手动添加cookie
过于简单,不作细述
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36','Cookie':'cna=tuxEE3P7Ah4CATsurIJv/hNX; thw=cn; miid=82973328358325713; hng=CN%7Czh-CN%7CCNY%7C156; enc=kRhiJJnvm93D0rrXU7wRBAaqd%2FIu5LOUzL12ixGWG7mDUwOyqHNGcPQhxt%2BpZYJvk7OKyIoTwXjjdWJS7nXYpw%3D%3D; UM_distinctid=168d4da25ce206-02459feb9-3b664008-1fa400-168d4da25cf36b; v=0; _tb_token_=eb3533565b383; unb=652498984; sg=54b; t=d67352809c9dfb1dc94c606e4d904faf; _l_g_=Ug%3D%3D; skt=0457744f2cebfa42; cookie2=59fbade39ff2795b3bae1040d518612d; cookie1=ACi9bWtE9Swd%2B7nwwIWMZefTwl6qKUcepd4lYB%2B9GhY%3D; csg=d905bd39; uc3=vt3=F8dByEzaZ25JtIrFM94%3D&id2=VWojfdPOsPRO&nk2=FPjanhY%2Fn9CxQYviMZUN&lg2=WqG3DMC9VAQiUQ%3D%3D; existShop=MTU1MDgzNDUxNg%3D%3D; tracknick=wangmin69323585; lgc=wangmin69323585; _cc_=V32FPkk%2Fhw%3D%3D; dnk=wangmin69323585; _nk_=wangmin69323585; cookie17=VWojfdPOsPRO; tg=0; mt=ci=9_1; ubn=p; ucn=unshyun; l=bBSQZo7cvM7X8RE2BOfalurza77OwIRb4PVzaNbMiICPOafeSQ1lWZZhyqLwC3GVw1YpR3JY9i9vBeYBqSf..; isg=BH9_ASiVH9kGVR1_dokonvm8DlMJZNMGQCRZRRFMpi51IJ-iGTF1VsqyYrB7fat-; uc1=cart_m=0&cookie14=UoTZ5OgAB6aJAA%3D%3D&lng=zh_CN&cookie16=U%2BGCWk%2F74Mx5tgzv3dWpnhjPaQ%3D%3D&existShop=true&cookie21=VT5L2FSpdet1EftGlDZ1Vg%3D%3D&tag=8&cookie15=UtASsssmOIJ0bQ%3D%3D&pas=0'}#构建请求对象request = urllib.request.Request(url,headers=header)
持续携带cookie
cookiejar 会自动带着coolie去访问网站
`首先请求登录页面,获得cookie,这个时候cookiejar会自动保存我们的cookie
然后再去访问个人中心`
import urllib.requestfrom http import cookiejarimport urllib.parseurl_login = 'https://www.yaozh.com/login' #登录页面url_personcent = 'https://www.yaozh.com/member/'#登录成功,个人中心页面 因为为登录前不会有个人中心,这里不一定非要设置个人中心,你也可以设置只要是登录才可以访问的页面也可,这样就可以这么cookiejar带着cookie的login_form_data = { #切记如下的一个不能少,我们只需要抓请求包即可,复制到这里,所以不一定只是这些参数,也不一定就需要如下参数,看抓包的结果就行'username': 'Sparky','pwd': '198248.zcc','formhash':'5515EFBA25','backurl': 'https%3A%2F%2Fwww.yaozh.com%2F'}headers = {"User-Agent":"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0"}login_str = urllib.parse.urlencode(login_form_data).encode('utf-8') #参数 将来 需要转译 转码; 2. post请求的 data要求是bytesdata = urllib.request.Request(url_login,headers=headers,data=login_str) #不是访问,只是添加相关参数headers,data信息cookjar = cookiejar.CookieJar()handler = urllib.request.HTTPCookieProcessor(cookjar)opener = urllib.request.build_opener(handler)datas = opener.open(data) ## 如果登录成功, cookjar自动保存cookieurl_cen = urllib.request.Request(url_personcent,headers=headers) #Request不是访问,而是指定url添加相关参数response = opener.open(url_personcent) ## 如果登录成功,表示我们已经成功让cookijar携带我们的cookie了data = response.read().decode('utf-8')with open('01cook_3.html', 'w',encoding='utf-8') as f:f.write(data)
异常处理
urllib模块中的urllib.error子模块,包含了URLError 、 HTTPError
URLError
import urllib.requestimport urllib.errorurl = 'https://blog.csdn.net/weixin_43362002/article/details/10' #不存在的urltry:data = urllib.request.urlopen(url).read().decode('utf-8')print(data)except urllib.error.URLError as e:print(e.reason)
运行结果如图

HTTPError
import urllib.requestimport urllib.errorurl = 'https://blog.csdn.net/weixin_43362002/article/details/10' #不存在的urltry:data = urllib.request.urlopen(url).read().decode('utf-8')print(data)except urllib.error.HTTPError as e:print(e.code)print(e.reason)print(e.headers)
运行结果如图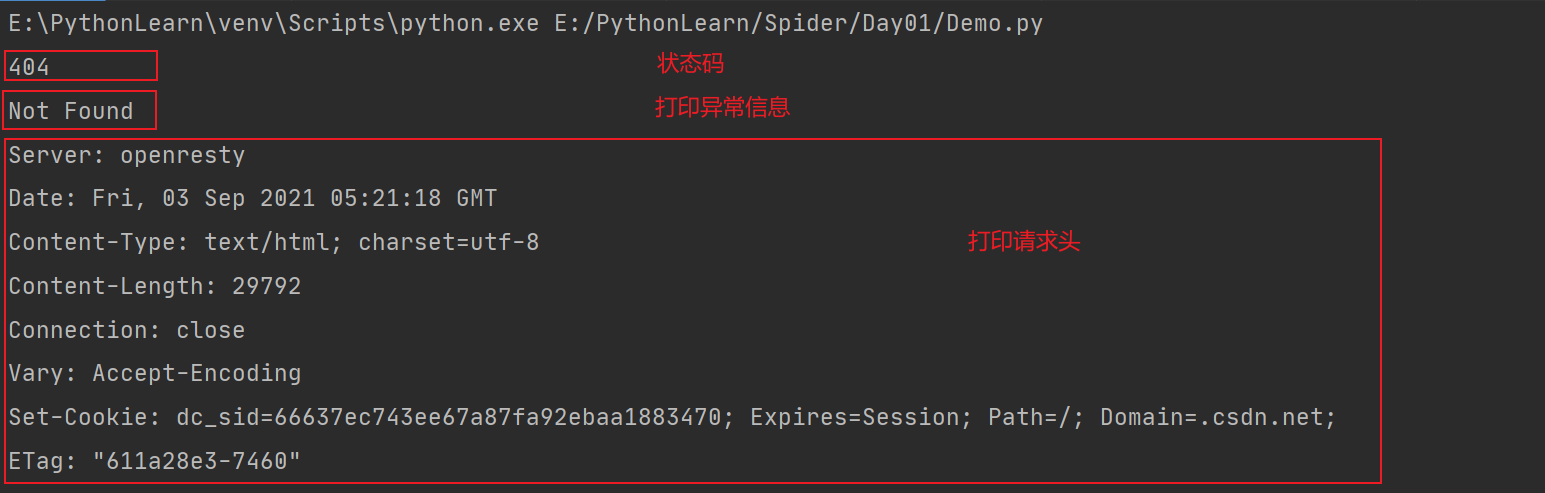
Response响应
接下来的内容都是围绕这个模块展开的
基本使用
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。Requests 的哲学是以 PEP 20 的习语为中心开发的,所以它比 urllib 更加 Pythoner。更重要的一点是它支持 Python3 哦!
简单来说,和urllib一个性质,只是代码用起来相对简介,还有其他新的功能,这里只是简单介绍一些,更全内容上有链接
import requestsurl = 'https://www.baidu.com/'data = requests.get(url)print(data.headers) #获取响应头print(data.request.headers) #获取请求头print(data.status_code) #获取响应状态码print(data.cookies) #获取请求的cookieprint(data.request.method) #获取请求方式#还有许多,你可以去了解
自动转译
requests模块发送请求有data、params两种携带参数的方法。params在get请求中使用,data在post请求中使用。import requestsrequests.get('http://www.dict.baidu.com/s', params={'wd': 'python'}) #GET参数实例requests.post('http://www.itwhy.org/wp-comments-post.php', data={'comment': '测试POST'}) #POST参数实例
说起来就是在网址后面添加参数而已,只是get请求用params,post请求用data
import requestsurl = 'https://www.baidu.com/s?'params = {'wd':'动漫'}data = {'wd':'动漫'}headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0'}url_GET = requests.get(url,params=params,headers=headers)url_POST = requests.post(url,data=data)print(url_GET)print(url_POST)
可以看到我没有对中文进行处理,即自动转译
用json转为字典
忽略第三方证书ssl
核心语句:verify=False
import requestsurl = 'https://www.12306.cn/index/'headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'}# 因为hhtps 是有第三方 CA 证书认证的# 但是 12306 虽然是https 但是 它不是 CA证书, 他是自己 颁布的证书# 解决方法 是: 告诉 web 忽略证书 访问#verify=False忽略第三方证书认证response = requests.get(url=url, headers=headers, verify=False)#data = response.content.decode()print(data)
我还以为是我没有成功,因为报错的缘故,但去网上一查发现这是成功,要想去除报错,可以采用如下方法
取消控制台输出的InsecureRequestWarning警告

session 类 可以自动保存cookies
前面有介绍cookiejar会自动保存cookies,你会发现前面调用包urllib其实前面说的清楚,两个库是一个性质,功能上都差不多,只不过这个更加简洁,我们继续望下去看
import requests# 请求数据urlmember_url = 'https://www.yaozh.com/member/'headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'}# session 类 可以自动保存cookies === cookiesJarsession = requests.session()# 1.代码登录login_url = 'https://www.yaozh.com/login'login_form_data = {'username':'xiaomaoera12','pwd': 'lina081012','formhash': '54AC1EE419','backurl': 'https%3A%2F%2Fwww.yaozh.com%2F',}login_response = session.post(login_url,data=login_form_data,headers=headers)print(login_response.content.decode())# 2.登录成功之后 带着 有效的cookies 访问 请求目标数据data = session.get(member_url,headers=headers).content.decode()print(data)
核心总结
1.verify参数—第三方证书response = requests.get(url=url, headers=headers, verify=False)verify=False忽略第三方证书2.session自动保存cookiessession = requests.session()

若有收获,就点个赞吧
0 人点赞
