回溯法也可以叫做回溯搜索法,它是一种搜索的方式,回溯是递归的副产品,只要有递归就会有回溯。
- 回溯法的效率
- 并不是什么高效的算法。因为回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案
- 回溯法解决的问题
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
- 如何理解回溯法
- 回溯法解决的问题都可以抽象为树形结构,是的,我指的是所有回溯法的问题都可以抽象为树形结构!因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度,就构成的树的深度。递归就要有终止条件,所以必然是一棵高度有限的树(N叉树)。
- 回溯搜索的遍历过程
在上面我们提到了,回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。
如图: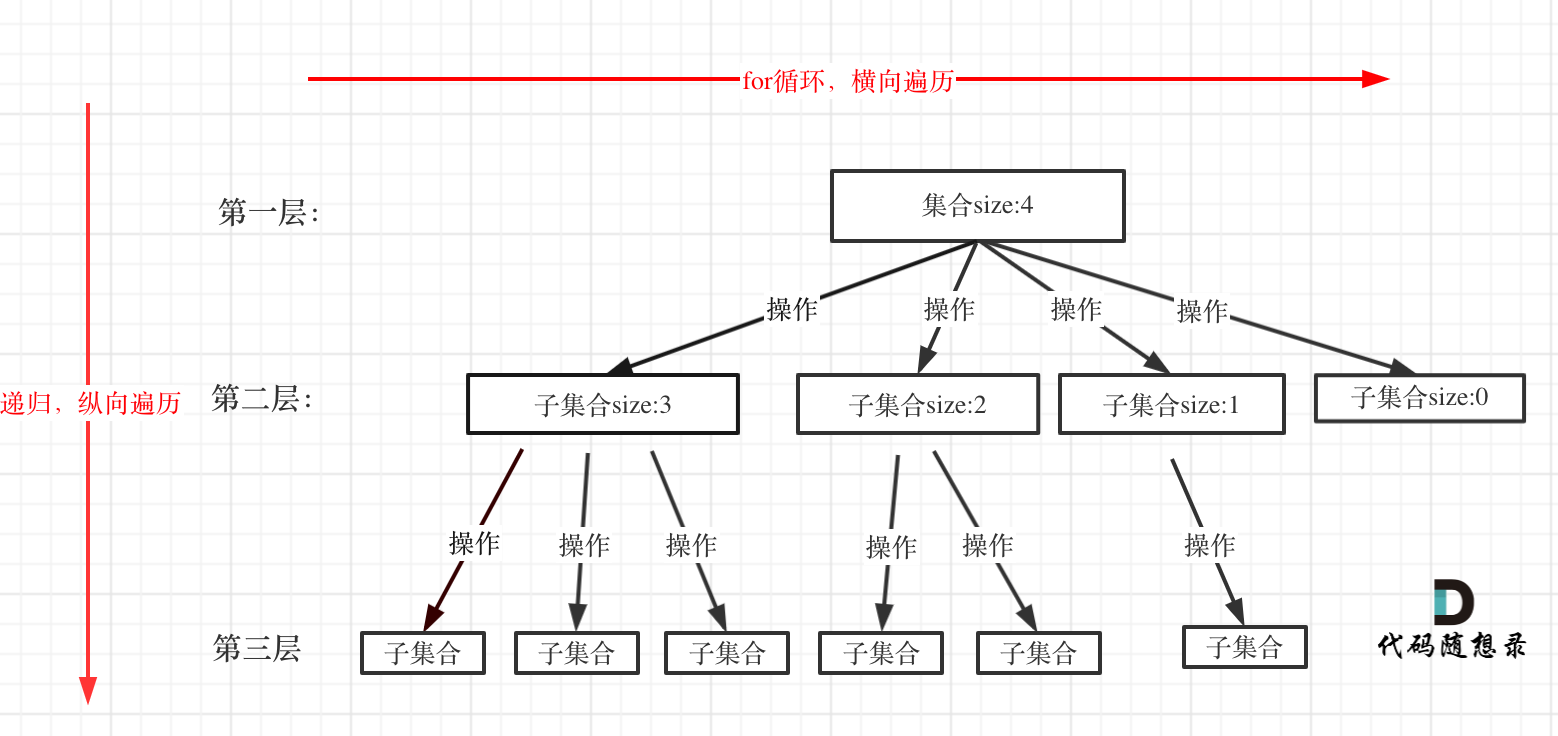
注意图中,我特意举例集合大小和孩子的数量是相等的!
回溯函数遍历过程伪代码如下:
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果}
for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
backtracking这里自己调用自己,实现递归。
大家可以从图中看出for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
分析完过程,回溯算法模板框架如下:
void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果}}
1.组合问题
把组合问题抽象为如下树形结构:
可以看出这个棵树,一开始集合是 1,2,3,4, 从左向右取数,取过的数,不在重复取。
第一次取1,集合变为2,3,4 ,因为k为2,我们只需要再取一个数就可以了,分别取2,3,4,得到集合[1,2] [1,3] [1,4],以此类推。
每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围。
图中可以发现n相当于树的宽度,k相当于树的深度。
那么如何在这个树上遍历,然后收集到我们要的结果集呢?
图中每次搜索到了叶子节点,我们就找到了一个结果。
相当于只需要把达到叶子节点的结果收集起来,就可以求得 n个数中k个数的组合集合
private List<List<Integer>> ans = new ArrayList<>();public List<List<Integer>> combine(int n, int k) {List<Integer> path = new ArrayList<>();process(n, k, 1, path);return ans;}private void process(int n, int k, int index, List<Integer> path) {if (path.size() == k) {List<Integer> list = new ArrayList<>(path);ans.add(list);return;}for (int i = index; i <= n ; i++) {path.add(i);process(n, k, i + 1, path);path.remove(path.size() - 1);}}
剪枝优化
这个遍历的范围是可以剪枝优化的,怎么优化呢?
来举一个例子,n = 4,k = 4的话,那么第一层for循环的时候,从元素2开始的遍历都没有意义了。 在第二层for循环,从元素3开始的遍历都没有意义了。
这么说有点抽象,如图所示: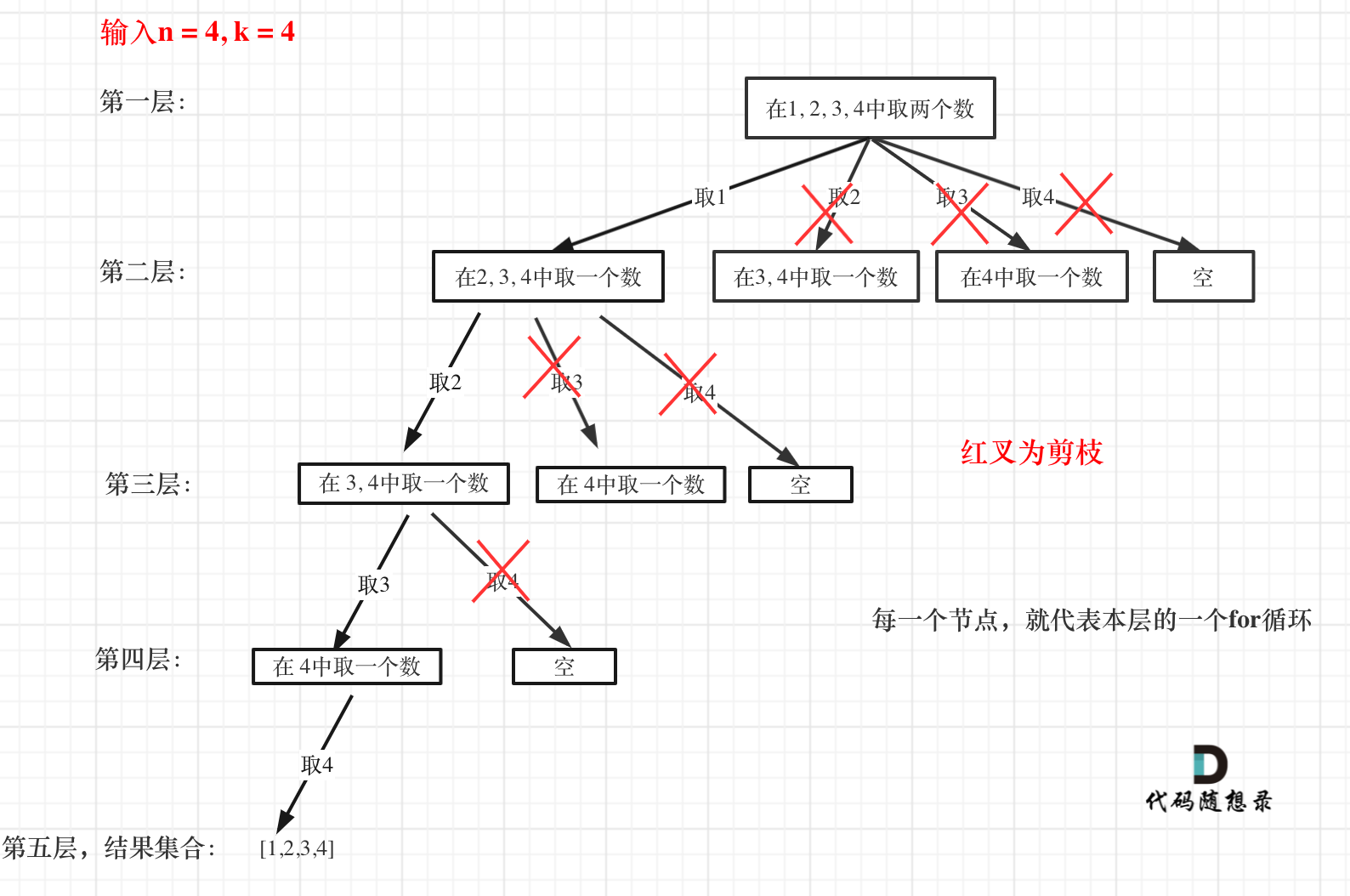
图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。
所以,可以剪枝的地方就在递归中每一层的for循环所选择的起始位置。
如果for循环选择的起始位置之后的元素个数 已经不足 我们需要的元素个数了,那么就没有必要搜索了。
注意代码中i,就是for循环里选择的起始位置。
for (int i = index; i <= n ; i++)
接下来看一下优化过程如下:
- 已经选择的元素个数:path.size();
- 还需要的元素个数为: k - path.size();
- 在集合n中至多要从该起始位置 : n - (k - path.size()) + 1,开始遍历
为什么有个+1呢,因为包括起始位置,我们要是一个左闭的集合。
举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
从2开始搜索都是合理的,可以是组合[2, 3, 4]
for (int i = index; i <= n - (k - path.size()) + 1 ; i++) { // 剪枝优化
2.组合总和Ⅲ
- 无非就是相比77.组合多了一个限制而已
```java
private List
path = new LinkedList<>();
public List
private void process(int targetSum, int k, int index, int sum) { //剪枝 if (sum > targetSum) return;
if (path.size() == k) {if (sum == targetSum) {ans.add(new ArrayList<>(path));}return;}for (int i = index; i <= 9 - (k - path.size()) + 1; i++) { //剪枝path.add(i);sum += i;process(targetSum, k, i + 1, sum);path.removeLast(); // 回溯sum -= i; // 回溯}
}
<a name="AKuGH"></a># 3.[电话号码的字母组合](https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number/)- 需要一个映射```javachar[][] map = {{' ', ' ', ' '},{' ', ' ', ' '},{'a', 'b', 'c'},{'d', 'e', 'f'},{'g', 'h', 'i'},{'j', 'k', 'l'},{'m', 'n', 'o'},{'p', 'q', 'r', 's'},{'t', 'u', 'v'},{'w', 'x', 'y', 'z'}};List<String> ans = new ArrayList<>();public List<String> letterCombinations(String digits) {if (digits == null || digits.length() == 0) {return ans;}char[] str = digits.toCharArray();LinkedList<Character> path = new LinkedList<>();process(str, 0, path);return ans;}private void process(char[] str, int index, LinkedList<Character> path) {if (index == str.length) {StringBuilder sb = new StringBuilder();for (char s : path) {sb.append(s);}ans.add(sb.toString());return;}char[] letters = map[str[index] - '0'];for (int i = 0; i < letters.length; i++) {path.add(letters[i]);process(str, index + 1, path);path.removeLast();}}
4.组合总和⭐
- candidate 中的每个元素都 互不相同
candidates 中的 同一个 数字可以 无限制重复被选取
private List<List<Integer>> ans = new ArrayList<>();private List<Integer> path = new ArrayList<>();public List<List<Integer>> combinationSum(int[] candidates, int target) {process(candidates, 0, target);return ans;}// arr[index....]的数自由选择,每一种数任意个,(0 .。。。 index -1) 不用管// 凑出targetLeaveprivate void process(int[] candidates, int index, int targetLeave) {if (targetLeave == 0) {ans.add(new ArrayList<>(path));return;}if (targetLeave < 0) {return;}for (int i = index; i < candidates.length; i++) {path.add(candidates[i]);targetLeave -= candidates[i];process(candidates, i, targetLeave); // 关键点:不用i+1了,表示可以重复读取当前的数targetLeave += candidates[i]; // 回溯path.remove(path.size() - 1); // 回溯}}
剪枝优化
- 对原数组进行排序
如果已经遍历到的i使得targetLeave - candidates[i] < 0就不用再继续遍历了
private List<List<Integer>> ans = new ArrayList<>();private List<Integer> path = new ArrayList<>();public List<List<Integer>> combinationSum(int[] candidates, int target) {Arrays.sort(candidates);process(candidates, 0, target);return ans;}// arr[index....]的数自由选择,每一种数任意个,(0 .。。。 index -1) 不用管// 凑出targetLeaveprivate void process(int[] candidates, int index, int targetLeave) {if (targetLeave == 0) {ans.add(new ArrayList<>(path));return;}//// if (targetLeave < 0) {// return;// }for (int i = index; i < candidates.length && targetLeave - candidates[i] >= 0; i++) { // 剪枝优化path.add(candidates[i]);targetLeave -= candidates[i];process(candidates, i, targetLeave); // 关键点:不用i+1了,表示可以重复读取当前的数targetLeave += candidates[i]; // 回溯path.remove(path.size() - 1); // 回溯}}
5.组合总和Ⅱ⭐
这道题目和39.组合总和(opens new window)如下区别:
- 本题candidates 中的每个数字在每个组合中只能使用一次。
- 本题数组candidates的元素是有重复的,而39.组合总和(opens new window)是无重复元素的数组candidates
最后本题和39.组合总和(opens new window)要求一样,解集不能包含重复的组合。
本题的难点在于区别2中:集合(数组candidates)有重复元素,但还不能有重复的组合。
如何在搜索的过程中去掉重复组合?
所谓去重,其实就是使用过的元素不能重复选取
都知道组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上使用过,一个维度是同一树层上使用过。没有理解这两个层面上的“使用过” 是造成大家没有彻底理解去重的根本原因。
那么问题来了,我们是要同一树层上使用过,还是同一树枝上使用过呢?
回看一下题目,元素在同一个组合内是可以重复的,怎么重复都没事,但两个组合不能相同。
所以我们要去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重。
为了理解去重我们来举一个例子,candidates = [1, 1, 2], target = 3,(方便起见candidates已经排序了)
强调一下,树层去重的话,需要对数组排序!
选择过程树形结构如图所示:
- 单层搜索的逻辑
这里与39.组合总和(opens new window)最大的不同就是要去重了。
前面我们提到:要去重的是“同一树层上的使用过”,如何判断同一树层上元素(相同的元素)是否使用过了呢。
如果candidates[i] == candidates[i - 1] 并且 used[i - 1] == false,就说明:前一个树枝,使用了candidates[i - 1],也就是说同一树层使用过candidates[i - 1]。
此时for循环里就应该做continue的操作。
这块比较抽象,如图: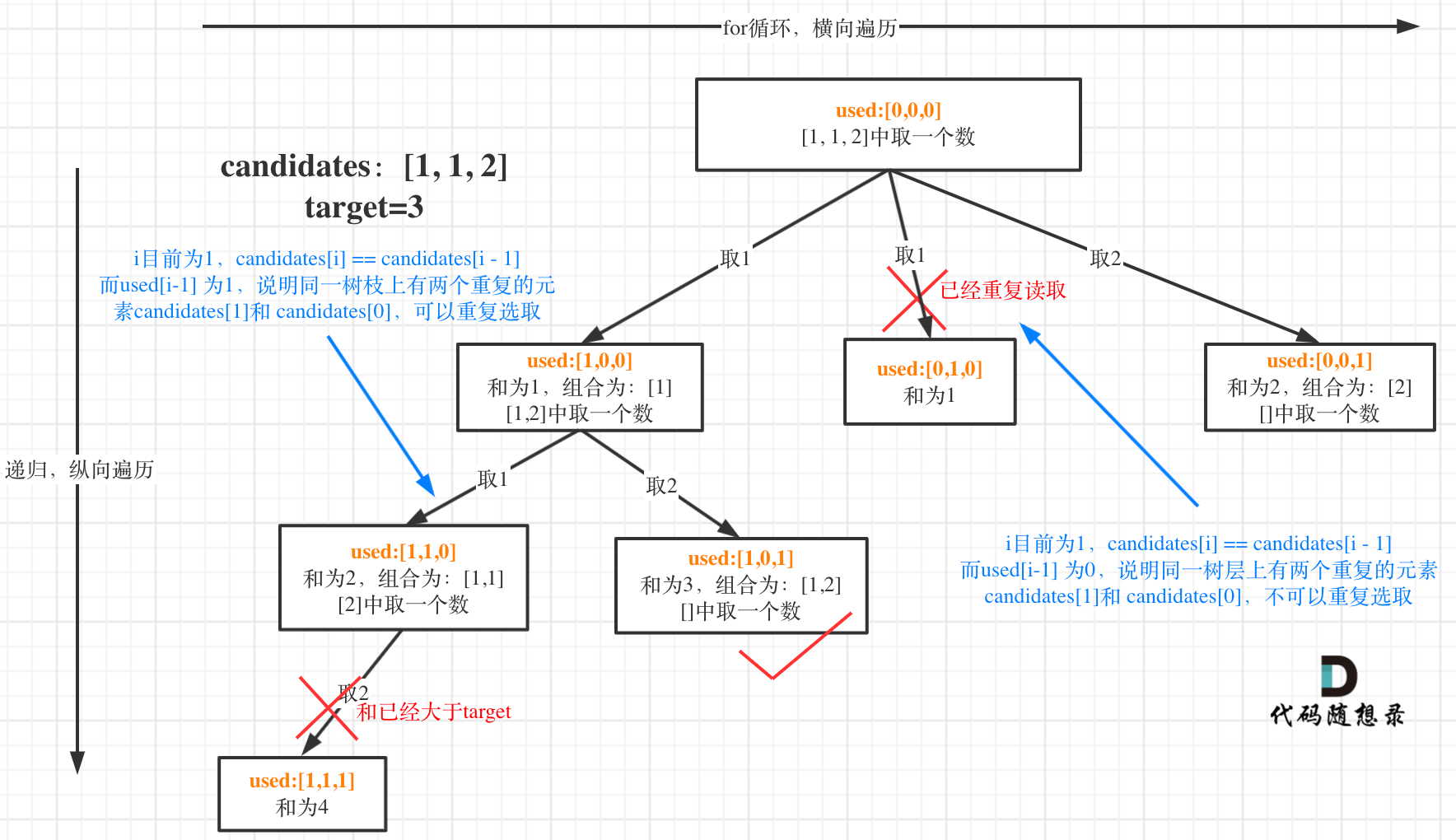
我在图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
- used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
- used[i - 1] == false,说明同一树层candidates[i - 1]使用过
```java
private List
path = new ArrayList<>();
public List<List<Integer>> combinationSum2(int[] candidates, int target) {Arrays.sort(candidates);boolean[] flag = new boolean[candidates.length];process(candidates, 0, target, flag);return ans;}private void process(int[] candidates, int index, int targetLeave, boolean[] flag) {if (targetLeave == 0) {ans.add(new ArrayList<>(path));}for (int i = index; i < candidates.length && targetLeave - candidates[i] >= 0; i++) {// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过// used[i - 1] == false,说明同一树层candidates[i - 1]使用过// 要对同一树层使用过的元素进行跳过if (i > 0 && candidates[i] == candidates[i - 1] && !flag[i - 1]) {continue;}path.add(candidates[i]);targetLeave -= candidates[i];flag[i] = true;process(candidates, i + 1, targetLeave, flag); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次flag[i] = false;targetLeave += candidates[i];path.remove(path.size() - 1);}}
- 直接使用index进行去重也可以```javaList<List<Integer>> res = new ArrayList<>();LinkedList<Integer> path = new LinkedList<>();int sum = 0;public List<List<Integer>> combinationSum2( int[] candidates, int target ) {//为了将重复的数字都放到一起,所以先进行排序Arrays.sort( candidates );backTracking( candidates, target, 0 );return res;}private void backTracking( int[] candidates, int target, int start ) {if ( sum == target ) {res.add( new ArrayList<>( path ) );return;}for ( int i = start; i < candidates.length && sum + candidates[i] <= target; i++ ) {//正确剔除重复解的办法//跳过同一树层使用过的元素if ( i > start && candidates[i] == candidates[i - 1] ) {continue;}sum += candidates[i];path.add( candidates[i] );// i+1 代表当前组内元素只选取一次backTracking( candidates, target, i + 1 );int temp = path.getLast();sum -= temp;path.removeLast();}}
6.分割回文串⭐
本题这涉及到两个关键问题:
- 切割问题,有不同的切割方式
- 判断回文
其实切割问题类似组合问题。
例如对于字符串abcdef:
- 组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中在选组第三个…..。
- 切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中在切割第三段…..。
所以切割问题,也可以抽象为一棵树形结构,如图:
递归用来纵向遍历,for循环用来横向遍历,切割线(就是图中的红线)切割到字符串的结尾位置,说明找到了一个切割方法。
此时可以发现,切割问题的回溯搜索的过程和组合问题的回溯搜索的过程是差不多的。
Stri , L~R范围上能分解出多少种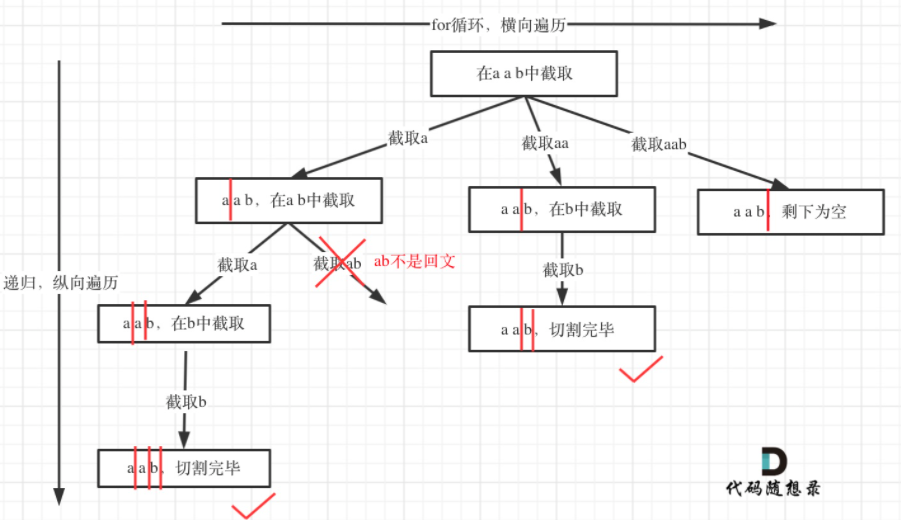
List<List<String>> ans = new ArrayList<>();LinkedList<String> path = new LinkedList<>(); // 放已经回文的子串public List<List<String>> partition(String s) {process(s, 0);return ans;}private void process(String str, int index) {// 如果起始位置已经等于s的大小,说明已经找到了一组分割方案了if (index == str.length()) {ans.add(new ArrayList<>(path));return;}for (int i = index; i < str.length(); i++) {if (isPalindrome(str, index, i)) {// 是回文子串// 获取[index,i]在s中的子串path.add(str.substring(index, i + 1));} else {// 不是回文,跳过continue;}process(str, i + 1);// 寻找i+1为起始位置的子串path.removeLast();// 回溯过程,弹出本次已经填在的子串}}private boolean isPalindrome(String str, int start, int end) {while (start < end) {if (str.charAt(start) != str.charAt(end)) {return false;}start++;end--;}return true;}
注意切割过的位置,不能重复切割,所以,process(s, i + 1); 传入下一层的起始位置为i + 1。
7.复原IP地址
这其实也是一个切割问题
切割问题就可以使用回溯搜索法把所有可能性搜出来
切割问题可以抽象为树型结构,如图:
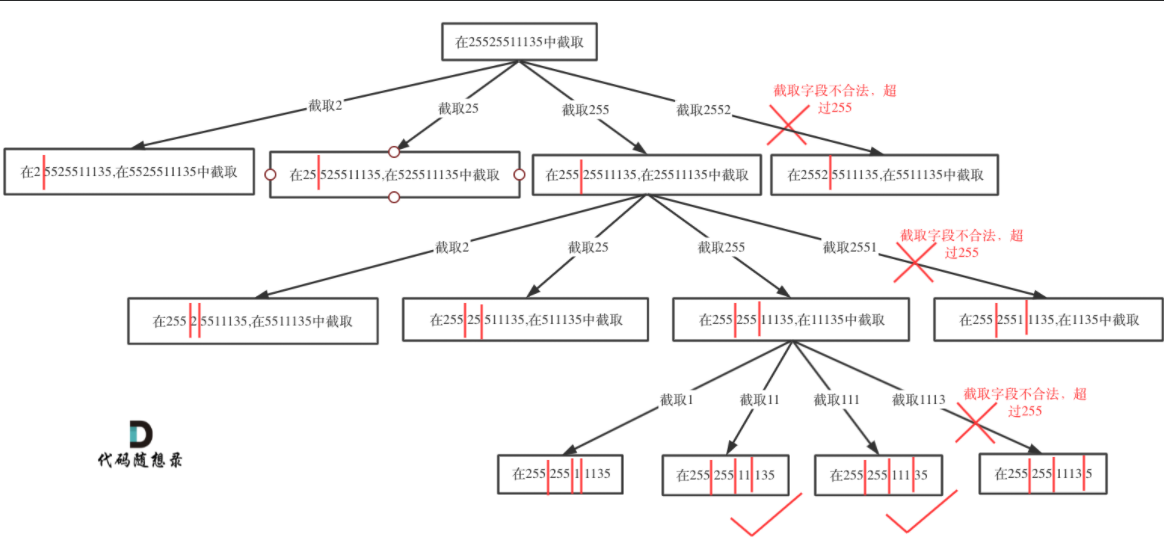
递归参数
- Index一定是需要的,因为不能重复分割,记录下一层递归分割的起始位置。
- 本题我们还需要一个变量pointNum,记录添加逗点的数量。
递归终止条件
终止条件和131.分割回文串 (opens new window)情况就不同了,本题明确要求只会分成4段,所以不能用切割线切到最后作为终止条件,而是分割的段数作为终止条件。
pointNum表示逗点数量,pointNum为3说明字符串分成了4段了。
然后验证一下第四段是否合法,如果合法就加入到结果集里List<String> ans = new ArrayList<>();public List<String> restoreIpAddresses(String s) {if (s.length() > 12 || s.length() == 0 ) {return ans;}process(s, 0, 0);return ans;}private void process(String s, int index, int pointNum) {if (pointNum == 3) {if (isValid(s, index, s.length() - 1)) {ans.add(s);}return;}for (int i = index; i < s.length(); i++) {//s[index, i]if (isValid(s, index, i)) {s = s.substring(0, i + 1) + "." + s.substring(i + 1);pointNum++;process(s, i + 2, pointNum);pointNum--;s = s.substring(0, i + 1) + s.substring(i + 2);} else {break;}}}//判断字符串[start, end]区间是否合法private boolean isValid(String str, int start, int end) {if (start > end) {return false;}//前导0if (str.charAt(start) == '0' && start != end) {return false;}//超范围int sum = 0;for (int i = start; i <= end; i++) {if (str.charAt(i) < '0' || str.charAt(i) > '9') {return false;}sum = sum * 10 + (str.charAt(i) - '0'); //注意别忘了 - ‘0’if (sum > 255) {return false;}}return true;}
8.子集问题⭐
求子集问题和77.组合(opens new window)和131.分割回文串(opens new window)又不一样了。
如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!
其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。
那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!
有同学问了,什么时候for可以从0开始呢?
求排列问题的时候,就要从0开始,因为集合是有序的,{1, 2} 和{2, 1}是两个集合,排列问题我们后续的文章就会讲到的。
以示例中nums = [1,2,3]为例把求子集抽象为树型结构,如下: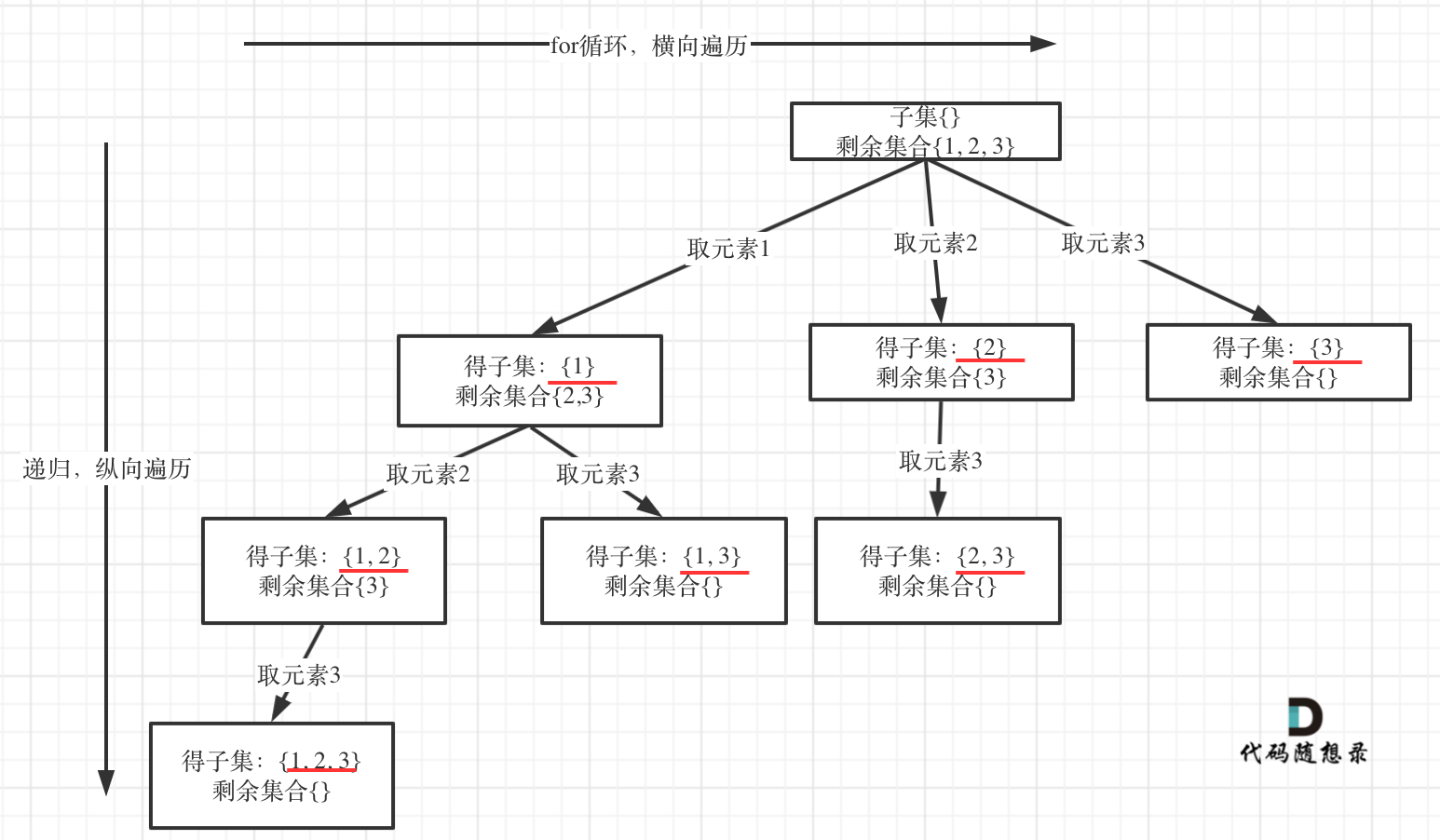
从图中红线部分,可以看出遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合。
List<List<Integer>> ans = new ArrayList<>();LinkedList<Integer> path = new LinkedList<>();public List<List<Integer>> subsets(int[] nums) {if (nums == null) {return ans;}process(nums, 0);return ans;}private void process(int[] nums, int index) {ans.add(new ArrayList<>(path));if (index >= nums.length) {return;}for (int i = index; i < nums.length; i++) {path.add(nums[i]);process(nums, i + 1);path.removeLast();}}
9.子集Ⅱ⭐
这道题目和78.子集 (opens new window)区别就是集合里有重复元素了,而且求取的子集要去重。
用示例中的[1, 2, 2] 来举例,如图所示: (注意去重需要先对集合排序)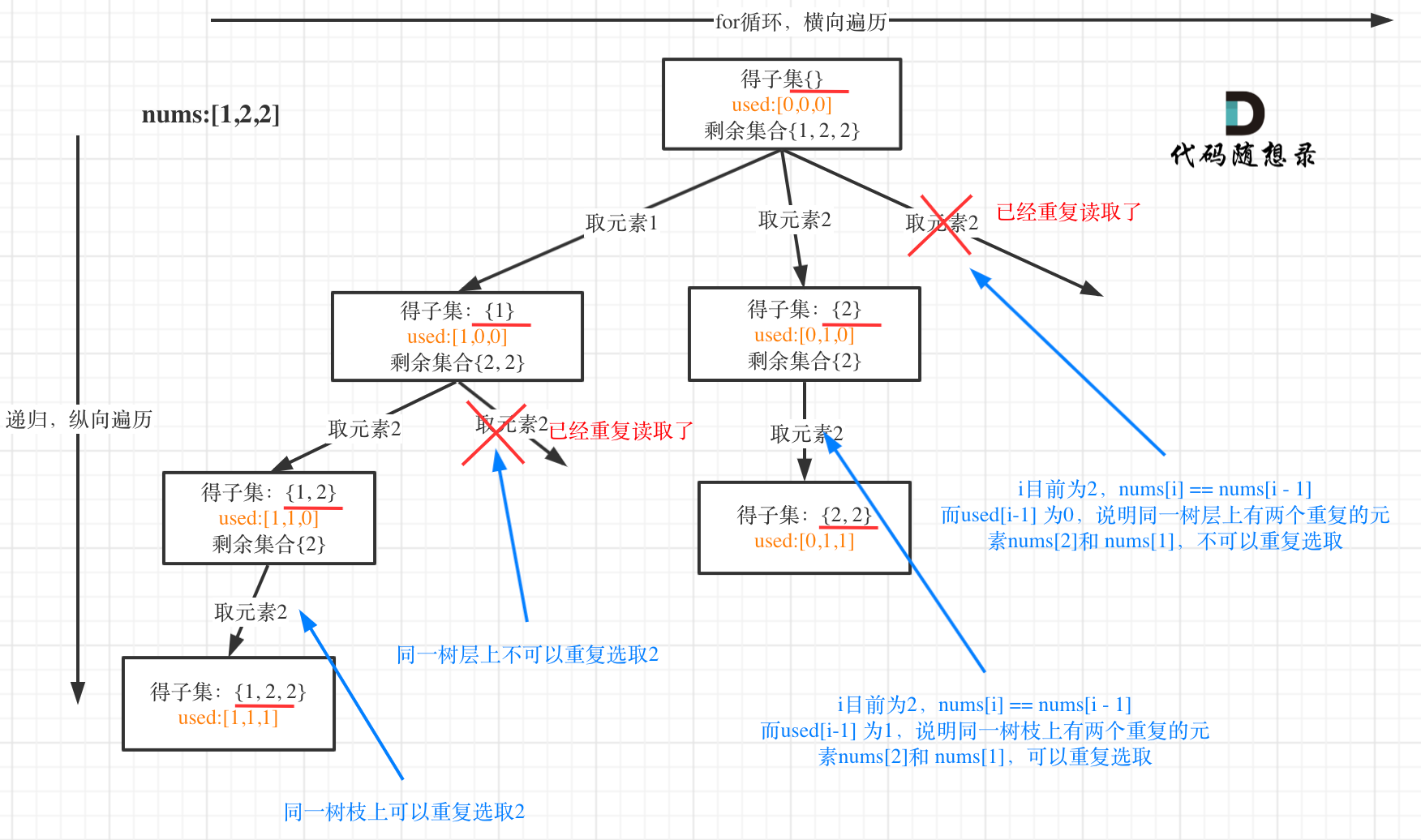
从图中可以看出,同一树层上重复取2 就要过滤掉,同一树枝上就可以重复取2,因为同一树枝上元素的集合才是唯一子集!
List<List<Integer>> ans = new ArrayList<>();LinkedList<Integer> path = new LinkedList<>();public List<List<Integer>> subsetsWithDup(int[] nums) {boolean[] used = new boolean[nums.length];if (nums == null) {return ans;}Arrays.sort(nums);// 去重需要排序process(nums, 0, used);return ans;}private void process(int[] nums, int index, boolean[] used) {ans.add(new ArrayList<>(path));if (index >= nums.length) {return;}for (int i = index; i < nums.length; i++) {// used[i - 1] == true,说明同一树枝candidates[i - 1]使用过// used[i - 1] == false,说明同一树层candidates[i - 1]使用过// 而我们要对同一树层使用过的元素进行跳过if (i > 0 && nums[i - 1] == nums[i] && used[i - 1] == false) {continue;}path.add(nums[i]);used[i] = true;process(nums, i + 1, used);used[i] = false;path.removeLast();}}
补充
本题也可以不使用used数组来去重,因为递归的时候下一个Index是i+1而不是0
List<List<Integer>> ans = new ArrayList<>();LinkedList<Integer> path = new LinkedList<>();public List<List<Integer>> subsetsWithDup(int[] nums) {boolean[] used = new boolean[nums.length];if (nums == null) {return ans;}Arrays.sort(nums);// 去重需要排序process(nums, 0, used);return ans;}private void process(int[] nums, int index, boolean[] used) {ans.add(new ArrayList<>(path));if (index >= nums.length) {return;}for (int i = index; i < nums.length; i++) {// 而我们要对同一树层使用过的元素进行跳过if (i > startIndex && nums[i] == nums[i - 1] ) { // 注意这里使用i > startIndexcontinue;}path.add(nums[i]);used[i] = true;process(nums, i + 1, used);used[i] = false;path.removeLast();}}
10.递增子序列⭐
这个递增子序列比较像是取有序的子集。而且本题也要求不能有相同的递增子序列。
这又是子集,又是去重,是不是不由自主的想起了刚刚讲过的90.子集II (opens new window)。
就是因为太像了,更要注意差别所在,要不就掉坑里了!
在90.子集II (opens new window)中我们是通过排序,再加一个标记数组来达到去重的目的。
而本题求自增子序列,是不能对原数组经行排序的,排完序的数组都是自增子序列了。
所以不能使用之前的去重逻辑!
本题给出的示例,还是一个有序数组 [4, 6, 7, 7],这更容易误导大家按照排序的思路去做了。
为了有鲜明的对比,我用[4, 7, 6, 7]这个数组来举例,抽象为树形结构如图:

回溯三部曲
- 递归函数参数
本题求子序列,很明显一个元素不能重复使用,所以需要startIndex,调整下一层递归的起始位置。
代码如下:
List<List<Integer>> ans = new ArrayList<>();LinkedList<Integer> path = new LinkedList<>();private void process(int[] nums, int index)
- 终止条件
本题其实类似求子集问题,也是要遍历树形结构找每一个节点,所以和回溯算法:求子集问题! (opens new window)一样,可以不加终止条件,startIndex每次都会加1,并不会无限递归。
但本题收集结果有所不同,题目要求递增子序列大小至少为2,所以代码如下:
if (path.size() >= 2) {ans.add(new ArrayList<>(path));// 注意这里不要加return,因为要取树上的所有节点}
- 单层搜索逻辑
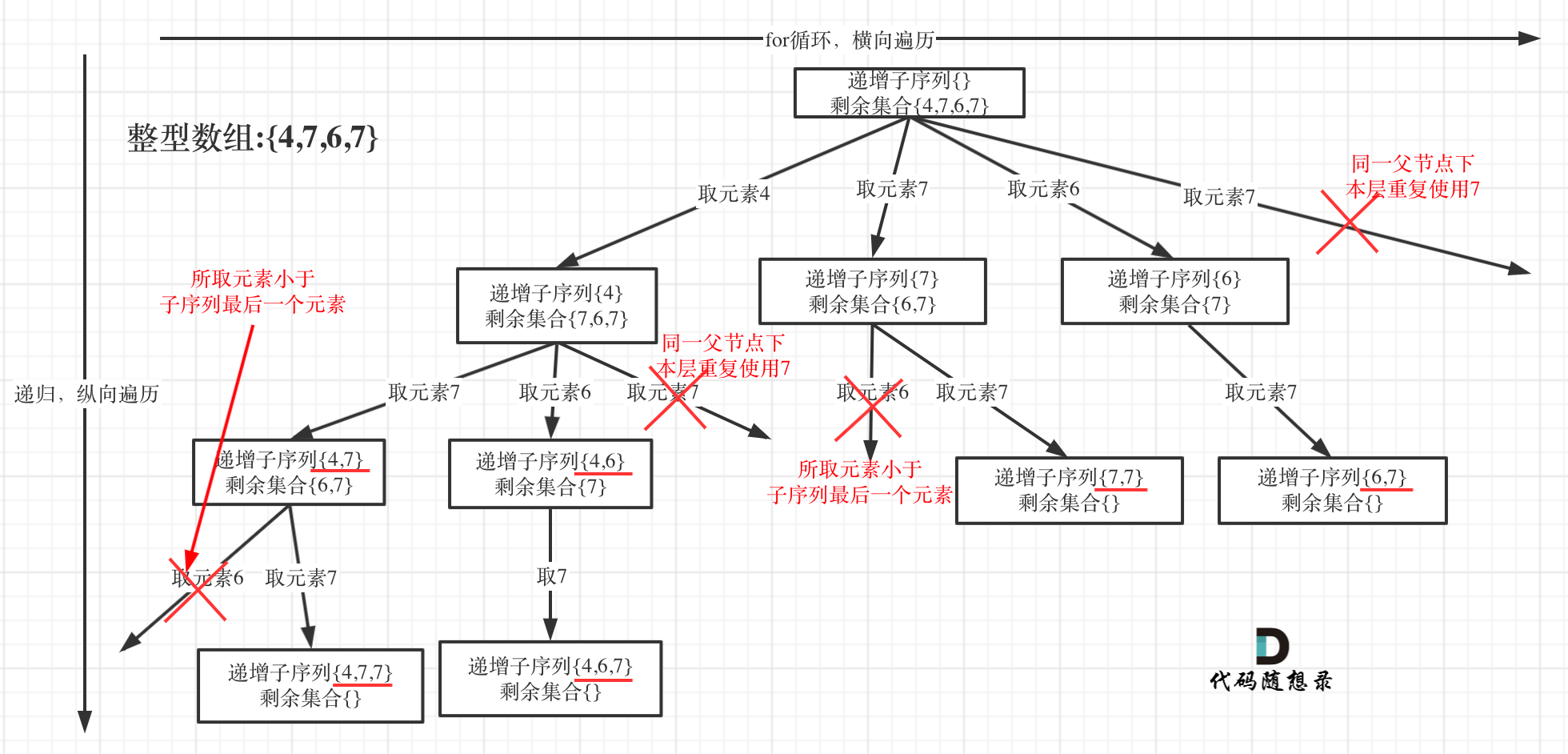
在图中可以看出,同一父节点下的同层上使用过的元素就不能在使用了
那么单层搜索代码如下:
Set<Integer> set = new HashSet<>(); // 使用set对本层元素进行去重for (int i = index; i < nums.length; i++) {if (!path.isEmpty() && nums[i] < path.peekLast() || set.contains(nums[i])) {continue;}set.add(nums[i]); // 记录这个元素在本层用过了,本层后面不能再用了path.add(nums[i]);process(nums, i + 1);path.removeLast();}
对于已经习惯写回溯的同学,看到递归函数上面的**uset.insert(nums[i]);**,下面却没有对应的pop之类的操作,应该很不习惯吧,哈哈
这也是需要注意的点,**unordered_set<int> uset;** 是记录本层元素是否重复使用,新的一层uset都会重新定义(清空),所以要知道uset只负责本层!
总代码
List<List<Integer>> ans = new ArrayList<>();LinkedList<Integer> path = new LinkedList<>();public List<List<Integer>> findSubsequences(int[] nums) {if (nums == null) {return ans;}process(nums, 0);return ans;}private void process(int[] nums, int index) {if (path.size() >= 2) {ans.add(new ArrayList<>(path));// 注意这里不要加return,因为要取树上的所有节点}Set<Integer> set = new HashSet<>(); // 使用set对本层元素进行去重for (int i = index; i < nums.length; i++) {if (!path.isEmpty() && nums[i] < path.peekLast() || set.contains(nums[i])) {continue;}set.add(nums[i]); // 记录这个元素在本层用过了,本层后面不能再用了path.add(nums[i]);process(nums, i + 1);path.removeLast();}}
11.全排列⭐
我以[1,2,3]为例,抽象成树形结构如下: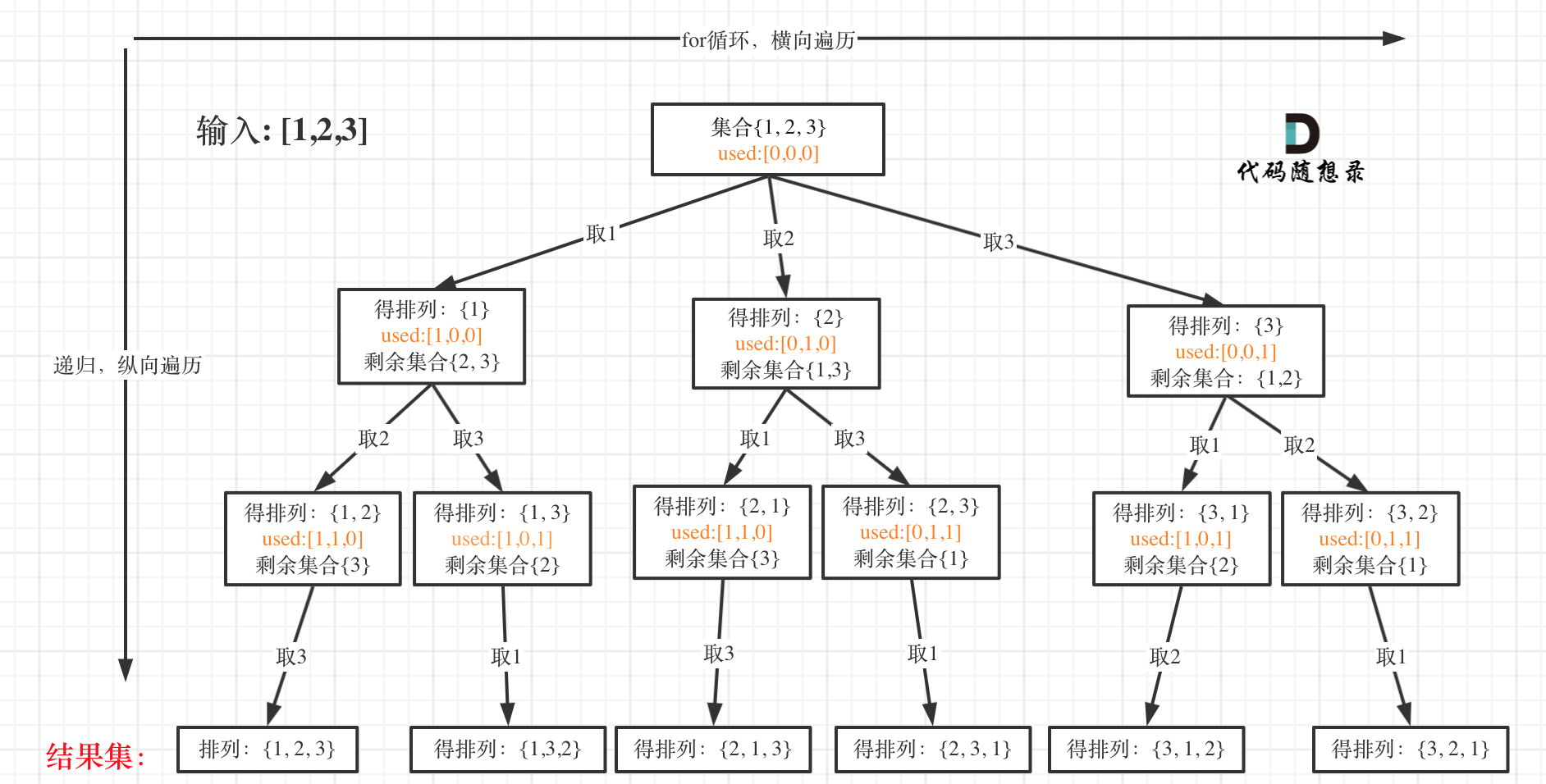
回溯三部曲
- 递归函数参数
首先排列是有序的,也就是说 [1,2] 和 [2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方。
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。
但排列问题需要一个used数组,标记已经选择的元素,如图橘黄色部分所示: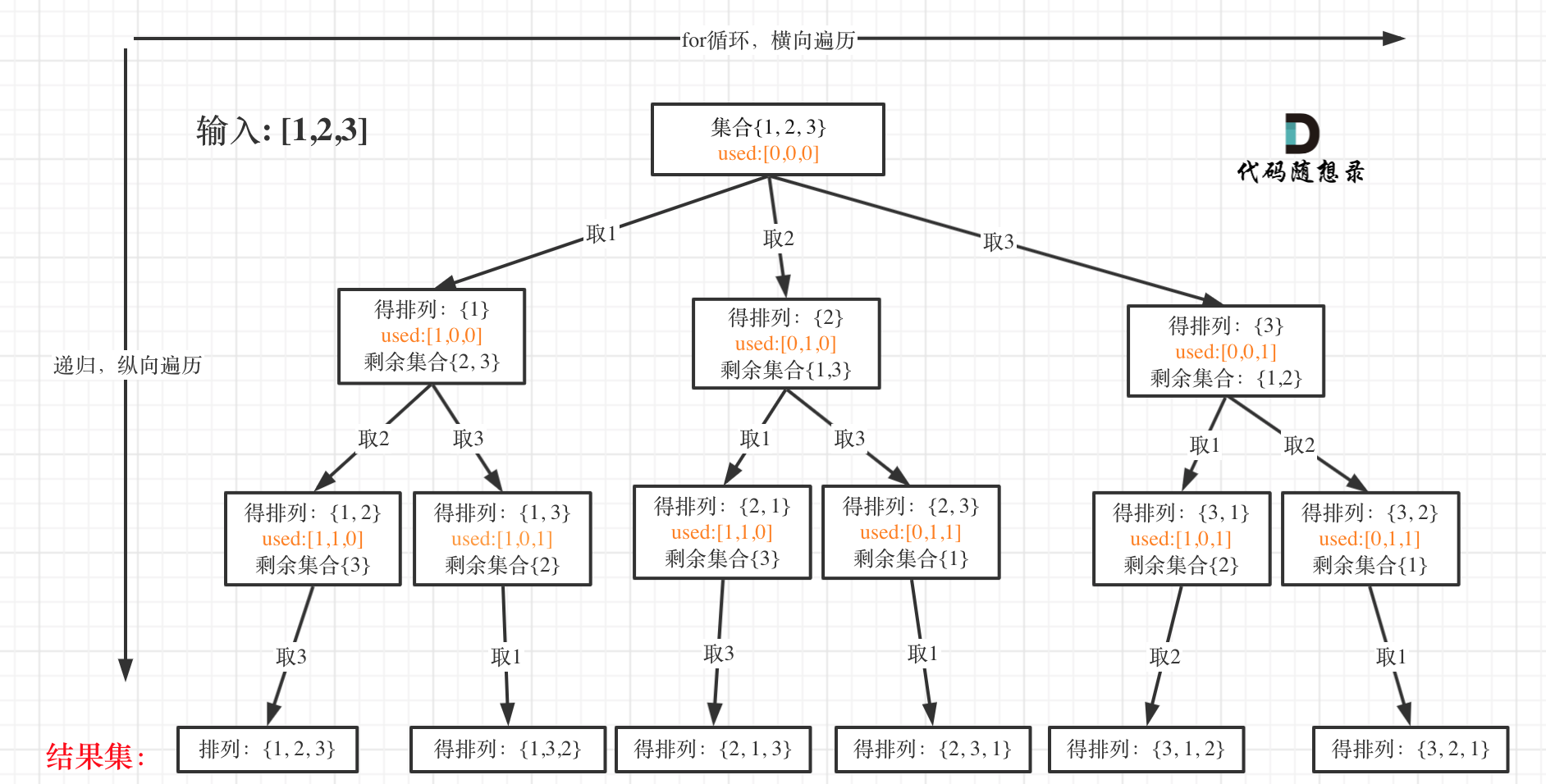
代码如下:
List<List<Integer>> ans = new ArrayList<>();LinkedList<Integer> path = new LinkedList<>();public List<List<Integer>> permute(int[] nums)
- 递归终止条件

可以看出叶子节点,就是收割结果的地方。
那么什么时候,算是到达叶子节点呢?
当收集元素的数组path的大小达到和nums数组一样大的时候,说明找到了一个全排列,也表示到达了叶子节点。
代码如下:
// 此时说明找到了一组if (path.size() == nums.length) {ans.add(new ArrayList<>(path));return;}
- 单层搜索的逻辑
这里和77.组合问题 (opens new window)、131.切割问题 (opens new window)和78.子集问题 (opens new window)最大的不同就是for循环里不用startIndex了。
因为排列问题,每次都要从头开始搜索,例如元素1在[1,2]中已经使用过了,但是在[2,1]中还要再使用一次1。
而used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次。
代码如下:
for (int i = 0; i < nums.length; i++) {if (used[i]) {continue;}path.add(nums[i]);used[i] = true;process(nums, used);used[i] = false;path.removeLast();}
整体java代码如下:
private List<List<Integer>> ans = new ArrayList<>();private LinkedList<Integer> path = new LinkedList<>();public List<List<Integer>> permute(int[] nums) {boolean[] used = new boolean[nums.length];process(nums, used);return ans;}//nums中无重复数字private void process(int[] nums, boolean[] used ) {if (path.size() == nums.length) {ans.add(new ArrayList<>(path));return;}for (int i = 0; i < nums.length; i++) {if (used[i]) {continue;}path.add(nums[i]);used[i] = true;process(nums, used);used[i] = false;path.removeLast();}}
总结:
此时可以感受出排列问题的不同:
- 每层都是从0开始搜索而不是startIndex
- 需要used数组记录path里都放了哪些元素了
排列问题是回溯算法解决的经典题目
12.全排列Ⅱ⭐
- 去重
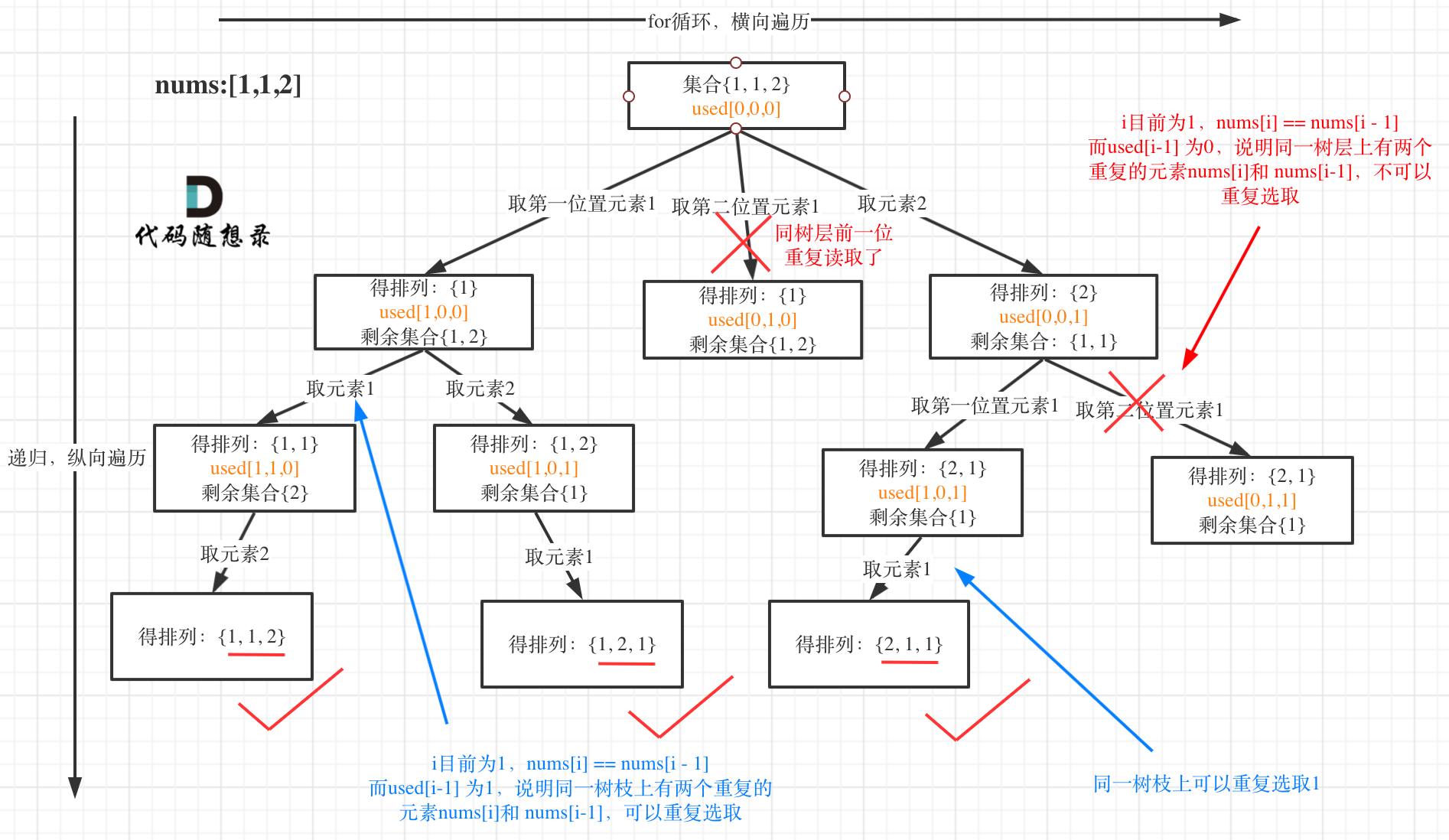
private List<List<Integer>> ans = new ArrayList<>();private LinkedList<Integer> path = new LinkedList<>();public List<List<Integer>> permuteUnique(int[] nums) {boolean[] used = new boolean[nums.length];Arrays.sort(nums);process(nums, used);return ans;}private void process(int[] nums, boolean[] used) {if (path.size() == nums.length) {ans.add(new ArrayList<>(path));return;}for (int i = 0; i < nums.length; i++) {if ((i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false)) {continue;}if (used[i] == false) {path.add(nums[i]);used[i] = true;process(nums, used);used[i] = false;path.removeLast();}}}
13.重新安排行程⭐⭐
这道题目有几个难点:
- 一个行程中,如果航班处理不好容易变成一个圈,成为死循环
- 有多种解法,字母序靠前排在前面,让很多同学望而退步,如何该记录映射关系呢 ?
- 使用回溯法(也可以说深搜) 的话,那么终止条件是什么呢?
- 搜索的过程中,如何遍历一个机场所对应的所有机场。
如何理解死循环?
对于死循环,举一个有重复机场的例子: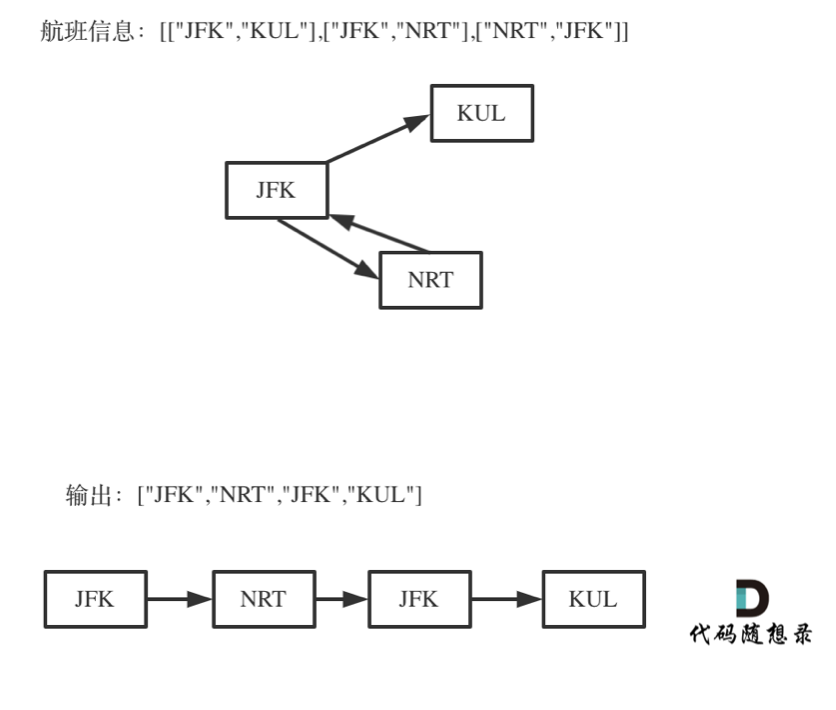
这个例子说明出发机场和到达机场也会重复的,如果在解题的过程中没有对集合元素处理好,就会死循环
记录映射关系
// <出发机场, <目的机场, 航班次数>>private Map<String, TreeMap<String, Integer>> map = new HashMap<>();
在遍历 map<出发机场, map<到达机场, 航班次数>> 的过程中,可以使用”航班次数”这个字段的数字做相应的增减,来标记到达机场是否使用过了。
如果“航班次数”大于零,说明目的地还可以飞,如果如果“航班次数”等于零说明目的地不能飞了,而不用对集合做删除元素或者增加元素的操作。
回溯法
private boolean process(int ticketNum)
注意函数返回值我用的是bool!
回溯算法一般函数返回值都是void,这次为什么是bool呢?
因为我们只需要找到一个行程,就是在树形结构中唯一的一条通向叶子节点的路线,如图: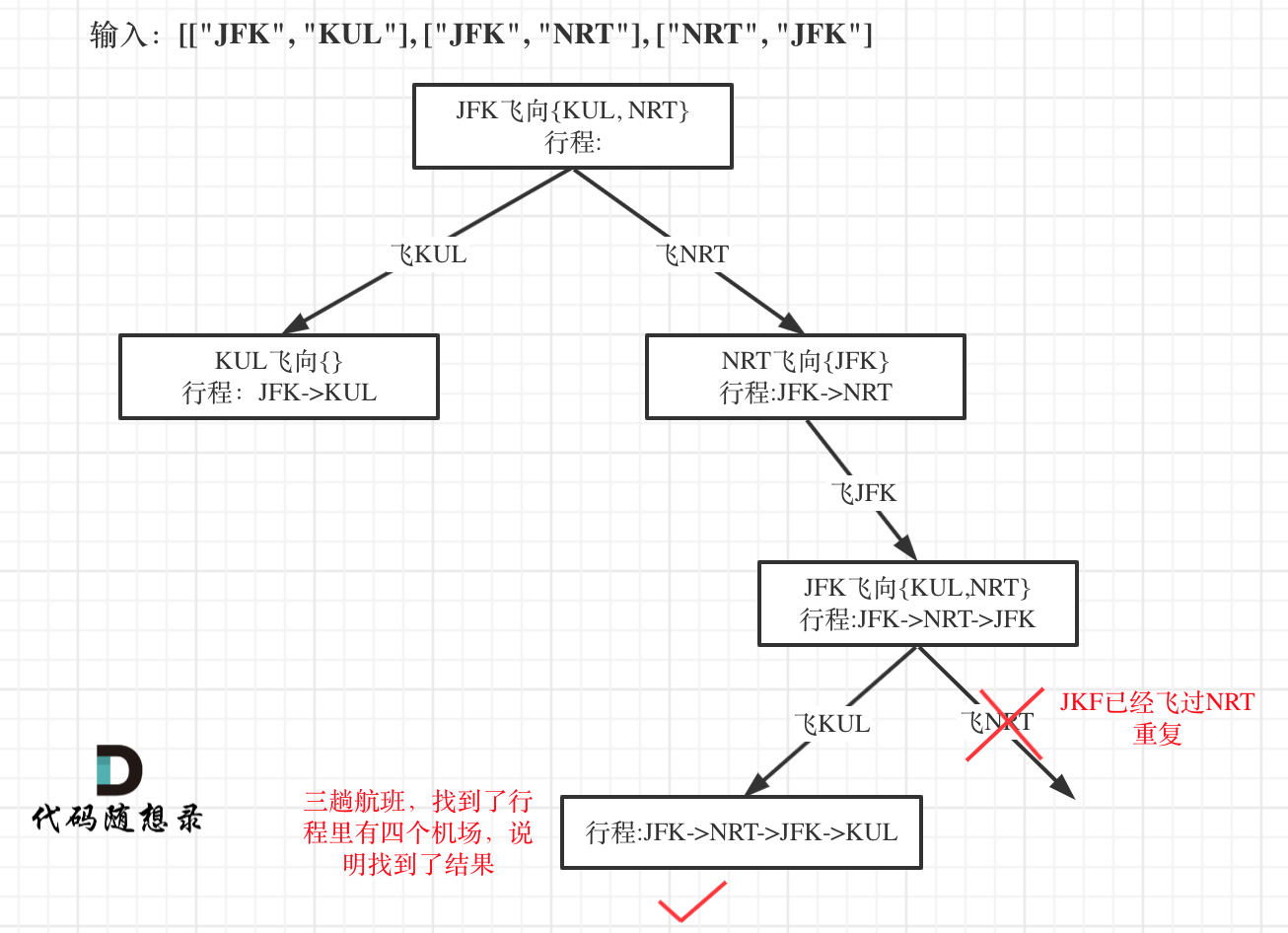
所以找到了这个叶子节点了直接返回
递归终止条件
输入: [[“MUC”, “LHR”], [“JFK”, “MUC”], [“SFO”, “SJC”], [“LHR”, “SFO”]] ,这是有4个航班,那么只要找出一种行程,行程里的机场个数是5就可以了。
所以终止条件是:我们回溯遍历的过程中,遇到的机场个数,如果达到了(航班数量+1),那么我们就找到了一个行程,把所有航班串在一起了。
if (res.size() == ticketNum + 1) {return true;}
总代码
private LinkedList<String> res = new LinkedList<>();// <出发机场, <目的机场, 航班次数>>private Map<String, Map<String, Integer>> map = new HashMap<>();public List<String> findItinerary(List<List<String>> tickets) {for (List<String> t : tickets) {Map<String, Integer> temp;if (map.containsKey(t.get(0))) {temp = map.get(t.get(0));temp.put(t.get(1), temp.getOrDefault(t.get(1), 0) + 1);} else {temp = new TreeMap<>(); //升序maptemp.put(t.get(1), 1);}map.put(t.get(0), temp);}res.add("JFK");process(tickets.size());return new ArrayList<>(res);}/*** @param ticketNum 航班数量*/private boolean process(int ticketNum) {if (res.size() == ticketNum + 1) {return true;}String last = res.getLast();if (map.containsKey(last)) {for (Map.Entry<String, Integer> target : map.get(last).entrySet()) {int count = target.getValue();if (count > 0) {res.add(target.getKey());target.setValue(count - 1);if (process(ticketNum)) return true;target.setValue(count);res.removeLast();}}}return false;}
14.N皇后⭐
首先来看一下皇后们的约束条件:
- 不能同行
- 不能同列
- 不能同斜线
确定完约束条件,来看看究竟要怎么去搜索皇后们的位置,其实搜索皇后的位置,可以抽象为一棵树。
下面我用一个 3 3 的棋盘,将搜索过程抽象为一棵树,如图: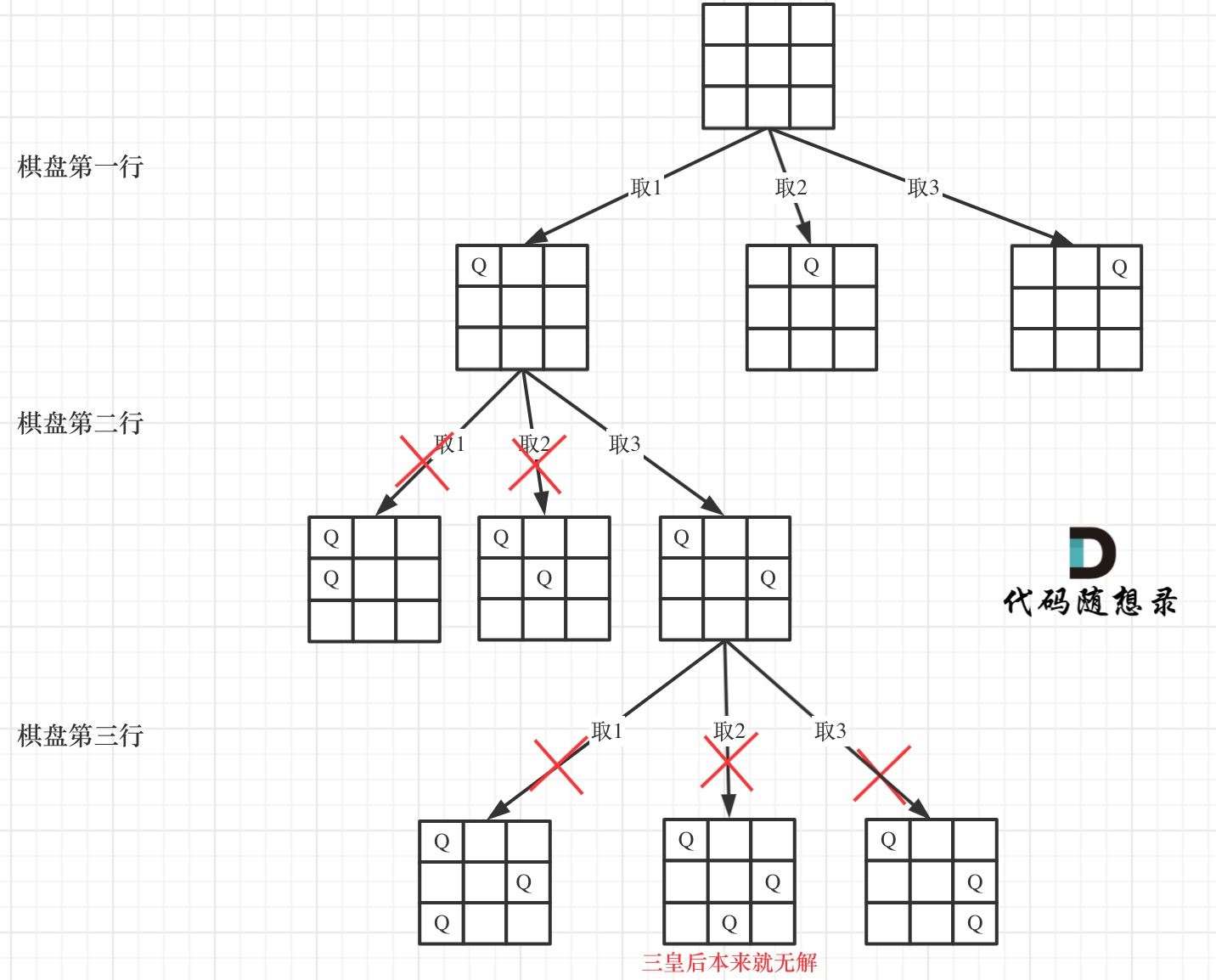
从图中,可以看出,二维矩阵中矩阵的高就是这棵树的高度,矩阵的宽就是树形结构中每一个节点的宽度。
那么我们用皇后们的约束条件,来回溯搜索这棵树,*只要搜索到了树的叶子节点,说明就找到了皇后们的合理位置了。
- 在检查合法性的代码中,可以发现为什么没有在同行进行检查呢?
- 因为在单层搜索的过程中,每一层递归,只会选for循环(也就是同一行)里的一个元素,所以不用去重了。
List<List<String>> res = new ArrayList<>();public List<List<String>> solveNQueens(int n) {char[][] chessboard = new char[n][n];for (char[] c : chessboard) {Arrays.fill(c, '.');}backTrack(n, 0, chessboard);return res;}private void backTrack(int n, int row, char[][] chessboard) {if (row == n) {res.add(toList(chessboard));return;}for (int col = 0; col < n; col++) {if (isValid(row, col, n,chessboard)) {chessboard[row][col] = 'Q'; //摆放皇后backTrack(n, row + 1, chessboard);chessboard[row][col] = '.'; //回溯}}}private boolean isValid(int row, int col, int n, char[][] chessboard) {// 检查列for (int i = 0; i < row; i++) { //相当于剪枝if (chessboard[i][col] == 'Q') {return false;}}// 检查45°对角线for (int i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--) {if (chessboard[i][j] == 'Q') {return false;}}//检查135°对角线for (int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {if (chessboard[i][j] == 'Q') {return false;}}return true;}private List<String> toList(char[][] chessboard) {List<String> list = new ArrayList<>();for (char[] c : chessboard) {list.add(String.valueOf(c));}return list;}
棋盘的宽度就是for循环的长度,递归的深度就是棋盘的高度,这样就可以套进回溯法的模板里了。
15.解数独
N皇后问题(opens new window)是因为每一行每一列只放一个皇后,只需要一层for循环遍历一行,递归来来遍历列,然后一行一列确定皇后的唯一位置。
本题就不一样了,本题中棋盘的每一个位置都要放一个数字,并检查数字是否合法,解数独的树形结构要比N皇后更宽更深。
因为这个树形结构太大了,我抽取一部分,如图所示:
- 递归函数以及参数
递归函数的返回值需要是bool类型,为什么呢?
因为解数独找到一个符合的条件(就在树的叶子节点上)立刻就返回,相当于找从根节点到叶子节点一条唯一路径
- 递归单层搜索逻辑
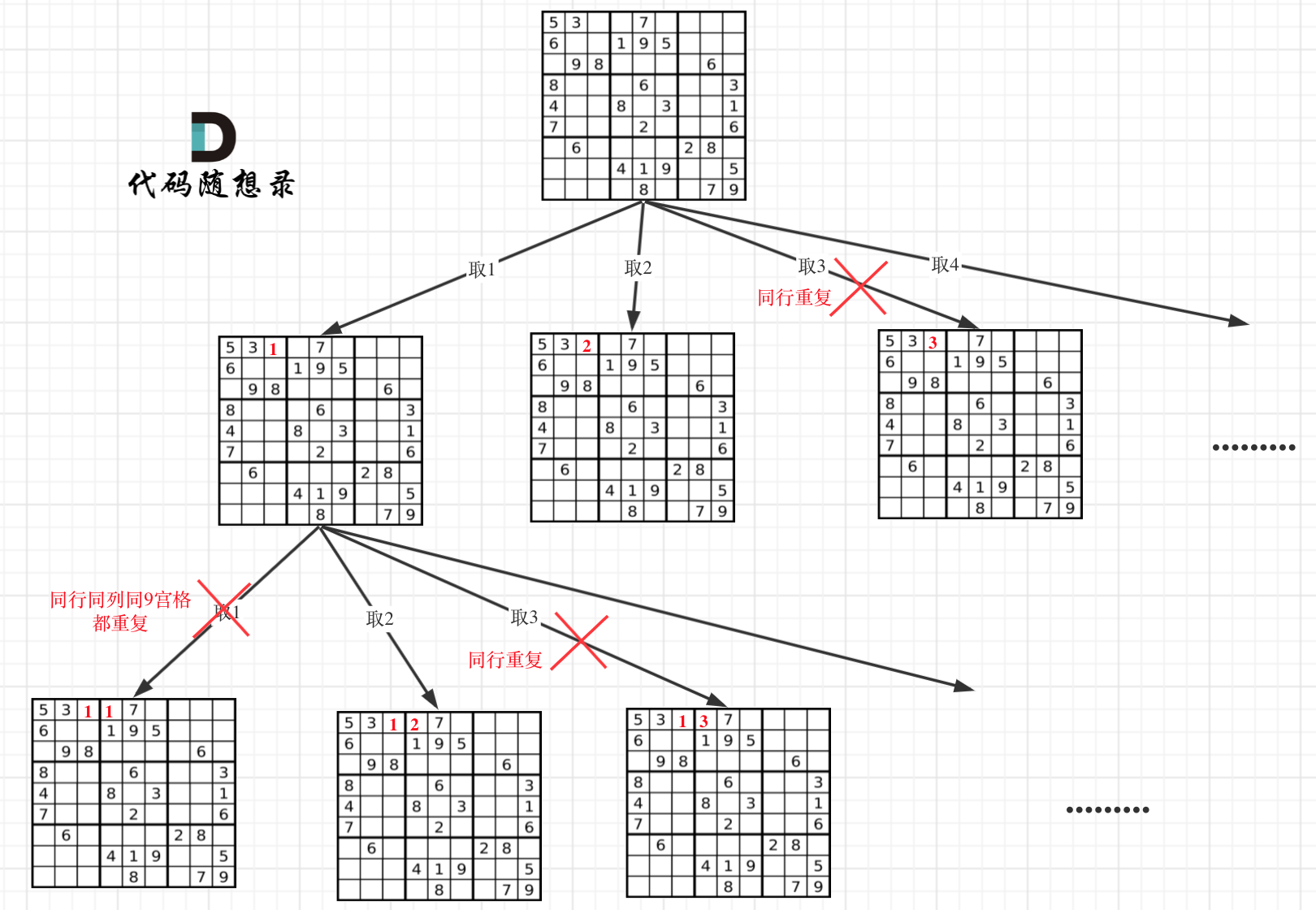
在树形图中可以看出我们需要的是一个二维的递归(也就是两个for循环嵌套着递归)
- 一个for循环遍历棋盘的行,一个for循环遍历棋盘的列,一行一列确定下来之后,递归遍历这个位置放9个数字的可能性!
实际上 可以不用两个for循环,而是我们自己来控制, 可以起到剪枝的效果
private boolean process(char[][] board, int i, int j) {if (i == 9) {return true;}int nexti = j != 8 ? i : i + 1;int nextj = j != 8 ? j + 1 : 0;if (board[i][j] != '.') { // 跳过原始数字return process(board, nexti, nextj);} else {for (char k = '1'; k <= '9'; k++) { // (i, j) 这个位置放k是否合适if (isValid(i, j, k, board)) {board[i][j] = k;if (process(board, nexti, nextj)) { //如果找到合适一组立刻返回return true;}board[i][j] = '.';}}// 9个数都试完了,都不行,返回falsereturn false;// 因为如果一行一列确定下来了,这里尝试了9个数都不行,说明这个棋盘找不到解决数独问题的解!// 那么会直接返回, 「这也就是为什么没有终止条件也不会永远填不满棋盘而无限递归下去!」}}
注意这里return false的地方,这里放return false 是有讲究的。
因为如果一行一列确定下来了,这里尝试了9个数都不行,说明这个棋盘找不到解决数独问题的解!
那么会直接返回, 这也就是为什么没有终止条件也不会永远填不满棋盘而无限递归下去!
判断棋盘是否合法有如下三个维度:
- 同行是否重复
- 同列是否重复
- 9宫格里是否重复
代码如下:
private boolean isValid(int row, int col, char val, char[][] board) {//同行for (int i = 0; i < 9; i++) {if (board[row][i] == val) {return false;}}//同列for (int i = 0; i < 9; i++) {if (board[i][col] == val) {return false;}}//九宫格int startRow = (row / 3) * 3;int startCol = (col / 3) * 3;for (int i = startRow; i < startRow + 3; i++) {for (int j = startCol; j < startCol + 3; j++) {if (board[i][j] == val) {return false;}}}return true;}
总代码
public void solveSudoku(char[][] board) {process(board, 0, 0);}private boolean process(char[][] board, int i, int j) {if (i == 9) {return true;}int nexti = j != 8 ? i : i + 1;int nextj = j != 8 ? j + 1 : 0;if (board[i][j] != '.') { // 跳过原始数字return process(board, nexti, nextj);} else {for (char k = '1'; k <= '9'; k++) { // (i, j) 这个位置放k是否合适if (isValid(i, j, k, board)) {board[i][j] = k;if (process(board, nexti, nextj)) { //如果找到合适一组立刻返回return true;}board[i][j] = '.';}}// 9个数都试完了,都不行,返回falsereturn false;// 因为如果一行一列确定下来了,这里尝试了9个数都不行,说明这个棋盘找不到解决数独问题的解!// 那么会直接返回, 「这也就是为什么没有终止条件也不会永远填不满棋盘而无限递归下去!」}}private boolean isValid(int row, int col, char val, char[][] board) {//同行for (int i = 0; i < 9; i++) {if (board[row][i] == val) {return false;}}//同列for (int i = 0; i < 9; i++) {if (board[i][col] == val) {return false;}}//九宫格int startRow = (row / 3) * 3;int startCol = (col / 3) * 3;for (int i = startRow; i < startRow + 3; i++) {for (int j = startCol; j < startCol + 3; j++) {if (board[i][j] == val) {return false;}}}return true;}
更加优化版本

若有收获,就点个赞吧
0 人点赞
