1.集合体系:
Java集合主要由2大体系构成,分别是Collection和Map 它们又分别是2大体系中的顶层接口。
Collection:主要有三个子接口,分别为List(列表)、Set(集)、Queue(队列)。
其中,List、Queue中的元素有序可重复,而Set中的元素无序不可重复。
List中主要有ArrayList、LinkedList两个实现类;Set中则是有HashSet实现类;
Map:Map中都是以key-value的形式存在,其中key必须唯一,主要有HashMap、HashTable、treeMap三个实现类。
Queue是在JDK1.5后才出现的新集合,主要以数组和链表两种形式存在。
2.List
List集合是有序的,可重复,可对其中每个元素的插入位置进行精确地控制,可以通过索引来访问元素,遍历元素。<br />**在List集合中,我们常用到ArrayList和LinkedList这两个类。**<br />**Arraylist:底层是数组,查找快,因为有下标索引,但是因为下标索引,增删慢,部分索引改变**<br />**Linkedlist:底层是链表,增删快,因为没下标索引,但是因为没下标索引,查找慢,二分查找**<br />**Arraylist增删慢只是相对来说,其实并不是很慢,所以,常用Arraylist;**<br />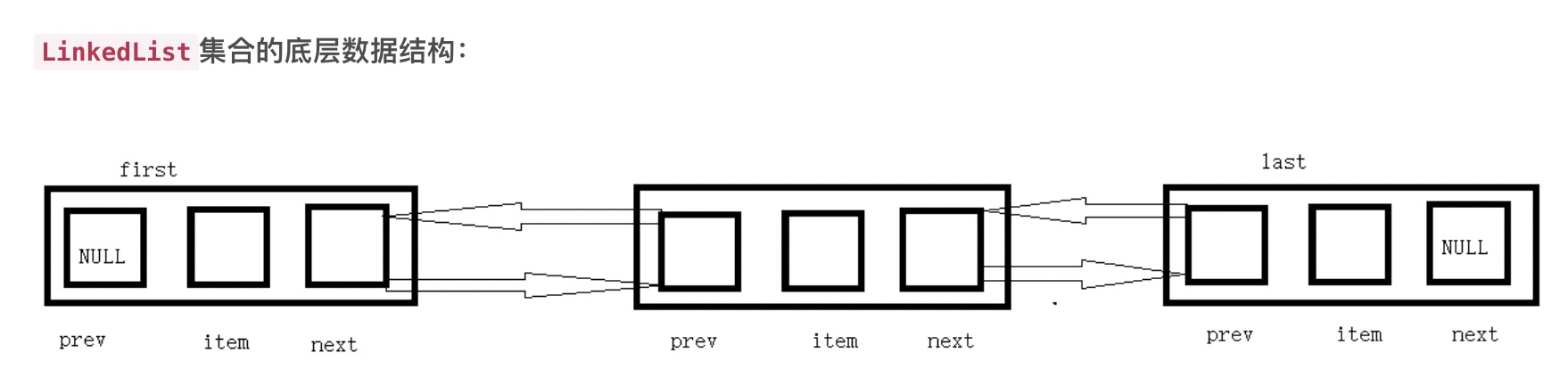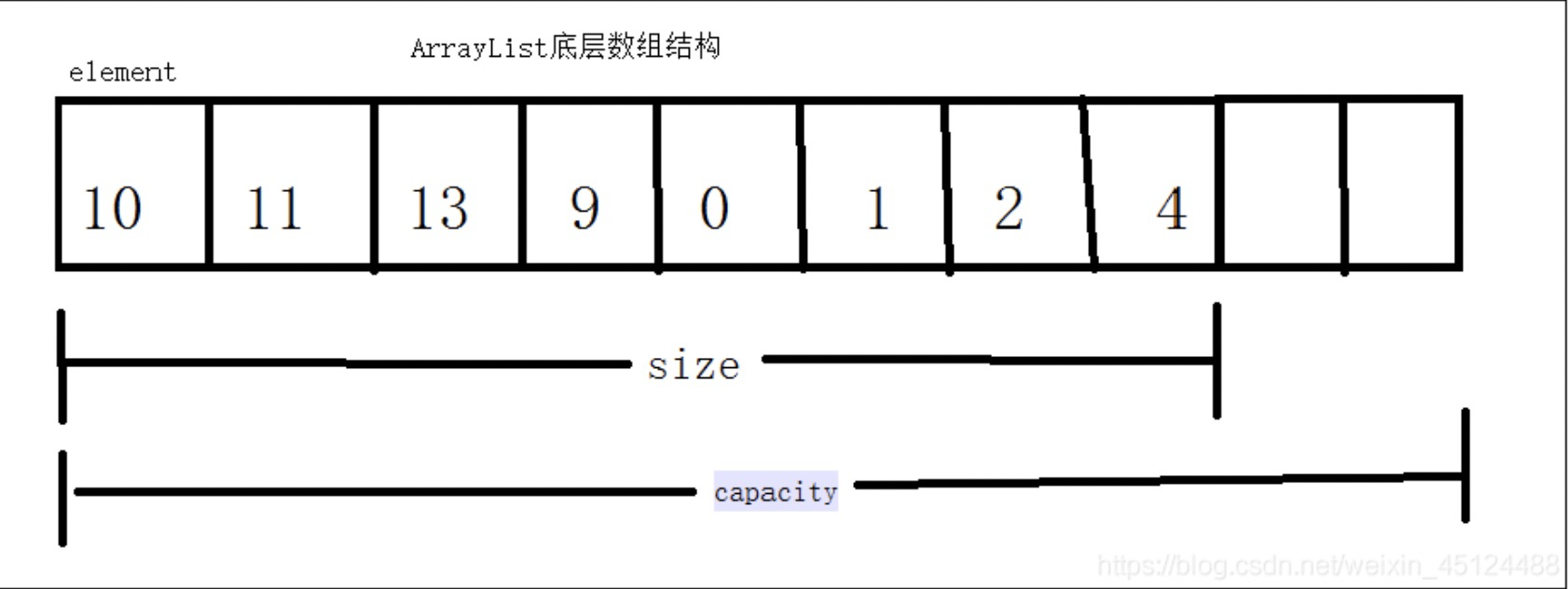
底层数据结构不同,ArrayList和Vector都是基于动态数组实现的,LinkedList是基于双向链表实现的。
扩容机制:
ArrayList是由Object类型的数组实现的,如果传入初始容量参数,则创建一个initialCapacity大小的数组,如果没有传入initialCapacity,那么创建一个默认大小(10)的数组,当存入的元素超过数组长度时,ArrayList会在内存中分配一个更大的数组来重新容纳这些元素,把原来的复制过来,因此可以将ArrayList集合看作一个长度可变的数组;由ensureCapacity()方法确认ArrayList容量,然后由grow()方法扩容。.ArrayList扩容 原来的1.5倍
vcetor扩容:是由一个增长系数决定。
Vector初始为10 ArrayList初始为0 第一次添加元素才为10
Vector扩容为2倍 ArrayList为1.5倍
linkedlist:它是一个双向链表,没有初始化大小,也没有扩容的机制,就是一直在前面或者后面新增就好。没有初始大小 不需要扩容 可以充分利用碎片空间
vector线程安全的,另外两个都是线程不安全的。
List集合中常用方法:
add(Object object):向集合中添加数据
get(int index):获取集合中指定的索引位置的元素数值
size():获取集合的长度
isEmpty():判断集合是否为空
contains(Object object);//判断结合中是否含有指定的这个元素
set(int index, Object object):更改集合中指定索引位置的元素数值
toArray():将集合转换为数组
remove(int index):删除集合中指定索引位置的元素数值
clear():清空集合元素数值,谨慎使用
3.Map
Map与Collection在集合框架中属并列存在
Map存储的是键值对
Map存储元素使用put方法,Collection使用add方法
Map集合没有直接取出元素的方法,而是先转成Set集合,在通过迭代获取元素
也就是Collection是单列集合, Map 是双列集合。
Map 的键不能重复,保证唯一,数据以键值对的形式存在.键与值存在映射关系.一定要保证键的唯一性.
1.hashmap
- HashMap() 不带参数,默认初始化大小为16,加载因子为0.75;扩容2的n次幂
- HashMap(int initialCapacity) 指定初始化大小;
- HashMap(int initialCapacity, float loadFactor) 指定初始化大小和加载因子大小;
(1)JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法:
JDK1.7是用单链表进行的纵向延伸,采用头插法能够提高插入的效率,会出现逆序且环形链表死循环问题。
JDK1.8之后加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
(2) JDK1.7是数组+ 单链表
JDK1.8及之后时,使用的是数组+链表+红黑树的数据结构
当链表长度达到8(默认阈值),数组容量大于64,就会自动扩容把链表转成红黑树,把时间复杂度从O(n)变成O(nlogN)提高了效率)
(3)当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值,即当前数组的长度乘以加载因子的值的时候,就会自动扩容,方法是使用一个新的数组代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里
小结:
(1) 扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
(2) 负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。
(3) HashMap是线程不安全的,不要在并发的环境中同时操作HashMap,建议使用ConcurrentHashMap。
(4) JDK1.8引入红黑树大程度优化了HashMap的性能。
1、HashMap线程不安全原因:
HashMap的存储数据结构,通过给Map的key计算hash值,然后决定value放到数组的对应索引位置上,这样就可以通过计算key的hash值,直接去数组中拿到value。
//当key冲突(不同的key生成的hash值是 相同的)的时候,就需要把多个value放到同一个位置,这时候,jdk1.7以前就是通过链表的方式挂在同一个位置上,jdk1.8以后就是通过平衡树的方式来代替链表的方式(这样就是怕出现冲突太多,链表太长,影响HashMap的性能)。
当我们多个线程同时插入数据库的时候就会出现线程不安全,putVal()是put()方法中调用的
由于put()和putVal()代码没有同步,插入一个value的时候会进行判空处理,在多线程的时候,如果正好2个线程都检查到对应位置是空的,都会插进去的话,先插进去的就会被后插进去的节点覆盖,而不是都挂在后面。就会出现数据错误,导致线程不安全
2.为什么Hashtable是线程安全的
因为它的remove,put,get做成了同步方法,保证了Hashtable的线程安全性。每个操作数据的方法都进行同步控制之后,只能有一个线程可以操纵Hashtable,所以其效率比较低。
2.红黑树
在红黑树中新加节点和删除节点时,如果需要调整红黑树时就会涉及到节点的左旋和右旋。
左旋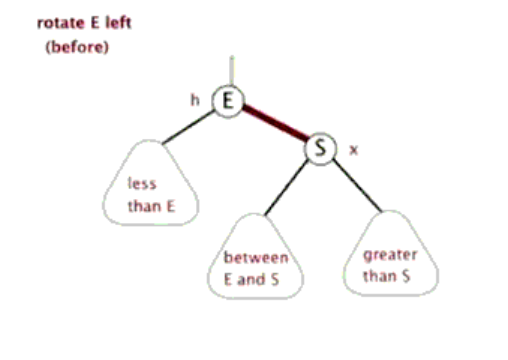
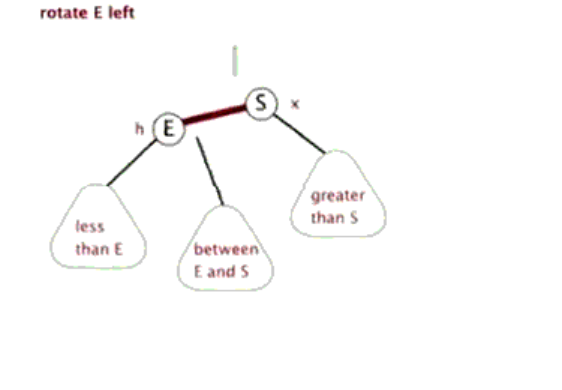
反之右旋
2.Map集合遍历
五、常见的 HashMap 的迭代方式
在实际开发过程中,我们对于 HashMap 的迭代遍历也是常见的操作,HashMap 的迭代遍历常用方式有如下几种:
方式一:迭代器模式
Map<String, String> map = new HashMap<>(16);Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();while (iterator.hasNext()) {Map.Entry<String, String> next = iterator.next();System.out.println(next.getKey() + ":" + next.getValue());}123456
方式二:遍历 Set>方式
Map<String, String> map = new HashMap<>(16);for (Map.Entry<String, String> entry : map.entrySet()) {System.out.println(entry.getKey() + ":" + entry.getValue());}1234
方式三:forEach 方式(JDK8 特性,lambda)
Map<String, String> map = new HashMap<>(16);map.forEach((key, value) -> System.out.println(key + ":" + value));12
方式四:keySet 方式
Map<String, String> map = new HashMap<>(16);Iterator<String> keyIterator = map.keySet().iterator();while (keyIterator.hasNext()) {String key = keyIterator.next();System.out.println(key + ":" + map.get(key));}123456
把这四种方式进行比较,前三种其实属于同一种,都是迭代器遍历方式,如果要同时使用到 key 和 value,推荐使用前三种方式,如果仅仅使用到 key,那么推荐使用第四种。
[
](https://blog.csdn.net/banzhuanhu/article/details/109605602)
3.HashMap和Hashtable的区别
(1) HashMap允许键和值是null,而 Hashtable不允许键或者值是null,ConCurrentHashMap都不允许
(2)hashtable出现的比较早,线程安全,hashmap线程不安全, HashMap更适合于单线程环境,Hashtable适合于多线程环境,HashMap 要比 HashTable 效率高一点
4.set
1、Set简介
① 元素是无序(存入和取出的顺序不一定一致),元素不可以重复;
② 查看Api会发现,set集合的功能与Collection集合的功能是一致的(就方法调用而言);
③ HashSet哈希表存储
HashSet存入重复元素
<1>同姓名同年龄视为同一个人 ,重复元素
④ 底层数据结构是哈希表
5.set集合不能存放重复元素的问题
存12341,五个数,最后size=4;
2、HashSet
哈希表存储、重复元素存储底层探究
① 元素是无序(存入和取出的顺序不一定一致)
② set.add 底层调用了hashCode/equals
3、Treeset
TreeSet可以对set集合中元素进行排序
String实现了Comparable接口,所以可以直接进行排序
引用数据类型想要排序,必须实现Comparable接口
4、LinkedHashSet
1、有序
2、无索引
3、元素不可重复
使用场景:
去重的同时可以保证元素的有序
HashSet并不管什么顺序,不同的是LinkedHashSet会维护“插入顺序”。HashSet内部使用HashMap对象来存储它的元素,而LinkedHashSet内部使用LinkedHashMap对象来存储和处理它的元素。

若有收获,就点个赞吧
0 人点赞
