jdk1.8新特性
1.lambda表达式接口
Lambda表达式的基础语法:Java8引入了一个新的操作符“->”,箭头操作符将Lambda表达式拆分成两部分
左侧:Lambda表达式的参数列表
右侧:Lambda表达式中所需执行的功能,即Lambda体。
**语法格式一:无参数,无返回值 Runnable r2 = () -> System.out.println(“hello lambda”);
**语法格式二:有一个参数,并且无返回值 (x) -> System.out.print(x);
**语法格式三:若只有一个参数,小括号可以省略不写 x -> System.out.print(x);
**语法格式四:有两个以上的参数,有返回值,并且Lambda体中有多条语句
Comparator<Integer> c1 = (x, y) -> {System.out.print(Integer.compare(x, y)+"函数式接口");return Integer.compare(x, y);} ;c1.compare(1, 2);
**语法格式五:若Lambda体中只有一条语句,return和大括号都可以省略不写
Comparator c1 = (x,y) -> Integer.compare(x,y);
**语法格式六:Lambda表达式的参数列表的数据类型可以省略不写,因为JVM编译器可以通过上下文进行类型推断出数据类型
(Integer x,Integer y) -> Integre.compare(x,y);
2.optional容器
Optional 类(java.util.Optional) 是一个容器类,代表一个值存在或不存在,原来用null 表示一个值不存在,现在Optional 可以更好的表达这个概念。并且可以避免空指针异常。
Optional.of(T t) : 创建一个Optional 实例
Optional.empty() : 创建一个空的Optional 实例
Optional.ofNullable(T t):若t 不为null,创建Optional 实例,否则创建空实例
isPresent() : 判断是否包含值
orElse(T t) : 如果调用对象包含值,返回该值,否则返回t
orElseGet(Supplier s) :如果调用对象包含值,返回该值,否则返回s 获取的值
map(Function f): 如果有值对其处理,并返回处理后的Optional,否则返回Optional.empty()
flatMap(Funntion mapper):与map 类似,要求返回值必须是Optional
3.新增currenthashmap
1.数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
2.保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全。
3.锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
4.链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
5.查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
[
](https://blog.csdn.net/qq_22343483/article/details/98510619)
JDK1.7版本的CurrentHashMap的实现原理
在JDK1.7中ConcurrentHashMap采用了数组+Segment+分段锁的方式实现。
1.Segment(分段锁)
ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
2.内部结构
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。
ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作。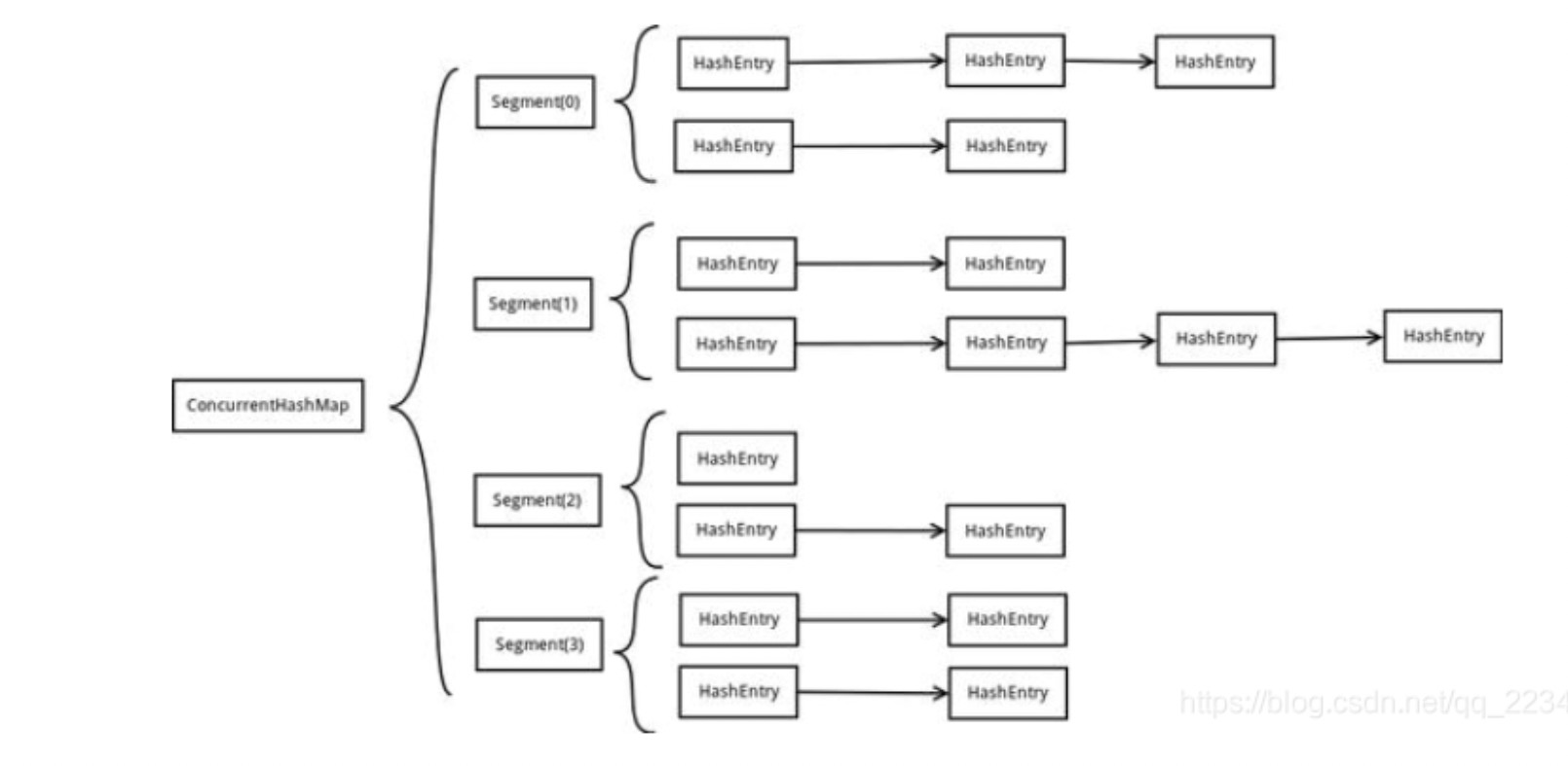
第一次Hash定位到Segment,
第二次Hash定位到元素所在的链表的头部。
3.该结构的优劣势
缺点
这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长
优点
写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上)。
所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
JDK1.8版本的CurrentHashMap的实现原理
JDK8中ConcurrentHashMap参考了JDK8 HashMap的实现,采用了数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作,这里我简要介绍下CAS。
CAS是compare and swap的缩写,即我们所说的比较交换。cas是一种基于锁的操作,而且是乐观锁。
在java中锁分为乐观锁和悲观锁。
悲观锁是将资源锁住,等一个之前获得锁的线程释放锁之后,下一个线程才可以访问。
而乐观锁采取了一种宽泛的态度,通过某种方式不加锁来处理资源,比如通过给记录加version来获取数据,性能较悲观锁有很大的提高。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存地址里面的值和A的值是一样的,那么就将内存里面的值更新成B。CAS是通过无限循环来获取数据的,若果在第一轮循环中,a线程获取地址里面的值被b线程修改了,那么a线程需要自旋,到下次循环才有可能机会执行。
JDK8中彻底放弃了Segment转而采用的是Node,其设计思想也不再是JDK1.7中的分段锁思想。
Node:保存key,value及key的hash值的数据结构。其中value和next都用volatile修饰,保证并发的可见性
java8 ConcurrentHashMap结构基本上和Java8的HashMap一样,不过保证线程安全性。
4.并行流
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
Java8中将并行进行了优化,可以很容易的对数据进行并行操作。Stream API可以声明性地通过**parallel()**与**sequential()**在并行流与顺序流之间进行切换。
Fork/Join框架:
在必要的情况下,将一个大任务进行必要的拆分Fork成若干个小任务,再将小任务的运算结果进行Join汇总。
Fork/Join框架和传统线程池的区别:
采用“工作窃取”模式(Working-stealing),即当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态,而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行,那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行,这种方式减少了线程等待的时间,提高了性能。
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API 可以声明性地通过parallel() 与sequential() 在并行流与顺序流之间进行切换。
自己实现的ForkJoin
/**
- JDK8的并行流实现。
*/
@Testpublic void test3(){Instant start = Instant.now();long sum = LongStream.rangeClosed(0, 1000000000L).parallel()//并行流//.sequential()//串行流.reduce(0, Long::sum);Instant end = Instant.now();System.out.println(Duration.between(start,end).toMillis());}
//并行流将会充分使用多核的优势,多线程并行执行,基数越大,效果越明显。其底层还是Fork/Join框架
5.hashmap
1.8之前:底层数据结构是数组加链表,数组是主体,链表主要是为了解决hash冲突(两个对象调用hashcode方法计算的哈希码值一致导致计算的数组索引值相同)
1.8之后:解决hash冲突时有了较大变
当链表长度大于阈值8(默认为8),并且数组长度大于64的时候,此时索引的位置上的数据改为使用红黑树储存,这两个条件必须同时满足,当链表大于8,数组长度小于64,只会扩容不会转换
因为数组比较小,查询效率相对来说并不慢,尽量避免红黑结构,否则效率变低,因为红黑树需要进行左旋右旋,变色来保持平衡。
1.HashMap
HashMap是线程不安全的,在多线程环境下,使用Hashmap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
2.HashTable
HashTable和HashMap的实现原理几乎一样,差别无非是
HashTable不允许key和value为null
HashTable是线程安全的

若有收获,就点个赞吧
0 人点赞
