我个人觉得,计数排序其实是桶排序的一种特殊情况。当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
我们都经历过高考,高考查分数系统你还记得吗?我们查分数的时候,系统会显示我们的成绩以及所在省的排名。如果你所在的省有 50 万考生,如何通过成绩快速排序得出名次呢?
考生的满分是 900 分,最小是 0 分,这个数据的范围很小,所以我们可以分成 901 个桶,对应分数从 0 分到 900 分。根据考生的成绩,我们将这 50 万考生划分到这 901 个桶里。桶内的数据都是分数相同的考生,所以并不需要再进行排序。我们只需要依次扫描每个桶,将桶内的考生依次输出到一个数组中,就实现了 50 万考生的排序。因为只涉及扫描遍历操作,所以时间复杂度是 O(n)。
计数排序的算法思想就是这么简单,跟桶排序非常类似,只是桶的大小粒度不一样。不过,为什么这个排序算法叫“计数”排序呢?“计数”的含义来自哪里呢?
想弄明白这个问题,我们就要来看计数排序算法的实现方法。我还拿考生那个例子来解释。为了方便说明,我对数据规模做了简化。假设只有 8 个考生,分数在 0 到 5 分之间。这 8 个考生的成绩我们放在一个数组 A[8]中,它们分别是:2,5,3,0,2,3,0,3。
考生的成绩从 0 到 5 分,我们使用大小为 6 的数组 C[6]表示桶,其中下标对应分数。不过,C[6]内存储的并不是考生,而是对应的考生个数。像我刚刚举的那个例子,我们只需要遍历一遍考生分数,就可以得到 C[6]的值。
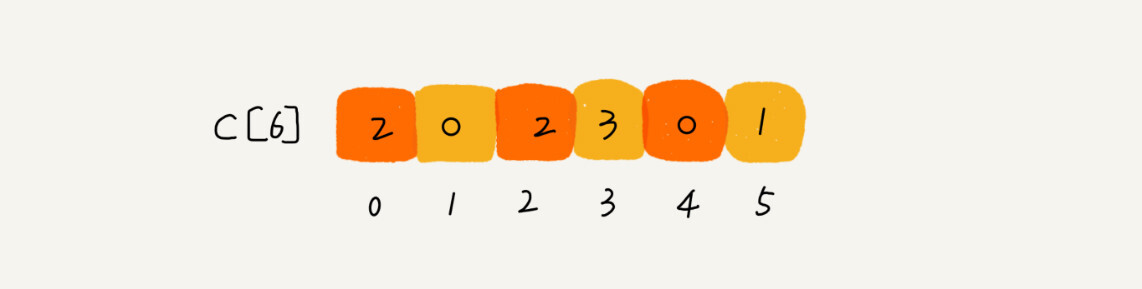
从图中可以看出,分数为 3 分的考生有 3 个,小于 3 分的考生有 4 个,所以,成绩为 3 分的考生在排序之后的有序数组 R[8]中,会保存下标 4,5,6 的位置。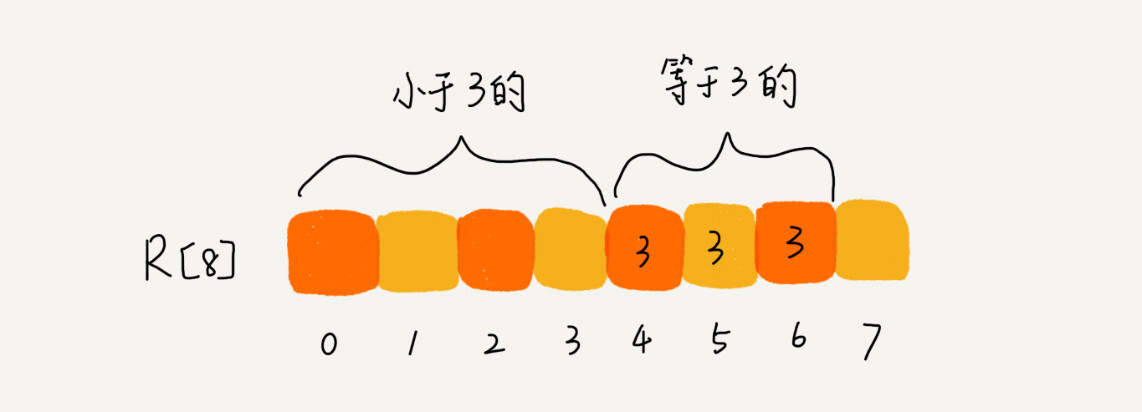
那我们如何快速计算出,每个分数的考生在有序数组中对应的存储位置呢?这个处理方法非常巧妙,很不容易想到。
思路是这样的:我们对 C[6]数组顺序求和,C[6]存储的数据就变成了下面这样子。C[k]里存储小于等于分数 k 的考生个数。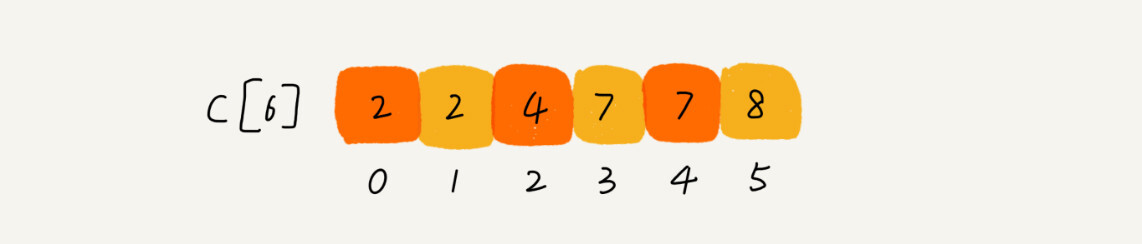
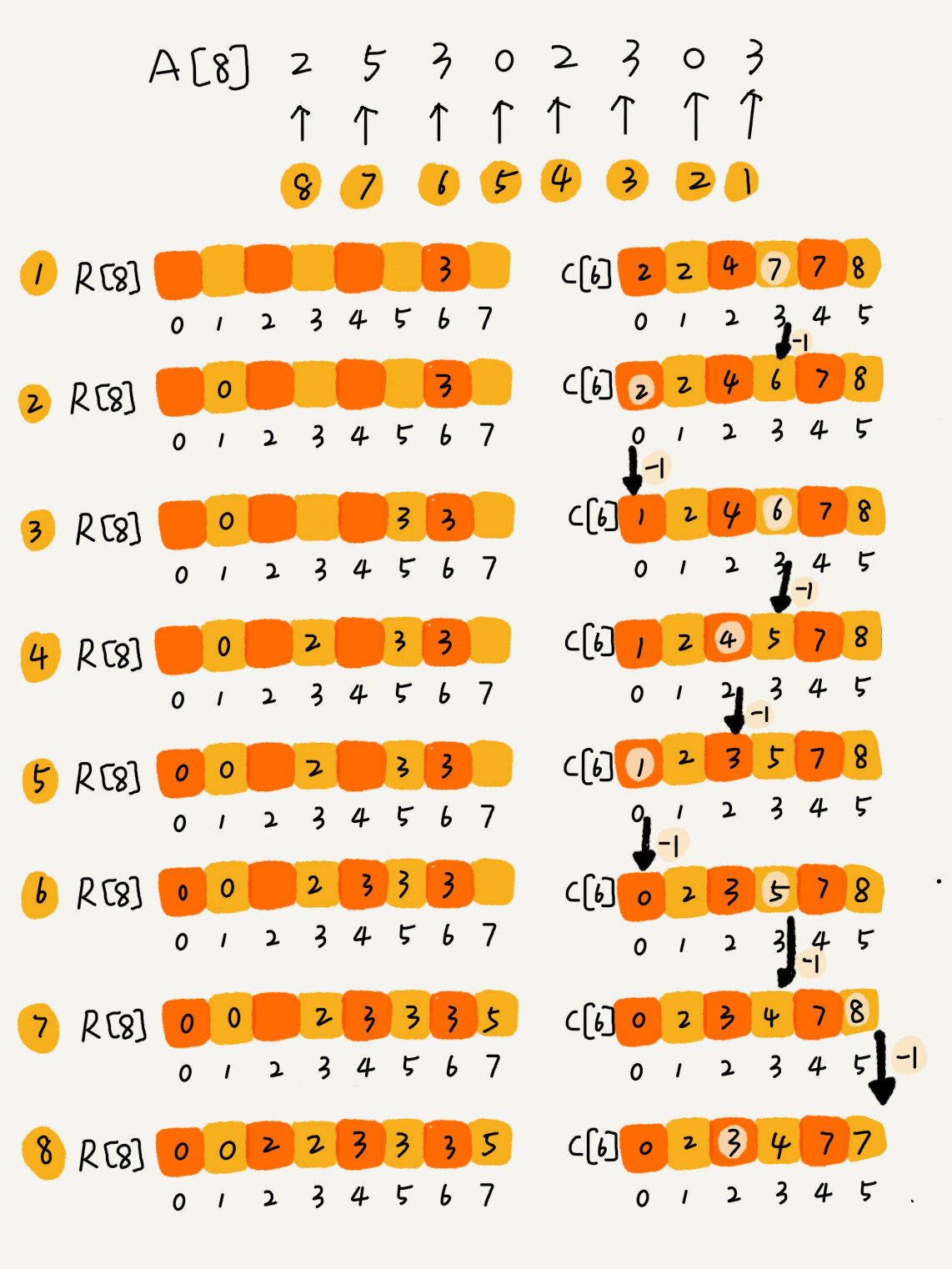
有了前面的数据准备之后,现在我就要讲计数排序中最复杂、最难理解的一部分了,请集中精力跟着我的思路!
我们从后到前依次扫描数组 A。比如,当扫描到 3 时,我们可以从数组 C 中取出下标为 3 的值 7,也就是说,到目前为止,包括自己在内,分数小于等于 3 的考生有 7 个,也就是说 3 是数组 R 中的第 7 个元素(也就是数组 R 中下标为 6 的位置)。当 3 放入到数组 R 中后,小于等于 3 的元素就只剩下了 6 个了,所以相应的 C[3]要减 1,变成 6。
以此类推,当我们扫描到第 2 个分数为 3 的考生的时候,就会把它放入数组 R 中的第 6 个元素的位置(也就是下标为 5 的位置)。当我们扫描完整个数组 A 后,数组 R 内的数据就是按照分数从小到大有序排列的了。

若有收获,就点个赞吧
0 人点赞
