
bert的介绍
BERT(Bidirectional Encoder Representations from Transformers),是Google2018年提出的预训练模型,即双向Transformer的Encoder,将模型深度提升到24。模型的主要创新点都在pre-train方法上,即用了Masked LM(MLM,借用了CBOW的上下预测中心的思虑,也是双向的)和Next Sentence Prediction(NSP)两种方法分别捕捉词语和句子级别的representation。下游任务中表现很好,主要得益于深度提取,即transform提取器;双向语义信息提取;embedding注入位置信息等。
具体而言,通过三种embedding(token,segment,position),输入到multi-attention,再经过残差连接和layer normlization。送入feed forword层(把 8 个矩阵降为 1 个,首先把 8 个矩阵连在一起,这样会得到一个大的矩阵,再随机初始化一个矩阵和这个组合好的矩阵相乘,最后得到一个最终的矩阵),通过迭代N层,送入到下游任务中训练。
transformer
一句话简介:2017年(Atention is all you need)引出,采用了 从N==6个Encoder(2个子层)-Decoder(3个子层)架构,ADD&Norm层使得NLP中深度能够搭建起来,包含几个重要组件:Self-Attention,Multi-Headed Attention(8个矩阵,类似CNN中的多个卷积核)以及FFN,masked mutil-head attetion,LN,Positional Encoding这些组件。主要的贡献点在:Multi-Headed Attention,LN,Positional Encoding,ADD&Norm(类残差结构)
transformer-xl
这篇文章介绍的Transformer-XL(extra long)则是为了进一步提升Transformer建模长期依赖的能力。它的核心算法包含两部分:片段递归机制(segment-level recurrence)和相对位置编码机制(relative positional encoding)。Transformer-XL带来的提升包括:1. 捕获长期依赖的能力;2. 解决了上下文碎片问题(context segmentation problem);3. 提升模型的预测速度和准确率。
以克服Transformer的长距离获取弱的缺点。
片段递归机制:segment做了缓存,可供当前segment使用,通过空间换时间,移动一个segment,提高速度和效果;
相对位置编码:是为了处理上述绝对位置编码重复带来的问题。主要是加入R_i-j 来处理的。
参考:
https://www.zhihu.com/tardis/landing/m/360/art/84159401
https://www.zhihu.com/tardis/landing/m/360/art/271984518
self-attention的计算
Self Attention顾名思义,可以理解为Target=Source这种特殊情况下的注意力计算机制。
计算流程
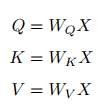
上面的公式可以看出,self-Attention中的Q是对自身(self)输入的变换,而在传统的Attention中,Q来自于外部。
Attention计算公式及复杂度

https://blog.csdn.net/Jeremy_lf/article/details/115874662
除以d的原因
1、首先要除以一个数,防止输入softmax的值过大,导致偏导数趋近于0;
2、选择根号d_k是因为可以使得q*k(原来的方差为d)的结果满足期望为0,方差为1的分布,类似于归一化。
作用
引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序列计算,对于远距离的相互依赖的特征,要经过若干时间步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。另外其优点如下:
1) 可以并行化处理,在计算self-Attention是不依赖于其他结果的。
2)计算复杂度低,self-Attention的计算复杂度是,而RNN是,在这里n是指序列的长度,d是指词向量的维
3)self-Attention可以很好的捕获全局信息,无论词的位置在哪,词之间的距离都是1,因为计算词之间的关系时是不依赖于其他词的。在大量的文献中表明,self-Attention的长距离信息捕捉能力和RNN相当,远远超过CNN。
为什么要多头注意力
Multi-Head Attention主要有两个作用:
- 增加了模型捕获不同位置信息的能力,如果你直接用映射前的Q, K, V计算,只能得到一个固定的权重概率分布,而这个概率分布会重点关注一个位置或个几个位置的信息,但是基于Multi-Head Attention的话,可以和更多的位置上的词关联起来。
- 因为在进行映射时不共享权值,因此映射后的子空间是不同的,认为不同的子空间涵盖的信息是不一样的,这样最后拼接的向量涵盖的信息会更广。
残差结构作用
主要就解决网络退化问题(模型退化:深层模型反而取得更高的训练和测试误差):在神经网络可以收敛的前提下,随着网络深度增加,网络的表现先是逐渐增加至饱和,然后迅速下降。另外:错误信号可以不经过任何中间权重矩阵变换直接传播到低层,一定程度上可以缓解梯度弥散问题
1)中间层矩阵权重很小,梯度也基本不会消失)。综上,可以认为残差连接使得信息前后向传播更加顺畅。
何恺明等人从前后向信息传播的角度给出了残差网路的一种解释:在前向传播时,输入信号可以从任意低层直接传播到高层。由于包含了一个天然的恒等映射,一定程度上可以解决网络退化问题。
2)集成学习的角度:残差网络就可以被看作是一系列路径集合组装而成的一个集成模型,其中不同的路径包含了不同的网络层子集。Andreas Veit等人展开了几组实验(Lesion study),在测试时,删去残差网络的部分网络层(即丢弃一部分路径)、或交换某些网络模块的顺序(改变网络的结构,丢弃一部分路径的同时引入新路径)。实验结果表明,网络的表现与正确网络路径数平滑相关(在路径变化时,网络表现没有剧烈变化),这表明残差网络展开后的路径具有一定的独立性和冗余性,使得残差网络表现得像一个集成模型(ensemble)。
3)梯度破碎的角度。2018年的一篇论文指出了一个新的观点,尽管残差网络提出是为了解决梯度弥散和网络退化的问题,但它解决的实际上是梯度破碎问题。梯度破碎就是在标准前馈神经网络中,随着深度增加,梯度逐渐呈现为白噪声的现象,即神经元梯度的相关性(corelation)按指数级减少;同时,梯度的空间结构也随着深度增加被逐渐消除。因为现在基于梯度的许多优化方法假设梯度在相邻点上是相似的,所以破碎的梯度会使这些优化方法的效果大打折扣。而残差连接可以极大地保留梯度的空间结构,缓解了梯度破碎问题。2018年有一篇可视化的论文支持这一说法,作者比较了Res56网络带残差模块和不带残差模块的损失函数三维图,不带残差模块的损失函数表面是一片怪石嶙峋,而带残差模块的损失函数表面像一片平缓的山丘,更有利于优化。
BERT后期为何将残差放到内部
GPT,ELMO,BERT区别
GPT和BERT采用了transform提取器,但是BERT使用了双向提取:具体为Mask LM的选择填空训练,另一个采取encoder部分,GPT采用的是decoder的去掉中间层的方式。
ELMO和BERT区别:都采用了双向语义信息,ELMO使用双向LSTM形式,BERT采用transform形式。ELMo采取双向拼接这种融合特征的能力可能比 Bert 一体化的融合特征方式弱
GPT 预训练时利用上文预测下一个单词,ELMO和BERT是根据上下文预测单词,因此在很多 NLP 任务上,GPT 的效果比 BERT 要差。但是 GPT 更加适合用于文本生成的任务,因为文本生成通常都是基于当前已有的信息,生成下一个单词。
MLM
中 对于在数据中随机选择 15% 的标记,其中80%被换位[mask],10%不变、10%随机替换其他单词,原因是什么?
因为Bert用于下游任务微调时, [MASK] 标记不会出现,它只出现在预训练任务中。这就造成了预训练和微调之间的不匹配,微调不出现[MASK]这个标记,模型好像就没有了着力点、不知从哪入手。所以只将80%的替换为[mask],但这也只是缓解、不能解决。这也是实验数据
bert 双向体现
首先我们指导BERT的预训练模型中,预训练任务是一个mask LM ,通过随机的把句子中的单词替换成mask标签, 然后对单词进行预测。
个人觉得另一个双向体现在使用呢transformer的encoder部分
这里注意到,对于模型,输入的是一个被挖了空的句子, 而由于Transformer的特性, 它是会注意到所有的单词的,这就导致模型会根据挖空的上下文来进行预测, 这就实现了双向表示, 说明BERT是一个双向的语言模型
layer Normalization 和BN的区别
LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
1、BN是对batchsize范围内数据进行处理,也就是一批次的一个特征维度进行normalization,图像任务中,因为输入维度是大小相同的像素点。NLP任务中可能会由于句子长度不一,导致信息表达紊乱。具体坏处有两点:
- 对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布;
- BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的特征
2、LN是对单个样本数据进行处理,不会出现上述问题。
因此:原始BN是为CNN而设计的,对整个batchsize范围内的数据进行考虑,而对于RNN以及transformer等等处理文本序列信息的模型来说,BN会变得非常复杂,而LN是对单个样本就可以进行处理,更加方便简单,自然选择用LN了。
layer Normalization 用途
- 一定程度解决神经网络的难题之一:梯度消失和梯度爆炸的问题(多个链式求导中存在的问题);
- 让每一层attention和feed-forward模块的输入值,均是经过归一化的,保持在一个量级上,从而可以加快收敛速度。
bert的变形
小的变形:见后面议题:比如albert,PKD,等
大的变形:
XLNet2019年发掘的自回归模型,采用预训练和下游微调方式处理NLP任务;解决动态语义问题,借鉴了Transformer-XL;借用XL中片段循环机制提高长依赖程度;排列语言建模(序列因式分解得到N!这种情况,双流自注意力解决引发的问题)达到保留了序列的上下文信息,也避免了采用mask标记位。算是一个当前有效技术的集成体。结合Bert、GPT 2.0和Transformer XL的综合体变身:
- 首先,它通过PLM(Permutation Language Model)预训练目标,吸收了Bert的双向语言模型;
- 然后,GPT2.0的核心其实是更多更高质量的预训练数据,这个明显也被XLNet吸收进来了
- 引入了Transformer-XL的主要思路:相对位置编码以及分段RNN机制。实践已经证明这两点对于长文档任务是很有帮助的
T5使用text-to-text思想,在清出的 750 GB 大数据上做大量实验(70多个),取众家所长:采用span masking的方式,mask 15% token,span平均长度为3;无监督中混入有监督数据;
Roberta在bert的基础上,使用更大模型参数,更大的batch size,更多的训练数据(160G);方法上去掉NSP,使用动态掩码,BPE编码(是字符级和单词级表示的混合),在多项任务中超越了之前的模型。
有哪些方法减小模型
而目前模型变小的技术大概有几种:
- 模型量化:即把float值变为int8,可以直接将模型降为原来的四分之一。速度也会有提高。
- 矩阵分解:大矩阵分解为小矩阵的乘积去拟合,可以显著降低size。
- 结构改动:比如更多的参数共享,更高效的层次计算等。
-
哪些方法加快预测
使用小模型或模型蒸馏形式
- ONNX Runtime转换提速:
- 将Pytorch模型转为ONNX格式,再用ONNX Runtime 进行推理,可以显著提速。实验结果,单条数据在CPU上的推理提速约3倍。
- 优化ONNX模型在OpenMP上运行加速显著。
- 量化效果提速显著。在ONNX上进行量化,大约可以继续提速2倍,最终取得5.5ms的模型推理性能。
- https://zhuanlan.zhihu.com/p/322545446
-
模型蒸馏如何进行
知识蒸馏是让一个小模型去学习一个大模型,所以首先会有一个预训练好的大模型,称之为Teacher模型,小模型被称为Student模型。知识蒸馏的方法就是会让Student模型去尽量拟合。Teacher模型的输出概率分布包含着更多的信息,从Teacher模型的概率分布中学习,能让Student模型充分去模拟Teacher模型的行为。
在具体的学习Teacher模型概率分布这个过程中,知识蒸馏还引入了温度的概念,即Teacher和Student的logits都先除以一个参数T,然后再去做softmax,得到的概率值再去做交叉熵。温度T控制着Student模型学习的程度,当T>1时,Student模型学习的是一个更加平滑的概率分布,当T<1时,则是更加陡峭的分布。因此,学习过程中,T一般是一个逐渐变小的过程。Teacher模型经过温度T之后的输出被称之为soft labels。
Soft labels的计算过程如下,Pt中的t代表的是Teacher模型,同样的,Student模型的输出也要经过类似的计算。
得到Teacher模型和Student的模型后,就可以计算知识蒸馏这部分的损失,得到LDS;然后student模型除了向teacher模型学习外,还需要向ground truth学习,得到LCE,然后再让两个损失去做加权平均。
PKD论文中先做了对比,减少模型宽度和减少模型深度,得到的结论是减少宽度带来的efficiency提高不如减少深度来的更大,因此,PKD主要关注减少模型深度。即Student模型比Teacher模型要浅。论文所提出的多层蒸馏,即Student模型除了学习Teacher模型的概率输出之外,还要学习一些中间层的输出。论文提出了两种方法,第一种是Skip模式,即每隔几层去学习一个中间层,第二种是Last模式,即学习teacher模型的最后几层。 论文记过显示,Skip一般会比Last模式要好。这是因为,Skip方式下,层次之间的距离较远,从而让student学习到各种层次的信息。
而更好的teacher模型不会带来增长。把12层的Bert模型换成了24层的Bert模型,反而导致效果变差。究其原因,可能是因为在实验中,我们使用Teacher模型的前N层来初始化Student模型,对于24层模型来说,前N层更容易导致不匹配。而更好的方法则是Student模型先训练好,再去学Teacher模型。
DistillBert的做法就比较简单直接,同样的,DistillBert还是保证模型的宽度不变,模型深度减为一半。主要在初始化和损失函数上下了功夫: 损失函数:采用知识蒸馏损失、Masked Language Model损失和cosine embedding损失加起来的值。
- 初始化:用Teacher模型的参数进行初始化,不过是从每两层中找一层出来。
蒸馏方法
具体可见ontnote笔记部分
| 模型名称 | 瘦身方式 | 主要方法 | 效果 | 备注 |
|---|---|---|---|---|
| DistilBERT | 蒸馏 | Teacher 12层,student 6层,每两层去掉一层; Loss= 5.0Lce+2.0 Lmlm+1.0* Lcos |
DistilBERT 比 BERT 快 60%, 体积比 BERT 小 60% |
2019年10月,HuggingFace |
| Distil-LSTM | 蒸馏 | 将bert蒸馏到BiLSTM中; hard target和soft target进行训练; |
参数量减少了100倍 速度提升了15倍 |
2019年5月 |
| TinyBERT | 蒸馏 | 1. 制作任务相关数据集; 1. fine-tune teacher BERT; 1. 固定 teacher BERT 参数,蒸馏得到 TinyBERT |
在 GLUE 上,比 BERT性能下降 3 个点 但推理性快了 9 倍多 |
2019年9月,华为诺亚 |
| FastBERT | 蒸馏 | 自适应机制: 每层Transformer后都去预测样本标签 |
Speed=0.2时速度可以提升1-10倍 且精度下降全部在0.11个点 |
ACL2020 北大+腾讯+北师大的 |
| BERT-PKD | 蒸馏 | 学习中间层和最后层的内容, 而不是仅仅学习最后一层 |
相比较KD,性能提升不少, 比原始的bert较差 |
|
| MobileBERT | 蒸馏 | 带反瓶颈结构(inverted-bottleneck)的近似BERT_large 的网络(IB-BERT),再训练其学生网络 |
保留24层的情况下,减少了4.3倍的参数,速度提升5.5倍, 在GLUE上平均只比BERT-base低了0.6个点 |
ACL2020,google |
| MiniLM | 蒸馏 | 蒸馏teacher模型最后一层Transformer自注意力; values之间的缩放点击运算; 引入助教模型蒸馏 |
参数相同下: 在多数任务上MiniLM都优于DistillBERT和TinyBERT |
2020 微软研究院, |
albert
采用矩阵分解,参数共享减低参数,使用SOP(sentence order prediction)替换nsp,segments-pair,变长mask,更宽的模型,去dropout来提升效果。
SOP
- NSP:下一句预测, 正样本=上下相邻的2个句子,负样本=随机2个句子(来自不同的文档)
- SOP:句子顺序预测,正样本=正常顺序的2个相邻句子,负样本=调换顺序的2个相邻句子
NSP任务过于简单,只要模型发现两个句子的主题不一样就行了,所以SOP预测任务能够让模型学习到更多的信息
模型规模
真的超越bert-large的是albert-xxlarge,把H从1024扩大到了4096,由于all-shared策略,不断加深albert不能带来提升,所以从宽度上进行扩展。Bert-lagre使用了24层,albert-large使用12层。整体看,albert的总参数是BERT的70%,当然使用albert-xlarge也是一个不错的选择。内存要少很多。
bert和albert 的成效
采用FT16精度,bert替换成albert
- 显存大小从400M降低到20M,速度提升1.7被,推理速度提升2.3倍。
- albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
复现论文
基于bert做些复现。。
bert的输入和transformer的输入有何区别
transformer的输入:position embedding 和 token embedding ;bert:多了Segment Embeddings用来区别两种句子
position embedding不同:猜测是bert训练数据较大,因此会可以通过自学习的方式来进行。
- 固定编码。;transformer是Sinusoidal(固定的正余弦函数),通过奇数列cos函数,偶数列sin函数方式,利用三角函数对位置进行固定编码。
- 动态训练。BERT采用了这种方式。先随机初始化一个embedding table,然后训练得到table 参数值。predict时通过embedding_lookup找到每个位置的embedding。这种方式和token embedding类似。

若有收获,就点个赞吧
0 人点赞
