梯度下降算法的作用
梯度下降算法,是我们用来对模型训练的时候,训练模型的时候使用的一种最常用的这样一种算法。
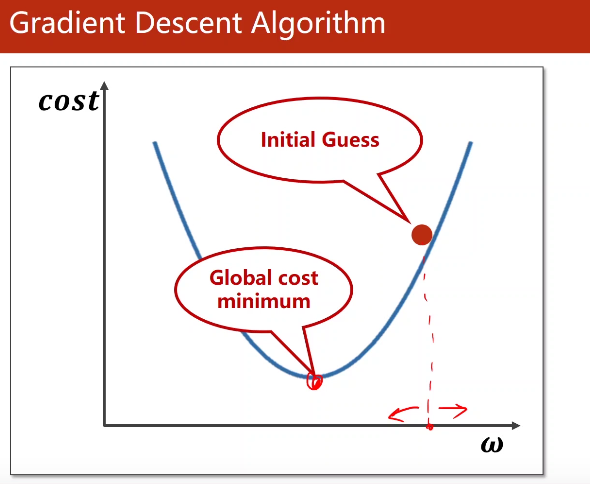
求解最优点
我们在求最优点的时候,我们用观察法(穷举)也好,还是分治法也好,它的缺陷都是非常明显的。
求解最优值的算法
即随机梯度下降算法
我们在这里面就把我们要找使目标函数最小的这种权重组合,这样的一个任务,我们就叫做优化问题,
优化函数就是要解决这个问题。
我们可以通过梯度定义来确定这个问题(往哪个方向走),也就是说,我们梯度的定义实际上就是用目标
函数对权重进行求导数,这样就求到了它的上升方向,
比如拿一元函数来说,你对x求导,它等于 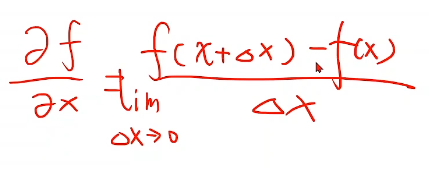
这里面满足 ,这是已知的。
,这是已知的。
如果导数为正—->说明x+▲x,目标函数值上升,用在我们这个场景,也就是损失函数值上升;
如果导数为负—->说明x+▲x,目标函数值下降,用在我们这个场景,也就是损失函数值下降(我们所期望的)。
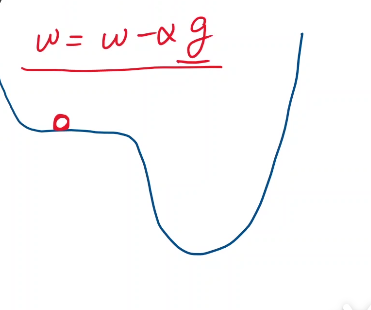
这里的x,用在我们的场景中,就是权重w。而我们发现,如果我们想要w一直往函数值下降的方向走,
那么我们就需要w = w + 导数的反方向
即
上图,就是我们用来更新权重的方法。α是学习率,肯定是正数。
特征的值是不变的
我们如果想要函数值下降的话,我们就得取导数的负方向。负的导数方向,就是我们往最小值走的方向。
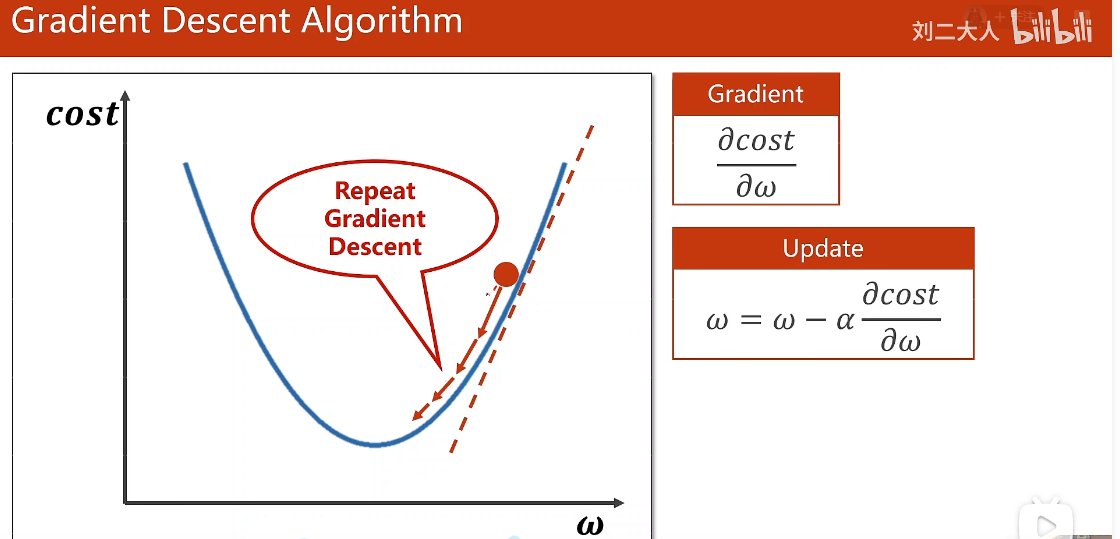
梯度定义
梯度的定义实际上就是用目标函数对权重进行求导数
学习率
α就是学习率。这个学习率表示你要往前走多远,这个学习率我们一般要取的比较小,
因为如果你的学习率取的比较大,就有可能一下子跑这里,一下子跑那里去了,所以
我们学习率要取的小一点。
梯度下降算法的本质
贪心算法。
用梯度下降算法也是,不一定得到最优的结果,但是能得到局部区域最优的结果。
所以我们用梯度下降算法,我们只能保证我们找到局部最优,我们没有办法找到全局最优。
全局最优点:没有任何一个局部最优点能够比它的函数值更小,那我们就把它叫做全局最优。
为什么,我们在深度学习里面会大量使用梯度下降作为咱们最基本的算法呢?
这是因为深度神经网络,它的目标函数,以前大家认为里面有很多的局部最优点,我们训练
的时候会陷入到局部最优,
但实际上,大家后来发现在神经网络里面,它的损失函数当中,并没有非常多的局部最优点,就是说
局部最优点很少,我们很难陷入到局部最优点。
鞍点
在鞍点这个位置,它的梯度等于0,如果你是多元的,就表示是一个0向量。如果是一元函数就是梯度为0,
梯度为0的这种鞍点,比如说像这样的一个函数:
这个地方它是没有局部最优点的,但是我们用梯度下降进行优化的时候,如果我们到达了这个位置,
它会没有办法再继续进行迭代,为什么呢?
因为我们的公式是 权重 = 权重 - α*梯度。现在如果梯度等于0,0乘α还是0,所以你的每一次更新
都没有用,那就意味着将来到了这个位置之后,它就走不动了,
它就陷入到鞍点这个位置,没有办法运动了。

从这个方向上看是最小值,但是从另外一个方向上看是最大值。就有点像马鞍。
从这个切面上看,它是最小值,但是从这个切面上看,它是最大值。这个点,我们就把它叫做鞍点。
深度学习里面我们要解决的问题
我们要解决的最大问题并不是局部最优,局部最优还是比较容易克服的;
最大的问题还是要解决鞍点的问题。因为如果你陷入到鞍点里面,那导致你是没有办法再继续进行迭代的。
梯度下降算法核心公式
指数加权均值,来把cost function变为一个更为平滑的
训练失败的情况
如果你将来训练的时候,画cost function走着走着变成这样了:<br /><br />那就说明你的训练发散了,它是没有办法收敛的,那有人就会说,是不是这儿的最低就是我们训练的最小值呢,不是,因为正常情况下,我们训练的时候肯定是趋近于这样的收敛情况:<br />
对于训练集来说,如果你能上去,说明训练发散了,这次训练失败了,训练失败的原因有很多,其中一种
常见的原因,就是学习率取的太大,你可以把学习率取的低一点,来观察下训练的过程。
这个就是使用梯度下降,实际上我们在深度学习的训练里面,梯度下降用的还是挺少的,我们用的是
梯度下降的衍生版本---随机梯度下降。
随机梯度下降
梯度下降算法,更新权重,是拿整个的损失。也就是所有数据的平均平方损失作为梯度下降的更新依据
即总体损失函数对w求导。--->公式(解析式)--->转化为代码
如下图


为什么要使用梯度下降呢?
现在的损失函数
是因为这样的原因:我们之前讲函数,可能长成这样一个形式,它是带有鞍点的损失函数,如果你整个cost func 长成这个样子,你到这个位置呢,你是没有办法再往前走的,cost func是所有的样本
算出来的,那么如果你每次只用其中的一个样本,因为我们拿到的数据基本是有噪声的,有噪声就引入了一个随机噪声,也就是即使陷入到了鞍点,但是随机噪声可能会把我们向前推动,那么引入了
这种随机性之后,将来在更新的时候就有可能跨越过这个鞍点,来向最优值前进,而且随机梯度下降在神经网络里面被证明是非常有效的方法。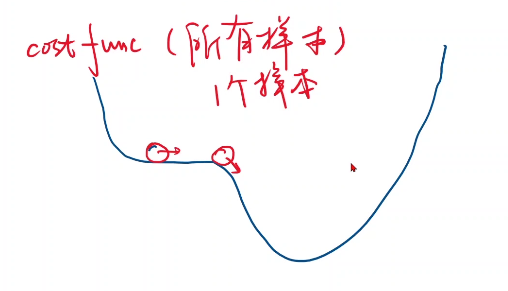
即如果用所有数据的,那么所有数据的算出来的导数一旦等于0,那么下一次也肯定还是0。
如果是随机选择的数据,可能这一次是0,下一次就不是0了。—-破除鞍点
随机梯度下降中计算该梯度的公式,你不需要吧所有样本的损失求出来然后求均值,你只需要把一个样本的均值求出来就行了:<br />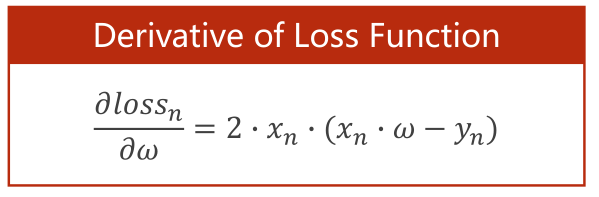
梯度下降与随机梯度下降做对比
但是我们在相应的深度学习里面,我们会遇到这样一个问题:如果你去用梯度下降,这里面有好多的数据样本,你在算梯度的时候,对于每一个样本x,你在用模型(前馈)给它计算的时候,注意:你计算f(xi)和
计算f(xi+1),它们是没有互相依赖关系的,因为你计算xi的函数值和计算xi+1这个点的函数值是没有依赖关系的,所以这些运算是可以并行的。—-因为大家此时是用的同一个w。
但是如果我们用了随机梯度下降,你要计算g(xi)即xi的梯度,然后你在这里面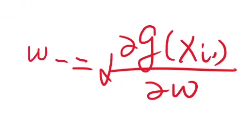 ,这个w是要去做更新的,接下来在计算x(i+1)的梯度的时候,用的就是更新后的w
,这个w是要去做更新的,接下来在计算x(i+1)的梯度的时候,用的就是更新后的w
,所以这个样本的梯度下降和下一个样本的梯度下降,它们之间是不能并行化的,它们之间是有依赖的。
那也就是意味着如果我们用并行化的计算优势,梯度下降算法效率是最高的,但是我们用随机梯度下降,虽然性能比较好(能找到更优的点),但是它的运算性能,时间复杂度太高,因为它没法利用并行性。
所以我们在深度学习里面,会用一种折中的方式,就是你把整个数据集都用上,然后这样去做,它会非常的方便,用并行算法算的很快,但是呢,它不如分成一个一个样本这样去算,这样最终
我们能拿到的最优值更好;
但是你要一个一个去算的话,时间复杂度就高,就是说,从性能(学习器的性能)上来说,把整个数据集都用上的方法性能会比较低,分成一个一个样本的方法性能会比较高,
从时间复杂度上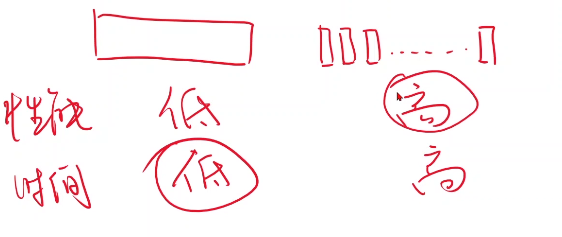
注意,这里面,对于性能来说,越高越好;对于时间复杂度来说,越低越好,所以我们在深度学习里面,我们就可以在性能和时间复杂度里取一个折中,这个折中叫做Batch,
什么叫做Batch呢?就是批量的随机梯度下降,批量的随机梯度下降指的是什么呢?你全都扔到一起,性能不好;你全都把它分开,那时间复杂度不好,那怎么办呢?
我就若干个一组,若干个一组,我就每次用这个一组样本去求相应的梯度,然后进行更新,我们在深度学习里面,默认采用的随机梯度下降(SGD),就是使用Batch这种方法,
但是Batch呢,原始的含义里面,我们提到Batch指的是全部的,所以更正式的名字叫做Mini-Batch,我不用所有数据集里的数据,我用小批量的,但是现在呢,因为我们
在深度学习里面,都是用Mini-Batch,所以有的时候,我们会看到很多接口里面,会直接把Mini取掉,就是说我们这次要拿一个Batch,下次要拿一个Bacth,但是你要知道
在原有的学习算法里面,这个Batch是指的全体,它不是指的Mini-Batch,但是因为现在Mini-Batch是主流,所以我们现在说到Batch指的都是Mini-Batch,而不再指的全部的
数据了。
总结:
训练过程使用随机梯度算法对权重(各个特征的权重)进行更新:
第一步:计算mini-Batch的梯度
第二步:w = w - 学习率*梯度

若有收获,就点个赞吧
0 人点赞
