基础知识
首先,从字符串编码说起,无论是Python2还是Python3,总体上说,字符串的编码只有两大类
1. 通用的Unicode编码1. 将Unicode转化成的某种类型的编码,如UTF-8、GBK
在Python3中。字符串的编码使用str和bytes两种类型
1. str字符串:使用Unicode1. bytes字符串:使用将Unicode转换成的某种类型的编码,如UTF-8、GBK
**Python3默认编码为str**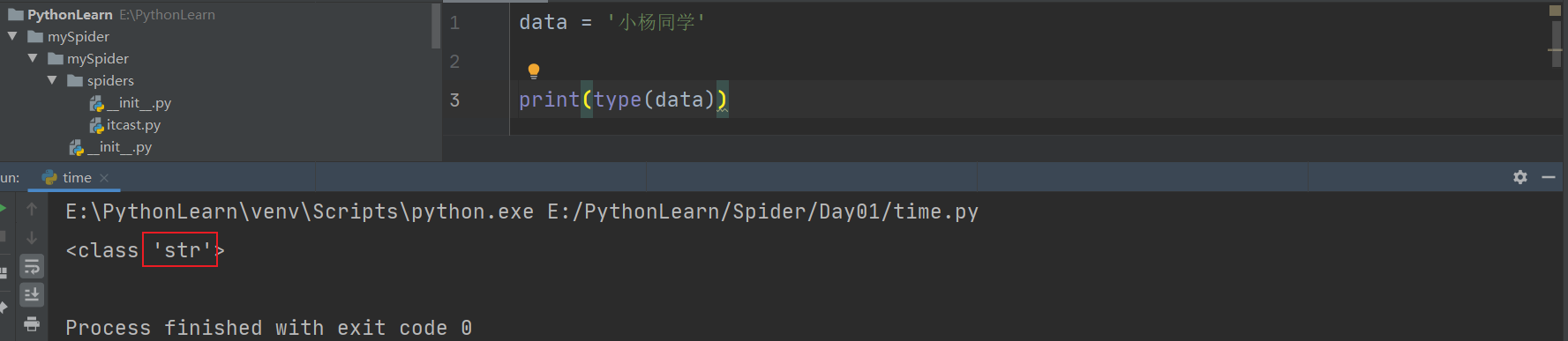
encode和decode
**encode---将Unicode编码转换成其他编码的字符串**
**decode---将其他编码的字符串转换成Unicode编码**

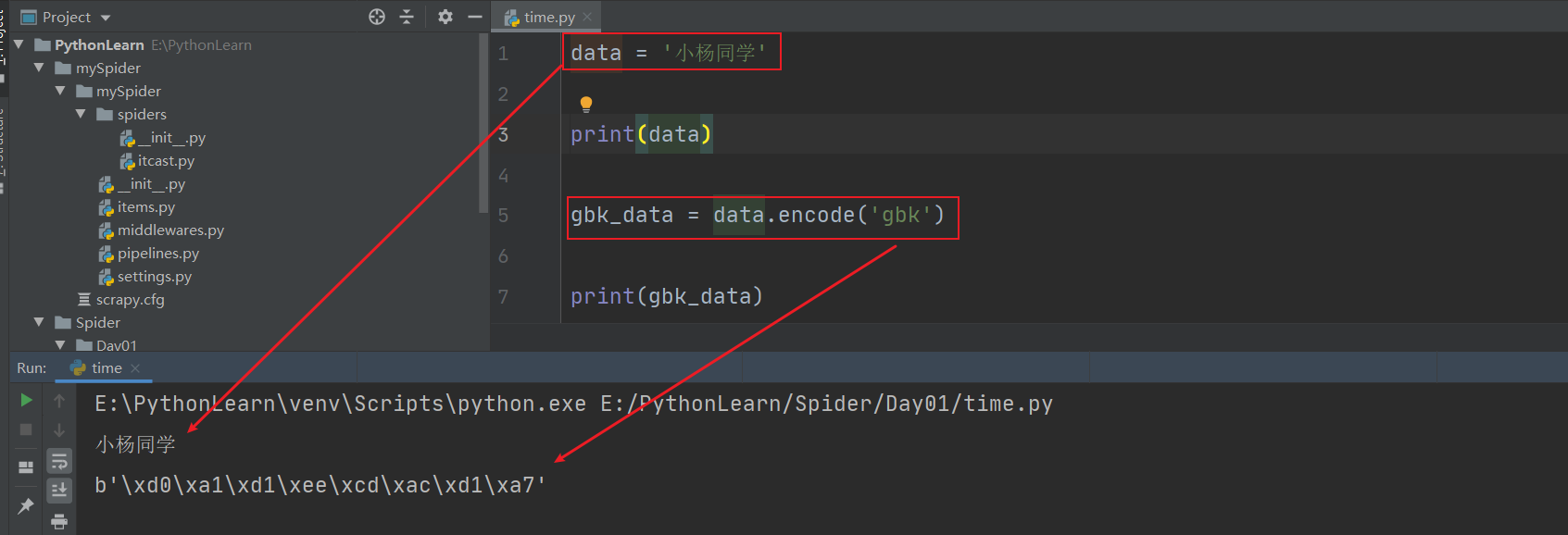
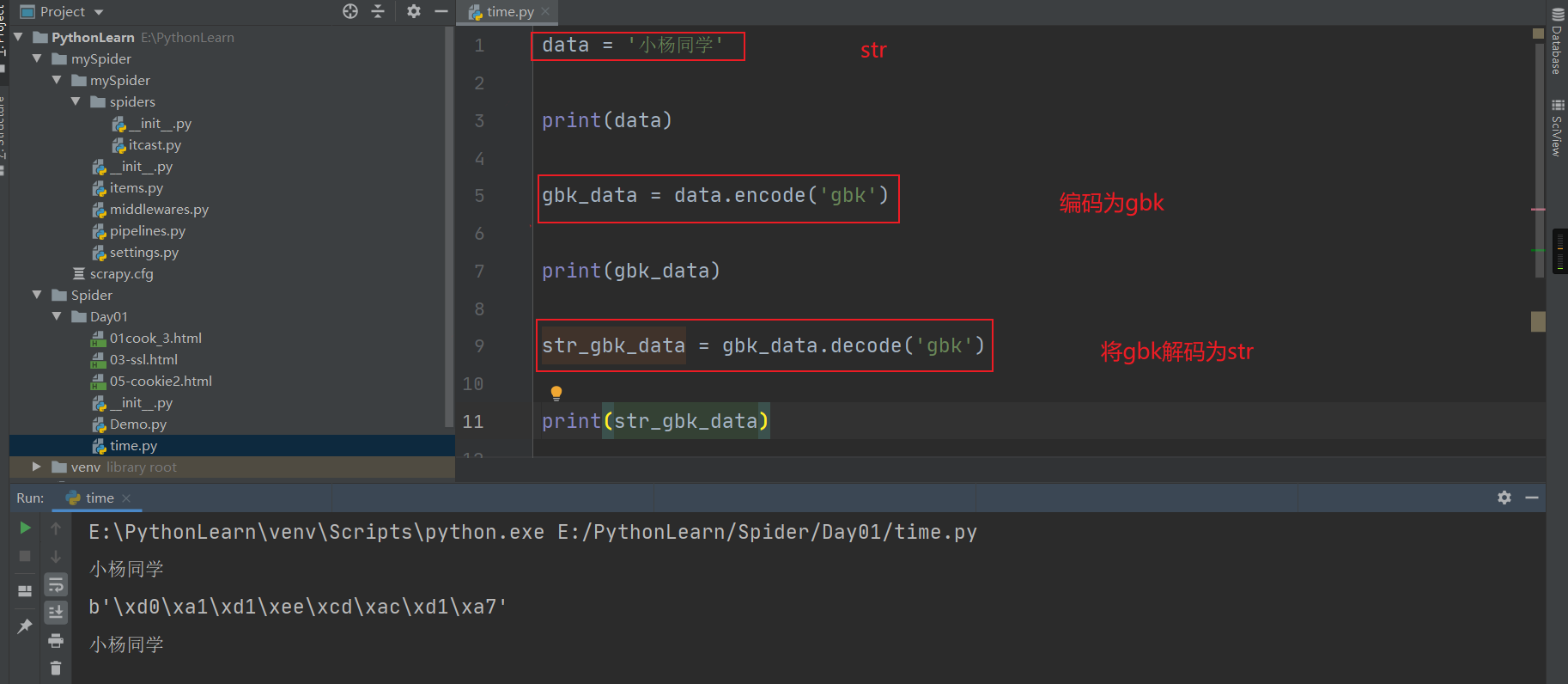
问题1:获取网站的中文显示乱码
这是比较常见的问题,也容易解决。每次爬取网站之前我们都需要检查对方网站使用的编码,Python默认UTF-8
打开浏览器,按下F12,在console控制台输入 document.charset
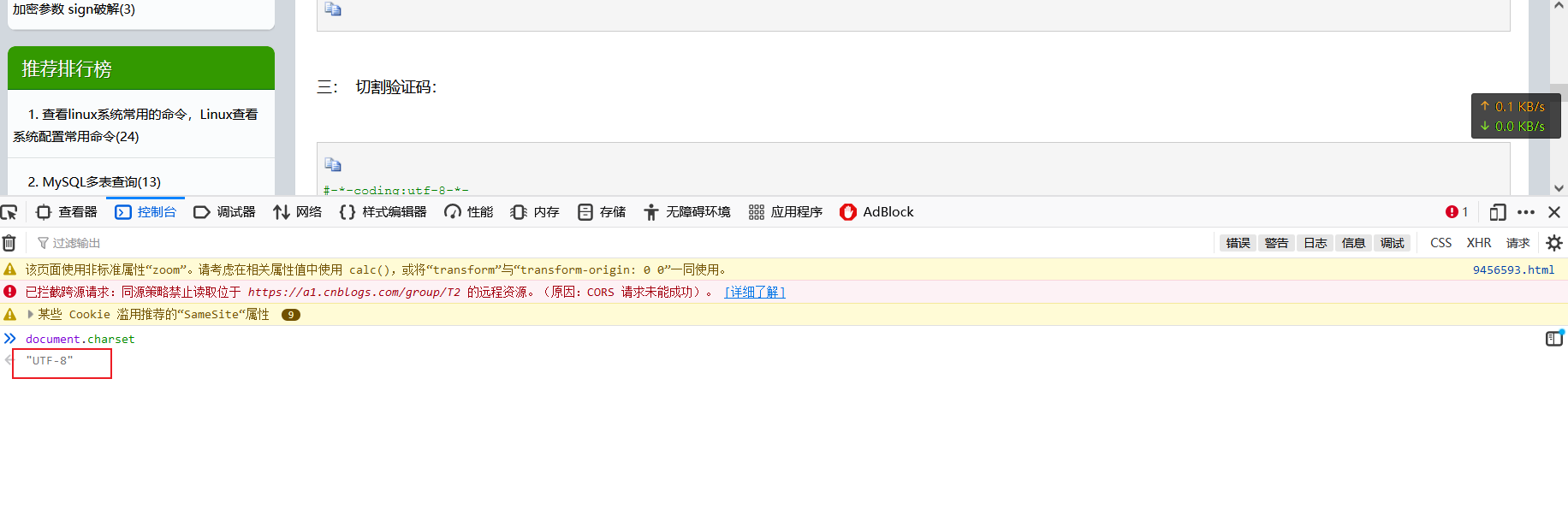
如果对方网站不是utf-8,需要对爬取内容进行解码,操作也是非常简单,前面讲的很清楚
data.decode('对方网站编码格式') #data指爬取数据内容
问题2:非法字符抛出异常
一个页面混入多种编码方式,就会出现非法字符
解决方法: data.decode('GBK','ignore')

问题3:网页使用gzip压缩
新浪网页就是这种情况,尽管使用默认编码,抓取的数据出现中文部分全为乱码,那是因为新浪网使用gzip将网页压缩了,需要对其解压
然后就进入到上面两个问题,查看对方编码,该解码解码
import chardetimport requestsurl = 'https://sina.cn/'url_data = requests.get(url)datas = url_data.content #抓取数据内容print(chardet.detect(datas)) #解压print(datas.decode('utf-8')) #解码
说明:我不知道新浪网页是不是依旧压缩网页,因为我实验的时候就常规操作也是可以正常输出中文的,但这不影响我们学习这个知识点
问题4:读写文件的中文乱码
是对CSV、TXT、JSON文件的编码问题的处理,即保存打开后如何不乱码

若有收获,就点个赞吧
0 人点赞
