网站为何应用反爬虫技术
1. 网络爬虫浪费网站的流量,也就是浪费钱--因为爬虫对于网站不是真正的用户流量1. 数据是每家公司非常宝贵的资源--竞争对手分析数据,导致公司竞争力的下降
反爬虫的方式有哪些
1. 不返回网页,如不返回网页(返回404页面)内容和延迟网页返回时间1. 返回数据非目标网页,如返回错误页、空白页、爬取多页均返回同一页1. 增加获取数据的难度,如登录才可以查看和登录时设置验证码(让你在八张图片中选择正确的选项,防止你自动抢票)
如何对付反爬虫
修改请求头User-Agent
使用Python库写代码,请求的内容明显标识为爬虫,所以需要我们对其进行修改,前面文章已经介绍这个技术,不赘述
Day02—-请求头设定
修改爬虫的间隔时间
没有小时间段的发送请求,明显是爬虫,这不是正常人该有的请求速度
太有规律的发送请求,明显是爬虫,正常人不会访问网站还要卡时间
太有时间段规律的发送请求也不行,有点机器人的嫌疑
所以我们对网站的访问的时间需要设定为随机值,并且设置发送请求多少次休息一下再接着访问
代码如下
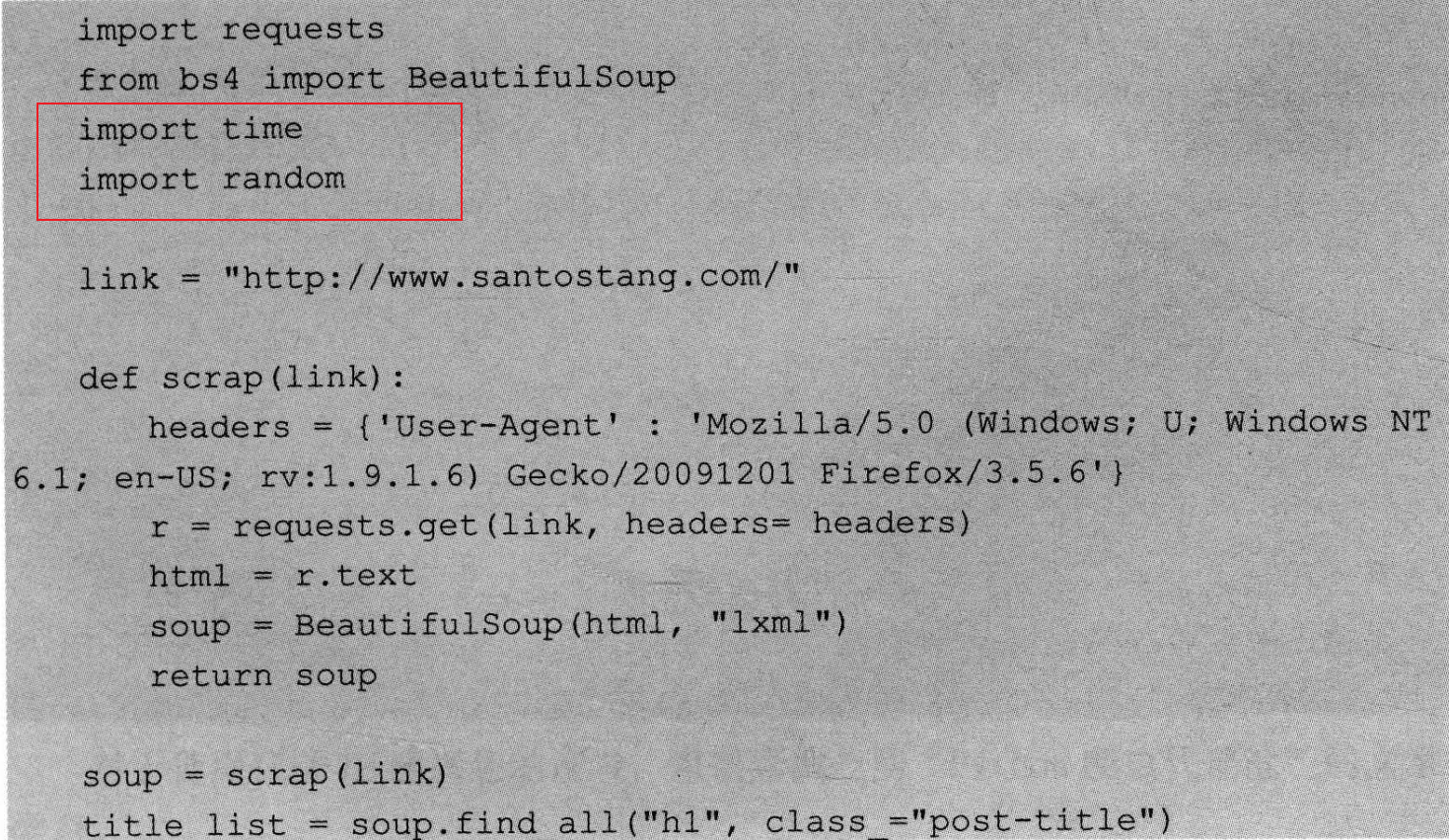
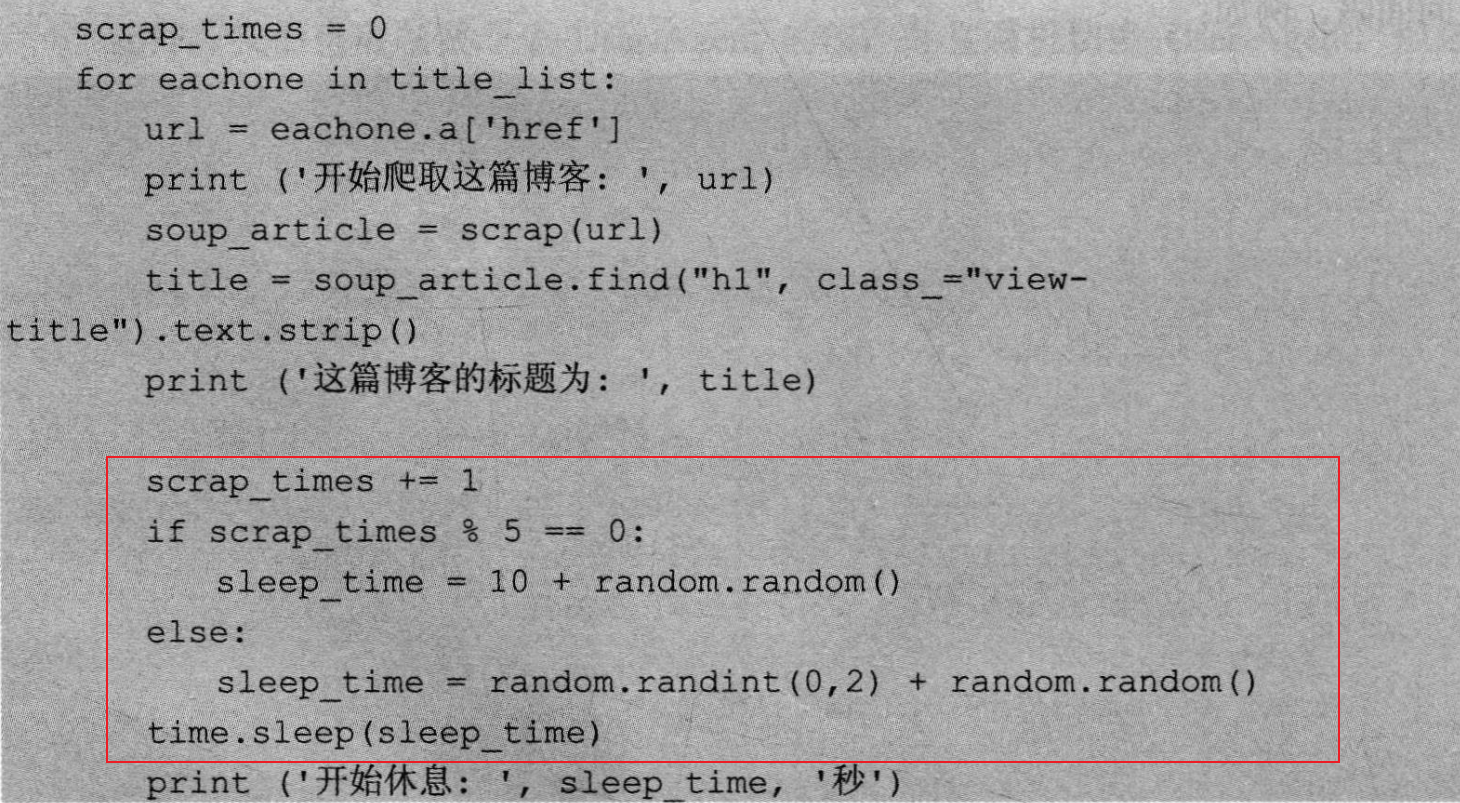
使用代理
免费代理和付费代理添加
Day03—-添加代理
云IP的添加
Day13—Python服务器采集
关于代理的添加到此就告一段落,目前我已知的就这些,我相信可以解决爬虫的IP被封问题,大家结合自己的需要选择不同的IP代理添加方式

若有收获,就点个赞吧
0 人点赞
