卷积层是干什么呢?
卷积层是我们要保留这个图像它的空间特征,保存它的空间结构。这个卷积神经网络是把这个图像直接按照原始的空间结构进行保存。经过了一个卷积层之后,我们得到的这个图像,你先注意它的输出,它的通道会变,它的图像的宽度和高度也会变,当然可以变,也可以不变;使用下采样的时候,我们这个通道数是不变的。
为什么要做下采样呢?
降低维度(接入到分类器的时候的维度)
降低维度;因为最终我们的卷积层(特征提取器)输出,肯定是一个一阶张量,那么其维度是直接
由Batch.view(Batch_size,-1)直接掰过来的。
那展开之后呢,我们就得到了这样一个线性的,只有向量的这样一种输入,然后接下来我们再用全连接层,
最终我们把它映射到10维的输出,然后我们就可以再接上交叉商损失,利用Softmax去计算它的分布,
最终,我们就可以去解决分类问题。
构建一个神经网络的时候
首先第一点,你要明确的是什么呢?
你的输入,它的张量的维度是什么?
你的输出它的张量维度是什么?
然后你想让网络正常跑起来,咱们先不说性能,咱们就说正常的工作。
就是你要利用这些各种层,然后进行维度上,或者是每个维度上尺寸大小的变化,
最终把它映射到我们想要的输出的空间里面,构建一个神经网络的时候
卷积和全连接的本质
所以实际上不管是卷积也好,还是全连接也好,我们都是在做这样一种空间变换。
特征提取器
神经网络里面前面的卷积还有下采样,我们把它叫做特征提取器,Feature Extraction,
就是我们能通过这个卷积运算,在里面找到某种特征,
前面的卷积,下采样这些工作,我们把它叫做Feature Extraction(特征的提取),后面的这些,我们叫做Classification(分类器)
在特征提取器这个阶段,我们是直接对图像做卷积运算的,然后提取完特征之后,我们再把它转换成向量,然后再利用一个全连接的网络去给它做分类
分类器
后面的全连接网络,实际上你经过特征提取之后,你把它变成了一个向量,然后拿这个向量去接一个
比较典型的全连接网络,然后我们去做分类,
卷积要做的
只要我们权重选的合适,我们就能从
这些信息(它就代表对这个里面某种特征的扫描,满足这个特征,它算出来的值就比较大,
不满足值就比较小
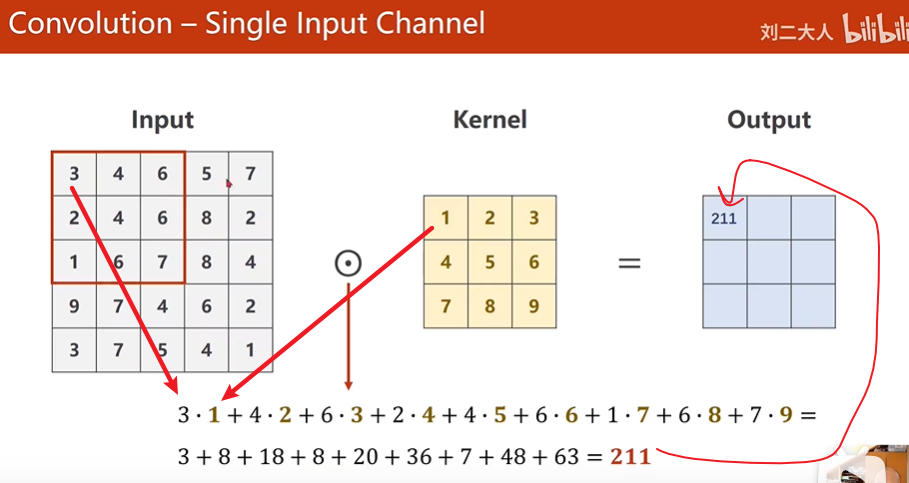
卷积的运算过程
单通道的卷积运算
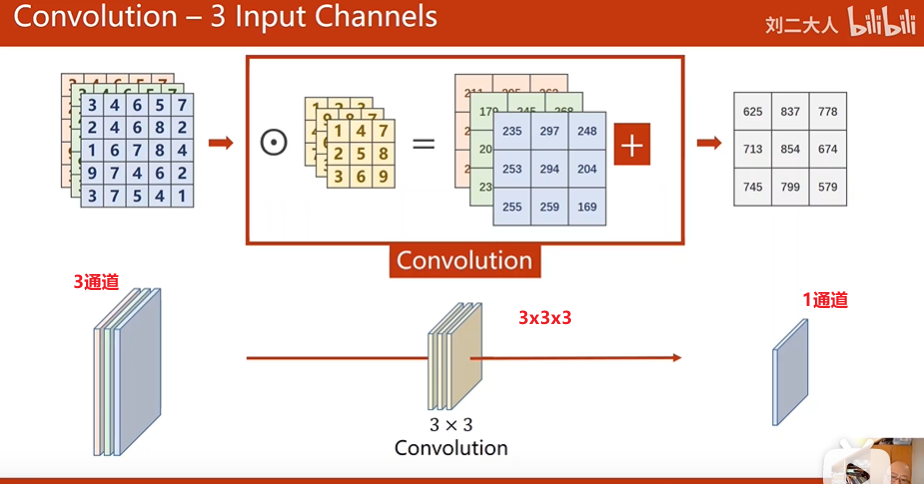
多通道的卷积运算:
如果你需要有m个输出通道,这样的卷积核就需要准备m个。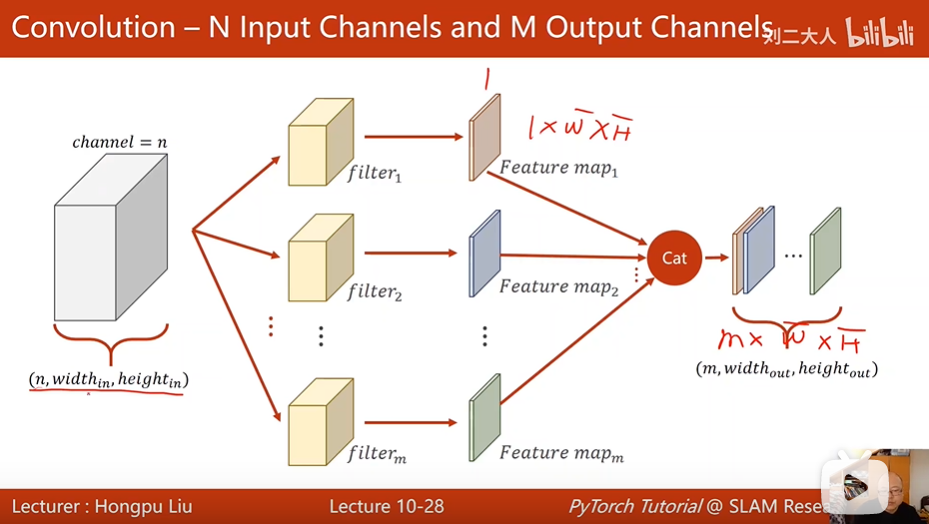
我们发现
1.每一个卷积核它的通道数量,要求和输入的通道数量是一致的,
2.这种卷积核的总数有多少个呢?和你输出通道的数量是一样的,
剩下的就是你这个卷积核的WxH是3x3的,是5x5的,还是7x7的,这个你自己来定,
它和图像的大小是没有关系的。
你图像多大,我们这个卷积核3x3的话,就是这么大的,因为我们在对每一个图像块做运算的时候,
我们都是用相同的卷积核,这是一种我们常说的共享权重的机制。
卷积层中的卷积核即卷积层共享权重
m x n x kernel_size(width) x kernel_size(height)
m表示有多少个卷积核:n x kernel_size(width) x kernel_size(height)
n为卷积核通道数
你得知道它的输入的维度,输出的维度,还有kernel_size(width) 和kernel_size(height),
一共需要四个维度。
使用Pytorch注意
在Pytorch里面,所有输入的数据,必须是小批量数据,所以你图像虽然是nxWxH的,
但是你前面要加一个Batch,就是你这个是小批量的第几个,这个是Batch的维度,

调整Tensor的形状
view
cat
unsqueeze
初始化卷积层的时候,实际上有很多权重可以设置,但是必须要设置的是,用来决定卷积核大小,
分别是输入通道,输出通道和卷积核的尺寸。
kernel-size选常数3,就是默认是3x3;你也可以给它一个元组,比如(5,3),长方形也是可以的。
但是我们一般是用正方形的。
卷积核的大小一般是用奇数。这就是我们创建的卷积层。 Pytorch里用偶数也没有关系

介绍一下卷积层里另外几个常见的权重(参数)
padding
就是看我们输入和输出宽度的需求,你比如说,我们需要输入大小和输出大小一样,
那我们就给它填充一圈
需要看kernel-size
如果是5x5的kernel size话,你就padding两圈,3/2 = 1;5/2 = 2.
即padding = kernel_size/2
padding有很多选择,最常见的就是填充0,填充完以后,我们就可以去做卷积。
这里为什么要把kernel的data赋给conv_layer.weight呢,
这是因为我们自定义了kernel的初始权重值,那么需要将其data数值赋给卷积层中的kernel的权重。
view(Batch_size,channel的维度,宽度,高度)
stride
stride就是步长,这个步长是什么呢?
如果stride = 2 ;
默认往下走的时候,也要跳一格,所以stride,就是你索引的下一个下标,不是要加1,而是要加2.
比如这个步长为2,第一次中心在4,下一次的中心就在8了。<br />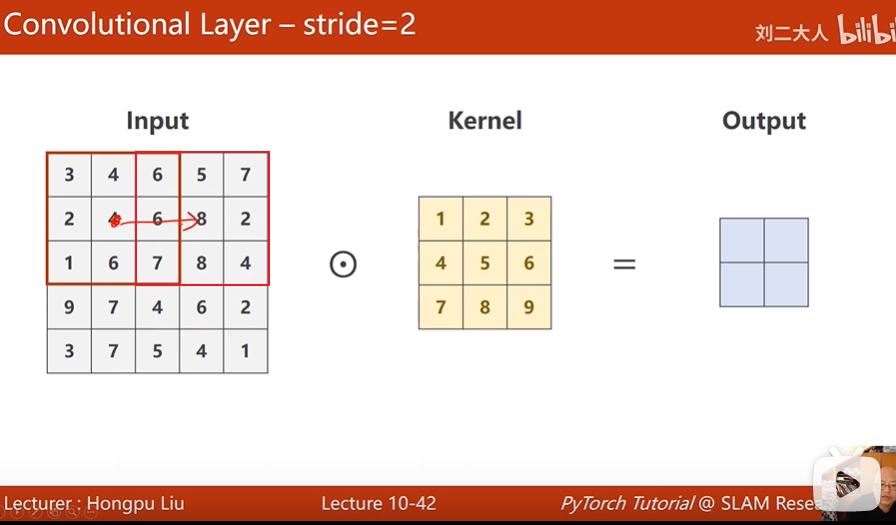
下采样:MaxPooling
用的比较多的下采样,叫做MaxPooling,叫做最大磁化层,注意它是没有权重的。
比如我们用一个2x2的MaxPooling,它默认stride=2
它没有权重,它就跟sigmoid和那个relu一样,它是没有权重的
所以在这里面,它的工作就是把这个图像,比如我们有一个4x4的图像,把它分成2x2一组,然后在每一组里找最大值,<br />然后把4,8,9,7拼成一个新的输出。所以这里面,我们能看到你在做MaxPooling的时候,你只能把一个通道拿出来做MaxPooling,<br />通道之间,不会去找最大值,所以做MaxPooling,通道数量是不变的。<br />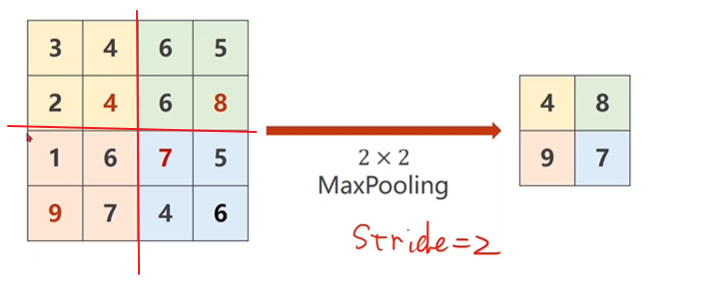<br /><br />通过卷积层融合原始信息;下采样,提取卷积后的信息中的最大值(即我们常说的特征)。

若有收获,就点个赞吧
0 人点赞
