一、redis基础问题
1. 五种基本数据类型
Redis 有 5 种基础数据结构,分别为:
string (字符串)
list (列表)
hash (哈希)
set (集合)
zset (有序集合)
2.redis的优点
i. 绝大部分请求是纯粹的内存操作(非常快速)
ii. 采用单线程,避免了不必要的上下文切换和竞争条件
iii. 非阻塞IO - IO多路复用
3.redis常用命令
一、String
| 命令 | 解释 |
|---|---|
| get key | 获取key的值 |
| set key v | 设置key的值 |
| del key | 删除key(应用于所有类型) |
| incr key | 将储存的值加上1 |
| decr key | 将储存的值减去1 |
| incrby key amout | 加上整数amount |
| decrby key amout | 减去整数amount |
| incrbybyfloat key amout | 加上浮点数amount字符串二进制 |
| append key v | 将值追加到key当前储存值的末尾 |
| getrange key start end | 获取下标start到end的字符串 |
| setrange key offset v | 将字符串看做二进制位串,并将位串中偏移量为offset的二进制位的值 |
| getbit key offset | 将字符串看做是二进制位串值为1的二进制位的数量,如果给定了可选的start偏移量和end偏移量,那么只对偏移量指定范围的二进制位进行统计 |
| bitop operation dest-key key-name [key-name …] | 对一个或多个二进制位串进行 并and,或 or,异或XOR,非NOT 在内的任意一种安位运算符操作(bitwise operation),并将计算的结果放到dest -key里面 |
二、list
| 命令 | 解释 |
|---|---|
| rpush key [v…] | 将一个或多个加入列表右端 |
| lpush key [v…] | 将一个或多个加入列表左端 |
| rpop key | 移除并返回最右端的元素 |
| lpop key | 移除并返回列表最左端的元素 |
| lindex key size | 返回下标(偏移量)为size的元素 |
| lrange key start end | 返回从start 到end的元素 包含start和end |
| ltrim key start end | 只保留从start 到end的元素 包含start和end |
三、hash
| 命令 | 解释 |
|---|---|
| hmget hkey key… | 获取多个值 |
| hmset hkey key v… | 为多个key设置值 |
| hdel hkey key… | 删除多个值并返回 |
| hlen hkey | 返回总数量 |
| hexists hkey key | 检查key是否存在在散列中 |
| hkeys hkey | 获取散列中所有key |
| hvals hkey | 获取三列中所有值 |
| hgetall hkey | 获取散列 |
| hincrby hkey key increment | 为key的值上加上整数increment |
| hincrbyfloat hkey key increment | 为key的值上加上浮点数increment |
四、set
| 命令 | 解释 |
|---|---|
| sadd key item … | 添加多个,返回新添加的个数(已存在的不算) |
| srem key item… | 从集合移除多个元素 ,返回被移除元素的数量 |
| sismember key item | 检查元素item是否在集合中 |
| scard key | 返回集合总数 |
| smembers key | 返回所有元素 |
| srandmember key cout | 随机返回cout个元素 cout为正整数 随机元素不重复 相反可能会出现重复 |
| spop key | 随机的移除一个元素 并返回已删除的元素 |
| smove key1 key2 item | 如果key1中包含item 移除key1中的item 添加到key2中,成功返回1 失败返回0 |
| 差运算 sdiffstore newkey key key1… | 将存在于key集合但是不存在key1…集合的其他元素 放到newkey里面(咬掉一口剩下的) |
| 交运算 sinter key… | 返回所有集合的交集(返回我们都有的的) |
| 交运算 sinterstore newkey key… | 返回多个集合的交集生成集合newkey |
| 并运算 sunion key… | (返回我们不重复的所有元素 ) |
| 并运算 sunion newkey key… | 结果放到newkey中 |
五、zset
| 命令 | 解释 |
|---|---|
| zadd key score member … | 添加多个 |
| zerm key memer… | 移除多个 |
| zcard key | 返回所有成员 |
| zincrby key incremnet member | 将member成员的分值加上increment |
| zcount key min max | 返回分值在 min和max中间的排名 |
| zrank key member | 返回成员member在集合中的排名 |
| zscore key member | 返回member的分值 |
| zrange key start stop | 返回 介于两者之间的成员 |
4.redis内存操作流流图
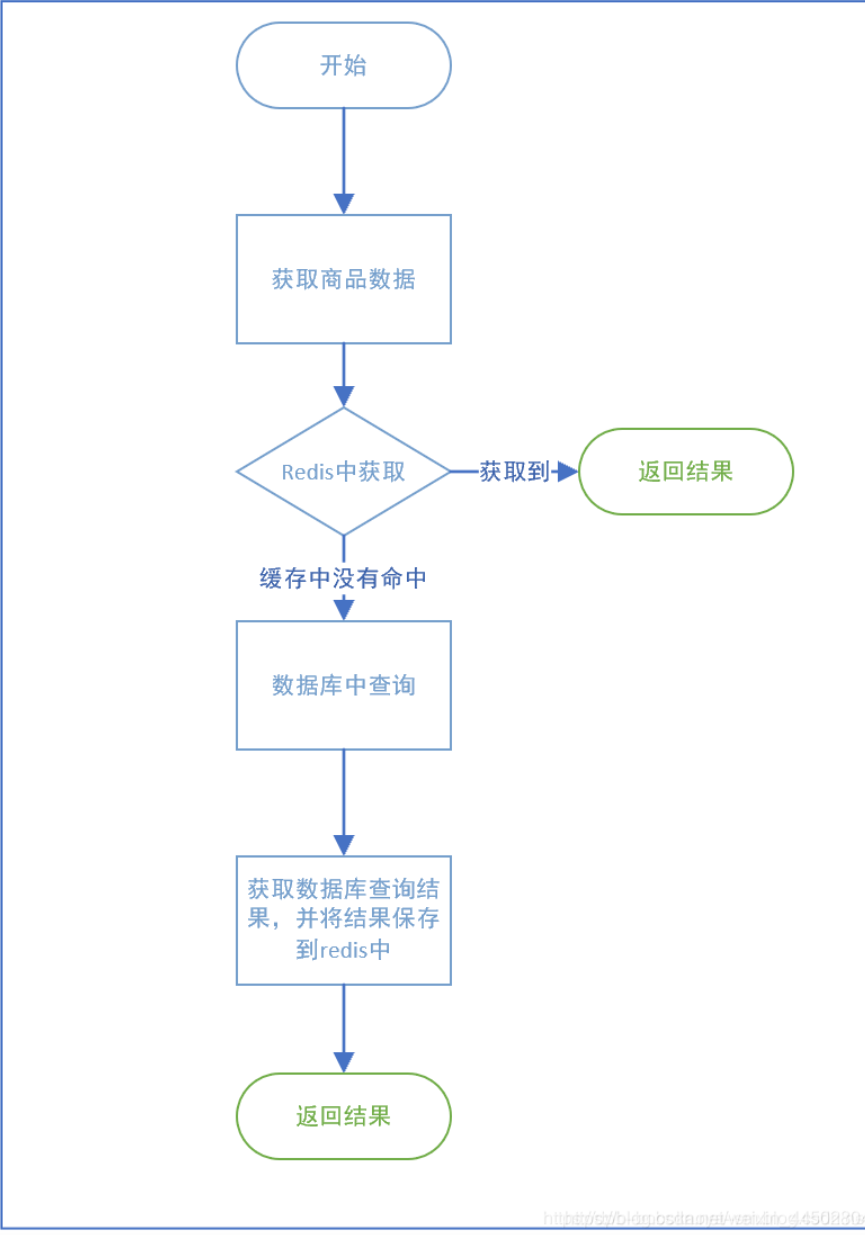
public Goods searchArticleById(Long goodsId){Object object = redisTemplate.opsForValue().get(String.valueOf(goodsId));if(object != null){// 缓存查询到了结果return (Goods)object;}// 开始查询数据库Goods goods = goodsMapper.selectByPrimaryKey(goodsId);if(goods!=null){// 将结果保存到缓存中redisTemplate.opsForValue().set(String.valueOf(goodsId),goods,60,TimeUnit.MINUTES);;}return goods;}
5.持久化机制
两种机制,**RDB(默认持久化方式)和AOF**<br /> rdb:按照一定周期性的策略,将数据保存到硬盘,对应生成一个dump系统文件,通过save参数定义快照的周期<br /> aof:将每一个收到的写命令通过write函数递加到文件中,重启会通过重新执行文件保存的写命令,在内存中重建一整个数据内容
二、过期策略&淘汰机制
1.过期策略
1.设置过期时间
四种方式
将 key 的过期时间设置为 ttl 秒
expire
将 key 的过期时间设置为 ttl 毫秒
pexpire
将 key 的过期时间设置为 timestamp 指定的秒数时间戳
expire
将 key 的过期时间设置为 timestamp 指定的毫秒数时间戳
pexpire
其中前三种方式都会转化为最后一种方式来实现过期时间
public Goods searchArticleById(Long goodsId){Object object = redisTemplate.opsForValue().get(String.valueOf(goodsId));if(object != null){// 缓存查询到了结果return (Goods)object;}// 开始查询数据库Goods goods = goodsMapper.selectByPrimaryKey(goodsId);if(goods!=null){Random random = new Random();// 将结果保存到缓存中if(goods.getGoodsCategory().equals("女装")){int time = 3600 + random.nextInt(3600);// 热门商品redisTemplate.opsForValue().set(String.valueOf(goodsId),goods,time,TimeUnit.MINUTES);}else{int time = 600 + random.nextInt(600);// 冷门商品redisTemplate.opsForValue().set(String.valueOf(goodsId),goods,time,TimeUnit.MINUTES);}}else{// 防止缓存穿透redisTemplate.opsForValue().set(String.valueOf(goodsId),null,60,TimeUnit.MINUTES);}return goods;}
2.保存过期时间
在 redisDb 结构的 expire 字典(过期字典)保存了所有键的过期时间
过期字典的键是一个指向键空间中的某个键对象的指针
过期字典的值保存了键所指向的数据库键的过期时间
3.判断过期键对象
通过查询过期字典,检查下面的条件判断是否过期
- 检查给定的键是否在过期字典中,如果存在就获取键的过期时间
- 检查当前 UNIX 时间戳是否大于键的过期时间,是就过期,否则未过期
4.删除过期键对象
惰性删除
在取出该键的时候对键进行过期检查,即只对当前处理的键做删除操作,不会在其他过期键上花费 CPU 时间
缺点:对内存不友好,如果一但键过期了,但会保存在内存中,如果这个键还不会被访问,那么久会造成内存浪费,甚至造成内存泄露
如何实现?
就是在执行 Redis 的读写命令前都会调用 expireIfNeeded 方法对键做过期检查
如果键已经过期,expireIfNeeded 方法将其删除
如果键未过期,expireIfNeeded 方法不做处理
定期删除
定期策略是每隔一段时间执行一次删除过期键的操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU 时间的影响,同时也减少了内存浪费
Redis 默认会每秒进行 10 次(redis.conf 中通过 hz 配置)过期扫描,扫描并不是遍历过期字典中的所有键,而是采用了如下方法
从过期字典中随机取出 20 个键
删除这 20 个键中过期的键
如果过期键的比例超过 25% ,重复步骤 1 和 2
为了保证扫描不会出现循环过度,导致线程卡死现象,还增加了扫描时间的上限,默认是 25 毫秒(即默认在慢模式下,如果是快模式,扫描上限是 1 毫秒)
所以我们在设置过期时间时,一定要避免同时大批量键过期的现象,所以如果有这种情况,最好给过期时间加个随机范围,缓解大量键同时过期,造成客户端等待超时的现象
定时删除
含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
优点:保证内存被尽快释放
若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key 定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
Redis 服务器采用惰性删除和定期删除这两种策略配合来实现,这样可以平衡使用 CPU 时间和避免内存浪费
2.Redis内存淘汰机制
内存淘汰机制就能保证在redis内存占用过高的时候,去进行内存淘汰,也就是删除一部分key,保证redis的内存占用率不会过高Redis目前共提供了8种内存淘汰策略,Redis 4.0版本之后又新增的两种LFU模式**:volatile-lfu和allkeys-lfu**。
no-eviction
1.当内存不足以容纳新写入数据时,新写入操作会报错,无法写入新数据,一般不采用。
allkeys-lru
当内存不足以容纳新写入数据时,移除最近最少使用的key,这个是最常用的
volatile-lru
当内存不足以容纳新写入数据时,在设置了过期时间的key中,移除最近最少使用的key。
allkeys-random
当内存不足以容纳新写入的数据时,随机移除key
volatile-random
内存不足以容纳新写入数据时,在设置了过期时间的key中,随机移除某个key 。
4.0新allkeys-lfu
当内存不足以容纳新写入数据时,移除最不经常(最少)使用的key
4.0新volatile-lfu
当内存不足以容纳新写入数据时,在设置了过期时间的key中,移除最不经常(最少)使用的key
volatile-ttl
当内存不足以容纳新写入数据时,在设置了过期时间的key中,优先移除剩余存活时间最短的key。
三、redis缓存穿透、雪崩
雪崩
数据未加载到缓存中,或者缓存同一时间大面积的失效,从而导致所有请求都去查数据库,导致数据库CPU和内存负载过高,甚至宕机。
雪崩的简单过程:
1、redis集群大面积故障
2、缓存失效,但依然大量请求访问缓存服务redis
3、redis大量失效后,大量请求转向到mysql数据库
4、mysql的调用量暴增,很快就扛不住了,甚至直接宕机
5、由于大量的应用服务依赖mysql和redis的服务,这个时候很快会演变成各服务器集群的雪崩,最后网站彻底崩溃。
如何预防缓存雪崩?
在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
对于“Redis挂掉了,请求全部走数据库”这种情况,我们可以有以下的思路:
事发前:实现Redis的高可用(主从架构+Sentinel 或者Redis Cluster),尽量避免Redis挂掉这种情况发生。
事发中:万一Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
事发后:redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
1.缓存的高可用性
缓存层设计成高可用,防止缓存大面积故障。即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如 Redis Sentinel 和 Redis Cluster 都实现了高可用。
2.缓存降级
可以利用ehcache等本地缓存(暂时支持),但主要还是对源服务访问进行限流、资源隔离(熔断)、降级等。
当访问量剧增、服务出现问题仍然需要保证服务还是可用的。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级,这里会涉及到运维的配合。
降级的最终目的是保证核心服务可用,即使是有损的。
比如推荐服务中,很多都是个性化的需求,假如个性化需求不能提供服务了,可以降级补充热点数据,不至于造成前端页面是个大空白。
在进行降级之前要对系统进行梳理,比如:哪些业务是核心(必须保证),哪些业务可以容许暂时不提供服务(利用静态页面替换)等,以及配合服务器核心指标,来后设置整体预案,比如:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
3.Redis备份和快速预热
(1)Redis数据备份和恢复
(2)快速缓存预热
4.提前演练
最后,建议还是在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,对高可用提前预演,提前发现问题。
穿透
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。<br />解决思路:<br />由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者压缩filter提前拦截,不合法就不让这个请求到数据库层!<br /> 当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。<br />这种情况我们一般会将空对象设置一个较短的过期时间。<br /> 如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。设置一个过期时间或者当有值的时候将缓存中的值替换掉即可。可以给key设置一些格式规则,然后查询之前先过滤掉不符合规则的Key。
缓存并发
这里的并发指的是多个redis的client同时set
key引起的并发问题。其实redis自身就是单线程操作,多个client并发操作,按照先到先执行的原则,先到的先执行,其余的阻塞。当然,另外的解决方案是把redis.set操作放在队列中使其串行化,必须的一个一个执行。
缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。
这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决思路:
1、直接写个缓存刷新页面,上线时手工操作下;
2、数据量不大,可以在项目启动的时候自动进行加载;
目的就是在系统上线前,将数据加载到缓存中。

若有收获,就点个赞吧
0 人点赞
