门和遗忘门系数之后就可以更新当前的细胞状态,Ct-1 更新为 Ct 。输出门控制着输出值中有多少信息流入到隐层中。所有LSTM除了有三个门来控制当前的输入和输出,其他的和RNN是一致的。
LSTM模型有两个隐藏状态 ht , Ct ,模型参数几乎是RNN的4倍,因为现在多了 Wf, Uf, bf, Wa, Ua, ba, Wi, Ui, bi, Wo, Uo, bo 这些参数。
前向传播过程在每个序列索引位置的过程为:
1)更新遗忘门输出:ft = σ (Wf ht-1 + Uf xt + bf)
2)更新输入门两部分输出:it = σ(Wi ht-1 + Ui xt + bi); at = tanh(Wa ht-1 + Ua xt + ba)
3)更新细胞状态:Ct = Ct-1 ft + itat
4)更新输出门输出:
ot = σ(Wo ht-1 + Uo xt + bo)
ht = ot tanh(Ct)
5)更新当前序列索引预测输出:yt = σ(V ht + c)
*tanh和sigmoid的作用:
1)因为 Sigmoid 函数的输出值范围为0-1,相当于控制门的百分比过滤
2)tanh输出是[-1,1],在输入门和输出门中均有使用,是为了控制该该次输入x因素对结果是正向还是负向的。
https://www.cnblogs.com/yifanrensheng/p/12662577.html
LSTM对比RNN做了哪些改进
由于RNN梯度消失的问题,因此很难处理长序列的数据,大牛们对RNN的机构做了改进,得到了RNN的特例长短期记忆网络LSTM(Long Short-Term Memory)和其它变形,可以从结构上避免常规RNN的梯度消失。 效果上优于RNN
当然也有缺陷:LSTM学习的参数更多,因此计算时间会更长。
LSTM和GRU的区别
另一个改动较大的变体是 Gated Recurrent Unit (GRU),这是由 Cho, et al. (2014) 提出。它将遗忘门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。

若有收获,就点个赞吧
0 人点赞
