视频链接:https://www.bilibili.com/video/BV1Y7411d7Ys?p=2
实际上是需要这样三个步骤:第一个步骤:准备你的数据集。---满足大数定律,才能接近数据的真实分布第二个步骤:进行模型的选择,或者模型的设计,比如说你要选择一个线层的模型,简单一点的模型还是复杂一点的模型,比如你要选择神经网络,决策树,还是选择朴素贝叶斯等等,这个要根据数据集的情况,来进行决定。---如何设计模型第三步:选择完模型之后,我们要进行训练,训练的过程,一般来说大部分的模型我们都需要进行训练;当然有些的模型它是在进行推理的时候,然后时间要长一点,有些可以不做训练,比如说像KNN模型;但是大部分的模型都需要做训练。---如何训练,如何矫正权重第四步:做完训练之后呢,把模型这个里面的权重(相当于特征)都确定下来,将来我们就可以做应用,做应用的时候,我们就可以做推理的工作,拿到新的数据,把它的结果推理出来。(即持久化模型)
在面对问题的时候,通常在大部分的情况下,通常我们这里面给出y数值的这些呢,是我们Training的时候要
做的。
没有给结果的这些呢,一般来说,我们要么是在推理过程(上线),要么是在测试过程。
也就是说模型看不到数据的y值的情况:1.测试阶段 2.上线阶段
1.拿到数据集进行训练
2.训练好之后,对于以后的数据输入,通过模型直接计算出我们的预测结果。
在训练(学习)的时候,我们知道x和y的值,我们把这种学习任务就叫做监督学习。
就是说,我们在学习的时候,是知道这个x对应的输出值是多少的,这样我们可以根据模型计算的值和输出值
的差异来对模型进行调整。---这就是训练学习的本质(需要根据损失值来动态调整计算图;即修改权重)
测试集的数据,我们在训练过程当中,是不能去偷看的。因为测试集的数据,我们是来看我们的模型
是不是有一个好的泛化能力。
所有的模型在训练好之后,都需要用训练集来进行测试,来评估它的性能。
这里面测试集的y,实际上我们在数据集里面,我们是知道的,但是我们是不能告诉这个模型的。我们
只能说拿模型算出来的结果和我们知道的测试集的结果来进行比对,然后根据
正确的比例,然后我们再去计算相应的指标,来判定我们模型是优是劣。
比如在很多网站上,大部分的竞赛,Training Set是可以直接下载下来的;Test Set只会给你输入。
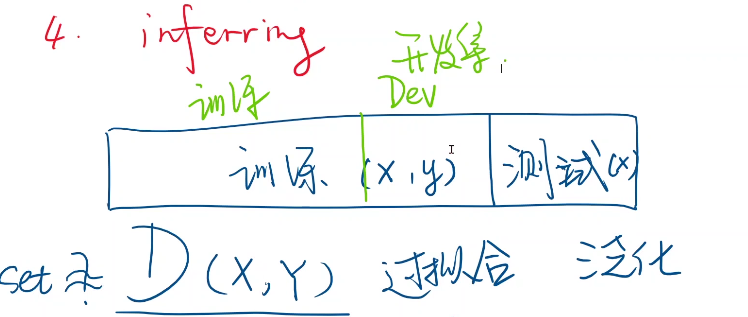
所以我们拿到数据集,我们先要把它分为两个部分,一部分是在训练的时候使用的 Training Set;
另外的一部分(作为Dev Set)呢,是训练好之后,进行测试的,测试模型的性能到底是怎么样的。
我们要把整个数据集分成两个部分。就是说我们训练好之后,在测试集里面去测。它的性能到底是怎样的。
有一些情况下,我们(训练模型的人并且模型本身)是知道测试集里对应的输出值是多少。
但是我们在训练的过程当中不能去偷看。
如果在竞赛网站中,如果可以看测试集的输出值的话,那么将来提交算法的时候,就直接根据数据集做一个
词典,那你就能百分百正确了。所以为了正确,我们在竞赛的时候,测试集我们是看不到结果的。
---这是竞赛的场景
训练集里是可以看到x和y;测试集通常只能看到x。
假设你只有训练集,但是你想在上传测试之前,你就想知道你这个训练集到底性能如何。
但是这里面有一个问题:
假设随机变量x(就是咱们输入的特征),和y符合联合分布D(X,Y)。
我们训练集里拿到的这些数据样本是不是能正确的表示这个分布,就是说
我这个数据集里面,是不能够把这个分布表示出来,
这里面,有可能我们是达不到这个目标的。因为在概率论里,我们学过,
如果要用采样的方法来接近真实分布的话,你要满足大数定律,这就意味着我们在处理数据集的时候,我们基本上
没有办法达到,依旧没有办法表示真实的分布。
举个例子来理解:
那么这个真实的分布,还有的时候,就是说,你这个真实分布的数据,不一定容易得到,比如你要上线这样一个功能:
用户上传一张图片,辨别是猫还是狗。比如咱们在选数据集的时候,你可能找的都是各种猫和狗的摄影图片,
作为你的数据集,都是经过美颜的,或者说照片是经过修改的。等到你这个系统上线以后,用户们上传的时候,可能就是随手一拍,左边是我们的训练集 右边的是上线之后,用户上传的数据输入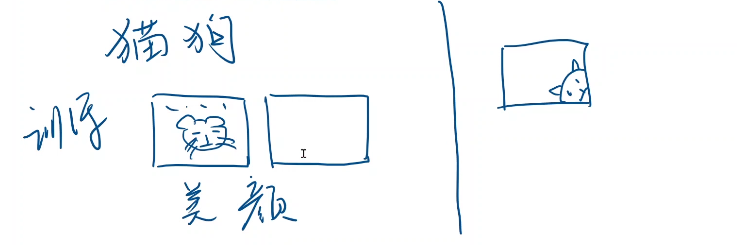
我们训练的时候,图像都能在中间,而将来用户发出来的图片什么可能都有,这就导致将来真实的业务场景里面,图像的分布和训练集里的分布是有比较大的差异的,所以一般来说,我们想要让我们的模型有尽可能有比较好的高性能,就是上线之后,投入到应用之后,有比较好的性能。那你必须要保证你的这个数据集要和用户真实上传的照片的数据集能尽可能的一致。
这就意味着,我们将来要做猫和狗的分辨,我们就不能光从艺术照片里面作为我们的数据来源,我们还要去
社交网络里去爬取更多的这种类似的用户真实环境下的图像。
---这是上线的场景
所以有的时候,我们在训练集上,因为我们的训练集倒无法完全接近真实的分布,所以如果我们在训练集上,训练
的非常好,它会造成我们在机器学习里遇到的一个核心的问题,就是我们在做机器学习的时候,最主要的难题
就是过拟合。
这个过拟合就是说我们在训练的时候,误差很小。---对于训练集而言。但又因为训练集并不能
完全的表示真实的数据分布。
并且我们在训练集上学习的时候,有可能把噪声也学进来了,这个是我们不想要的。
我们希望我们的模型有比较好的泛化能力,什么叫泛化能力呢?
就是你在训练集里训练好了之后,模型就是对于一个没有见过的图像,也能够进行正确的识别。
---我们把它叫做泛化
有的时候我们为了测验模型的泛化能力,那么通常,我们很多时候,会把训练集分为两份,
一份用来进行训练,另外一份用来进行模型的评估(开发集Dev),如果评估的比较好的
话,性能比较好的话,那我们可以最后把所有训练集里的数据都扔到模型里,再做一次训练,
然后再去面对测试集。
性能比较好的话,那我们可以最后把所有训练集里的数据都扔到模型里,再做一次训练,
然后再去面对测试集。
---那对于模型的设计,我们要解决的就是,对于这些数据来说,什么样的模型是合适的。
所谓的模型是什么呢?
就是我们要找到y=f(x)这个函数,y=f(x)的形式是非常多样的,比如可以写成ax+b,ax²+bx+c;ae^bx+c
每一种选择都代表着一种模型,这带有参数的一个模型。(a , b ,c 皆为参数,亦叫权重)
所以我们第一个就是先要选择模型,一般来说,在我们做很多机器学习的任务里面,最常见的一种思路就是
先用一个线性模型来看一下,在这里面是不是有效。
因为我们发现在很多的任务里面,我们发现线性模型可以作为最基本的这样一种方式,先架构出这样一个机器
学习的训练架构。
如果后面我们发现这个模型不好,我们再换模型,然后再进行其它的调整。
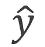 叫做预测的结果
叫做预测的结果
在机器学习里面,我们首先是做一个随机猜测,我们随机猜权重是多少,取一个随机数,取完随机数之后,
权重有可能大,有可能小,它的权重不一定是能够落在真实值上,所以我们要评估,当你取了一个权重
之后,它所表示的模型和我们数据集里面的数据之间,它的偏移程度到底有多大,也就是说你这个计算误差
有多大。
我们要找到一种方法(Evalvate)来评估我们找到的模型(以此时的权重设定的模型)和数据集之间存在的误差。
对于训练集中每一个输入都有一个其对应的Loss。
对于每一个训练集,关于其当前的权重都有其对应的MSE(平均平方误差)。
MSE(代指所有的损失函数计算出来的误差值)=0的损失在大部分学习任务里面,我们很难得到0损失,
这等于就是说你的学习里面任何噪声都没有,而且是标准的模型,我们选用的模型正好是数据真实的分布,
当然这个是理想的状态,所以我们就需要找把权重取什么样的值,可以将损失降到最小,这就是我们的目标。

数据集中的x与y是一一对应的。
zip函数可以将两个列表组合为一个字典,形成一一对应的关系。
1.根据模型依据输入值x,计算出对应的y_hat值
2.计算出路径上的偏导数
依据forward计算出的y_hat,来拿它和y值做差。
·对于训练集来说,它的误差是一直一直减小,
·但是你如果每训练完一轮,然后去做开发集的数据进行测试,你会发现开发集的数据会跟着它减少减少,
减少到一定程度,就要增加了,
·所以我们将来在深度学习的时候,根据Epoch,我们想知道什么时候是真正的收敛了,
一般来说,你就要找这个点,这个点有的时候,我们是需要人工观察,你至少要训练一段时间,然后去观察。
不是模型本身的参数。
比如轮数,一些训练参数如batch_size等,皆为超参数。
模型在训练的过程当中能够实时的画一些图,比如用visdom,我们就可以远程登陆服务器给我们提供的
Web功能进行观看,实时的训练过程。
·比如可视化的问题,
·还有断点重开的问题,就是说你训练到一半,程序崩溃了,你原来数据,比如你模型要训练七天,
结果到第六天的时候,你程序崩溃了,最后你结果没了,那这里面你时间就白白耽误了,
所以我们还要在深度学习训练过程当中,我们要对模型进行持久化,
换句话说就是你要存盘,你如果不定期存盘的话,那你在深度学习里面会遇到很多的问题。

若有收获,就点个赞吧
0 人点赞
