(1) 案例问题
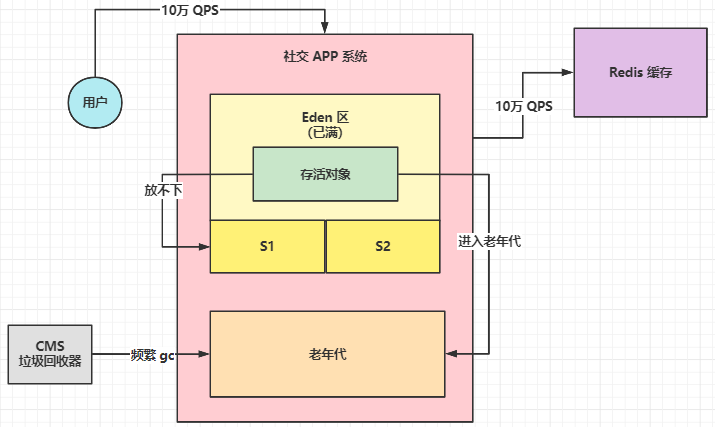
- 高并发可达到10万 QPS,Eden 区迅速被填满,触发 Young GC,之后因为有很多请求还没处理完毕,会有很多对象存活下来;
- 发现存在 Survivor 放不下存活对象的问题,大量存活对象进入老年代中;
- 老年代的新增速率太快,频繁触发 Full GC;
- 频繁的 Full GC 导致大量内存碎片,如果不及时内存整理,会提高 Full GC 频率;
(2) 优化思路
- 核心的思路
- 增加机器,减少每台机器的负载压力;
- 调大年轻代的 Survivor 空间,每次 Young GC 后尽量让存活对象停留在 Survivor,别进老年代;
- 优化方案:
- 通过 jstat 分析各个机器上的 JVM 的运行状态,判断每次 Young GC 后存活对象有多少,增加相应的 Survivor 内存,避免存活对象快速进入老年代;
- 增加了年轻代和 Survivor 的大小,发现还是慢慢有对象进入老年代,如果每小时一次 Full GC,那么在高负载的场景下,是可以接收的频率;
- 针对 CMS 内存碎片的优化:
- 降低 Full GC 的触发频率后,设置如下参数,使每次 Full GC 后都整理一下内存碎片;
-XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0
- 降低 Full GC 的触发频率后,设置如下参数,使每次 Full GC 后都整理一下内存碎片;
- 通过 jstat 分析各个机器上的 JVM 的运行状态,判断每次 Young GC 后存活对象有多少,增加相应的 Survivor 内存,避免存活对象快速进入老年代;

若有收获,就点个赞吧
0 人点赞
