我们再来看快速排序算法(Quicksort),我们习惯性把它简称为“快排”。快排利用的也是分治思想。乍看起来,它有点像归并排序,但是思路其实完全不一样。我们待会会讲两者的区别。现在,我们先来看下快排的核心思想。
快排的思想是这样的:如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。
我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
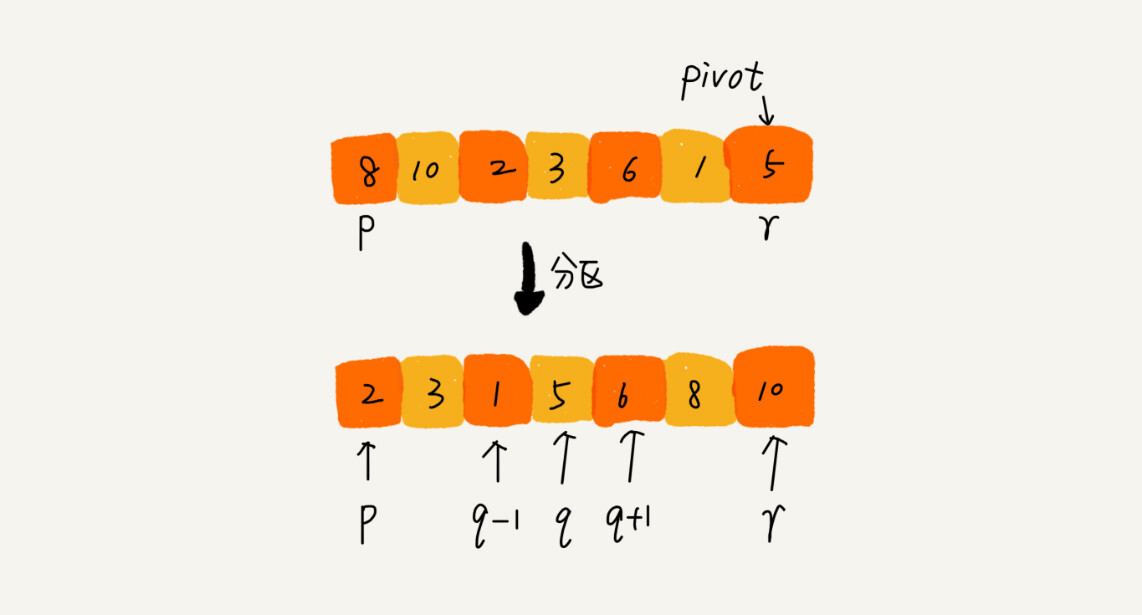
根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
如果我们用递推公式来将上面的过程写出来的话,就是这样:
递推公式:quick_sort(p…r) = quick_sort(p…q-1) + quick_sort(q+1… r)终止条件:p >= r
我将递推公式转化成递归代码。跟归并排序一样,我还是用伪代码来实现,你可以翻译成你熟悉的任何语言。
// 快速排序,A是数组,n表示数组的大小
quick_sort(A, n) {
quick_sort_c(A, 0, n-1)
}
// 快速排序递归函数,p,r为下标
quick_sort_c(A, p, r) {
if p >= r then return
q = partition(A, p, r) // 获取分区点
quick_sort_c(A, p, q-1)
quick_sort_c(A, q+1, r)
}
归并排序中有一个 merge() 合并函数,我们这里有一个 partition() 分区函数。partition() 分区函数实际上我们前面已经讲过了,就是随机选择一个元素作为 pivot(一般情况下,可以选择 p 到 r 区间的最后一个元素),然后对 A[p…r]分区,函数返回 pivot 的下标。
如果我们不考虑空间消耗的话,partition() 分区函数可以写得非常简单。我们申请两个临时数组 X 和 Y,遍历 A[p…r],将小于 pivot 的元素都拷贝到临时数组 X,将大于 pivot 的元素都拷贝到临时数组 Y,最后再将数组 X 和数组 Y 中数据顺序拷贝到 A[p….r]。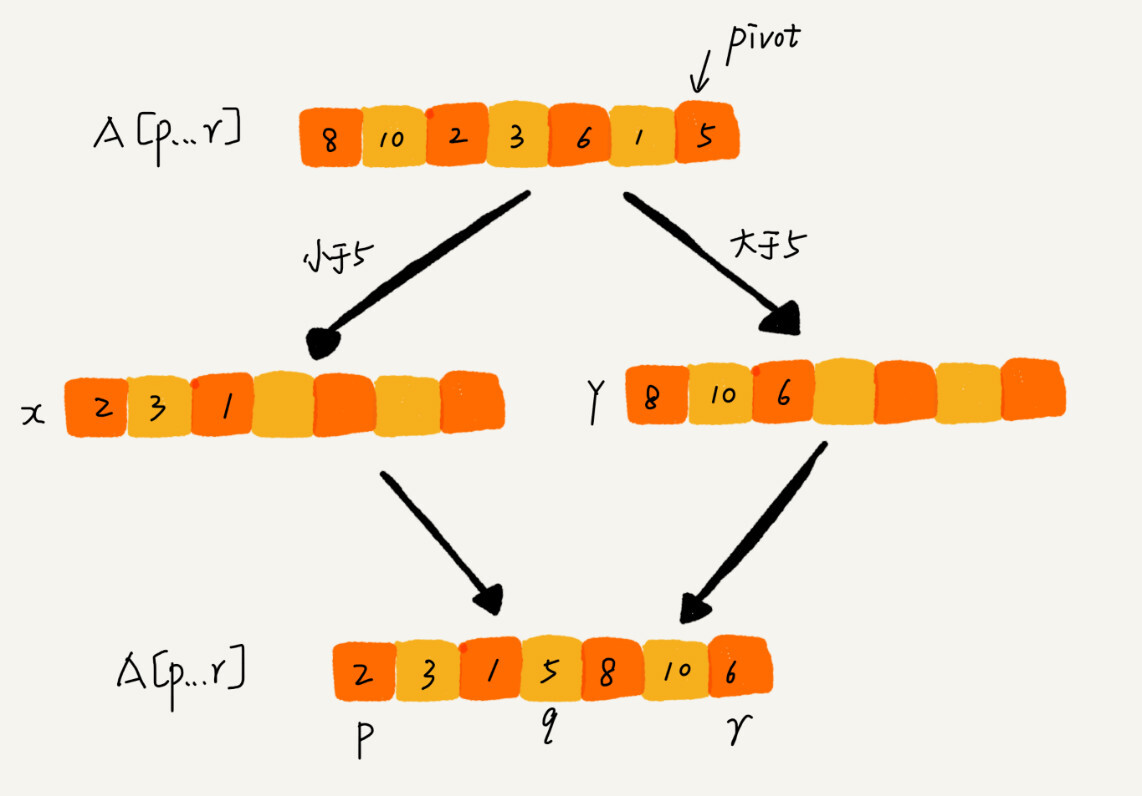
但是,如果按照这种思路实现的话,partition() 函数就需要很多额外的内存空间,所以快排就不是原地排序算法了。如果我们希望快排是原地排序算法,那它的空间复杂度得是 O(1),那 partition() 分区函数就不能占用太多额外的内存空间,我们就需要在 A[p…r]的原地完成分区操作。
原地分区函数的实现思路非常巧妙,我写成了伪代码,我们一起来看一下。
partition(A, p, r) {
pivot := A[r]
i := p
for j := p to r-1 do {
if A[j] < pivot {
swap A[i] with A[j]
i := i+1
}
}
swap A[i] with A[r]
return i
这里的处理有点类似选择排序。我们通过游标 i 把 A[p…r-1]分成两部分。A[p…i-1]的元素都是小于 pivot 的,我们暂且叫它“已处理区间”,A[i…r-1]是“未处理区间”。我们每次都从未处理的区间 A[i…r-1]中取一个元素 A[j],与 pivot 对比,如果小于 pivot,则将其加入到已处理区间的尾部,也就是 A[i]的位置。
数组的插入操作还记得吗?在数组某个位置插入元素,需要搬移数据,非常耗时。当时我们也讲了一种处理技巧,就是交换,在 O(1) 的时间复杂度内完成插入操作。这里我们也借助这个思想,只需要将 A[i]与 A[j]交换,就可以在 O(1) 时间复杂度内将 A[j]放到下标为 i 的位置。
文字不如图直观,所以我画了一张图来展示分区的整个过程。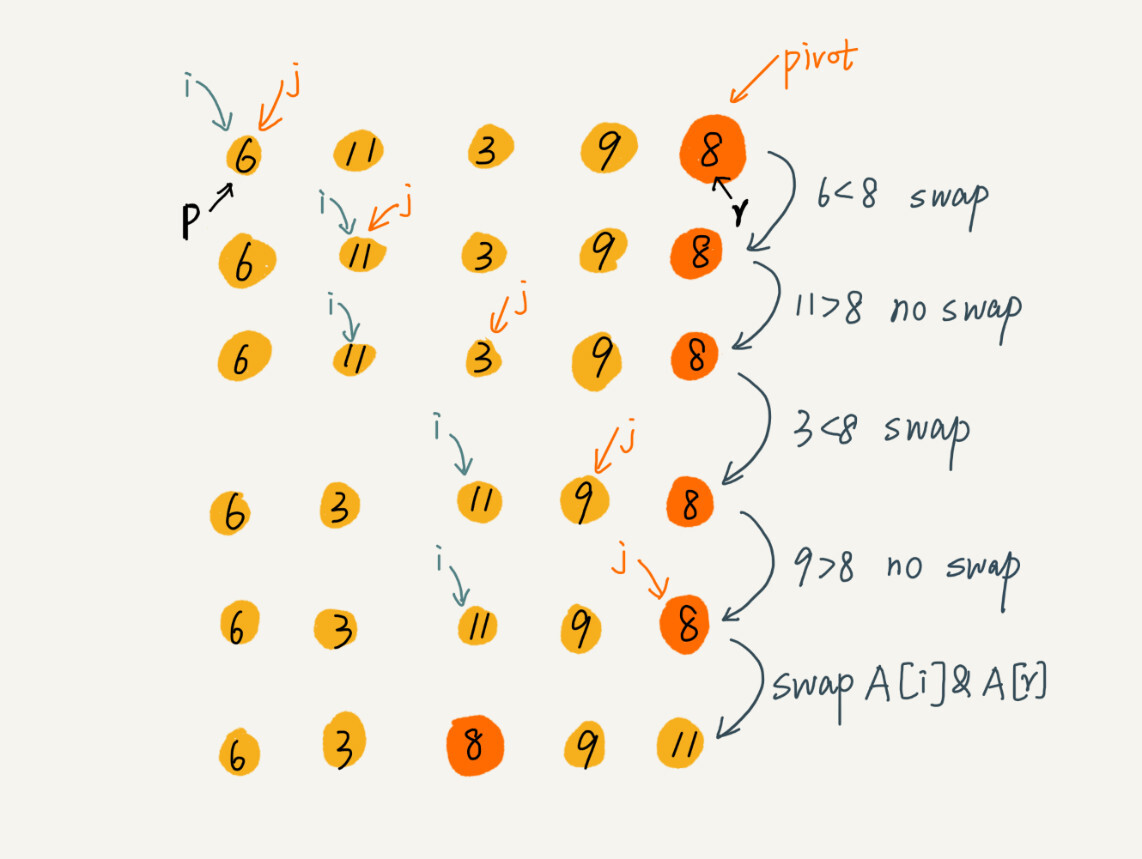
因为分区的过程涉及交换操作,如果数组中有两个相同的元素,比如序列 6,8,7,6,3,5,9,4,在经过第一次分区操作之后,两个 6 的相对先后顺序就会改变。所以,快速排序并不是一个稳定的排序算法。
到此,快速排序的原理你应该也掌握了。现在,我再来看另外一个问题:快排和归并用的都是分治思想,递推公式和递归代码也非常相似,那它们的区别在哪里呢?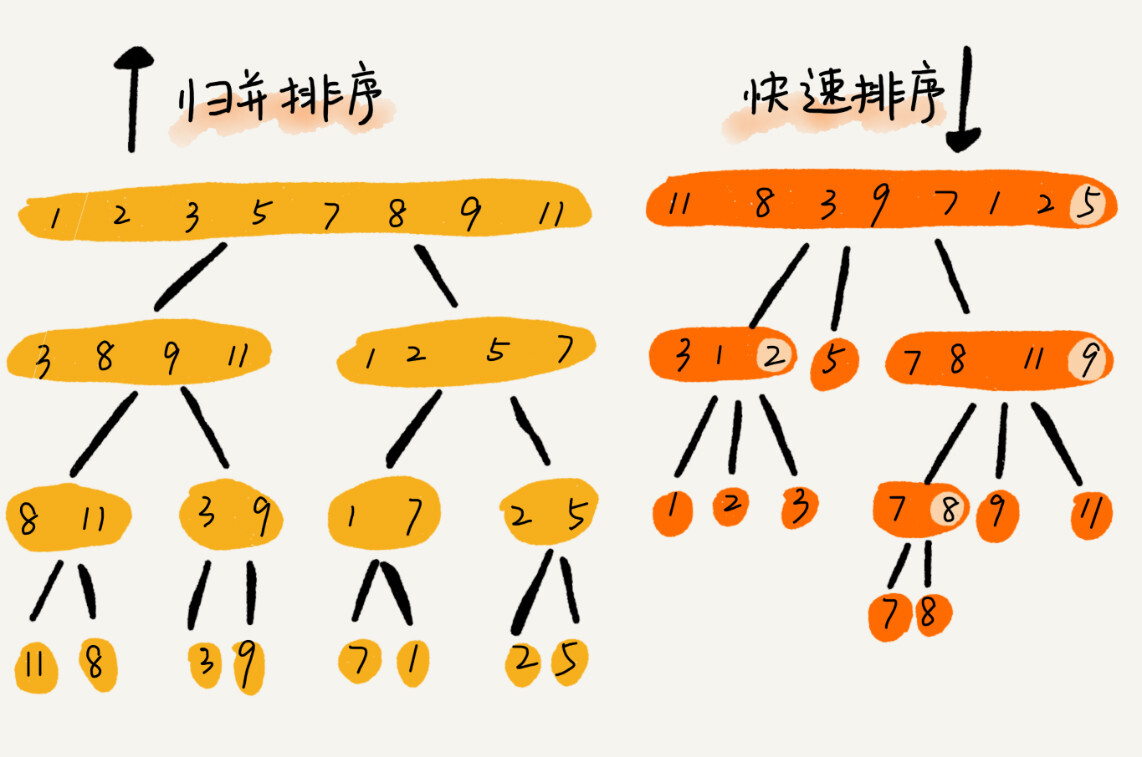
可以发现,归并排序的处理过程是由下到上的,先处理子问题,然后再合并。而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
快速排序的性能分析
现在,我们来分析一下快速排序的性能。我在讲解快排的实现原理的时候,已经分析了稳定性和空间复杂度。快排是一种原地、不稳定的排序算法。现在,我们集中精力来看快排的时间复杂度。

若有收获,就点个赞吧
0 人点赞
