微服务的拆分规范和原则
压力模型拆分
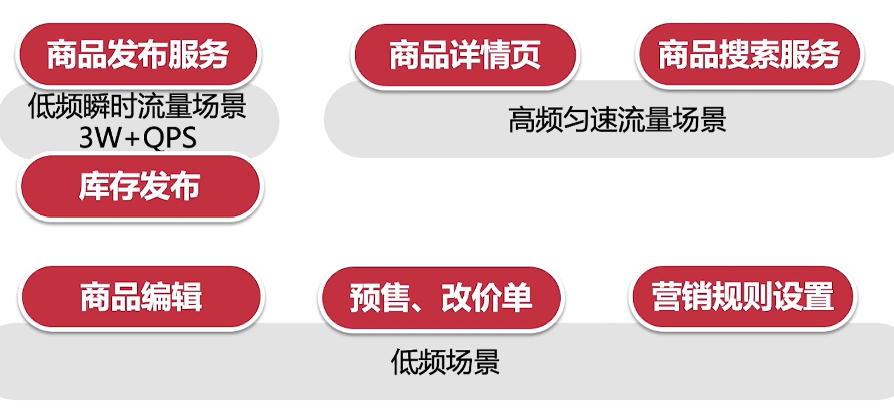
高频高并发场景
比如商品详情页,它既是一个高频场景(时时刻刻都会发生),同时也是高并发的场景(QPS - Query per seconds极高)
建议将高频高并发的场景隔离出来,单独作为一个微服务模块,典型的就是商品详情页的后台服务。对低频突发流量的场景,如果条件允许也可以剥离出来独立组成模块,如果必须和其他业务包在一个微服务下,那一定要做好流控措施(最典型的就是削峰策略),而且还要考虑到异常情况下的补偿机制。对于低频流量场景,我们根据业务模型切分就好了
低频瞬时流量
低频场景
业务模型拆分

主链路拆分
比如商品搜索->商品详情页->购物车模块->订单结算->支付业务,这是就是一条最简单的主链路。如果这是一场战斗的话,那么主链路就是这场战斗的正面战场,我们必须力保主链路不失守。
1)异常容错 为主链路建立层次化的降级策略(多级降级),以及合理的熔断策略
2)调配资源 主链路通常来讲都是高频场景,自然需要更多的计算资源,最主要的体现就是集群里分配的虚机数量多。
3)服务隔离 主链路是主打输出的C位,把主链路与其他打辅助的业务服务隔离开来,避免边缘服务的异常情况影响到主链路。
领域模型拆分DDD
所谓领域模型,其实就是一套各司其职的服务集合。这里涉及到领域和合并和分拆。
天猫和淘宝各有一套营销服务,如果不考虑底层技术,从业务层面来说它们做的事情是一样的,都属于营销优惠计算的领域范围,因此后面两条技术线整合成了一套UMP营销优惠服务。领域拆分的例子就太多了,我们做微服务规划的时候要确保各个领域之间有清晰的界限,比如商品服务,和订单服务,尽管他们之间有交集(都围绕商品主数据),但是毕竟是服务于不同领域(商品域和订单域),所以我们要将两者拆分成独立的服务。
用户群体拆分
电商领域,我们有2C的小卖家,也有2B的大客户,在集团内部有运营、采购、还有客服小二等等。对每个不同的用户群体来说,即便是相同的业务领域,也有该群体其独有的业务场景。
前后台业务分离
将前台业务和后台业务做一个隔离,这也符合高频业务(前台)和低频业务(后台)的隔离策略。
如何改造单体服务
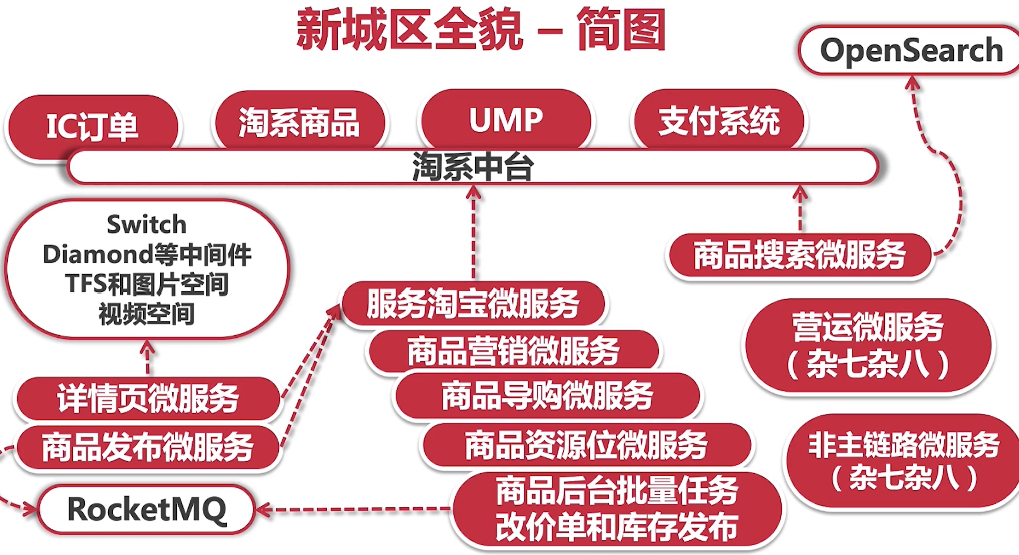
注册中心
Eurka服务注册拳
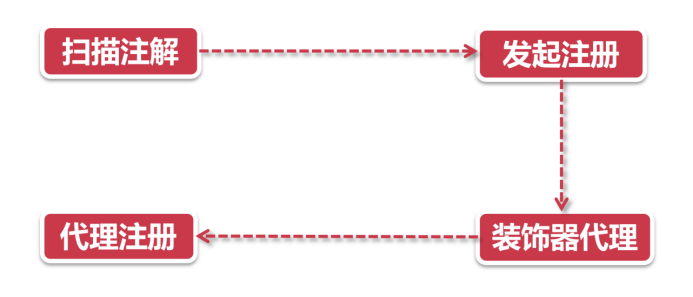
扫描注解
运起了@EnableDiscoveryClient注解里内置的autoRegister**心法。
发起注册
DiscoveryClient类的register方法(类似Facade模式的门面类)他是服务节点很多操作的入口。执行到了SessionedEurekaHttpClient装饰器。
代理+装饰器模式
Eureka的一众连接器全部师从(继承)自这个EurekaHttpClientDecorator。从名字中的Decorator就可以看出它用了装饰器设计模式,简单的说,装饰器就像一层套一层的俄罗斯娃娃,每一层都会给本体加上一层Buff(假定大家都玩过王者荣耀,知道Buff是什么意思),所以你也尽可称呼它为装B模式。JDK里使用装B模式的还有大名鼎鼎的输入输出流框架(InputStream和OutputStream)。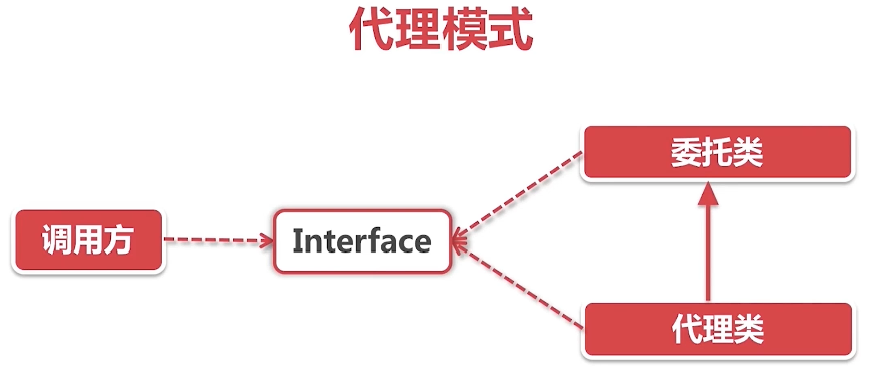
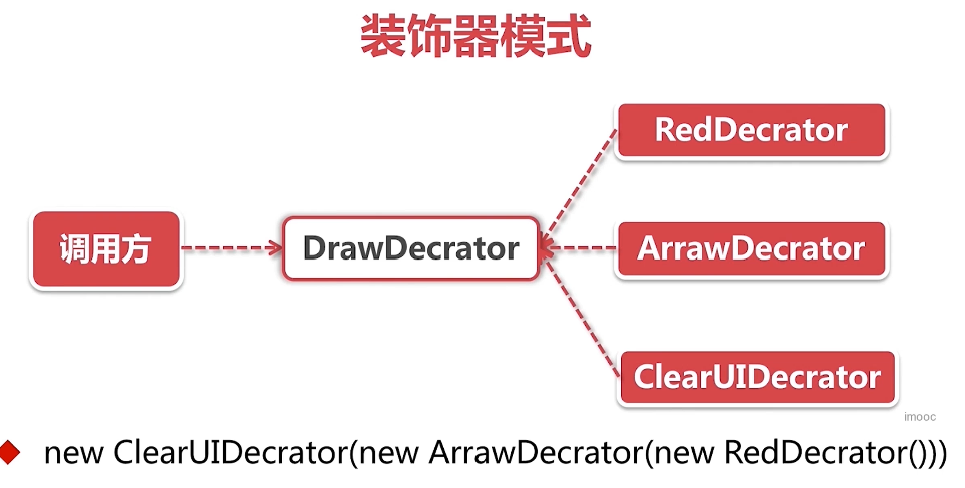
代理注册
Eureka的注册流程其实是用代理+回调的方式,实现了类似装饰器的效果,也就是说虽然这个祖师爷EurekaHttpClientDecorator名字里带了个Decorator,但并不是完全体的装B模式,他没有上一步提到的JDK Stream框架装B的彻底。接下来,就要看Eureka大显神通,运用一层层代理,给注册器加上各种装饰器的Buff。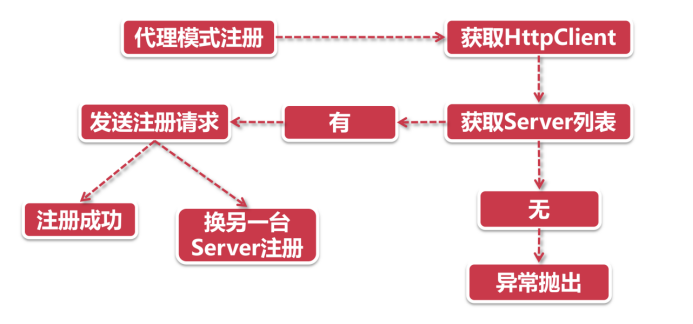
代理模式注册
前面说到了装饰器模式就像层层嵌套的洋娃娃,我们抽丝剥茧之后发现,总共有4层洋娃娃,每一层装饰器都有特殊的功能,正所谓我走过的最长的路是Eureka的套路。这里我们选一层最重要的娃娃来展开,那就是RetryableEurekaHttpClient(注意,这不是最里层的那个)。从名字Retryable我们不难看出,它自带了“失败重试”的功能,这就是它的特殊的Buff-原地复活。
获取HttpClient
这里的HttpClient是RetryableEurekaHttpClient里面的代理对象,也是下一层的洋娃娃,它里面封装了上次同步成功的注册中心地址等信息。假如代理对象为空,那我们就不知道该连向哪个注册中心了,这时候我们就要从Server列表中找一台服务器。
获取Server列表
客户端的Server列表是开发人员通过上帝视角直接配置的,那么第一步就是获取这些已经配置好的Server列表信息。
服务自保
服务自保机制会检查过去15分钟以内,所有成功续约的节点,占所有注册节点的比例,如果低于一个限定值(比如85%)就开启服务自保模式。服务自保模式往往是为了应对短暂的网络环境问题
服务下线
服务下线是一件严肃的事情,总不能反反复复被执行吧,所以这一步需要借助一个特殊的锁,来完成线程安全的下线操作。
Java中的线程安全方法有很多,比如大家熟知的synchronize,或者借助concurrent包下的各种类。可是当面试官问你,抛开这些,你还有什么线程安全的方式?有的同学可能会说Thread中的wait和notify。 刚才我们说的都是Java层面提供的封装好的机制,然而还有一个利用底层操作系统实现的乐观同步锁,他叫做CAS,即Compare and Swap。
unsafe.compareAndSwapInt操作是看不到源码的,因为CAS操作是借助了底层操作系统的接口,因此这实际是一个被native关键字修饰的由操作系统实现的方法。操作系统的cas操作会将内存值与expect值进行比较,如果相等就会将update参数更新到内存,并返回成功,如果不等则返回失败,在操作系统层面,这个比对-替换的操作是原子性的,所以也就可以保证线程安全。
负载均衡
负载均衡策略
RandomRule - 随性而为
随机挑选一个节点访问。使用了yield(Thread.yeld让出线程)+自旋的方式做重试,还采用了严格的防御性编程(对所有输入进行判断)。
RoundRobinRule - 按部就班
一个节点一步一步地向后选取节点(依靠底层的自旋锁+CAS的同步操作。)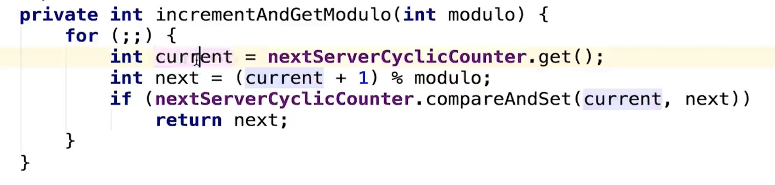
自旋锁如果迟迟不能释放,将会带来CPU资源的浪费,因为自旋本身并不会执行任何业务逻辑,而是单纯的使CPU“空转”。所以通常情况下会对自旋锁的旋转次数做一个限制,比如JDK中synchronize底层的锁升级策略,就对自旋次数做了动态调整。
RetryRule - 卷土重来(装饰器)
类似装饰器模式的Rule,他的BUFF就是给其他负载均衡策略加上“重试”功能。而在RetryRule里还藏着一个subRule,这才是隐藏在下面的真正被执行的负载均衡策略。
WeightedResponseTimeRule - 能者多劳
根据服务节点的响应时间计算权重,响应时间越长权重就越低,响应越快则权重越高,权重的高低决定了机器被选中概率的高低。(服务器刚启动的时候,对各个服务节点采样不足,因此会采用轮询策略)
BestAvailableRule - 让最闲的人来
过滤掉故障服务以后,它会基于过去30分钟的统计结果选取当前并发量最小的服务节点,也就是最“闲”的节点作为目标地址。
AvailabilityFilteringRule - 我是有底线的
依赖RandomRobinRule来选取节点,但并非来者不拒,它也是有一些底线的,必须要满足它的最低要求的节点才会被选中。
- 是否处于熔断状态。
- 节点当前的active请求连接数超过阈值。
ZoneAvoidanceRule - 我的地盘我做主(机房地区)
在Eureka注册中一个服务节点有Zone, Region和URL三个身份信息,其中Zone可以理解为机房大区(未指定则由Eureka给定默认值),而这里会对这个Zone的健康情况过滤其下面所有服务节点。合适的方案
连接数敏感模型
对响应时间较短,或RT和业务复杂度是非线性相关关系的接口,采用基于可用连接数的负载均衡策略更加合适。RT受很多因素制约,服务本身响应时间,网络连接时间,容器状态甚至JVM的full GC等等都会影响最终的RT。我们来设想这样一个场景,现在有一个非常轻量级的微服务,他的业务代码耗时大概在2ms范围内,只占整个接口响应时间的20%,而剩下80%基本都用在了网络连接的开销上。 由于接口响应时间较短,因此性能瓶颈更容易被连接线程数卡住。线程数量达到上限会延长新请求的等待时间,从而增加RT,但这种情况下active的线程数量有更灵敏的指示作用,因为等到RT显著增加的时候,线程池可能早已被吃满了。
RT敏感模型
对重量级接口,尤其是根据参数不同会导致系统资源使用率浮动较大的接口(RT与业务复杂度线性相关),建议采用基于响应时间的负载均衡策略。
当断则断
假如集成了Hystrix熔断器,而当前服务正处于熔断状态,你还想往火坑里跳吗?这时我们就需要根据熔断状态做过滤,使用AvailabilityFilteringRule便是极好的。
LoadBalanced注解
Ribbon的作用机制就是,由LoadBalanced在RestTemplate上打标,Ribbon将带有负载均衡能力的拦截器注入标记好的RestTemplate中,以此实现了负载均衡。
服务调用
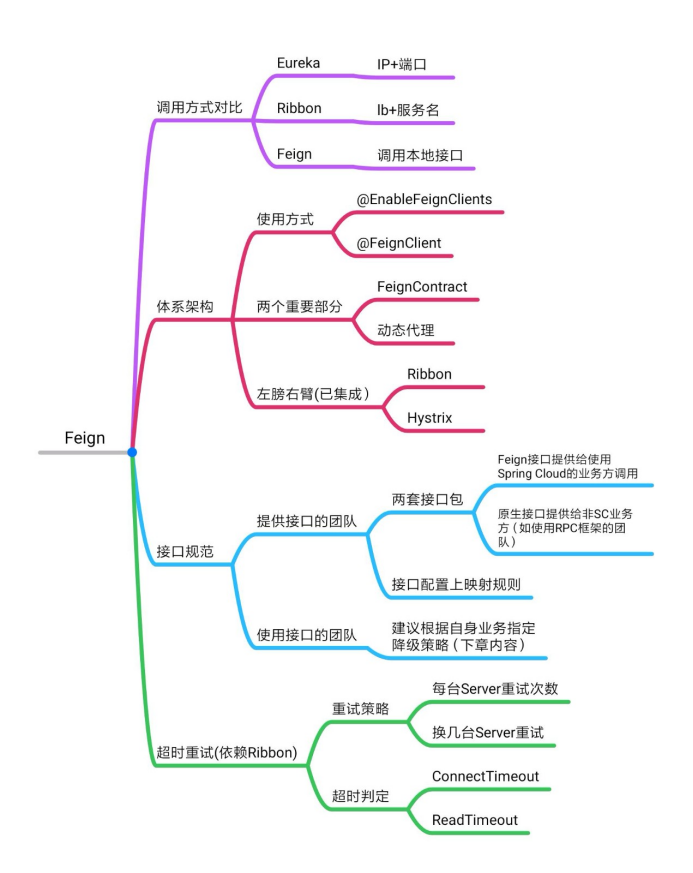
Feign:声明一个代理接口,服务调用者通过调用这个代理接口的方式来调用远程服务。
Feign体系架构
构建请求
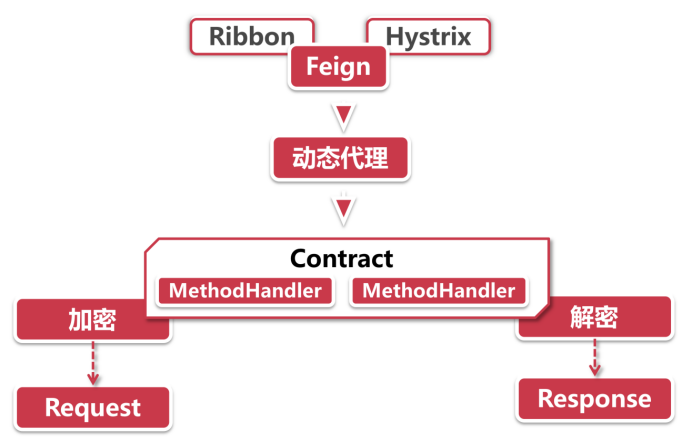
动态代理:Feign是通过一个代理接口进行远程调用,这一步就是为了构造接口的动态代理对象,用来代理远程服务的真实调用,这样你就可以像调用本地方法一样发起HTTP请求,不需要像Ribbon或者Eureka那样在方法调用的地方提供服务名。
在Feign中动态代理是通过Feign.build返回的构造器来装配相关参数,然后调用ReflectFeign的newInstance方法创建的。这里就应用到了Builder设计模式。
发起调用
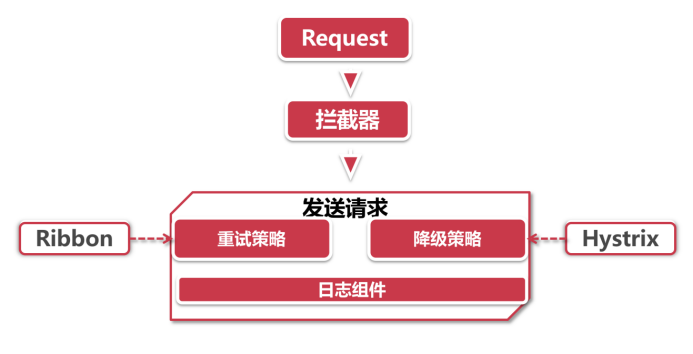
拦截器 :拦截器是Spring处理网络请求的经典方案,Feign这里也沿用了这个做法,通过一系列的拦截器对Request和Response对象进行装饰,比如通过RequestInterceptor给Request对象构造请求头。
Feign之动态代理
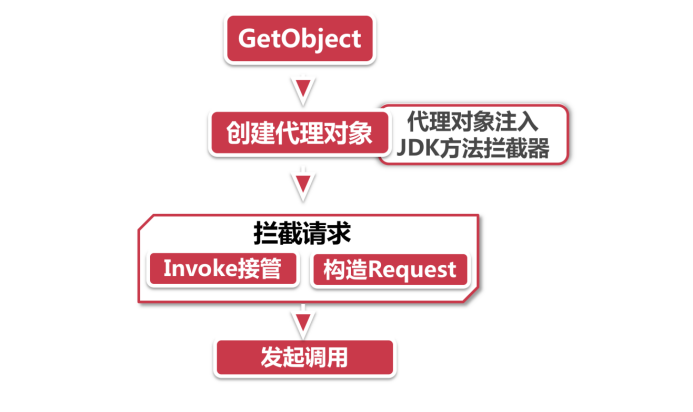
Feign通过实现JDK的InvocationHandler接口,将自己的Handler和上一步组装的Method进行了关联,这样一来,所有对这个接口方法的调用,都将被Feign自定义的InvocationHandler给接管。
Spring扩展注解
- 在注解里面声明 @Import 注解。
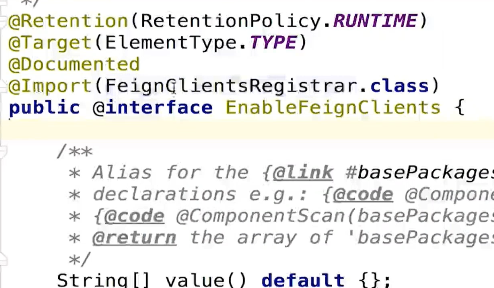
- 在 @Import 声明的类中继承相应的spring提供的接口。

FeignContext
所有Feign的动态代理对象都是通过newInstance方法生成的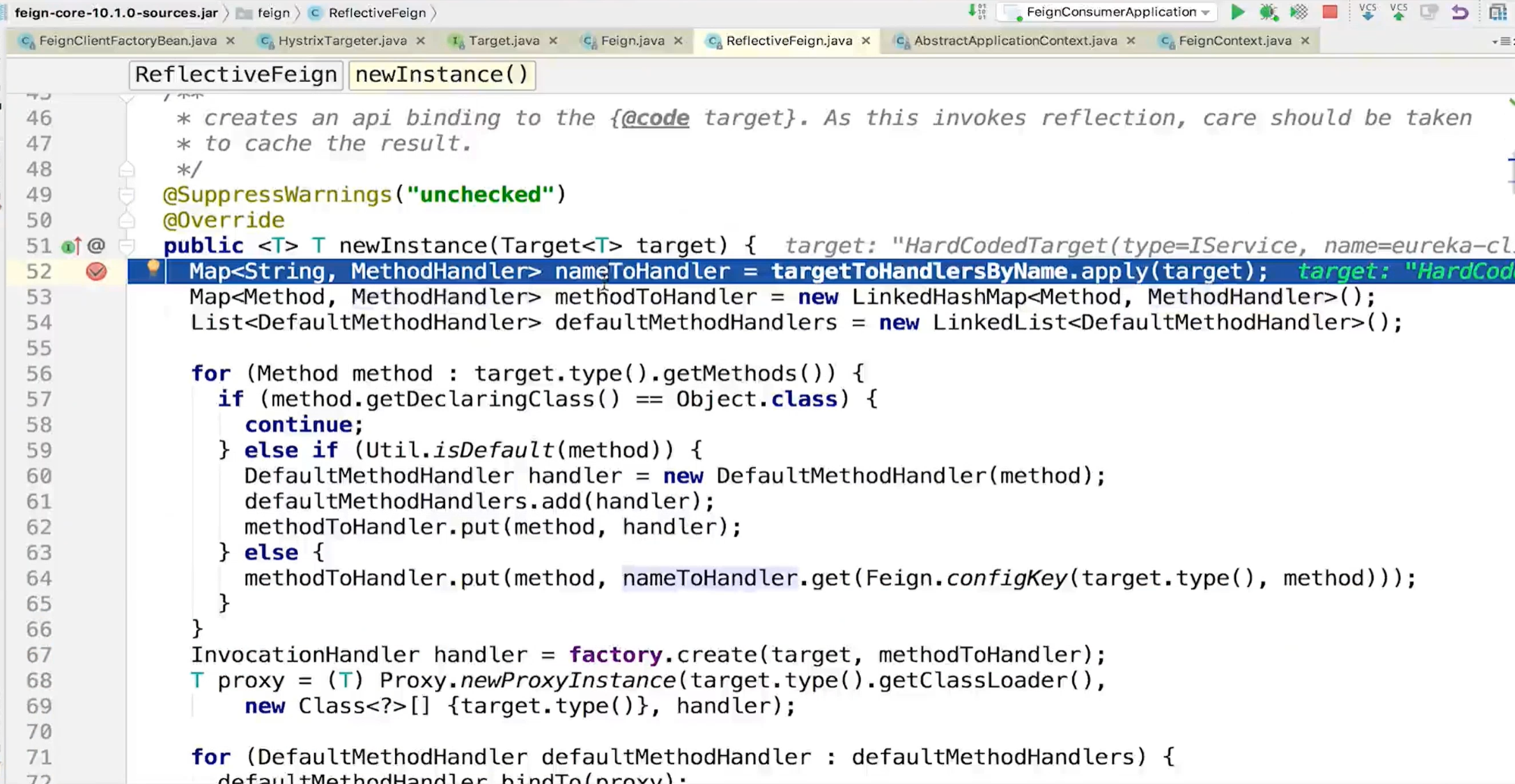
面试考点:
- InvocationHandler接口 -》 发表5min的演讲
- Proxy.newProxyInstance reflect反射?
- 1.8 lamda底层怎么实现?自己怎么设计?

服务容错
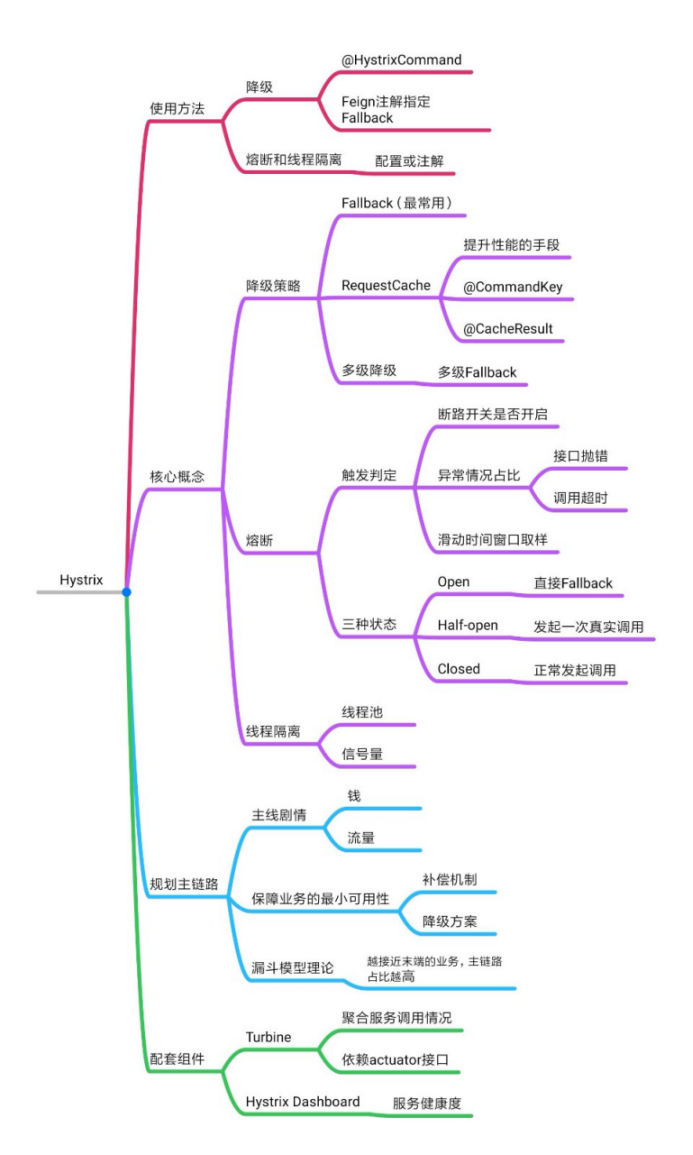
服务降级原理解析
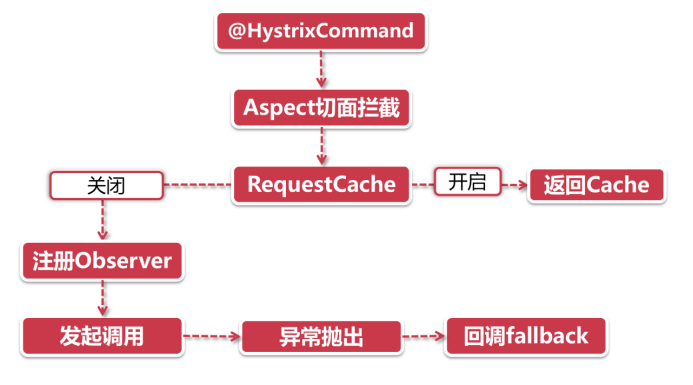
服务降级常用方案
沉默是金 - 静默处理
瞒天过海:默认值
设计商品详情页服务的时候,规定了淘系营销服务接口响应时间的上限是1000ms,超过这个数字则自动降级为0优惠。
好好改造:想办法恢复服务
- 缓存异常:假如因为缓存故障无法获取数据,在fallback逻辑中可以转而访问底层数据库(这个方法不能用在热点数据上,否则可能把数据库打挂,或者引发更大范围的服务降级和熔断,要谨慎使用)。反过来如果数据库发生故障,也可以在fallback里访问缓存,但要注意数据一致性
- 切换备库:一般大型应用都会采用主从+备库的方式做灾备,假如我们的主从库都发生了故障,往往需要人工将数据源切换到备份数据库(参考支付宝2015年的挖掘机事故),我们在fallback中可以先于人工干预之前自动访问备库数据。这个场景尽量限定在核心主链路接口上,不要动不动就去访问备库,以免造成脏读幻读
- 重试:Ribbon可以处理超时重试,但对于异常情况来说(比如当前资源被暂时锁定),我们可以在fallback中自己尝试重新发起接口调用
- 人工干预:有些极其重要的接口,对异常不能容忍,这里可以借助fallback启动人工干预流程,比如做日志打点,通过监控组件触发报警,通知人工介入
真实项目里服务降级的补救措施是八仙过海各显神通,但是目标都是相同的,就是对系统的影响降到最低。
一错再错 - 多次降级
fallback里不好好改造,又捣鼓出一个异常来。这时候我们可以做二次降级,也就是在fallback中再引入一个fallback。
Request Cache并不是让你在fallback里访问缓存,它是Hystrix的一个特殊功能。我们可以通过@CacheResult和@CacheKey两个注解实现。 @CacheResult注解的意思是该方法的结果可以被Hystrix缓存起来,@CacheKey指定了这个缓存结果的业务ID是什么。在一个Hystrix上下文范围内,如果使用相同的参数对@CacheResult修饰的方法发起了多次调用,Hystrix只会在首次调用时向服务节点发送请求,后面的几次调用实际上是从Hystrix的本地缓存里读取数据。 Request Cache并不是由调用异常或超时导致的,而是一种主动的可预知的降级手段,严格的说,这更像是一种性能优化而非降级措施。
Hystrix方法级别超时控制
- 基于方法签名的超时配置
hystrix.command.ClassName#methodName(Integer).execution.isolation.thread.timeoutInMilliseconds=1000
上面的配置是基于“方法签名”生成的,其中ClassName#methodName(Integer)就是一串类名+方法名+方法参数的组合,对于复杂的方法,人工拼出这一套组合字符串也挺费脑子的,Feign提供了一个简单的工具根据反射机制生成字符串:
Feign.configKey(MyService.class, MyService.class.getMethod(“findFriend”, Integer.class))
- 基于CommandKey的配置
我们在声明@HystrixCommand的时候,可以给方法指定一个CommandKey,就像下面这样:
@HystrixCommand(commandKey = “myKey”,fallbackMethod = “fallback”)
这里我们给方法指定了commandKey为mykey,接下来只要使用myKey来替换方法签名就可以实现同样的效果。
hystrix.command.myKey.execution.isolation.thread.timeoutInMilliseconds=1000
熔断器以及工作原理
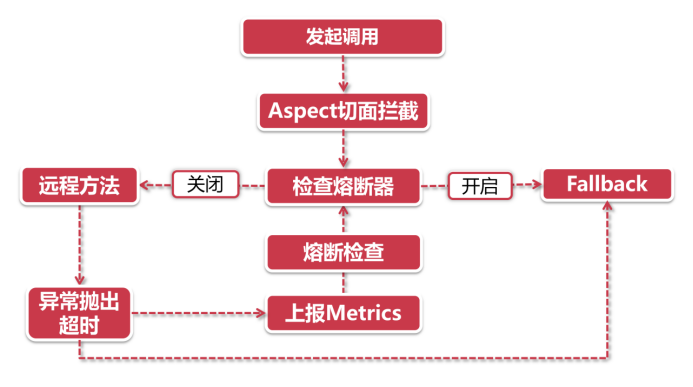
押入天牢 - 熔断开启
- 发起调用-切面拦截:由于熔断器是建立在服务降级的基础上,因此在前面的触发机制上和服务降级流程一模一样。在向@HystrixCommand注解修饰的方法发起调用时,将会触发由Aspect切面逻辑
- 检查熔断器:当熔断状态开启的时候,直接执行进入fallback,不执行远程调用
- 发起远程调用-异常情况:还记得前面服务降级小节里讲到的,服务降级是由一系列的回调函数构成的,当远程方法调用抛出异常或超时的时候,这个异常情况将被对应的回调函数捕捉到
- 计算Metrics:这里的Metrics指的是衡量指标,在异常情况发生后,将会根据断路器的配置计算当前服务健康程度,如果达到熔断标准,则开启断路开关,后续的请求将直接进入fallback流程里
取保候审 - 熔断半开启
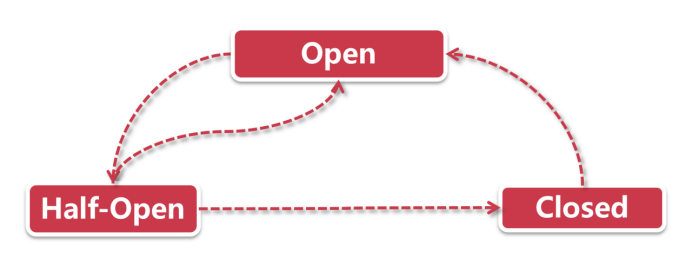
- 熔断器open状态:劳改中,服务在一定时间内不得发起外部调用,前来探视者一律去fallback里接待
- 熔断器half-open状态:取保候审,在fallback里待的也够久了,给一个改过自新的机会,可以尝试发起真实的服务调用,但这一切都在监视下进行
- 熔断器closed:无罪释放,上一步的调用成功了,那便关闭熔断,开始一段正常生活
熔断器的判断阀值
主链路规划
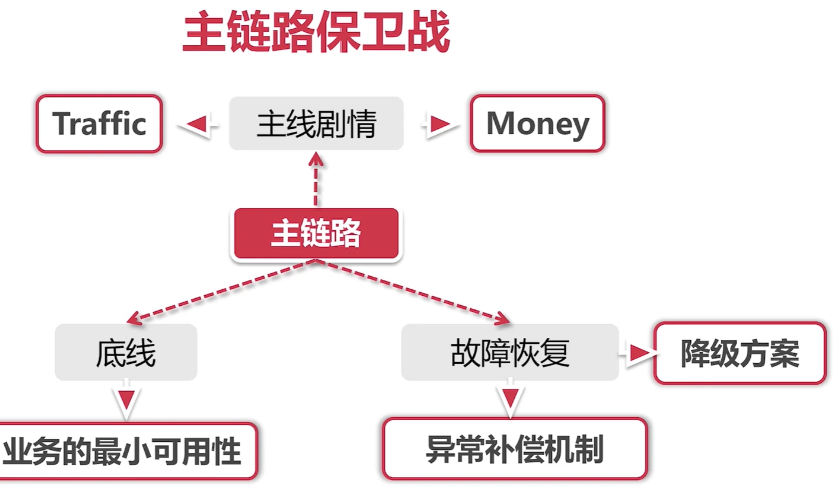
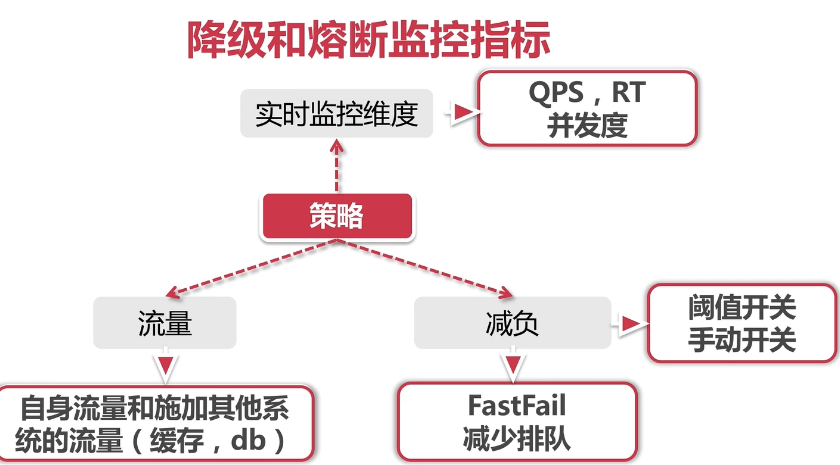
线程隔离
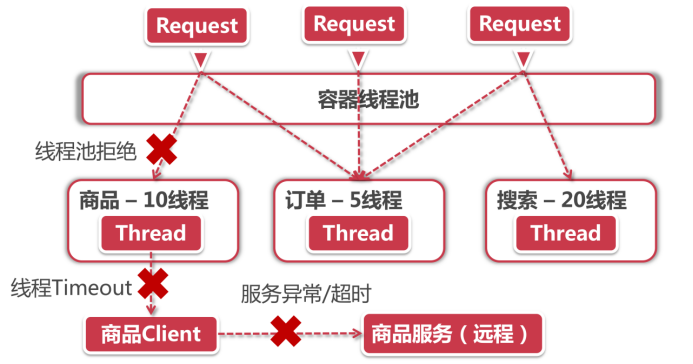
- 线程池拒绝:这一步是线程隔离机制直接负责的,假如当前商品服务分配了10个线程,那么当线程池已经饱和的时候就可以拒绝服务,调用请求会收到Thread Pool Rejects,然后将被转到对应的fallback逻辑中。
- 线程Timeout:调用失败和延迟也可能发生在远程调用之前(比如说一次超长的Full GC导致的超时,或者方法只是一个本地业务计算,并不会调用外部方法)。因此在方法调用过程中,如果同样发生了超时,则会产生Thread Timeout,调用请求被流转到fallback。
服务异常/超时:这就是我们前面学习的的服务降级,在调用远程方法后发生异常或者连接超时等情况,直接进入fallback。
线程隔离的方式
Hystrix提供了两种线程隔离的方式,分别是线程池技术和信号量技术。这两种方式在业务流程上是一致的,在默认情况下,Hystrix使用线程池的方式。
线程池技术:它使用Hystrix自己内建的线程池去执行方法调用,而不是使用Tomcat的容器线程
- 信号量技术:它直接使用Tomcat的容器线程去执行方法,不会另外创建新的线程,信号量只充当开关和计数器的作用。获取到信号量的线程就可以执行方法,没获取到的就转到fallback
从性能角度看
线程池技术:涉及到线程的创建、销毁和任务调度,而且CPU在执行多线程任务的时候会在不同线程之间做切换,我们知道在操作系统层面CPU的线程切换是一个相对耗时的操作,因此从资源利用率和效率的角度来看,线程池技术会比信号量慢
信号量技术:由于直接使用Tomcat容器线程去访问方法,信号量只是充当一个计数器的作用,没有额外的系统资源消费,所以在性能方面具有明显的优势超时判定
线程池技术:相当于多了一层保护机制(Hystrix自建线程),因此可以直接对“执行阶段”的超时进行判定
信号量技术:只能等待诸如网络请求超时等“被动超时”的情况。
信号量适用在超高并发的非外部接口调用上(还是中文言简意赅),注意“the only time”,意思是官方只建议在上述场景中应用信号量技术,在其他场景上尽量使用线程池做线程隔离。
线程池技术要特别注意ThreadLocal的数据传递作用,由于前后调用不在同一个线程内,也不在父子线程内,所以如果你在业务层面声明了ThreadLocal变量,将无法获取正确的值。
分布式配置中心
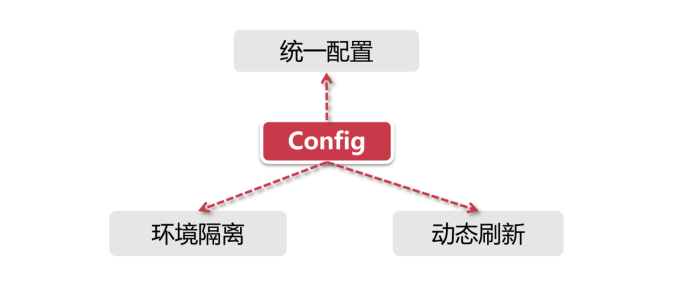
Config Server实现原理分析
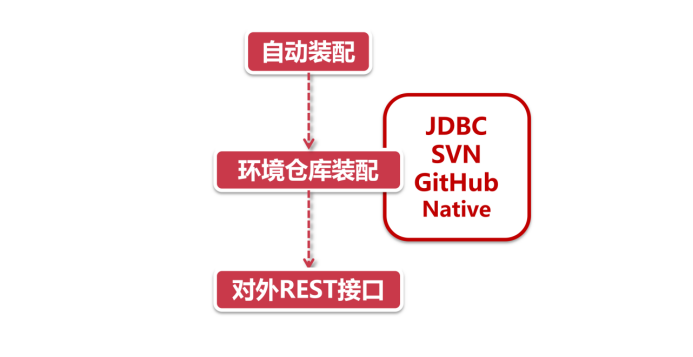
- 自动装配:只要在启动类上放个@EnableConfigServer注解就可以了,Config内部再通过@Import注解引入其他配置类,完成自动装配(具体承担自动装配的类是ConfigServerAutoConfiguration)
- 环境仓库装配:启动了自动装配以后,自然要知道从哪里拉取配置文件,具体负责环境仓库装配的是EnvironmentRepositoryConfiguration这个类。Config Server支持很多种文件存储仓库,比如JDBC,SVN,GitHub和本地文件,当然也可以配置多种类型组合的方式,也就是说Config会从不同的地方拉取配置文件。
- 对外REST接口:从外部环境拉取到了配置文件之后,需要返回给客户端。Config通过EnvironmentController这个类对外提供了一套供客户端调用的REST格式接口,所有服务都是通过GET方法对外提供,客户端可以通过不同的URL路径获取相对应的配置内容。
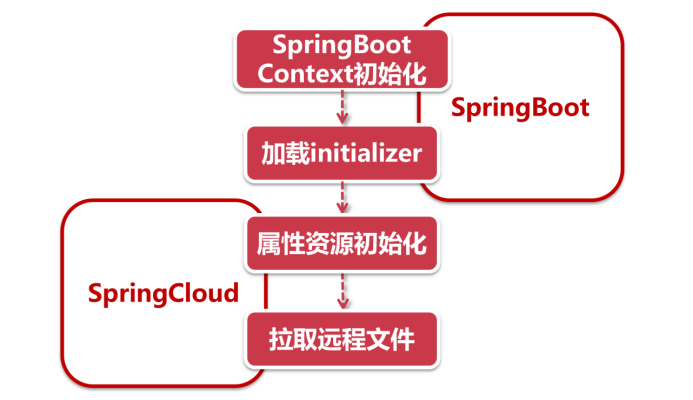
- SpringBoot构建Context:和所有的SpringBoot项目一样,通过SpringApplication类的run方法开始启动项目初始化和加载流程,其中就包括prepareContext这一步,整个项目的上下文结构就通过这个方法来构建
- 加载initializer:这是一连串的初始化构造过程,当我们在项目中引入了SpringCloud依赖时,PropertySourceBootstrapConfiguration将作为一个初始化构造器,参与SpringBoot上下文的初始化,用来加载SpringCloud的属性资源
- 初始化属性资源:PropertySourceBootstrapConfiguration是通过一系列的locator来定位资源文件的,当我们在项目中引入springcloud-config-client的依赖以后,就会开启Config组件的自动装配(由ConfigServiceBootstrapConfiguration实现),在这个自动装配过程中会向locator列表里添加一个专门用来获取远程文件的类-ConfigServicePropertySourceLocator
拉取远程文件:ConfigServicePropertySourceLocator定义了执行顺序的优先级是0(通过@Order(0)注解定义),在Spring中这个数字越小则表示优先级越高,因此,这个组件将优先于其他locator先被执行。通过getRemoteEnvironment方法,向Config Server发起请求,获取远程属性
配置文件动态刷新
发送刷新请求 我们选定一个服务节点,通过POST请求访问节点下的/actuator/refresh路径,这时节点会发送一个刷新请求到Config服务器
- 拉取文件 Config服务器会访问Github获取最新的内容,并把配置信息文件下载到本地
- 获取更新内容 接着服务节点从Config那里拿到变更内容,并将变动的属性配置到各个类中。
假如一个类中有需要进行运行期替换操作的属性,那就要把@RefreshScope注解加到这个类上,这样运行期参数修改才会在这个类上面生效。
消息总线-BUS
当服务节点数量非常庞大的时候,我们不可能一台一台服务器挨个去手工触发刷新,这时候就需要一个可以号令武林的角色出场,由它代替我们做批量刷新的事儿。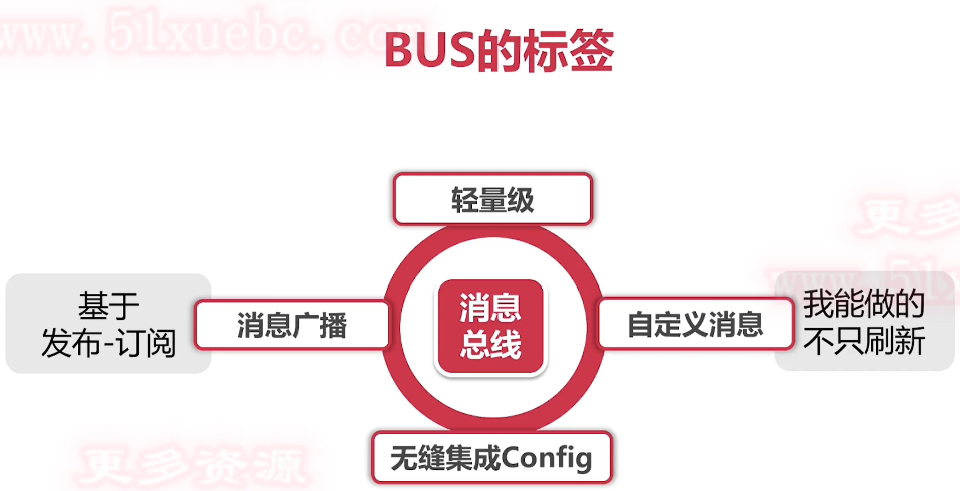
- 配置变更通知
- 自定义消息广播
我们可以将自定义事件广播到所有监听该事件的节点,让所有消费者触发事件响应。消息广播的使用场景非常多,我们随便举两个实际应用中的例子: 清空缓存:通知所有服务监听者清空某项业务的本地缓存信息,我们也可以在自定义的消息体中加业务属性,事件监听逻辑可以根据这些属性来定点清除某个特定业务对象的缓存 数据同步:子系统依赖实时的数据库记录变动触发相应的业务逻辑,我们这里就可以将数据库的binlog抓取出来,通过广播功能同步到所有监听器,起到数据同步的作用
服务网关
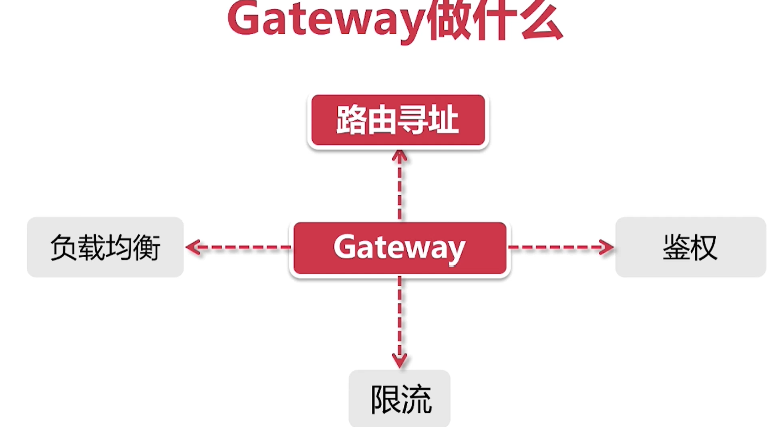
Gateway体系架构解析
Netty在Gateway中主要应用在以下几个地方:
- 发起服务调用:由NettyRoutingFilter过滤器实现,底层采用基于Netty的HttpClient发起外部服务的调用
- Response传输:由NettyResponseFilter过滤器实现,网络请求结束后要将Response回传给调用者
- Socket连接:具体由ReactorNettyWebSocketClient类承接,通过Netty的HttpClient发起连接请求
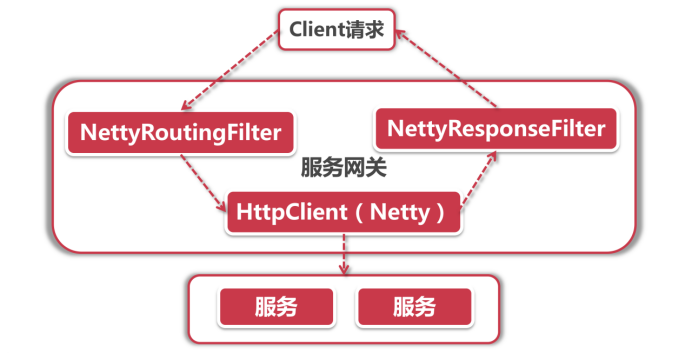
Client发起请求到服务网关之后,由NettyRoutingFilter底层的HttpClient(也是Netty组件)向服务发起调用,调用结束后的Response由NettyResponseFilter再回传给客户端。有了Netty的加持,网络请求效率大幅提升(Zuul 1.x还是使用Servlet,在2.x版本才移步到Netty)由此可见,Netty贯穿了从Request发起到Response结束的过程,承担了所有和网络调用相关的任务。
Gateway自动装配
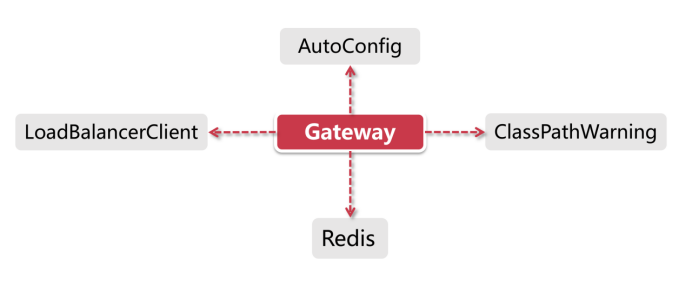
- AutoConfig 作为核心自动装配主类,GatewayAutoConfiguration负责初始化所有的Route路由规则、Predicate断言工厂和Filter(包括Global Filter和Route Filter),这三样是Gateway吃饭的家伙,用来完成路由功能。AutoConfig也会同时加载Netty配置
- LoadBalancerClient 这部分在AutoConfig完成之后由GatewayLoadBalancerClientAutoConfiguration负责加载,用来加载Ribbon和一系列负载均衡配置
- ClassPathWarning 同样也是在AutoConfig完成之后触发(具体加载类为GatewayClassPathWarningAutoConfiguration),由于Gateway底层依赖Spring WebFlux的实现,所以它会检查项目是否加载了正确配置
- Redis 在Gateway中Redis主要负责限流的功能,这部分将在后面的小节里讲
路由功能详解
路由三重门
Gateway中可以定义很多个Route,一个Route就是一套包含完整转发规则的路由,主要由三部分组成:1. 断言集合
断言是路由处理的第一个环节,它是路由的匹配规则,它决定了一个网络请求是否可以匹配给当前路由来处理。之所以它是一个集合的原因是我们可以给一个路由添加多个断言,当每个断言都匹配成功以后才算过了路由的第一关。Predicate Handler 具体承接类是RoutePredicateHandlerMapping。首先它获取所有的路由(配置的routes全集),然后依次循环每个Route,把应用请求与Route中配置的所有断言进行匹配,如果当前Route所有断言都验证通过,Predict Handler就选定当前的路由。这个模式是典型的职责链。
常用断言介绍
路径匹配
- Path断言。
- Method断言。
- Method断言。
- RequestParam匹配。
- Header断言。
- Cookie断言。
- 时间片匹配。
- 自定义断言
.route(r -> r.path(“/gateway/**”)
.and().header(“Authorization”)
.uri(“lb://FEIGN-SERVICE-PROVIDER/“)
)
2. 过滤器集合
如果请求通过了前面的断言匹配,那就表示它被当前路由正式接手了,接下来这个请求就要经过一系列的过滤器集合。过滤器可以对当前请求做一系列的操作,比如说权限验证,或者将其他非业务性校验的规则提到网关过滤器这一层。在过滤器这一层依然可以通过修改Response里的Status Code达到中断效果,比如对鉴权失败的访问请求设置Status Code为403之后中断操作。
Filter Handler 在前一步选中路由后,由FilteringWebHandler将请求交给过滤器,在具体处理过程中,不仅当前Route中定义的过滤器会生效,我们在项目中添加的全局过滤器(Global Filter)也会一同参与。同学们看到图中有Pre Filter和Post Filter,这是指过滤器的作用阶段
3. 转发请求
URI是统一资源标识符,它可以是一个具体的网址,也可以是IP+端口的组合,或者是Eureka中注册的服务名称
这一步将把请求转发到URI指定的地址,在发送请求之前,所有Pre类型过滤器都将被执行,而Post过滤器会在调用请求返回之后起作用。
借助网关层对服务端各类异常做统一处理
代理模式 - BodyHackerFunction接口
public interface BodyHackerFunction extends
BiFunction
}
引入代理模式是为了将装饰器和具体业务代理逻辑拆分开来,在装饰器中只需要依赖一个代理接口,而不需要和具体的代理逻辑绑定起来。
装饰器模式 - BodyHackerDecrator
public class BodyHackerHttpResponseDecorator extends ServerHttpResponseDecorator {
/**
- 负责具体写入Body内容的代理类
*/
private BodyHackerFunction delegate = null;
public BodyHackerHttpResponseDecorator(BodyHackerFunction bodyHandler, ServerHttpResponse delegate) {
super(delegate);
this.delegate = bodyHandler;
}
@Override
public Mono writeWith(Publisher<? extends DataBuffer> body) {
return delegate.apply(getDelegate(), body);
}
}
这个装饰器的构造方法接收一个BodyHancker代理类,其中的关键方法writeWith就是用来向Response Body中写入内容的。这里我们覆盖了该方法,使用代理类来托管方法的执行,而在整个装饰器类中看不到一点业务逻辑,这就是我们常说的单一职责。
创建Filter
@Component
@Slf4j
public class ErrorFilter implements GatewayFilter, Ordered {
@Override
public Mono
final ServerHttpRequest request = exchange.getRequest();
BodyHackerFunction delegate = (resp, body) -> Flux.from(body)
.flatMap(orgBody -> {
// 原始的response body
byte[] orgContent = new byte[orgBody.readableByteCount()];
orgBody.read(orgContent);
String content = new String(orgContent);
log.info(“original content {}”, content);
// 如果500错误,则替换
if (resp.getStatusCode().value() == 500) {
content = String.format(“{\”status\”: %d,\”path\”:\”%s\”}”,
resp.getStatusCode().value(),
request.getPath().value());
}
// 告知客户端Body的长度,如果不设置的话客户端会一直处于等待状态不结束
HttpHeaders headers = resp.getHeaders();
headers.setContentLength(content.length());
return resp.writeWith(Flux.just(content)
.map(bx -> resp.bufferFactory().wrap(bx.getBytes())));
}).then();
// 将装饰器当做Response返回
BodyHackerHttpResponseDecorator responseDecorator =
new BodyHackerHttpResponseDecorator(delegate, exchange.getResponse());
return chain.filter(exchange.mutate().response(responseDecorator).build());
}
@Override
public int getOrder() {
// WRITE_RESPONSE_FILTER的执行顺序是-1,我们的Hacker在它之前执行
return -2;
}
}
在这个Filter中,我们定义了一个装饰器类BodyHackerHttpResponseDecorator,同时声明了一个匿名内部类(代码TODO部分),实现了BodyHackerFunction代理类的Body替换逻辑,并且将这个代理类传入了装饰器。这个装饰器将直接参与构造Response Body。 我们还覆盖了getOrder方法,是为了确保我们的filter在默认的Response构造器之前执行。 记得在header中设置content-length,让客户端知道Response中内容的长度,否则的话客户端会认为传输未结束,一直等在那里。
服务调用链追踪
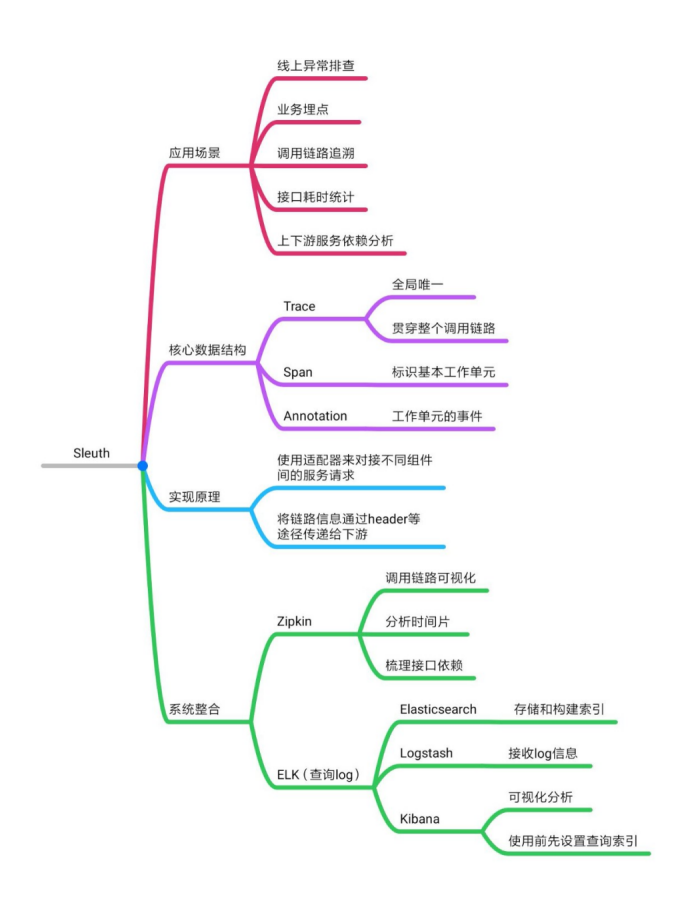
Sleuth核心功能和体系架构解析
Sleuth最核心的功能就是提供链路追踪,在一个用户请求发起到结束的整个过程中,这个Request经过的所有服务都会被Sleuth梳理出来.
Log系统集成 (MDC + Format Pattern)
Log Format Pattern
MDC
MDC是通过InheritableThreadLocal来实现的,它可以携带当前线程的上下文信息。它的底层是一个Map结构,存储了一系列Key-Value的值。Sleuth就是借助Spring的AOP机制,在方法调用的时候配置了切面,将链路追踪数据加入到了MDC中,这样在打印Log的时候,就能从MDC中获取这些值,填入到Log Format中的占位符里。
由于MDC基于InheritableThreadLocal而不是ThreadLocal实现,因此假如在当前线程中又开启了新的子线程,那么子线程依然会保留父线程的上下文信息。
调用链路数据模型
Sleuth数据结构 Trace + Span
- Trace 它就是从头到尾贯穿整个调用链的ID,我们叫它Trace ID,不管调用链路中途访问了多少服务节点,在每个节点的log中都会打印同一个Trace ID
- Span 它标识了Sleuth下面一个基本的工作单元,每个单元都有一个独一无二的ID。比如服务A发起对服务B的调用,这个事件就可以看做一个独立单元,生成一个独立的ID。
Span不单单只是一个ID,它还包含一些其他信息,比如时间戳,它标识了一个事件从开始到结束经过的时间,我们可以用这个信息来统计接口的执行时间。每个Span还有一系列特殊的“标记”“Annotation”,它标识了这个Span在执行过程中发起的一些特殊事件。
Annotation标记
一个Span可以包含多个Annotation,每个Annotation表示一个特殊事件,比如:
cs Client Sent,客户端发送了一个调用请求
sr Server Received,服务端收到了来自客户端的调用
ss Server Sent,服务端将Response发送给客户端
cr Client Received,客户端收到了服务端发来的Response
每个Annotation同样有一个时间戳字段,这样我们就能分析一个Span内部每个事件的起始和结束时间。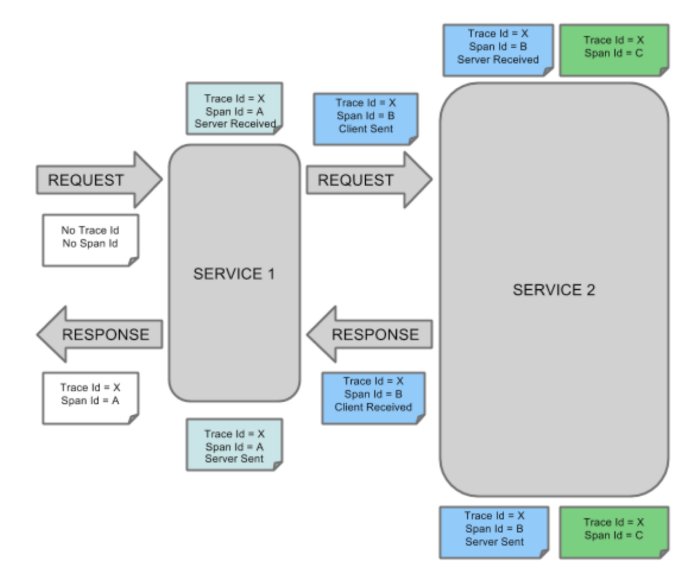
服务节点间的ID传递 - 向Header中添加追踪信息
在调用下一个服务的时候,Sleuth会在当前的Request Header中写入下面的信息.
| X-B3-TraceId | Trace ID | 链路全局唯一ID |
|---|---|---|
| X-B3-SpanId | Span ID | 当前Span的ID |
| X-B3-ParentSpanId | Parent Span ID | 前一个Span的ID |
| X-Span-Export | Can be exported for sampling or not | 是否可以被采样 |
Zipkin(面向Timing Data)
Zipkin是一套分布式实时数据追踪系统,它主要关注的是时间维度的监控数据,比如某个调用链路下各个阶段所花费的时间,同时还可以从可视化的角度帮我们梳理上下游系统之间的依赖关系。
- 数据收集 聚合客户端数据
-
Zipkin的组件
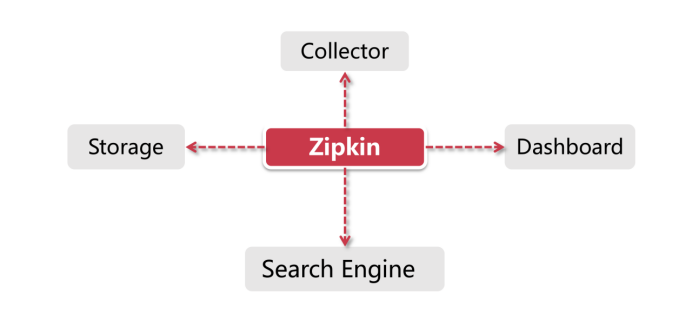
Collector:很多人以为Collector是一个客户端组件,其实它是Zipkin Server的守护进程,用来验证客户端发送来的链路数据,并在存储结构中建立索引。守护进程就是指一类用于执行特定任务的后台进程,它独立于Zipkin Server的控制终端,一直等待接收客户端数据。
- Storage:Zipkin支持ElasticSearch和MySQL等存储介质用来保存链路信息,本章demo中采用默认的Cassandra作为存储方式
- Search Engine:提供基于JSON API的接口来查找信息
- Dashboard:一个大盘监控页面,后台调用Search Engine来获取展示信息。
消息中间件
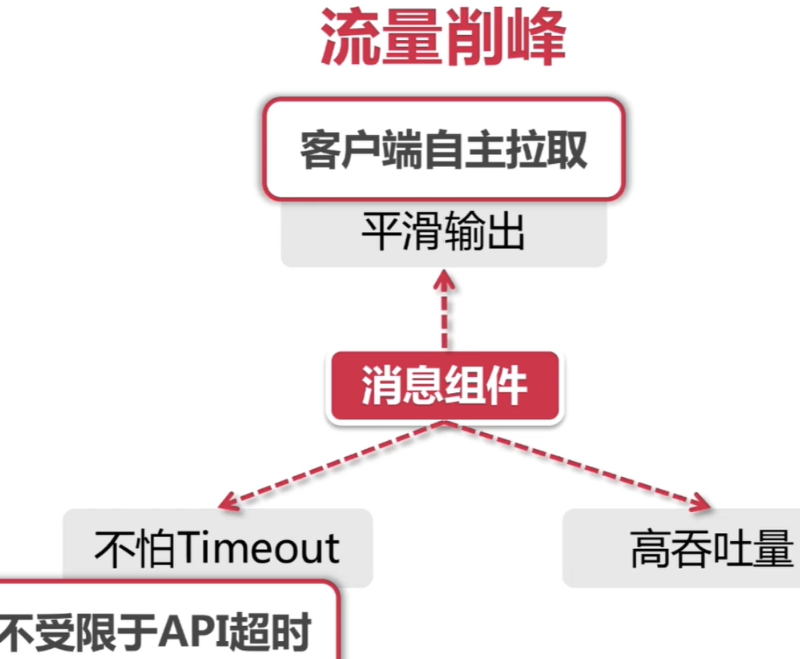
Stream Binder作用机制
Stream为每种不同类型的消息组件开发了一套Binder作为适配器,从而打通消息中间件和Stream的Input、Output通道之间连接。当我们将一个Binder组件引入Pom文件之后,它将在项目启动的时候进行自动装配,分别对我们代码中声明的@Input,@Output和@StreamListener注解进行解析,并绑定到对应的通信通道。
解析@StreamListener注解
Spring中的注解都需要一个对应的解析器来执行具体业务,对于@StreamListener注解来说,它的对应解析器就是StreamListenerAnnotationBeanPostProcessor.
private final MultiValueMap<String, StreamListenerHandlerMethodMapping>mappedListenerMethods = new LinkedMultiValueMap<>();
这个类实现了BeanPostProcessor接口,并且覆盖了postProcessAfterInitialization方法。
在Spring完成每个Bean的初始化之后,会调用该方法执行一段逻辑。
/**在Spring加载Bean的时候,Stream就找出了所有标注的@StreamListener的消费者方法,然后这些消费者被装进一个个Runnable线程对象中,等待后面启动线程对象并开启消息监听。**/@Overridepublic final Object postProcessAfterInitialization(Object bean,final String beanName) throws BeansException {// 对每个托管到Spring的Bean,先通过反射拿到class对象Class<?> targetClass = AopUtils.isAopProxy(bean) ?AopUtils.getTargetClass(bean) : bean.getClass();// 再通过反射获取该类声明的方法Method[] uniqueDeclaredMethods = ReflectionUtils.getUniqueDeclaredMethods(targetClass);for (Method method : uniqueDeclaredMethods) {// 找出那些添加了@StreamListener注解的方法StreamListener streamListener = AnnotatedElementUtils.findMergedAnnotation(method, StreamListener.class);if (streamListener != null && !method.isBridge()) {// streamListenerCallbacks是一个Runnable的数组// 这里会将符合条件的方法转为一个Runnable对象,添加到数组中this.streamListenerCallbacks.add(() -> {// 断言检测,该方法不能同时定义@Input注解和@StreamListener注解Assert.isTrue(method.getAnnotation(Input.class) == null,StreamListenerErrorMessages.INPUT_AT_STREAM_LISTENER);this.doPostProcess(streamListener, method, bean);});}}return bean;}
这个Runnable线程对象将会在解析器内的afterSingletonsInstantiated方法中被执行(这里涉及到Spring的Bean初始化生命周期),在这个阶段就启动了消息监听。
Spring Bean生命周期
- Bean的实例化:通过构造器或者工厂方法等创建一个实例
- 执行一系列的Aware接口:这些接口大家在工作中应该经常会见到,比如BeanClassLoaderAware、ApplicationContextAware等实现了Aware接口的类,如果你的Bean继承了这些接口并实现了对应的回调方法,那么Spring就会在Bean初始化的相应阶段触发回调方法。刚刚我们提到的在@StreamListener加载流程中被调用postProcessAfterInitialization方法就是在这个阶段执行
- BeanPostProcessor.postProcessBeforeInitialization:在Bean初始化之前执行的操作
- BeanPostProcessor.postProcessAfterInitialization:在Bean初始化之后执行的操作
- SmartInitializingSingleton.afterSingletonsInstantiated:在所有Bean都完成实例化之后调用
- SmartLifecycle.start:当这一步执行完成以后,就可以认为容器已经成功加载了这个Bean
- SmartLifecycle.stop和DisposableBean.destroy:这两个步骤在应用关闭的时候会执行(Application.close)

若有收获,就点个赞吧
0 人点赞
