1、面向对象
→ 什么是面向对象
面向对象、面向过程
面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现 。 面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
面向对象是以功能来划分问题,而不是步骤 。
面向对象就是高度实物抽象化、面向过程就是自顶向下的编程!
面向对象的三大基本特征和五大基本原则
三大特征:
封装: 隐藏对象的属性和实现细节,仅对外公开接口,控制在程序中属性的读和修改的访问级别 。目的是增强安全性和简化编程
继承: 继承机制允许创建分等级层次的类 。 继承机制可以很好的描述一个类的生态,也提高了代码复用率
多态: 是指一个类实例(对象)的相同方法在不同情形有不同表现形式。 多态机制使具有不同内部结构的对象可以共享相同的外部接口。
五大基本原则:
单一职责原则SRP: 一个类应该有且只有一个去改变它的理由,这意味着一个类应该只有一项工作。
开放封闭原则OCP: 对象或实体应该对扩展开放,对修改封闭。
里氏替换原则LSP: 在对象 x 为类型 T 时 q(x) 成立,那么当 S 是 T 的子类时,对象 y 为类型 S 时 q(y) 也应成立。(即对父类的调用同样适用于子类)
依赖倒置原则DIP: 低层次依赖高层次,都依赖抽象。具体实现依赖于抽象。
接口隔离原则ISP: 使用多个专门的接口比使用单个接口要好的多!
→ 平台无关性
Java 如何实现的平台无关
平台无关性就是一种语言在计算机上的运行不受平台的约束,一次编译,到处执行(Write Once ,Run Anywhere)。 对于Java的平台无关性的支持,重要的角色的有Java语言规范、Class文件、Java虚拟机(JVM)等。
- Java语言规范
- 通过规定Java语言中基本数据类型的取值范围和行为
- Class文件
- 所有Java文件要编译成统一的Class文件
- Java虚拟机
- 通过Java虚拟机将Class文件转成对应平台的二进制文件等
Java中,我们所熟知的javac的编译就是前端编译。 主要功能就是把.java代码转换成.class代码。
后端编译主要是将中间代码再翻译成机器语言。Java中,这一步骤就是Java虚拟机来执行的。
虽然Java语言是平台无关的,但是JVM确实平台有关的,不同的操作系统上面要安装对应的JVM。
所以,Java之所以可以做到跨平台,是因为Java虚拟机充当了桥梁。他扮演了运行时Java程序与其下的硬件和操作系统之间的缓冲角色。
JVM 还支持哪些语言(Kotlin、Groovy、JRuby、Jython、Scala)
Java的无关性不仅仅体现在平台无关性上面,向外扩展一下,Java还具有语言无关性。 JVM其实并不是和Java文件进行交互的,而是和Class文件, 如今商业机构和开源机构已经在Java语言之外发展出一大批可以在JVM上运行的语言了,如Groovy、Scala、Jython等。之所以可以支持,就是因为这些语言也可以被编译成字节码(Class文件)。
→ 值传递
值传递、引用传递
值传递:是把实参的值赋值给形参 ,那么对形参的修改,不会影响实参的值
引用传递:以地址的方式传递参数 ,传递以后,行参和实参都是同一个对象,只是名字不同而已 ,对行参的修改将影响实参的值
为什么说 Java 中只有值传递
值传递和引用传递的区别并不是传递的内容。而是实参到底有没有被复制一份给形参。 在判断实参内容有没有受影响的时候,要看传的的是什么,如果你传递的是个地址,那么就看这个地址的变化会不会有影响,而不是看地址指向的对象的变化。就像钥匙和房子的关系。
所以说,Java中其实还是值传递的,只不过对于对象参数,值的内容是对象的引用。
无论是值传递还是引用传递,其实都是一种求值策略(Evaluation strategy)。在求值策略中,还有一种叫做按共享传递(call by sharing)。其实Java中的参数传递严格意义上说应该是按共享传递。
简单点说,Java中的传递,是值传递,而这个值,实际上是对象的引用。
【参考链接】 https://blog.csdn.net/bjweimengshu/article/details/79799485
→ 封装、继承、多态
什么是多态、方法重写与重载
多态:指的是同一个方法的调用,由于对象不同可能会有不同的行为。
- (1)多态是方法的多态,不是属性的多态(多态与属性无关);
- (2)多态的存在要有3个必要条件:继承、方法重写、父类引用指向子类对象;
- (3)父类引用指向子类对象后,用该父类引用调用子类重写的方法,此时多态就出现了。
重写:子类继承父类中的方法,想在原有的基础上作一定的修改。
- (1)方法重写时, 方法名与形参列表必须一致。
- (2)方法重写时,子类的权限修饰符必须要大于或者等于父类的权限修饰符。
- (3)方法重写时,子类的返回值类型必须要小于或者 等于父类的返回值类型。
- (4)方法重写时, 子类抛出的异常类型要小于或者等于父类抛出的异常类型。
重载:在一个类中 存在两个或者两个 以上的同名函数,称作为方法重载。
- (1)函数名要一致。
- (2)形参列表不一致(形参的个数或形参 的类型不一致)
-
Java 的继承与实现
联系: 继承和接口都能实现代码重用,提高开发效率。提现了实物的传递性,继承关系达到复用的目的。
区别:
不同的修饰符修饰;实现:implements,继承:extends;
Java只支持“接口”的多继承,不支持“类“”的多继承。单继承,多实现。
在接口中只能定义全局常量(static final)和无实现的方法,而在继承中可以定义属性方法,变量,常量等。类变量、成员变量和局部变量
静态变量即类变量, 由static修饰,是一个全局变量,为所有对象共享,共享一份内存,线程非安全。
成员变量:
1、成员变量定义在类中,在整个类中都可以被访问。
2、成员变量随着对象的建立而建立,随着对象的消失而消失,存在于对象所在的堆内存中。
3、成员变量有默认初始化值。
局部变量:
1、局部变量只定义在局部范围内,如:函数内,语句内等,只在所属的区域有效。
2、局部变量存在于栈内存中,作用的范围结束,变量空间会自动释放。
3、局部变量没有默认初始化值成员变量和方法作用域
public:表明该成员变量或者方法是对所有类或者对象都是可见的,所有类或者对象都可以直接访问
- private:表明该成员变量或者方法是私有的,只有当前类对其具有访问权限,除此之外其他类或者对象都没有访问权限,子类也没有访问权限。
- protected:表明成员变量或者方法对类自身,与同在一个包中的其他类可见,其他包下的类不可访问,除非是他的子类
- 默认:表明该成员变量或者方法只有自己和其位于同一个包的内可见,其他包内的类不能访问,即便是它的子类
→ Java创建对象有几种方式
- new创建新对象
- 通过反射机制
- 采用clone机制
- 通过序列化机制
2、Java基础知识
→ 基本数据类型
8 种基本数据类型:整型4、浮点型2、布尔型1、字符型1
整型中 byte、short、int、long 的取值范围
byte: -128~127 -2(7)~2(7)-1 1字节
short:-32768 ~ 32767 -2(15)~2(15)-1 2字节
int:-2(31)~2(31)-1 4字节
long:-2(63)~2(63)-1 8字节
什么是浮点型?什么是单精度和双精度?为什么不能用浮点型表示金额?
简单说就是小数类型,小数点可以在相应的二进制的不同位置浮动
单精度 float , 4 个字节;双精度double用 8 个字节存储,这是他们最本质的区别。
单精度是1位符号,8位指数,23位小数。 32位
双精度是1位符号,11位指数,52位小数。 64位
浮点数的能表示的数据大小范围由阶码决定,但是能够表示的精度完全取决于尾数的长度 。 long的最大值是2的64次方减1,需要63个二进制位表示,即便是double,52位的尾数也无法完整的表示long的最大值。不能表示的部分也就只能被舍去了。对于金额,舍去不能表示的部分,损失也就产生了。 还有一个深刻的原因与进制转换有关。十进制的0.1在二进制下将是一个无限循环小数。 如果一个小数不是2的负整数次幂,用浮点数表示必然产生浮点误差。
→ 自动拆装箱
什么是包装类型、什么是基本类型、什么是自动拆装箱 ?
由于基本类型不面向对象,所以包装类就是将基本类型包装起来,使其具备对象的性质,可以添加属性和方法,位于java.lang包下
基本类型,或者叫做内置类型,是Java中不同于类(Class)的特殊类型 。 他们不会在堆上创建,而是直接在栈内存中存储,因此会更加高效。
自动拆装箱
拆箱的过程就是通过Integer 实体调用intValue()方法;
装箱的过程就是调用了 Integer.valueOf(int i) 方法,帮你直接new了一个Integer对象
Integer 的缓存机制
Integer是对小数据(-128 ~ 127)是有缓存的,再jvm初始化的时候,数据-128 ~ 127之间的数字便被缓存到了本地内存中,这样,如果初始化-128~127之间的数字,便会直接从内存中取出,而不需要再新建一个对象 。
public class CompareExample {public static void main(String[] args) {Integer num3 = 100;Integer num4 = 100;System.out.println("num3==num4 " + (num3 == num4)); // true 符合缓存机制Integer num5 = 128;Integer num6 = 128;System.out.println("num5==num6 " + (num5 == num6));// false 不符合缓存机制int num9 = 100;Integer num10 = new Integer(100);System.out.println("num9==num10 " + (num9 == num10));// true 基本数据类型比较}}
→ String
字符串的不可变性
不可变性:当你给一个字符串重新赋值之后,老值并没有在内存中销毁,而是重新开辟一块空间存储新值。
当代码中存在多个不同的字符串变量,它们存储的字符值都是相同的时候,这些变量存储的字符串不会每一个都单独去开辟空间,而是它们共用一个字符串对象。
JDK 6 和 JDK 7 中 substring 的原理及区别
JDK 6中的substring:String是通过字符数组实现的。在jdk 6 中,String类包含三个成员变量:char value[], int offset,int count。他们分别用来存储真正的字符数组,数组的第一个位置索引以及字符串中包含的字符个数。当调用substring方法的时候,会创建一个新的string对象,但是这个string的值仍然指向堆中的同一个字符数组。这两个对象中只有count和offset 的值是不同的。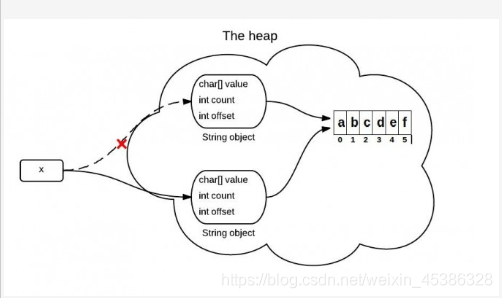
jdk6的源码
//JDK 6String(int offset, int count, char value[]) {this.offset = offset;this.count = count;this.value = value;}public String substring(int beginIndex, int endIndex) {//check boundaryreturn new String(offset + beginIndex, endIndex - beginIndex, value);}
如果你有一个很长很长的字符串,但是当你使用substring进行切割的时候你只需要很短的一段。这可能导致性能问题,因为你需要的只是一小段字符序列,但是你却引用了整个字符串(因为这个非常长的字符数组一直在被引用,所以无法被回收,就可能导致内存泄露)。 在JDK 6中,一般用以下方式来解决该问题,原理其实就是生成一个新的字符串并引用他。
x = x.substring(x, y) + ""
JDK 7 中的substring: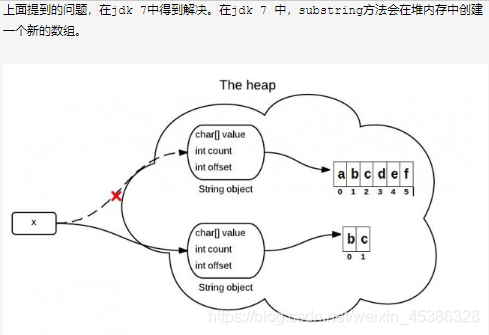
//JDK 7public String(char value[], int offset, int count) {//check boundarythis.value = Arrays.copyOfRange(value, offset, offset + count);}public String substring(int beginIndex, int endIndex) {//check boundaryint subLen = endIndex - beginIndex;return new String(value, beginIndex, subLen);}
【参考链接】 https://www.cnblogs.com/dsitn/p/7151624.html
replaceFirst、replaceAll、replace 区别
replace:参数为target和replaceent,也就是替换的目标对象和新对象
replaceAll:参数为regex和replacement,是正则表达式和新对象,也就是说replaceAll可以支持正则表达替换
replaceFirst:参数也是regex和replacement,不同的是它执行匹配的第一个结果
String s = "abcdefg1234hlqwa";System.out.println(s.replace("a", "#"));System.out.println(s.replaceAll("\\d", "#"));System.out.println(s.replaceFirst("\\d", "#"));// #bcdefg1234hlqw#// abcdefg####hlqwa// abcdefg#234hlqwa
String 对“+”的重载、字符串拼接的几种方式和区别
使用**+**拼接字符串 : 使用+拼接字符串不是运算符重载, 只是Java提供的一个语法糖。 字符串常量在拼接过程中,是将String转成了StringBuilder后,使用其append方法进行处理的。 也就是说,Java中的+对字符串的拼接,其实现原理是使用StringBuilder.append
语法糖:语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·兰丁发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用。语法糖让程序更加简洁,有更高的可读性。
concat方法 : 首先创建了一个字符数组,长度是已有字符串和待拼接字符串的长度之和,再把两个字符串的值复制到新的字符数组中,并使用这个字符数组创建一个新的String对象并返回。 经过concat方法,其实是new了一个新的String,这也就呼应到前面我们说的字符串的不变性问题上了。
StringBuilder :StringBuilder类也封装了一个字符数组,定义如下:char[] value; 它有一个实例变量,表示数组中已经使用的字符个数,定义如下: int count; append会直接拷贝字符到内部的字符数组中,如果字符数组长度不够,会进行扩展。
StringBuffer : StringBuffer同上,区别是StringBuffer是线程安全的 ,使用synchronized进行了声明
StringUtils.join : 通过查看StringUtils.join的源码,可以发现其实它也是通过StringBuilder来实现的。
用时由短到长: **StringBuilder** < **StringBuffer** < **concat** < **+** < **StringUtils.join**
StringUtils.join更擅长处理字符串数组或者列表的拼接。
使用+拼接 :源码在for循环中,每次都是new一个StringBuilder,然后再把String转成StringBuilder, 再进行append。 所以,阿里巴巴Java开发手册建议:循环体内,字符串的连接方式,使用 StringBuilder 的 append 方法进行扩展。而不要使用+。
String.valueOf 和 Integer.toString 的区别
String.valueOf(i)也是调用Integer.toString(i)来实现的。
java.lang.Object类里已有public方法.toString(),所以对任何严格意义上的java对象都可以调用此方法。但在使用时要注意,必须保证object不是null值,否则将抛出NullPointerException异常。
而valueOf(Object obj)对null值进行了处理,不会报任何异常。但当object为null 时,String.valueOf(object)的值是字符串”null”,而不是null。
switch 对 String 的支持
java中switch支持String,是利用String的hash值。
jvm是先调用String的hashCode方法得到hash值,然后将case中的常量换掉 ,本质上是switch-int结构。
并且String的Hash可能会冲突,即两个不同的String可能计算出相同的hash值, 因此 jvm又用String的equals方法来防止hash冲突的问题。最后利用switch-byte结构,精确匹配。
其实 switch中只能使用整型 ,其他数据类型都是转换成整型之后在使用switch的。
字符串池、常量池(Class 常量池、运行时常量池)、intern
jvm在执行某个类的时候,必须经过加载、连接、初始化,而连接又包括验证、准备、解析三个阶段。
全局字符串池(string pool):在类加载完成 ,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中 。 在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表,里面存的是驻留字符串(用双引号括起来的字符串)的引用(而不是驻留字符串实例本身)
class常量池(class constant pool): 在java文件被编译成class文件后生成 。class文件中包含一项信息就是常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。 常量池的每一项常量都是一个表, 一共有11种各不相同的表结构数据,每种不同类型的常量类型具有不同的结构 。
运行时常量池(runtime constant pool): 当类加载到内存中后,jvm就会将class常量池中的内容存放到运行时常量池中,由此可知,运行时常量池也是每个类都有一个。 class常量池中存的是字面量和符号引用, 经过解析(resolve)之后,也就是把符号引用替换为直接引用,解析的过程会去查询全局字符串池,也就是我们上面所说的StringTable,以保证运行时常量池所引用的字符串与全局字符串池中所引用的是一致的。
String.intern()是一个Native方法,作用是:如果字符串常量池存在字符串相等(equals() )的字符串对象,就返回此常量池中的String对象。否则将String对象添加到常量池中,并返回此String对象的引用。Jdk1.6及其之前的版本,字符串常量池分布在永久带(方法区)中,Intern()把首次遇到的字符串复制到常量池中,返回的也是常量池中实例的引用。jdk1.7以后字符串常量池移到了堆中,Intern()不再复制实例,只是在常量池中记录实例的引用,因此返回的引用和下面StringBuilder创建的实例是同一个。
总结:
- 1.全局常量池在每个VM中只有一份,存放的是字符串常量的引用值。
- 2.class常量池是在编译的时候每个class都有的,在编译阶段,存放的是常量的符号引用。
- 3.运行时常量池是在类加载完成之后,将每个class常量池中的符号引用值转存到运行时常量池中,每个class都有一个运行时常量池,类在解析之后,将符号引用替换成直接引用,与全局常量池中的引用值保持一致。
JDK1.7为什么要把字符串常量池移动到堆里面 在Java 7之前,JVM 将Java字符串池放在永久代PermGen(方法区)中,该空间具有固定的大小 - 它不能在运行时扩展,也不在垃圾回收的范围内。在PermGen中实现字符串的风险是,如果我们定义太多字符串,JVM可能报OutOfMemory错误。 从Java 7开始,Java字符串池存储在堆空间中,这是 JVM的垃圾收集范围内。这种方法降低了OutOfMemory错误的风险,因为未引用的字符串将从池中删除,从而释放内存。
【参考链接】https://blog.csdn.net/xiao__xin/article/details/81985654
https://blog.csdn.net/h2453532874/article/details/84453801
→ 熟悉 Java 中各种关键字
transient、instanceof、final、static、volatile、synchronized、const 原理及用法
transient: 作用于变量上, 用transient关键字标记的成员变量不参与序列化过程 ,防止属性被序列化。
instanceof:用来在运行时指出对象是否是特定类的一个实例。
final: 修饰类则这个类不能被继承。修饰方法则这个方法不能被重写。修饰变量则这个变量只能初始化一次。
static: 创建独立于具体对象的域变量或者方法。即时没有创建对象,也能使用属性和方法。
volatile:保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的(实现可见性)。 禁止进行指令重排序(实现有序性)。 volatile 只能保证对单次读/写的原子性。不保证操作的原子性,比如i++ 操作。
synchronized: 可以保证在同一时刻,只有一个线程可以执行某个方法或某个代码块,同时synchronized可以保证一个线程的变化可见(可见性),即可以代替volatile。
const :Java没有这个关键字,是预留关键字,与其异曲同工的是final
一些小坑
a=a+b与a+=b有什么区别吗?
+= 操作符会进行隐式自动类型转换,此处a+=b隐式的将加操作的结果类型强制转换为持有结果的类型, 而a=a+b则不会自动进行类型转换.
静态内部类
定义在类内部的静态类,就是静态内部类。
- 静态内部类可以访问外部类所有的静态变量和方法,即使是 private 的也一样。
- 静态内部类和一般类一致,可以定义静态变量、方法,构造方法等。
- 其它类使用静态内部类需要使用“外部类.静态内部类”方式,如下所示:Out.Inner inner = new Out.Inner();inner.print();
- Java集合类HashMap内部就有一个静态内部类Entry。Entry是HashMap存放元素的抽象,HashMap 内部维护 Entry 数组用了存放元素,但是 Entry 对使用者是透明的。像这种和外部类关系密切的,且不依赖外部类实例的,都可以使用静态内部类。.
char 型变量中能不能存贮一个中文汉字
char 类型可以存储一个中文汉字,因为 Java 中使用的编码是 Unicode(不选择任何特定的编码,直接使用字符在字符集中的编号,这是统 一的唯一方法),一个 char 类型占 2 个字节(16 比特),所以放一个中文是没问题的。
补充:使用 Unicode 意味着字符在 JVM 内部和外部有不同的表现形式,在 JVM内部都是 Unicode,当这个字符被从 JVM 内部转移到外部时 (例如存入文件系统中),需要进行编码转换。所以 Java 中有字节流和字符流,以及在字符流和字节流之间进行转换的转换流,如 InputStreamReader 和 OutputStreamReader,这两个类是字节流和字符流之间的适配器类,承担了编码转换的任务;
32 位和 64 位的 JVM,int 类型变量的长度是多数?
Java 中,int 类型变量的长度是一个固定值,与平台无关,都是 32 位。意思就是说,在 32 位 和 64 位 的 Java 虚拟机中,int 类型的长度是相同的。

若有收获,就点个赞吧
0 人点赞
