fasttext
softmax的公式,层次softmax和负采样等
见onenote 340DL的【NLP-03】同步主要的如下:
简单的
- softmax:[a,b,c,d,e]——>[进行一系列归一化处理,得到最终的概率】因此计算一个概率,必须要得到k个类别的概率
- 层次softmax:思想是 直接根据哈弗曼树得到概率 【logk次分类问题】
「这里使用霍夫曼树来代替隐藏层和输出层的神经元,霍夫曼树的叶子节点起到输出层神经元的作用,所有叶子节点就类似于之前神经网络softmax输出层的神经元,叶子节点的个数即为词汇表的大小,而内部节点则起到隐藏层神经元的作用。」
第一步:Hierachical Softmax的基本思想就是首先将词典中的每个词按照词频大小构建出一棵Huffman树,保证词频较大的词距离根节点进,词频较低的词到根节点远,每一个词都处于这棵Huffman树上的某个叶子节点;
第二步:沿着霍夫曼树一步步采用了二元逻辑回归的方法找到词对应的概率-本质是二叉树中从根节点开始,经过一系列中间的父节点,最终到达当前这个词的叶子节点而组成,那么在每一个父节点上,都对应的是一个二分类问题(本质上就是一个LR分类器)。使得计算量为分类数量(比如word2vec中的词数量)的对数级别,即log(V),而普通的softmax,势必要求词典中的每一个词的概率大小,为了减少这一步的计算量。计算量是单词V的级别。
「负例采样的思想其实和层次Softmax很类似,也是将Softmax多分类问题转化成多次二分类问题,使用二元逻辑回归可以让一个训练样本每次仅仅更新一小部分的权重,不同于原本每个训练样本更新所有的权重,这样大大减少了梯度下降过程中的计算量。」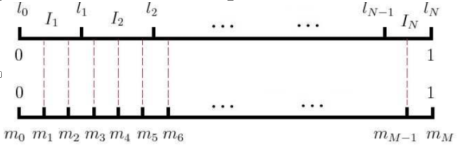
「对高频词汇进行降采样避免对于这些低信息词汇的无谓计算,同时避免高频词汇对模型造成过大的影响」,降低高频词的采样概率。如下: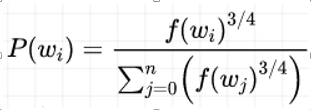
小结:
- 层序softmax使用了二叉树,并根据根结点到叶结点的路径来构造损失函数。其训练中每一步的梯度计算开销与词典大小的对数相关。
- 负采样通过考虑同时含有正类样本和负类样本的相互独立事件来构造损失函数。其训练中每一步的梯度计算开销与采样的噪声词的个数线性相关。
从实验角度来看:当数据量很大时:一般采用Skip-gram,数据量小时:一般用CROW
细节问题
1 为什么fastText甚至可以为语料库中未出现的单词产生词向量
因为fastText是通过包含在单词中的子字符substring of character来构建单词的词向量,正文中也有论述,因此这种训练模型的方式使得fastText可以为拼写错误的单词或者连接组装的单词产生词向量。简单说直接拆分出来的char n-gram 表达直接平均相加作为新词本身的词向量。
2 在模型训练时遇到了NaN,为什么会这样
这种现象是可能出现的,很大原因是因为你的学习率太高了,可以尝试降低一下学习率直到不再出现NaN
3 为什么fastText甚至可以为语料库中未出现的单词产生词向量
fastText一个重要的特性便是有能力为任何单词产生词向量,即使是未出现的,组装的单词。主要是因为fastText是通过包含在单词中的子字符substring of character来构建单词的词向量,正文中也有论述,因此这种训练模型的方式使得fastText可以为拼写错误的单词或者连接组装的单词产生词向量
和word2vec的区别
见onenote 340DL的【NLP-06】fastText文本分类算法,同步主要的如下:
相同点:图模型结构很像,都是采用embedding向量的形式(这里我理解是训练过程中产生这种效果,不是指输入时,因为Word2Vec输入时one-hot编码),得到word的隐向量表达。
- 都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
- 都有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的target,隐含层都是对多个词向量的叠加平均。
之前一直不明白fasttext用层次softmax时叶子节点是啥,CBOW很清楚,它的叶子节点是词和词频,看源码可知,其实fasttext叶子节点里是类标和类标的频数。
| Word2Vec | fastText | |
|---|---|---|
| 输入 | one-hot形式的单词的向量 | embedding过的单词的词向量和n-gram向量 |
| 输出 | 对应的是每一个term,计算某term概率最大 | 对应的是分类的标签 |
| 类型 | 无监督学习 | 有监督学习 |
Glove与Word2vec比较:
- Word2vec是局部语料库训练的,其特征提取是基于滑窗的;而glove的滑窗是为了构建co-occurance matrix(上面详细描述了窗口滑动的过程),统计了全部语料库里在固定窗口内的词共线的频次,是基于全局语料的,可见glove需要事先统计共现概率;因此,word2vec可以进行在线学习,glove则需要统计固定语料信息。
- Word2vec是无监督学习,同样由于不需要人工标注,glove通常被认为是无监督学习,但实际上glove还是有label的,即共现次数log(X_i,j)
- Word2vec损失函数实质上是带权重的交叉熵,权重固定;glove的损失函数是最小平方损失函数,权重可以做映射变换。
- Glove利用了全局信息,使其在训练时收敛更快,训练周期较word2vec较短且效果更好。

若有收获,就点个赞吧
0 人点赞
