本节参考链接
https://blog.csdn.net/weixin_44627151/article/details/115775239 https://www.bilibili.com/video/BV1jt411Q7PD?from=search&seid=10299534250007155058&spm_id_from=333.337.0.0
简介
写一个爬虫,需要做很多的事情。比如:发送网络请求、数据解析、数据存储、反反爬虫机制(更换p代理、设置请求头等)、异步·请求……这些知识点前面已经讲得清楚,大家会发现我们是一个一个去写每个步骤,然后我们可以用函数封装起来,但是这些工作如果每次都要自己从零开始写的话,比较浪费时间。因此Scrapy把一些基础的东西封装好了,在他上面写爬虫可以变的更加的高效(抓取效率和开发效率)因此真正在公司里,一些上了量的爬虫,都是使用scrapy框架来解决
Scrapy框架原理
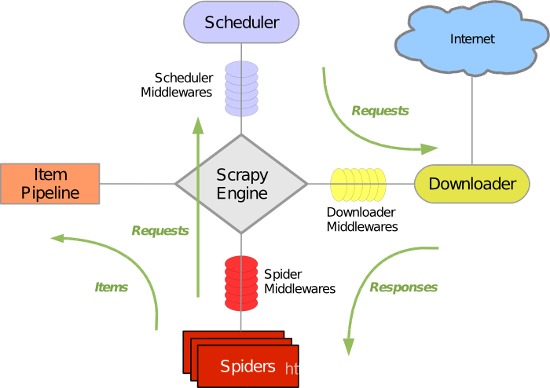
引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心)调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址下载器(Downloader)用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)爬虫(Spiders)爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面项目管道(Pipeline)负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应爬虫中间件(Spider Middlewares)介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出调度中间件(Scheduler Middewares)介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
基本命令
全局命令scrapy sstartproject 创建项目genspider: scrapy genspider [-t template] <name> <domain>生成爬虫,-l 查看模板; -t 指定模板,name爬虫名,domain域名(爬取网站范围)settings 查看设置runspider 运行爬虫(运行一个独立的python文件,不必创建项目)shell :scrapy shell [url]进入交互式命令行,可以方便调试–spider=SPIDER 忽略爬虫自动检测,强制使用指定的爬虫-c 评估代码,打印结果并退出:$ scrapy shell --nolog http://www.example.com/ -c '(response.status, response.url)'(200, 'http://www.example.com/')12–no-redirect 拒绝重定向–nolog 不打印日志response.status 查看响应码response.urlresponse.text; response.body 响应文本;响应二进制view(response) 打开下载到本地的页面,方便分析页面(比如非静态元素)fetch 查看爬虫是如何获取页面的,常见选项如下:–spider=SPIDER 忽略爬虫自动检测,强制使用指定的爬虫–headers 查看响应头信息–no-redirect 拒绝重定向view 同交互式命令中的viewversion项目命令crawl : scrapy crawl <spider> 指定爬虫开始爬取(确保配置文件中ROBOTSTXT_OBEY = False)check: scrapy check [-l] <spider>检查语法错误list 爬虫listedit 命令行模式编辑爬虫(没啥用)parse: scrapy parse <url> [options] 爬取并用指定的回掉函数解析(可以验证我们的回调函数是否正确)–callback 或者 -c 指定回调函数bench 测试爬虫性能
scrapy startproject maitian # 创建一个爬虫项目 maitian
我利用Pycharm的终端和Scrapy命令创建了项目,结果如下
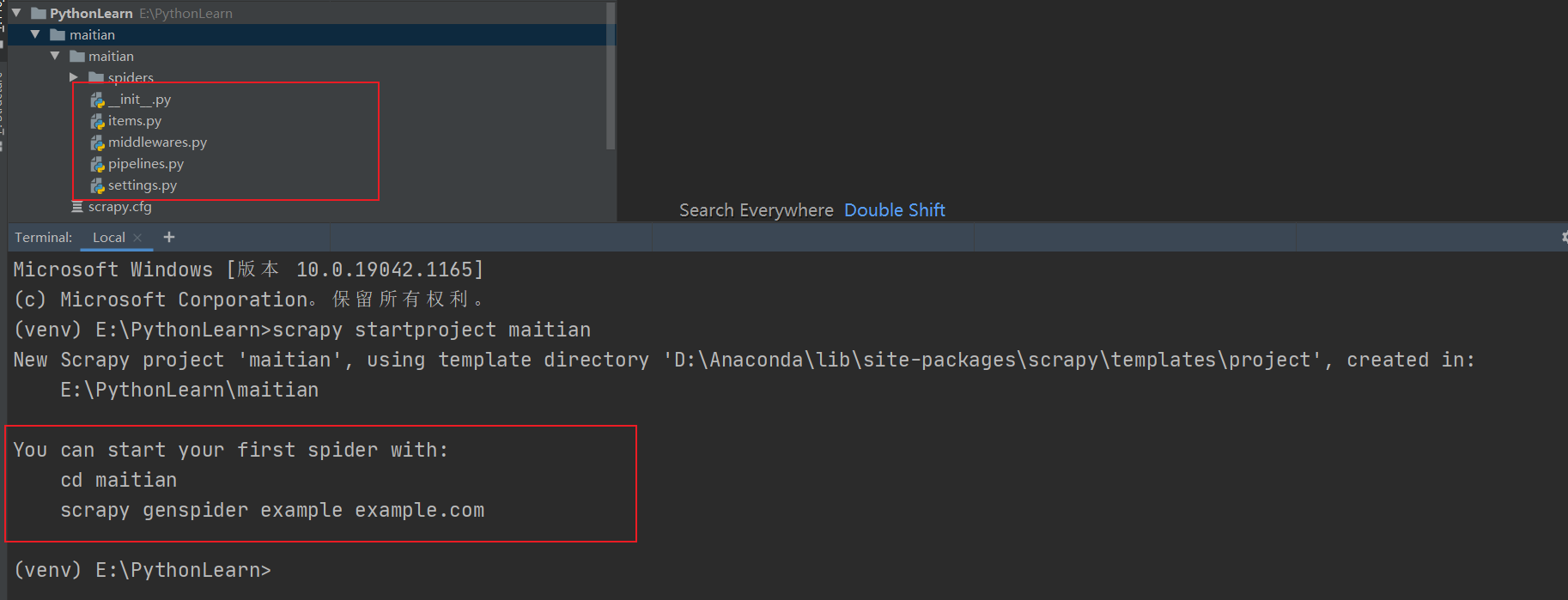
创建项目后,自动生成如下文件
1. scrapy startproject 项目名称- 在当前目录中创建中创建一个项目文件(类似于Django)2. scrapy genspider [-t template] <name> <domain>- 创建爬虫应用如:scrapy genspider -t basic oldboy oldboy.comscrapy genspider -t xmlfeed autohome autohome.com.cnPS:查看所有命令:scrapy gensipider -l查看模板命令:scrapy gensipider -d 模板名称3. scrapy list- 展示爬虫应用列表4. scrapy crawl 爬虫应用名称- 运行单独爬虫应用scrapy crawl xxx --nolog5.scrapy shell 进入shell复制代码
问题1 :代码运行出错解决办法
大家在运行代码一定出现这个错误
ModuleNotFoundError: No module named ‘protego‘
不要去用pycharm去安装,而要用Anaconda去安装,安装后把protego文件夹复制到你运行Python文件的库里面,当然如果你本来用的就是Anaconda就不用了 参考链接:[https://blog.csdn.net/qq_43236333/article/details/115871163](https://blog.csdn.net/qq_43236333/article/details/115871163)
问题2 :创建爬虫文件的代码
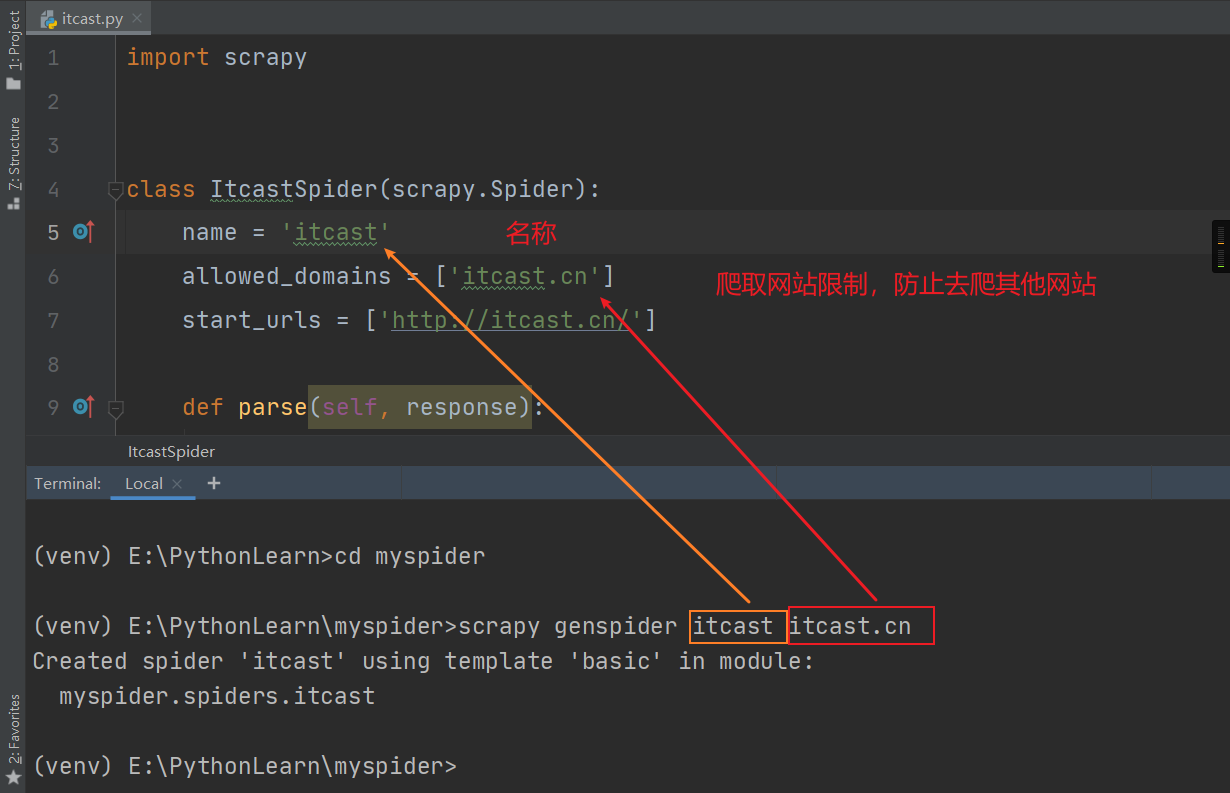
name:用于区别spider。该名字必须是唯一的,不能为不同的spider设定相同的名字statr_urls:它是spider在启动时进行爬取的入口URL列表。因此,第一个被获取到的页面的URL将是其中之一,后续的URL则从初始的URL的响应中主动提取parse():它是spider的一个方法。该方法负责解析返回的数据、提取数据(生成item)以及生成需要进一步处理的URL的request对象
import scrapyclass ItcastSpider(scrapy.Spider):name = 'itcast' 爬虫名称allowed_domains = ['itcast.cn'] #允许的域名start_urls = ['http://itcast.cn/']def parse(self, response):pass#处理start_urls的相应
问题3:shell进入命令交互
如:scrapy shell URL --nolog # –-nolog不打印日志
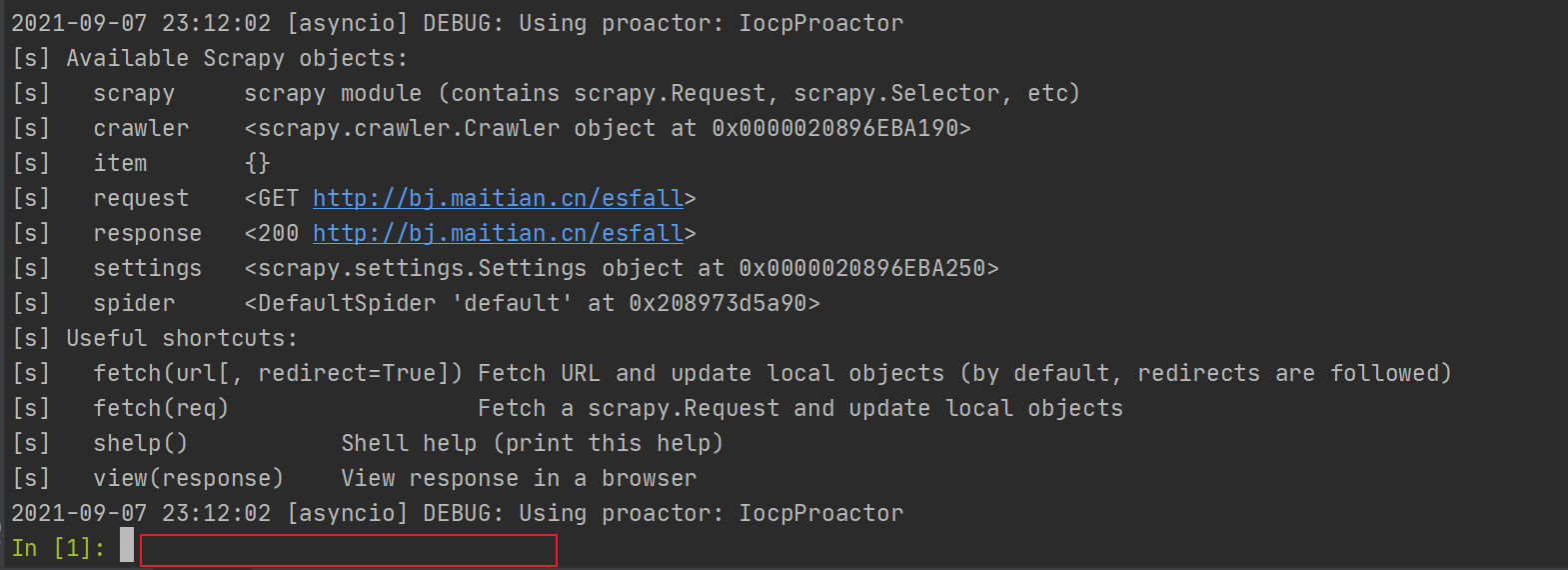
问题4:shell命令的使用
>>>response.xpath('//title/text()').extract_first()重新下载页面>>>fetch (URL)修改请求参数,比如讲默认的GET方法改为POST方法,然后用fetch直接请求request>>>requset = requset.replace(method='post')>>>fetch(request)exit() 即可退出scrapy shell 终端模式还有其他的使用命令,上图明显
.extract_first()
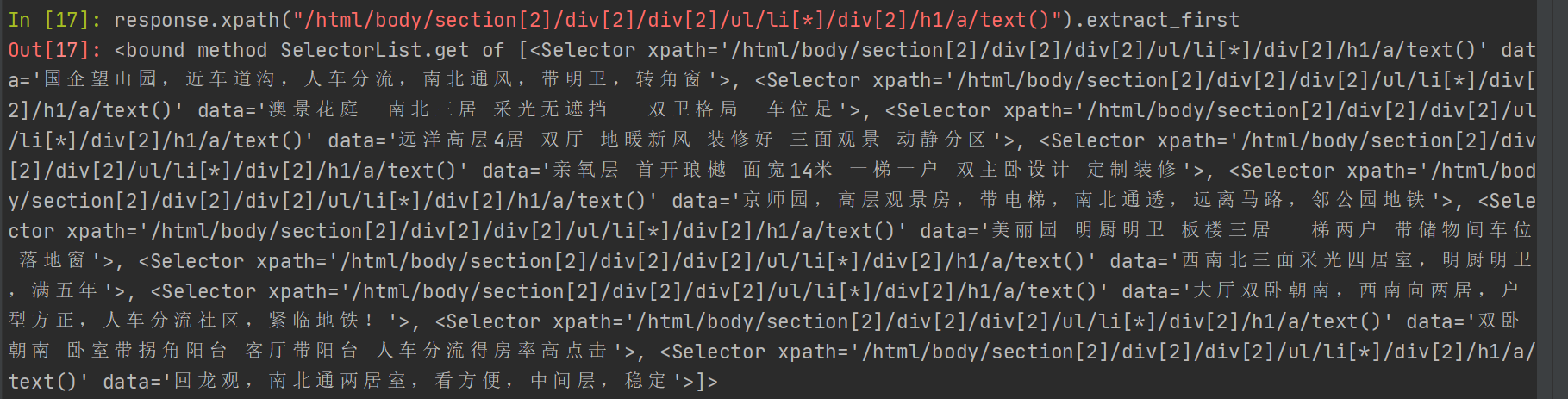
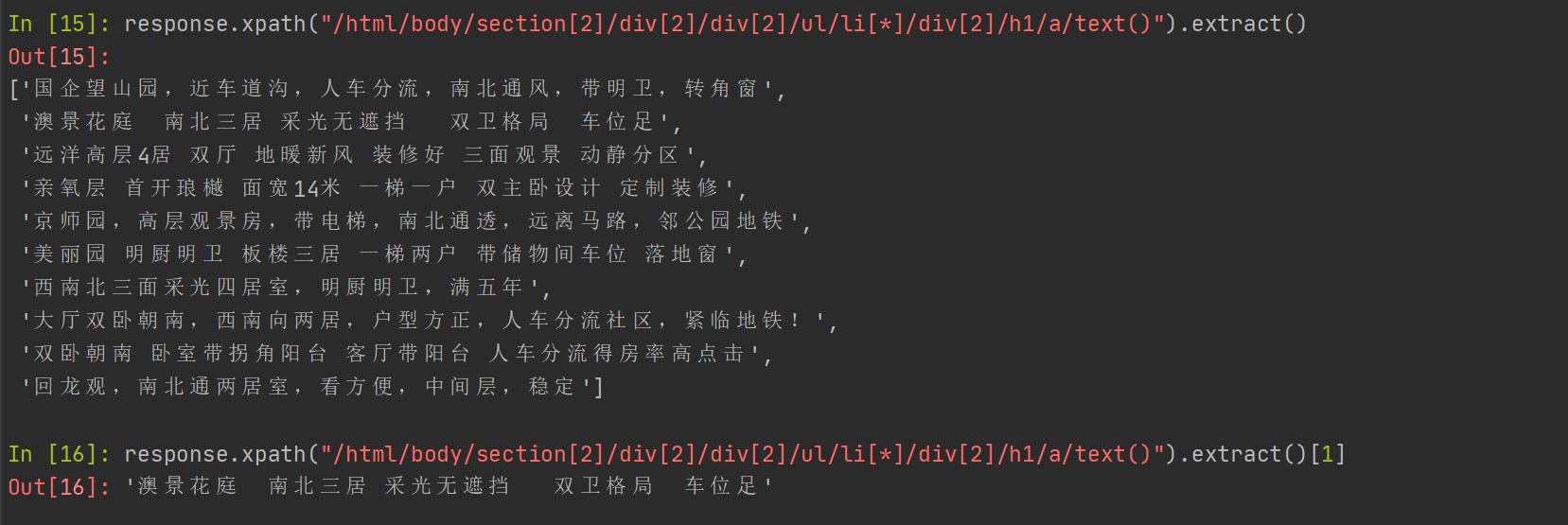
import scrapyfrom maitian.items import MaitianItemclass WebSpider(scrapy.Spider):name = 'web'allowed_domains = ['maitian.cn']start_urls = ['http://bj.maitian.cn/zfall/PG1']def parse(self, response):for web_itme in response.xpath("/html/body/section[2]/div[2]/div[2]/ul/li[3]/div[2]"):yield {'title': web_itme.xpath("./h1/a/text()").extrace_first().strip(),'price': web_itme.xpath("./div/ol/strong/span/text()").extrace_first().strip(),'area': web_itme.xpath(".p[1]/span[1]/text()").extrace_first().strip()}next_page_url=response.xpath("//[@id="paging"]/a[@class="down_page"]/@href").extract_first()if next_page_url is not None:yield scrapy.Request(response.urljoin(next_page_url))
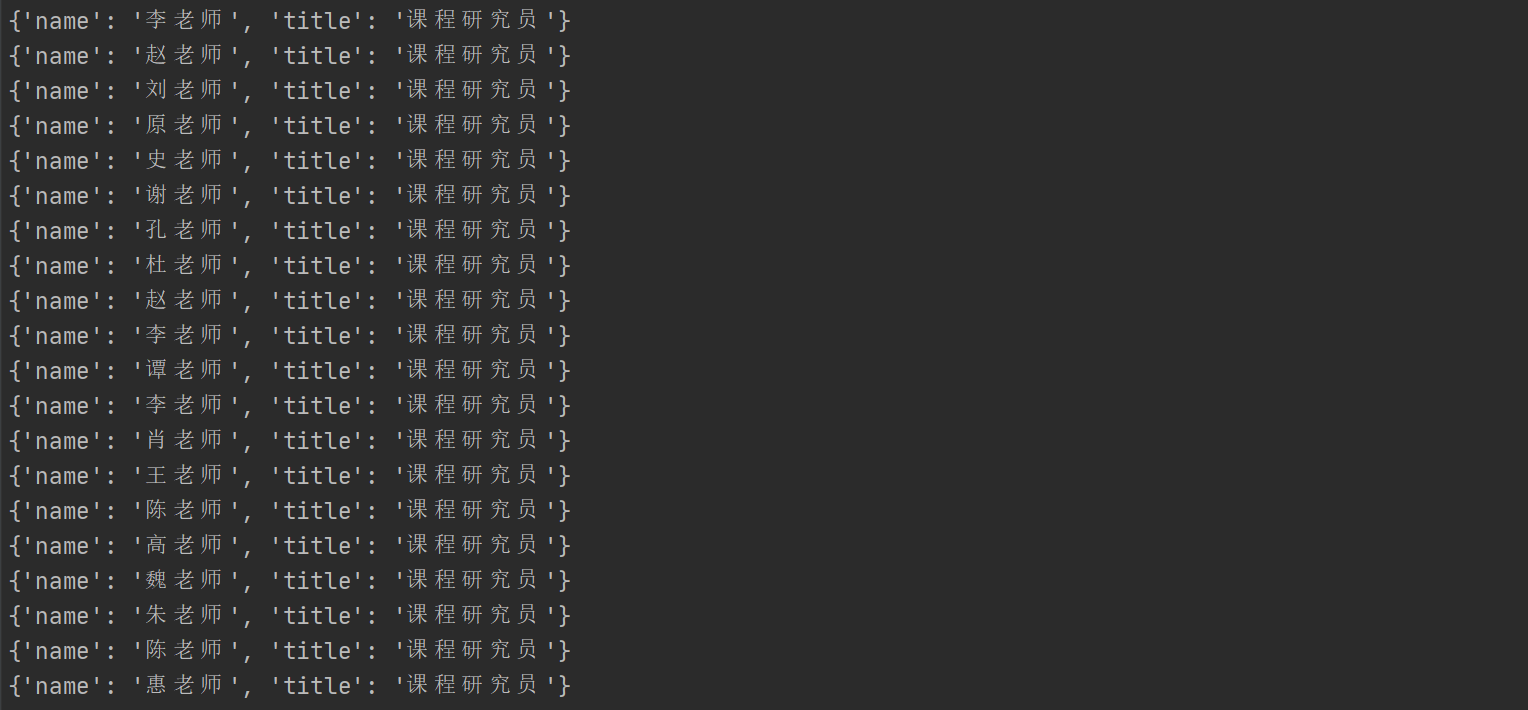
# 分组(对抓取数据,进行有必要的分组)li_list = response.xpath("/html/body/div[10]/div/div[2]/ul/li")for li in li_list:item = {}item["name"] = li.xpath("./div[2]/h2/text()").extract_first()item["title"] = li.xpath("./div[2]/h2/span/text()").extract_first()print(item)

若有收获,就点个赞吧
0 人点赞
