1.线性代数 + 概率统计2.理解随机变量和分布之间的关系
1.没有标签的训练是无监督学习2.利用打了标签的数据集进行训练是监督学习:我们拿出一组打了标签的数据集,我们知道每一个图片的答案,然后我们建立一个模型,用数据对模型进行训练,最终得到我们的算法。
在机器学习里面,算法不是我们人工设计出来的,那么算法是怎么来的呢?1.首先是有了数据集,即DataSet。2.然后,我们要做的,就是从数据集里把我们想要的算法给它找出来。这就是一个机器学习的过程。
1.首先你需要有数据集2.然后就是拿数据集去训练3.训练完了之后进行验证,如果好用的话,那我们就可以去部署了
1.机器学习的算法来自于数据,而不是来自于我们人工的设计。
2.机器学习里用的主要是基于统计的一些方法。比如说很多优化的目标函数都是来自于最大似然,最大后验。
深度学习是机器学习里的一个分支。
1.所谓的表示学习,实际上是特征的提取,就是说我们原始的数据,它可能非常的大,每一个数据样本它里
面的数据特征非常的多,我们想用一种更好的办法来表示这个数据样本的信息,这就叫表示学习。
2.那么表示学习里面呢,比如像以前传统的神经网络里有浅层的自动编码器(Shallow autoencoders),然
后呢,除了浅层(自动编码器(Shallow autoencoders))之外,深层的就叫做Deep learning,
Deep learning如果从模型上来算,它用的是神经网络,但是从目标上来看,它是属于表示学习的分支。
深度学习里面也有很多不同的方法,比如有多层感知机(MLPs),然后还有很多,比如卷积神经网络,循环神经网络,各种各样的架构
1.数据输入进来,然后进行手工设计来提取特征(手工特征提取,有的是比较简单的,比如我们发现
数学和英语对于下一个学习的物理成绩影响很大,那么我们直接就把这两个数据筛选出来;)
这个输入有可能是关系型数据表当中的一个记录,也有可能是一个无结构的数据,比如是一段语音,
一段波形,一段文字,或者是一张图片,我们最终要把它变成向量(或者是变成一个张量)
2.然后我们把向量(张量)和我们输出之间建立出一个映射的函数。
就是说这个向量是我们真正的输入x,输出是y,换句话说就是找到y=f(x)的映射,这就是咱们这个Mapping,
所以咱们之前讲的那个线性的模型,包括感知机,然后还有神经网络,实际上都是在做这么一个工作。
1.不用人工参与提取特征的过程,提取原始数据特征的过程也是学习出来的。
2.表示学习里面,它的最主要的改进,就是这个Features,它的提取,我们更希望这个Feature的提取方法,
最好也能学习出来,
在早期的时候,Feature的提取,它实际上是单独的一个步骤,我们用一些(特殊的)算法,然后来把一个非常
复杂的非结构的输入数据里面提取出一个向量,然后再把这个向量扔到Mapping from features里面。
向量x(即特征),如果它的维度太高,那么根据大数定律,在在统计里面,你采样越多,你和这个数据真实的
分布就越贴近。
比如说现在你这个数据只有一个feature。一个feature对应一维空间
也就是说你在一维空间里面采样,采了10个样本,对于这个例子来说这个密度就已经足够了。
假如你在有两个feature的空间里面采样,两个feature就变成x1,x2,变成了一个平面
这个时候,你要进行采样,必须在这两个维度的密度上都达到10,那么这里面的点一共有10²。
也就是说你需要100个点,这样的话,你的密度才可以和它对应。满足这个密度,你才能够说
我的采样数据,满足大数定律,我能够表示原始数据的分布。
大数定律
通过采样的数据能够代表原始数据的分布。
对于大部分的学习器来说,都是这样,就是说你的维度越高,你对数据的需求就越大,但是收集数据本身,
的工作量是非常大的。你比如说我们要收集图片,给这些图片打标签,我们说这个图片里面是什么,
那就得雇人专门看完图片打一个标签,看完图片打一个标签。你才能把这个数据集做出来,这个是你需要
雇很多人的,所以说数据集是很贵的,尤其是打了标签的数据集。成本很高。
这个就叫做维度的诅咒。
即维度越高,所需要的数据量越大。而我们在做很多业务的时候,我们没有办法获得这么多的数据。
解决方案:
降低维度。
通过线性变换,将高维度转换到低维度,但是在降维的过程中,你不能把10维空间里不同的点都映射到
3维空间(三维空间里是有三个点的)里面的一个点上,我们希望尽量保持高维空间里面的度量信息。
原来,你要训练专门的特征提取器,现在在深度学习里面,我们就用非常简单的特征,
什么叫非常简单的特征呢?
就是就把它做成一些原始性的特征,然后直接把它拿进来,
什么叫原始特征?比如你有一张图片,那我们把这个图片里的像素值变成一个张量,然后我们把它拿进来。
那如果这是一段语音,那你这个语音不是波形吗?我就把波形序列拿进来。
如果你是二维关系表格,数据库里的一条记录,那我就把整个记录拿进来,当然拿进来的时候,我们要做
一点变换,比如数据库里有些值,它不是数值,它是离散的,那这里我们要做基本的处理,
做一些非常简单的变换,
拿进来之后,我们要设计一个独立的(额外的)层来提取特征,然后接入到学习器,最后输出。
学习器一般就是多层神经网络,就可以胜任这个任务。
传统的方法{
里面,features这个部分,和这个学习器,是分开训练的,就是Features单独去训练,
就是机器学习里面的无监督学习,其中有很多的工作就是来做Features的训练,然后就是
Features提取的训练,因为它没有标签,所以它肯定是无监督学习的方法;
然后就是Mapping from features(学习器),学习器是有标签的。
}
层与层之间是紧密相连接的,这一层的输出是下一层的输入,中间无任何处理过程的。?
深度学习里面,这些训练过程是统一的,所以我们把Deep learning的过程,叫做End To End,端到端的
训练过程,
那也就是说我们把数据从input拿进来,然后整个一系列过程,一直到输出,我们构建一个非常大的模型,
然后对整个模型来进行训练,这就是深度学习系统和以前的差别。
神经网络处理信息是分层的。
分层的感知(即线层神经网络识别低级特征,深层神经网络识别高层特征)
对于神经网络来说,最重要的一个算法,能够让神经网络工作起来的算法,叫做Back Propagation,
反向传播。
反向传播实际上就是求偏导数。
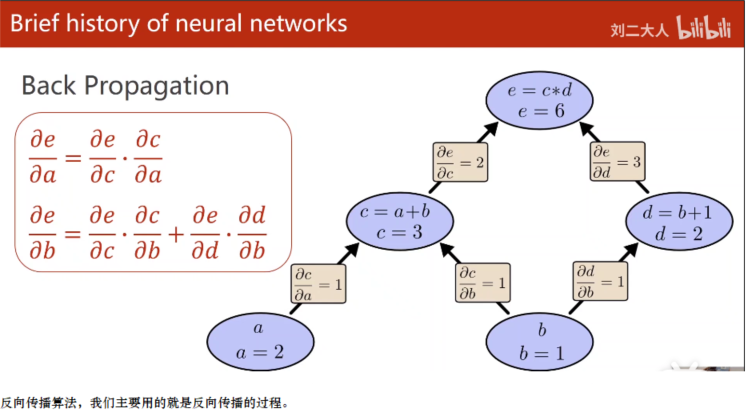
反向传播的核心叫做计算图。
你比如说我们现在有这样一个计算,这个计算是什么呢?
我们有两个输入量:a和b,其中a,b可以看作输入量,也可以看作是权重,然后我们现在呢,
想要求(a与b经过一系列的计算可以得到e )
在计算图里面,每一步计算的时候,我们每一步只能进行一些原子计算,原子计算就是最简单的运算,
我们不再把它进行分割的计算,就叫做原子计算。
在深度学习框架里面,我们可以发现有大量的原子运算,比如矩阵的乘法,基本的卷积运算,
都是它所支持的原子运算。
对于节点c来说,它的原子计算就是加法,对于节点d来说,它的原子计算也是加法。但是实际上它里面是有
一个常量1,当然这个常量,我们是不需要求导数的,所以我们就可以把它省略的。
接下来呢,c和d两个节点,它要经过乘法运算,然后得到最终的结果,我们就构建出这样一个计算图。
然后计算图计算的过程,先是正向计算,比如a = 1 ,b = 2;c = a+b=3,d=b+1=3;e = c*d=9,这是前馈
过程,我们在计算图的时候,我们注意c=a+b,那刚才在做前馈的时候,
你实际上就可以求c对a的偏导 = 1,以及c对b的偏导 = 1,
你在求d的时候,d比b的偏导你也求出来了,等于1,
我们拿c节点和d节点去算e节点的时候,那e对c的偏导为3,e对d的偏导等于c,它的值等于3.
即正向计算,会计算出最后的y值,以及y到特征x路径上的各个位置偏导数。
反向传播,就是计算出y值与各个特征的导数。
比如这里就是e对a的导数,e对b的导数。
关键是学会一些构造模型的套路,然后你去构造自己的模型,也就是说你要学会一些基本块怎么实现,
最后把它们组装起来。
所以这里面,我们做深度神经网络开发的时候,有点像什么呢,就是说我们知道一些基本块怎么用,就
好像这是一些基本语句或者结构,我们要用一些(比如ResNet看成是if结构),然后呢,
我们循环神经网络可以看成是一个循环结构,接下来呢,还有一些块呢,我们可以把它看成是基本的语句,
然后你把它变成一段代码的过程。
所以我们在学神经网络的时候,我们要学一些基本块怎么做,然后你要做的工作,就是针对你的任务,来
把这些东西进行组装,来适合你要完成任务的目标。
第一个就是算法层面的进展,深度学习的算法越来越多,各种各样的算法,它们解决了很多不同的问题,
(比如这一章节,我们学的是反向传播的算法)
然后第二点,就是数据集,我们获得的越来越丰富,数据集的量也越来越大,
第三点,就是算力上的提升,算力主要是就是英伟达显卡,
1.深度学习其实并不难
基本上只要你有基本的线性代数,概率论数理统计,和python你就能胜任深度学习的系统开发了。
不超过一年的时间,你就能上手。上手的速度很快。
2.刚才讲的那些计算图的算法,我们是不需要自己去实现的,都是用现成的Deeping learning的框架,
用这些框架里面实现的图算法,来帮我们构建深度学习模型。
这些现有的框架都能非常高效方便的使用GPU。使用你的显卡。你就不需要直接去和CUDA打交道。
框架已经提供了大量的神经网络的基本构件。比如像卷积,循环的神经网络模块,它都已经提供了,
所以我们在构建神经网络的时候,速度和效率会非常高。很快就能把它搭建出来。
Pytorch 用的是动态图,动态图就是说你运算的时候,你一边做计算,你的图构建出来,等你一算完,
你把图就释放了。
依据计算图,做前馈过程(算预测值和偏导数);然后依据损失函数根据预测值与实际y值算损失。
一个batch_size算一次平均损失,然后根据平均损失,还有反向传播(传递偏导数)算出y对特征的导数。
动态调整权重,这样图又被构建了。之后又可以依据新的计算图算预测值和损失值。
所以你每一次都可以构建出不同的图,所以这对于写神经网络来说,是非常方便的。
我们可以构建非常灵活的工作模型。
1.模型,图算法,反向传播,前馈这些都是Pytorch已经提供了的。---暂时这么认为。
模型的训练(学习)就是依据计算图中算出的y对特征的导数,还有损失值,动态地调整计算图。(每一个
batch_size就调整一次),一直调整到我们通过可视化工具观察到哪个位置(训练和测试)的损失值都为
最低。
2.损失函数的选择

若有收获,就点个赞吧
0 人点赞
