排序对于任何一个程序员来说,可能都不会陌生。你学的第一个算法,可能就是排序。大部分编程语言中,也都提供了排序函数。在平常的项目中,我们也经常会用到排序。排序非常重要,所以我会花多一点时间来详细讲一讲经典的排序算法。
排序算法太多了,有很多可能你连名字都没听说过,比如猴子排序、睡眠排序、面条排序等。我只讲众多排序算法中的一小撮,也是最经典的、最常用的:冒泡排序、插入排序、选择排序、归并排序、快速排序、计数排序、基数排序、桶排序。我按照时间复杂度把它们分成了三类,分三节课来讲解。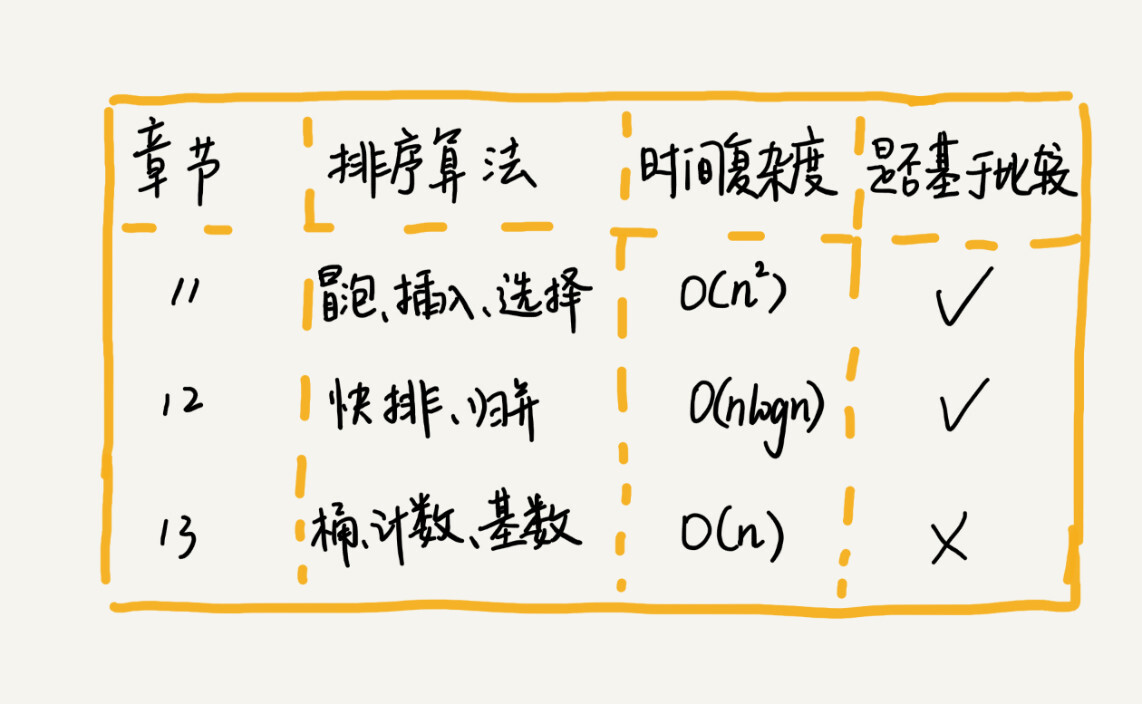
带着问题去学习,是最有效的学习方法。所以按照惯例,我还是先给你出一个思考题:插入排序和冒泡排序的时间复杂度相同,都是 O(n2),在实际的软件开发里,为什么我们更倾向于使用插入排序算法而不是冒泡排序算法呢?
解答;
基本的知识都讲完了,我们来看开篇的问题:冒泡排序和插入排序的时间复杂度都是 O(n2),都是原地排序算法,为什么插入排序要比冒泡排序更受欢迎呢?
我们前面分析冒泡排序和插入排序的时候讲到,冒泡排序不管怎么优化,元素交换的次数是一个固定值,是原始数据的逆序度。插入排序是同样的,不管怎么优化,元素移动的次数也等于原始数据的逆序度。
但是,从代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要 3 个赋值操作,而插入排序只需要 1 个。我们来看这段操作:
冒泡排序中数据的交换操作:if (a[j] > a[j+1]) { // 交换int tmp = a[j];a[j] = a[j+1];a[j+1] = tmp;flag = true;}插入排序中数据的移动操作:if (a[j] > value) {a[j+1] = a[j]; // 数据移动} else {break;}
我们把执行一个赋值语句的时间粗略地计为单位时间(unit_time),然后分别用冒泡排序和插入排序对同一个逆序度是 K 的数组进行排序。用冒泡排序,需要 K 次交换操作,每次需要 3 个赋值语句,所以交换操作总耗时就是 3*K 单位时间。而插入排序中数据移动操作只需要 K 个单位时间。
这个只是我们非常理论的分析,为了实验,针对上面的冒泡排序和插入排序的 Java 代码,我写了一个性能对比测试程序,随机生成 10000 个数组,每个数组中包含 200 个数据,然后在我的机器上分别用冒泡和插入排序算法来排序,冒泡排序算法大约 700ms 才能执行完成,而插入排序只需要 100ms 左右就能搞定!

若有收获,就点个赞吧
0 人点赞
