1. 存储模型
1.1 行数据的物理存储结构
- 行格式:COMPACT…
- (额外信息)对这行数据进行一定描述的头字段:变长字段的长度列表,null值列表,数据头
- 这行数据每一列的具体的值:column 01的值,column 02的值…
- VARCHAR 变长字段,怎么存储?
- 可变字段长度列表中的长度是以十六进制存储;
- 如果变长字段的值是 NULL,就不用在变长字段长度列表里存放它值的长度;
- 一行有多个变长字段,变长字段的长度列表中逆向存储这些字段的长度,例如:
- VARCHAR(10)VARCHAR(5)VARCHAR(20) CHAR(1) CHAR(1),hellohihao a a
- 0x030x020x05 null值列表 头字段 hellohihao a a
- Null 字段,怎么存储?
- Null 值是以二进制 bit 位存储;
- 所有允许值为 Null 的字段(不一定说值就是 Null),在null值列表里都会有一个二进制bit位的值,1 就是 null,0 就是非null;
- 多个字段的话,在 null 值列表中按逆序存储;
- 实际 null 值列表存放时,长度一般是8个bit位的倍数,如果不足8个bit位的就高位补0,例如:
- 字段信息:
- name VARCHAR(10) NOT NULL,address VARCHAR(20),gender CHAR(1),job VARCHAR(30),school VARCHAR(50)
- 行数据:
- jackNULL mNULL xx_school (null列表 1010,逆向存储:0101,补0:00000101)
- 实际存储格式:
- 0x090x04 00000101 头信息 column1=value1 column2=value2 … columnN=valueN
- 字段信息:
- 像上面格式的行存储,怎么读出来?
- 先读取可变字段长度列表和 null 值列表,分析出有几个变长字段,哪几个变长字段是 null;
- 解析出不为 null 的可变字段的长度,那几个字段是 null;
- 40个 bit 位的数据头
- 用来描述这行数据的一些状态和附加信息;
- 第一个bit位和第二个bit位,都是预留的,没有含义;
- 下一个 bit 位是 delete_mask,标识这行数据是否被删除(删除一行数据,未必立马把它从磁盘中清理掉);
- 下一个 bit 位是 min_rec_mask,B+树里每一层的非叶子节点里的最小值都有这个标记;
- 下一个 bit 位是 n_owned,记录一个记录数;
- 下一个 bit 位是 heap_no,当前这行数据再记录堆里的位置;
- 下三个 bit 位是 record_type,描述这行数据的类型,0代表的是普通类型,1代表的是B+树非叶子节点,2代表的是最小值数据,3代表的是最大值数据;
- 最后16个bit位是 next_record,指向下一条数据的指针;
- 实际数据,怎么存储?
- 由两部分组成:
- 字符串和其他类型的数值最终都会根据数据库指定的字符集进行编码,转成一些数字和符号存储在磁盘上;
- 加入一些隐藏字段
- DB_ROW_ID 字段,数据库内部自己生成的一行的唯一标识(不是主键ID),没有指定主键和 unique key 唯一索引的时候,他就内部自动加一个 ROW_ID 作为主键;
- DB_TRX_ID 字段,标识这是哪个事务更新的数据,事务ID;
- DB_ROLL_PTR 字段,回滚指针,用来进行事务回滚的;
- 由两部分组成:
- 磁盘上的每一行数据,就是类似下面这样的:
- 0x09 0x04 00000101 0000000000000000000010000000000000011001 00000000094C(DB_ROW_ID)00000000032D(DB_TRX_ID)EA000010078E(DB_ROL_PTR) 616161 636320 6262626262
行溢出
一个 16KB 的数据页拆分成了多个部分,其中空白数据页没有数据行区域,填满的数据页中空闲空间被消耗完,没有了:
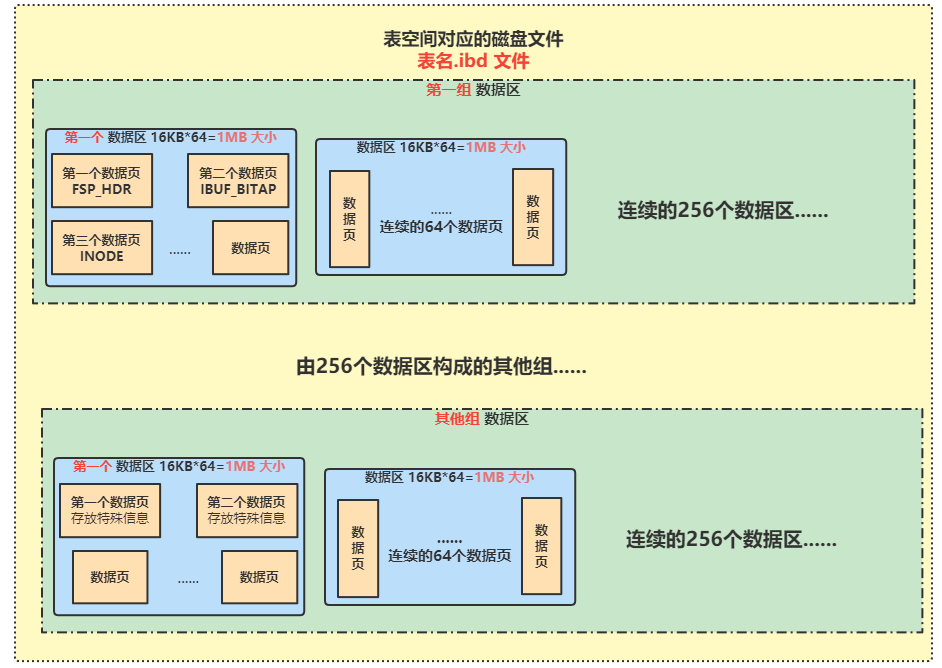
每个表都有一个表空间概念,表空间对应的就是磁盘上的数据文件;
- 系统表的表空间对应着多个数据文件;自己创建的表的表空间,在磁盘上对应的就是 “表名.ibd” 这样的一个磁盘数据文件;
- 数据区:
- 一个表空间由很多的数据区组成,一个数据区对应着64个连续的数据页,即每个数据区的大小为 64*16KB=1MB;
- 256个数据区构成一个数据区组;
- 表空间的第一组的第一个数据区的前三个数据页都是固定的,放一些描述性的数据,例如 FSP_HDR、IBUF_BITMAP、INODE;
- 表空间的其他组的第一个数据区的前两个数据页,放一些特殊信息用来描述这组数据区的;
2. 存储模型与 Buffer Pool 结合回顾读写机制
- 如何插入一条数据?
- 根据表找到一个表空间,找到表空间后,就可以定位到 表名.ibd 磁盘文件;
- 找到磁盘文件,就可以找到一个数据区组,接着找到一个数据区,然后找到一个数据页出来,这个数据页可能是空的,也可能已经放了一些数据行了;
- 把这个数据页从磁盘文件里完整的加载出来,放入 Buffer Pool 的缓存页中;
- 读取数据页的时候,指定磁盘文件里的开始位置和截至位置,就能读取出来指定位置的一段数据,这段数据就是一个数据页包含的内容了;
- 接着 curd 操作直接针对缓存页去执行,会自动把更新的缓存页加入 flush 链表,然后更新它在 LRU 链表的位置,包括更新过的缓存页会从 free 链表里拿出来,等等一系列操作;
- 对于那些更新过的缓存页,会由后台线程刷入磁盘;
- 写入数据页和读取数据页类似,选择好固定的一段位置的数据,直接把缓存页的数据覆盖掉磁盘上原来的那个数据页;

若有收获,就点个赞吧
0 人点赞
