RPC (远程过程调用)
RPC 就是 Remote Procedure Call,远程过程调用,它相对应的是本地过程调用。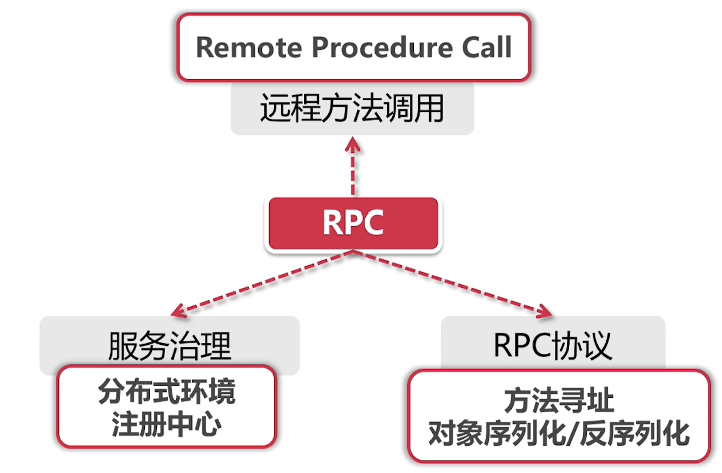
RPC VS REST HTTP
接口风格
RPC(动词命名)queryProduct 【面向执行过程】
REST (名词) {GET}/product?id=3【面向所操作的资源】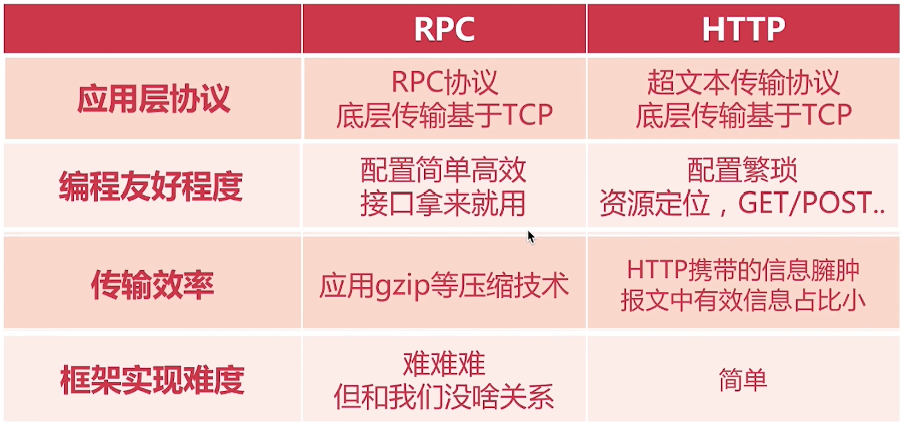
HTTP 只是传输协议,协议只是规范了一定的交流格式。
RPC 对比的是本地过程调用,是用来作为分布式系统之间的通信,它可以用 HTTP 来传输,也可以基于 TCP 自定义协议传输。
HTTP 协议比较冗余,所以 RPC 大多都是基于 TCP 自定义协议,定制化的才是最适合自己的。
但像 HTTP2 已经做了相应的压缩了,而且系统之间的调用都在内网,所以说影响也不会很大。

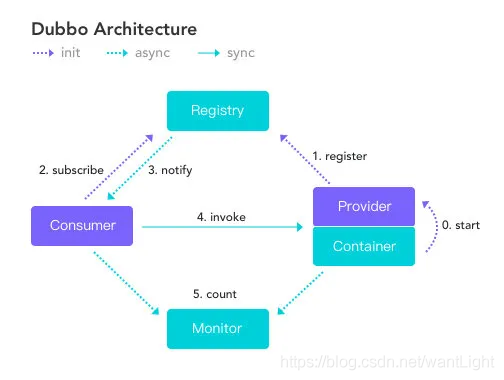
Dubbo架构设计解析
| 节点 | 角色说明 |
|---|---|
| Consumer | 需要调用远程服务的服务消费方 |
| Registry | 注册中心 |
| Provider | 服务提供方 |
| Container | 服务运行的容器 |
| Monitor | 监控中心,用来统计服务调用的频率和响应时间 |
- Start:服务容器启动后初始化服务提供者。
- Register :服务提供者 Provider 向注册中心注册自己所能提供的服务。
Subscribe :服务消费者 Consumer 启动向注册中心订阅自己所需的服务。
这一个流程就和Eureka就大不相同了,Eureka是Consumer主动到服务中心去拉取数据,而Dubbo采用了一种Pub/Sub模式,也就是发布订阅模型
Notify :注册中心将Provider 提供者元信息通知给 Consumer(建立在长连接之上)
Invoke :服务消费者发起远程调用,这个过程会使用负载均衡算法挑选目标服务器
Consumer 因为已经从注册中心获取提供者的地址,因此可以通过负载均衡选择一个 Provider 直接调用 。
服务提供方元数据变更的话注册中心会把变更推送给服务消费者。
- 服务提供者和消费者都会在内存中记录着调用的次数和时间,然后定时的发送统计数据到监控中心(平时这些信息就暂存于内存当中)。
注册中心和监控中心是可选的,你可以不要监控,也不要注册中心,直接在配置文件里面写然后提供方和消费方直连。
注册中心、提供方和消费方之间都是长连接,和监控方不是长连接,并且消费方是直接调用提供方,不经过注册中心。
就算注册中心和监控中心宕机了也不会影响到已经正常运行的提供者和消费者,因为消费者有本地缓存提供者的信息。
Dubbo和Eureka中服务发现的不同
服务发现应该是Dubbo和Eureka最大的一个不同之处。
Dubbo里的注册中心、Provider和Consumer三者之间都是长连接,借助于Zookeeper的高吞吐量,实现基于服务端的服务发现机制。因此Dubbo利用Zookeeper+发布订阅模型可以很快将服务节点的上线和下线同步到Consumer集群。如果服务提供者宕机,那么注册中心的长连接会立马感知到这个事件,并且立即推送通知到消费者。
在服务发现的做法上Dubbo和Eureka有很大的不同,Eureka使用客户端的服务发现机制,因此对服务列表的变动响应会稍慢,比如在某台机器下线以后,在一段时间内可能还会陆续有服务请求发过来,当然这些请求会收到Service Unavailable的异常,需要借助Ribbon或Hystrix实现重试或者降级措施。
对于注册中心宕机的情况,Dubbo和Eureka的处理方式相同,这两个框架的服务节点都在本地缓存了服务提供者的列表,因此仍然可以发起调用,但服务提供者列表无法被更新,因此可能导致本地缓存的服务状态与实际情况有别。
Dubbo 分层架构
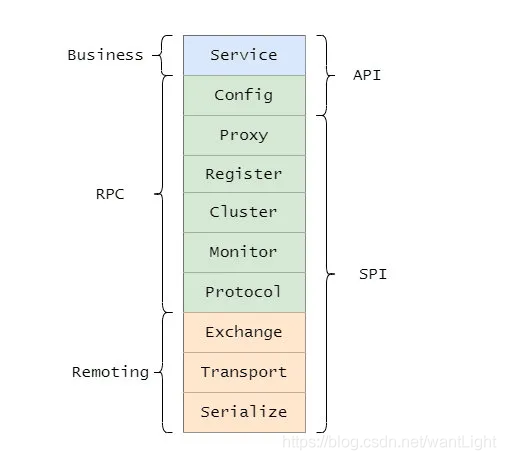
大的三层分别为 Business(业务层)、RPC 层、Remoting,并且还分为 API 层和 SPI 层。
而分 API 层和 SPI 层这是 Dubbo 成功的一点,采用微内核设计+SPI扩展,使得有特殊需求的接入方可以自定义扩展,做定制的二次开发。
每层功能
- Service,业务层,就是咱们开发的业务逻辑层。
- Config,配置层,主要围绕 ServiceConfig 和 ReferenceConfig,初始化配置信息。
- Proxy,代理层,服务提供者还是消费者都会生成一个代理类,使得服务接口透明化,代理层做远程调用和返回结果。
- Register,注册层,封装了服务注册和发现。
- Cluster,路由和集群容错层,负责选取具体调用的节点,处理特殊的调用要求和负责远程调用失败的容错措施。
- Monitor,监控层,负责监控统计调用时间和次数。
- Portocol,远程调用层,主要是封装 RPC 调用,主要负责管理 Invoker,Invoker代表一个抽象封装了的执行体,之后再做详解。
- Exchange,信息交换层,用来封装请求响应模型,同步转异步。
- Transport,网络传输层,抽象了网络传输的统一接口,这样用户想用 Netty 就用 Netty,想用 Mina 就用 Mina。
- Serialize,序列化层,将数据序列化成二进制流,当然也做反序列化。
SPI (JDK 内置的一个服务发现机制)
它使得接口和具体实现完全解耦。我们只声明接口,具体的实现类在配置中选择。定义了一个接口,然后在META-INF/services目录下放置一个与接口同名的文本文件,文件的内容为接口的实现类,多个实现类用换行符分隔。
Dubbo的服务暴露过程
URL
Dubbo 就是采用 URL 的方式来作为约定的参数类型,被称为公共契约,就是我们都通过 URL 来交互,来交流。
protocol://username:password@host:port/path?key=value&key=value
- protocol:指的是 dubbo 中的各种协议,如:dubbo thrift http
- username/password:用户名/密码
- host/port:主机/端口
- path:接口的名称
- parameters:参数键值对
配置解析
一般常用 XML 或者注解来进行 Dubbo 的配置。
Dubbo 利用了 Spring 配置文件扩展了自定义的解析,像 dubbo.xsd 就是用来约束 XML 配置时候的标签和对应的属性用的,然后 Spring 在解析到自定义的标签的时候会查找 spring.schemas 和 spring.handlers。
spring.schemas 就是指明了约束文件的路径,而 spring.handlers 指明了利用该 handler 来解析标签
本质就是为了生成 Spring 的 BeanDefinition,然后利用 Spring 最终创建对应的对象。
服务暴露全流程
从代码的流程来看大致可以分为三个步骤(本文默认都需要暴露服务到注册中心)。
第一步是检测配置,如果有些配置空的话会默认创建,并且组装成 URL 。
第二步是暴露服务,包括暴露到本地的服务和远程的服务。
第三步是注册服务至注册中心。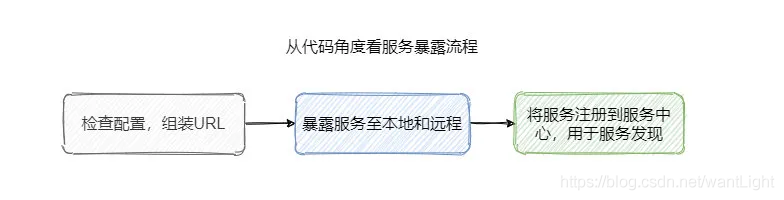
从对象构建转换的角度看可以分为两个步骤。
第一步是将服务实现类转成 Invoker。
第二部是将 Invoker 通过具体的协议转换成 Exporter。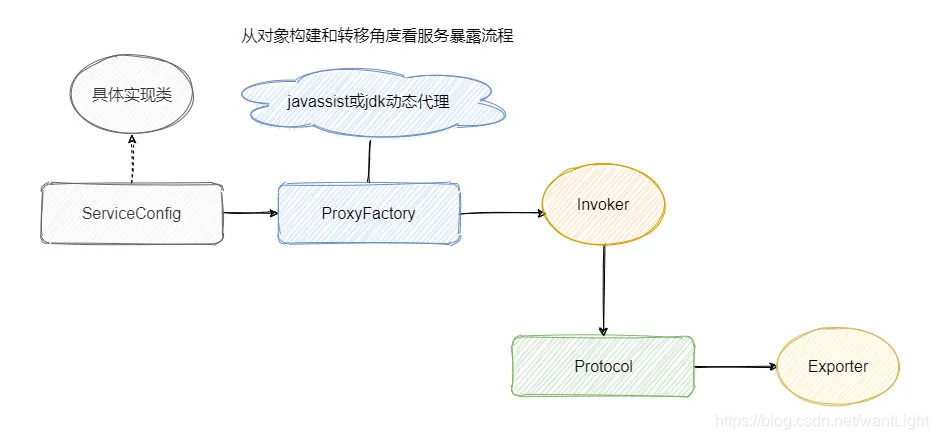
服务暴露源码分析
1. ServiceBean
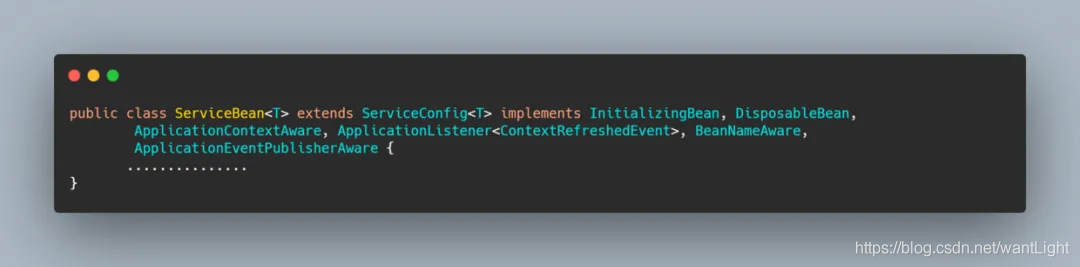
ServiceBean实现了 ApplicationListener,这样就会在 Spring IOC 容器刷新完成后调用 onApplicationEvent 方法,而这个方法里面做的就是服务暴露,这就是服务暴露的启动点。(如果不是延迟暴露、并且还没暴露过、并且支持暴露的话就执行 export 方法,而 export 最终会调用父类的 export 方法)
2. export 方法
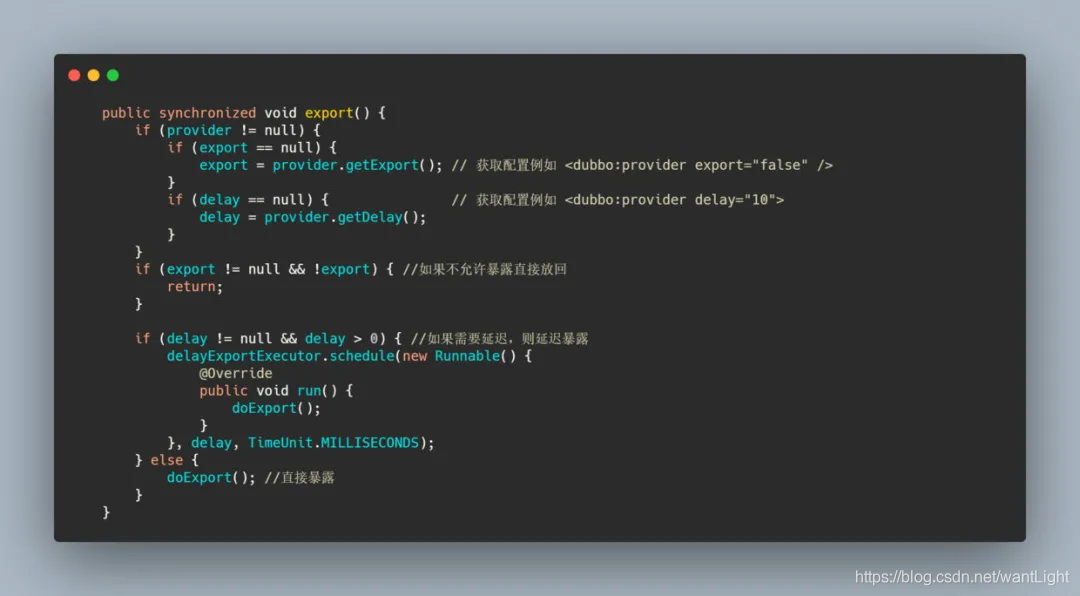
主要就是检查了一下配置,确认需要暴露的话就暴露服务, doExport 这个方法很长,不过都是一些检测配置的过程,虽说不可或缺不过不是我们关注的重点,我们重点关注里面的 doExportUrls 方法
3. doExportUrls
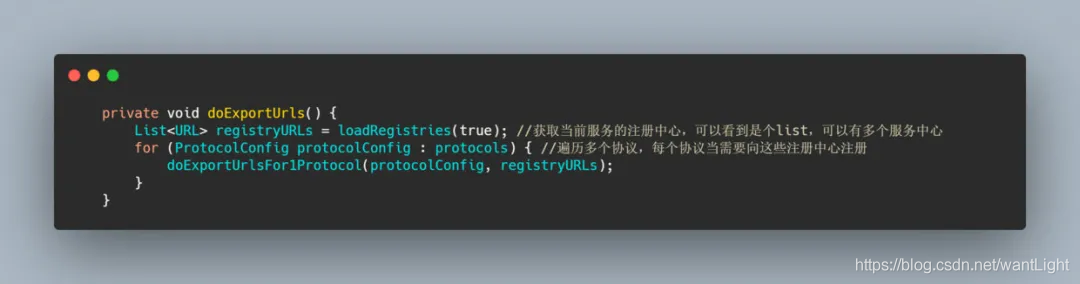
可以看到 Dubbo 支持多注册中心,并且支持多个协议,一个服务如果有多个协议那么就都需要暴露,比如同时支持 dubbo 协议和 hessian 协议,那么需要将这个服务用两种协议分别向多个注册中心(如果有多个的话)暴露注册。
4. loadRegistries 方法:根据配置组装成注册中心相关的 URL
registry://127.0.0.1:2181/com.alibaba.dubbo.registry.RegistryService?application=demo-provider&dubbo=2.0.2&pid=7960&qos.port=22222®istry=zookeeper×tamp=1598624821286
5. doExportUrlsFor1Protocol :构建URL,根据 URL 服务暴露。
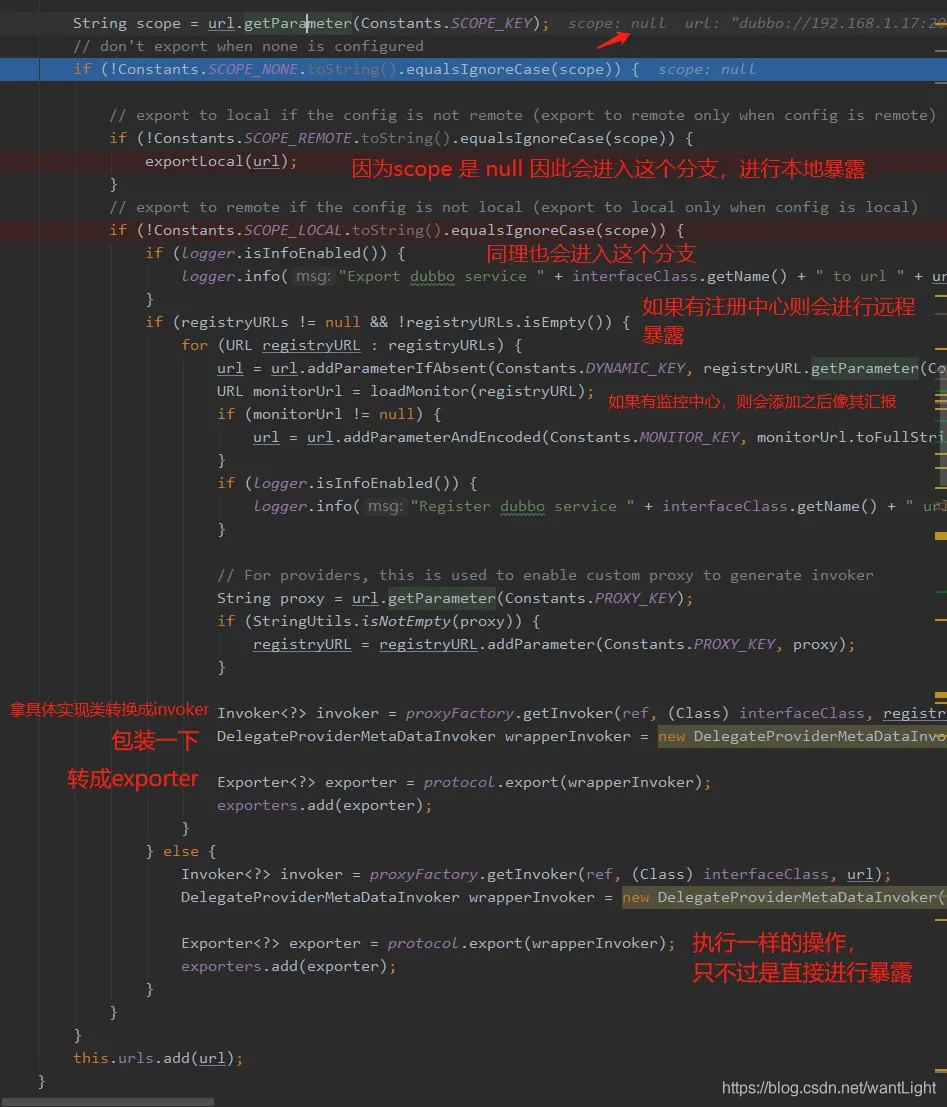
exportLocal (本地暴露):injvm 协议
exportLocal 方法,这个方法是本地暴露,走的是 injvm 协议,它搞了个新的 URL 修改了协议。
Protocol 的 export 方法是标注了 @ Adaptive 注解的,因此会生成代理类,然后代理类会根据 Invoker 里面的 URL 参数得知具体的协议,然后通过 Dubbo SPI 机制选择对应的实现类进行 export,而这个方法就会调用 InjvmProtocol#export 方法。
invoker 其实是由 Javassist 创建的。dubbo 为什么用 javassist 而不用 jdk 动态代理是因为 javassist 快。
为什么要封装成 invoker
想屏蔽调用的细节,统一暴露出一个可执行体,这样调用者简单的使用它,向它发起 invoke 调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。
为什么要搞个本地暴露
可能存在同一个 JVM 内部引用自身服务的情况,因此暴露的本地服务在内部调用的时候可以直接消费同一个 JVM 的服务避免了网络间的通信。
远程暴露:也和本地暴露一样,需要封装成 Invoker
走 registry 协议,然后参数里又有 export=dubbo://,这个走 dubbo 协议,所以我们可以得知会先通过 registry 协议找到 RegistryProtocol 进行 export,并且在此方法里面还会根据 export 字段得到值然后执行 DubboProtocol 的 export 方法。
将上面的 export=dubbo://… 先转换成 exporter ,然后获取注册中心的相关配置。
往一个 ConcurrentHashMap 中将塞入 invoker,key 就是服务接口全限定名,value 是一个 set,set 里面会存包装过的 invoker 。
根据URL上 Dubbo 协议暴露出 exporter。
Dubbo 协议的 export 主要就是根据 URL 构建出 key(例如有分组、接口名端口等等),然后 key 和 invoker 关联,关联之后存储到 DubboProtocol 的 exporterMap 中,然后如果是服务初次暴露则会创建监听服务器,默认是 NettyServer,并且会初始化各种 Handler 比如心跳啊、编解码等等。
通过 Dubbo SPI 扫包会把 wrapper 结尾的类(分别是 ProtocolFilterWrapper 和 ProtocolListenerWrapper)缓存起来,然后当加载具体实现类的时候会包装实现类,来实现 Dubbo 的 AOP。
对于所有的 Protocol 实现类来说就是这么个调用链。
总结
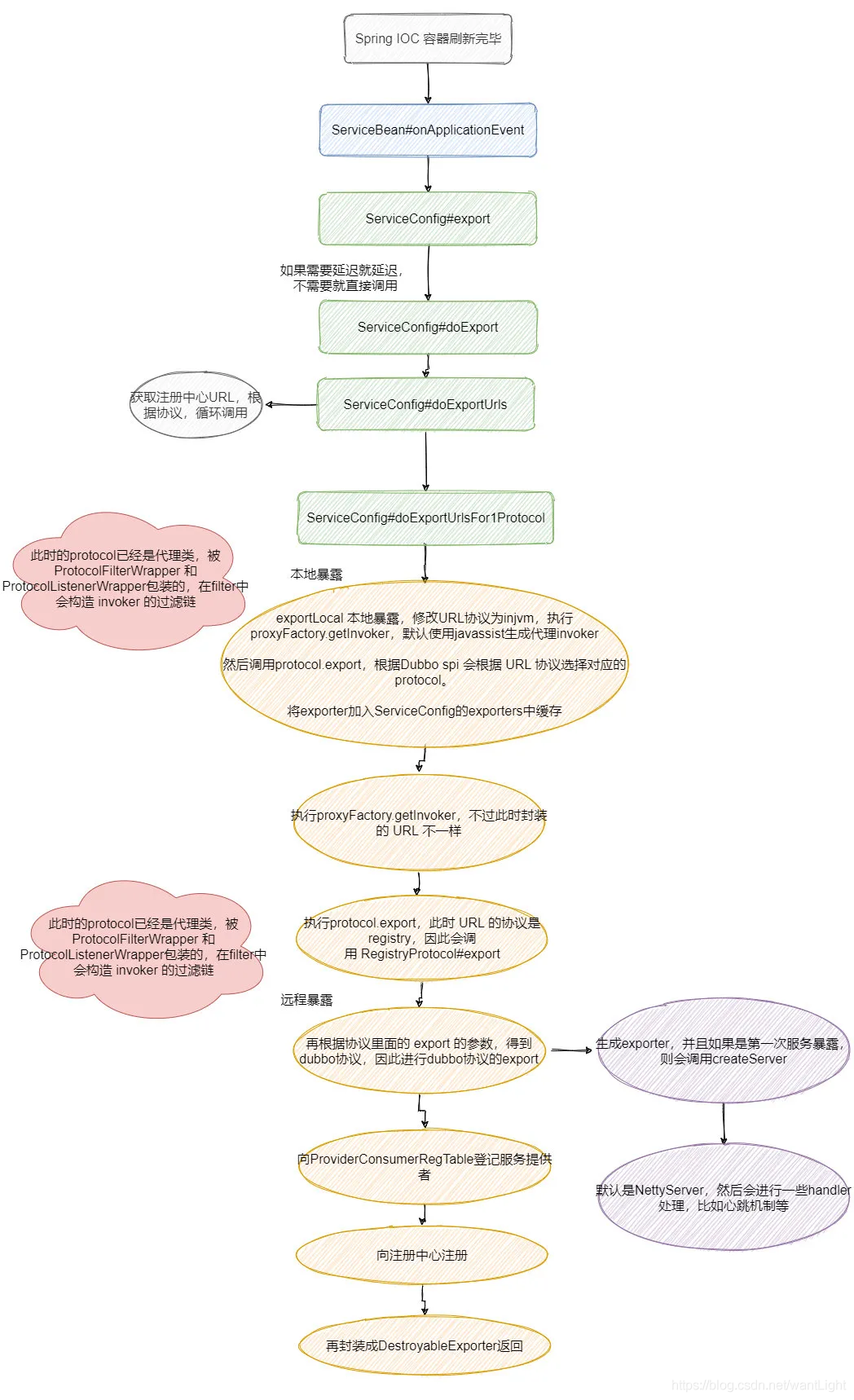
服务暴露的过程起始于 Spring IOC 容器刷新完成之时,具体的流程就是根据配置得到 URL,再利用 Dubbo SPI 机制根据 URL 的参数选择对应的实现类,实现扩展。
通过 javassist 动态封装 ref (你写的服务实现类),统一暴露出 Invoker 使得调用方便,屏蔽底层实现细节,然后封装成 exporter 存储起来,等待消费者的调用,并且会将 URL 注册到注册中心,使得消费者可以获取服务提供者的信息。
Dubbo服务引用过程
服务的引入和服务的暴露一样,也是通过 spring 自定义标签机制解析生成对应的 Bean,Provider Service 对应解析的是 ServiceBean 而 Consumer Reference 对应的是 ReferenceBean。
服务引入的时机
服务的引入时机有两种,第一种是饿汉式,第二种是懒汉式。
饿汉式是通过实现 Spring 的InitializingBean接口中的 afterPropertiesSet方法,容器通过调用 ReferenceBean的 afterPropertiesSet方法时引入服务。
懒汉式是只有当这个服务被注入到其他类中时启动引入流程,也就是说用到了才会开始服务引入。
默认情况下,Dubbo 使用懒汉式引入服务,如果需要使用饿汉式,可通过配置 dubbo:reference 的 init 属性开启。
服务引入的三种方式
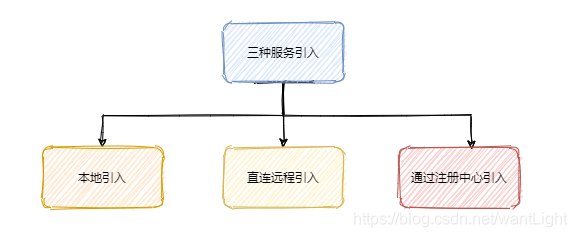
本地引入之前服务暴露的流程每个服务都会通过搞一个本地暴露,走 injvm 协议(当然你要是 scope = remote 就没本地引用了),因为存在一个服务端既是 Provider 又是 Consumer 的情况,然后有可能自己会调用自己的服务,因此就弄了一个本地引入,这样就避免了远程网络调用的开销。所以服务引入会先去本地缓存找找看有没有本地服务。
直连远程引入服务,平日测试的情况下用用,不需要启动注册中心,由 Consumer 直接配置写死 Provider 的地址,然后直连即可。
注册中心引入远程服务:Consumer 通过注册中心得知 Provider 的相关信息,然后进行服务的引入,这里还包括多注册中心,同一个服务多个提供者的情况,如何抉择如何封装,如何进行负载均衡、容错并且让使用者无感知。
源码分析
丙的链接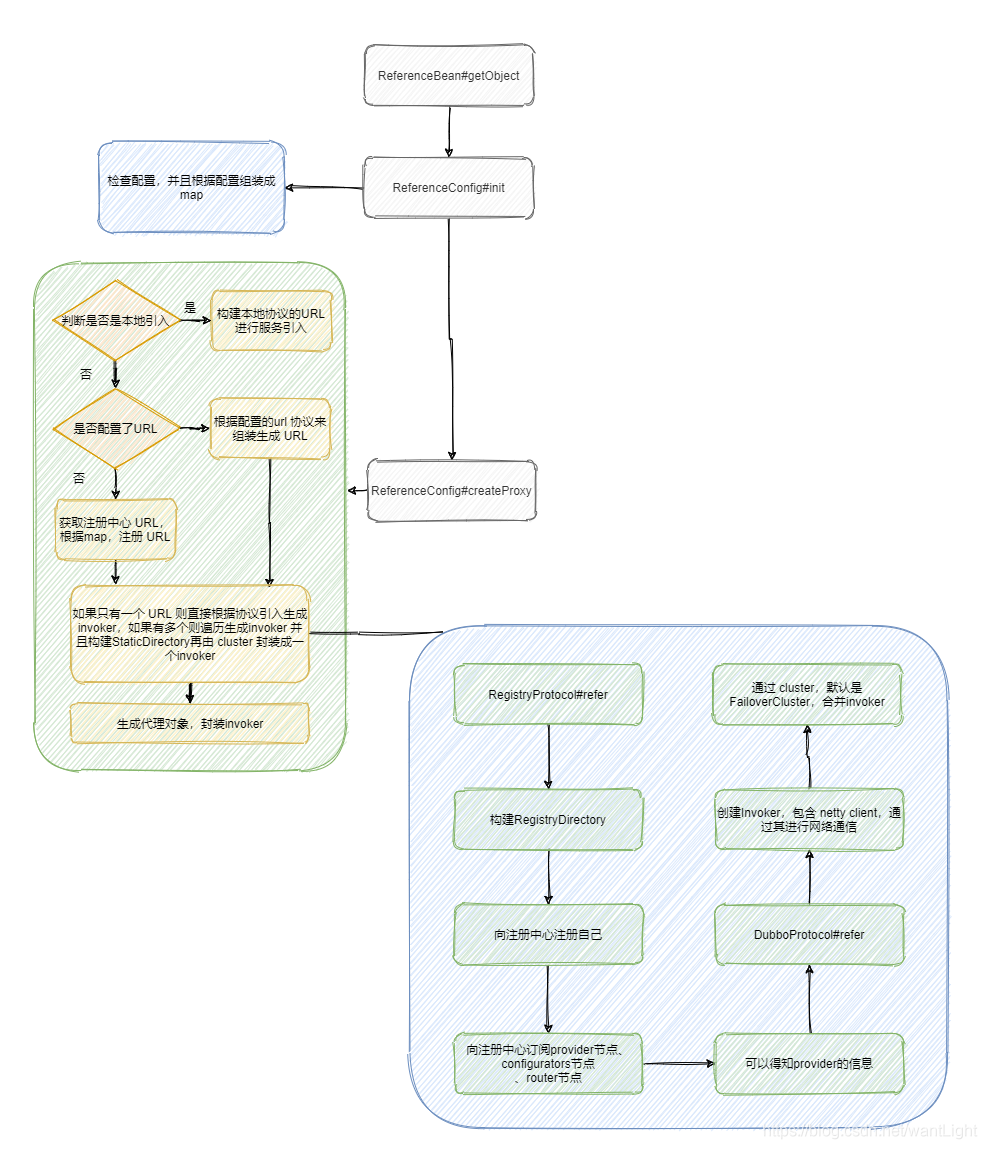
通过配置组成 URL ,然后通过自适应得到对于的实现类进行服务引入,如果是注册中心那么会向注册中心注册自己的信息,然后订阅注册中心相关信息,得到远程 provider的 ip 等信息,再通过netty客户端进行连接。
并且通过directory 和 cluster 进行底层多个服务提供者的屏蔽、容错和负载均衡等,这个之后文章会详细分析,最终得到封装好的 invoker再通过动态代理封装得到代理类,让接口调用者无感知的调用方法。
Dubbo服务调用过程
丙的链接
首先需要双方定义一个协议,这样计算机才能解析出正确的信息。
Dubbo 协议
Dubbo 协议属于 header+body 形式,而且也有特殊的字符 0xdabb 。头部里面会填写 body 的长度, body 是不固定长度的(用来解决 TCP 网络粘包)。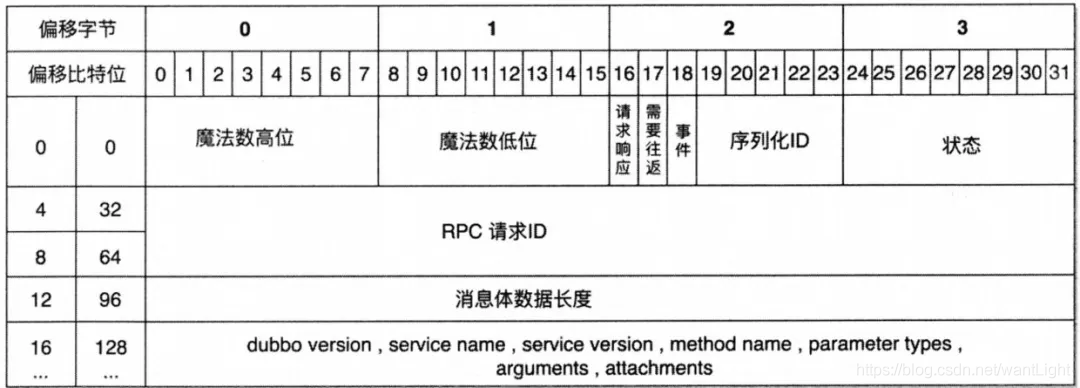
16 字节的头部主要携带了魔法数,也就是之前说的 0xdabb,然后一些请求的设置,消息体的长度等等。16 字节之后就是协议体了,包括协议版本、接口名字、接口版本、方法名字等等。
- 需要约定序列化器
- Dubbo 默认用的是 hessian2 序列化协议
Dubbo协议的适用场景
适用场景 传入传出参数数据包较小(建议小于100K),但是并发量高的场景。简单来说就是短平快,QPS/TPS高但是数据量小的情况
不适场景 尽量不要用Dubbo协议传输大数据包(比如大文件、视频、超大字符串等)源码分析
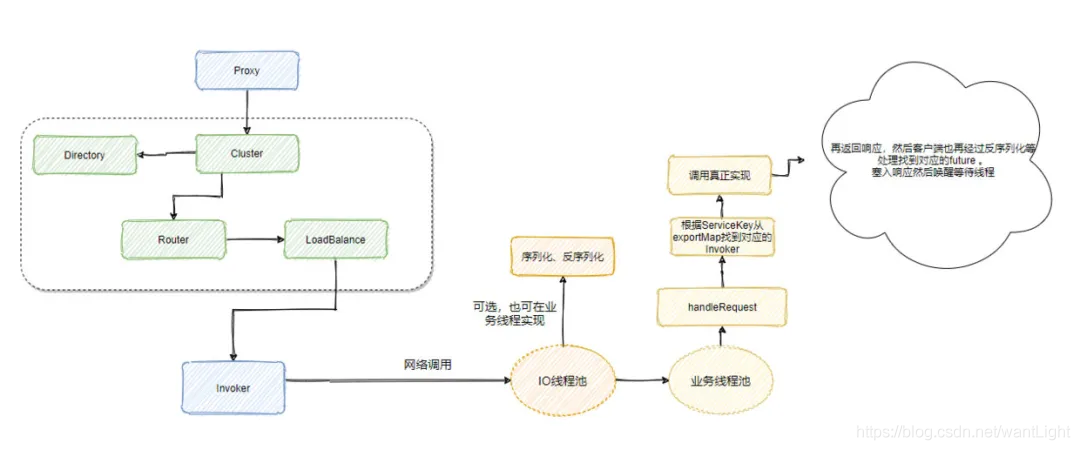
首先客户端调用接口的某个方法,实际调用的是代理类,代理类会通过 cluster 从 directory 中获取一堆 invokers(如果有一堆的话),然后进行 router 的过滤(其中看配置也会添加 mockInvoker 用于服务降级),然后再通过 SPI 得到 loadBalance 进行一波负载均衡。
现在我们已经得到要调用的远程服务对应的 invoker 了,此时根据具体的协议构造请求头,然后将参数根据具体的序列化协议序列化之后构造塞入请求体中,再通过 NettyClient 发起远程调用。
服务端 NettyServer 收到请求之后,根据协议得到信息并且反序列化成对象,再按照派发策略派发消息,默认是 All,扔给业务线程池。
业务线程会根据消息类型判断然后得到 serviceKey 从之前服务暴露生成的 exporterMap 中得到对应的 Invoker ,然后调用真实的实现类。
最终将结果返回,因为请求和响应都有一个统一的 ID, 客户端根据响应的 ID 找到存储起来的 Future, 然后塞入响应再唤醒等待 future 的线程,完成一次远程调用全过程。
Dubbo中的负载均衡解析
RandomLoadBalance - 权重算法
RandomLoadBalance是Dubbo的缺省实现,所谓权重算法,实际上是加权随机算法的意思。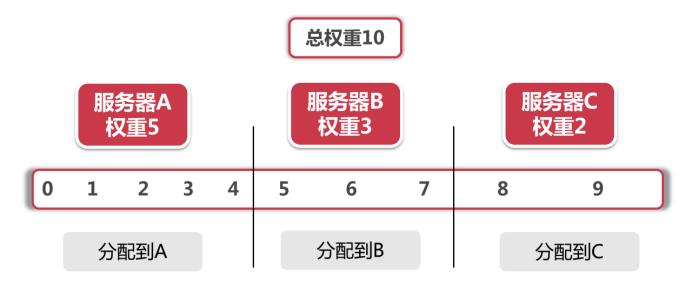
LeastActiveLoadBalance - 最少活跃数
这个算法的思想就是“能者多劳”,它认为当前活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求,因此应优先将请求分配给该服务提供者。
ConsistentHashLoadBalance - Hash算法
一致性Hash算法由麻省理工学院的Karger及其合作者于1997年提出的,算法提出之初是用于大规模缓存系统的负载均衡。
在Dubbo中它的工作流程是这样的:
首先根据服务地址为服务节点生成一个Hash,并将这个Hash 投射到 [0, 232 - 1] 的圆环上
当有请求到来时,根据请求参数等维度的信息作为一个Key,生成一个 hash 值。然后查找第一个大于或等于该Hash值的服务节点,并将这个请求转发到该节点。
如果当前节点挂了,则查找另一个大于其Hash值的缓存节点即可。
RoundRobinLoadBalance - 加权轮询
轮询是指将请求轮流分配给每台服务器。比如说我们有3台机器A、B、C,当请求到来的时候我们从A开始依次派发,第一个请求给A,第二个给B,依次类推,到最后一个节点C派发完之后再回到A重新开始。
从上面的例子中可以看出,每台机器接到请求的概率是相等的,但是在实际应用中我们并不能保证每台机器的效率都一样,因此可能会出现某台Server性能特别慢导致无法消化请求的情况。因此我们需要对轮询过程进行加权,以调控每台服务器的负载。
配置负载均衡策略
Dubbo可以在类级别(@Service)和方法级别(@Resource)指定负载均衡策略,以方法级别为例,下面的代码配置了使用RoundRobin的负载均衡规则:
@Reference(loadbalance = “roundrobin”)
private IDubboService dubboService;
Dubbo的相关问题
简述服务暴露流程
服务的暴露起始于 Spring IOC 容器刷新完毕之后,会根据配置参数组装成 URL, 然后根据 URL 的参数来进行本地或者远程调用。
通过 proxyFactory.getInvoker,利用 javassist 来进行动态代理,封装真的实现类,然后再通过 URL 参数选择对应的协议来进行 protocol.export,默认是 Dubbo 协议。
在第一次暴露的时候会调用 createServer 来创建 Server,默认是 NettyServer。
然后将 export 得到的 exporter 存入一个 Map 中,供之后的远程调用查找,然后会向注册中心注册提供者的信息。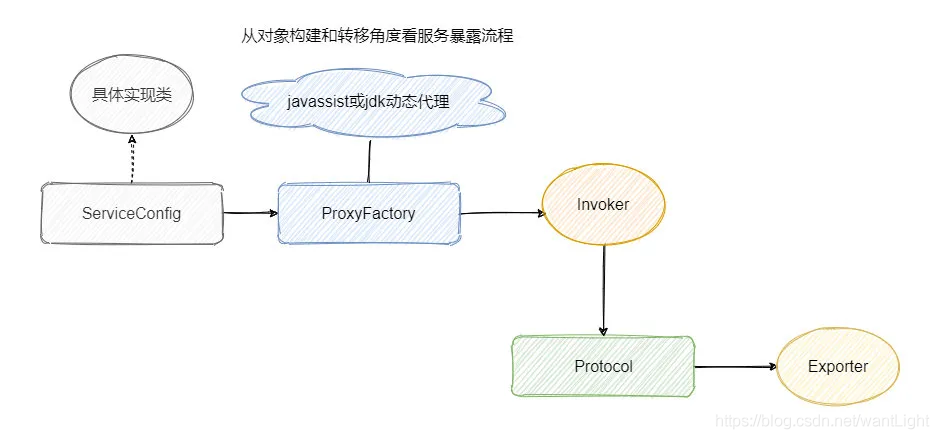
Dubbo 为什么默认用 Javassist 动态代理 (快,且字节码生成方便)
ASM 比 Javassist 更快,但是没有快一个数量级,而Javassist 只需用字符串拼接就可以生成字节码,而 ASM 需要手工生成,成本较高,比较麻烦。
简述服务引入流程
服务的引入时机有两种,第一种是饿汉式,第二种是懒汉式。
饿汉式就是加载完毕就会引入,懒汉式是只有当这个服务被注入到其他类中时启动引入流程,默认是懒汉式。
会先根据配置参数组装成 URL ,一般而言我们都会配置的注册中心,所以会构建 RegistryDirectory 向注册中心注册消费者的信息,并且订阅提供者、配置、路由等节点。
得知提供者的信息之后会进入 Dubbo 协议的引入,会创建 Invoker ,期间会包含 NettyClient,来进行远程通信,最后通过 Cluster 来包装 Invoker,默认是 FailoverCluster,最终返回代理类。
服务调用流程
调用某个接口的方法会调用之前生成的代理类,然后会从 cluster 中经过路由的过滤、负载均衡机制选择一个 invoker 发起远程调用,此时会记录此请求和请求的 ID 等待服务端的响应。
服务端接受请求之后会通过参数找到之前暴露存储的 map,得到相应的 exporter ,然后最终调用真正的实现类,再组装好结果返回,这个响应会带上之前请求的 ID。
消费者收到这个响应之后会通过 ID 去找之前记录的请求,然后找到请求之后将响应塞到对应的 Future 中,唤醒等待的线程,最后消费者得到响应,一个流程完毕。(Dubbo 默认是异步)
什么是 SPI
SPI 是 Service Provider Interface,主要用于框架中,框架定义好接口,不同的使用者有不同的需求,因此需要有不同的实现,而 SPI 就通过定义一个特定的位置,Java SPI 约定在 Classpath 下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,然后文件里面记录的是此 jar 包提供的具体实现类的全限定名。
所以就可以通过接口找到对应的文件,获取具体的实现类然后加载即可,做到了灵活的替换具体的实现类。
为什么 Dubbo 不用 JDK 的 SPI
Java SPI 在查找扩展实现类的时候遍历 SPI 的配置文件并且将实现类全部实例化,假设一个实现类初始化过程比较消耗资源且耗时,但是你的代码里面又用不上它,这就产生了资源的浪费。
自己设计一个 RPC 框架
- 高性能的网络传输,可以采用 Netty 来实现
- 自定义协议。毕竟远程交互都需要遵循一定的协议,然后还需要定义好序列化协议,网络的传输毕竟都是二进制流传输的。
- IDL 描述服务的语言。让所有的服务都用 IDL 定义,再由框架转换为特定编程语言的接口,这样就能跨语言了。
- 代理实现。把上述的细节对使用者进行屏蔽,让他们感觉不到本地调用和远程调用的区别。
- 集群功能。因此要服务发现、注册等功能,所以需要注册中心。
- 完善的监控机制。埋点上报调用情况。

若有收获,就点个赞吧
0 人点赞
