一、量化概念
1、定义
Float32 -> int8 / uint8
把高位宽(比如高精度浮点数,~
)表示的权值和激活值用更低位宽(比如低精度8比特定点数,0~255,-128~127)来近似表示。
低精度优点:
- 定点运算指令比float32运算指令,在单位时间内能处理更多数据;
例子:一条向量化指令是128bit,可存储4个float32数据,但量化后可存储16个8bit数据。 - 模型大小可以压缩,32bit权值量化为8bit理论上减少4倍存储空间;
2、对称量化&非对称量化
量化均属于线性量化。线性量化数学表达式:
)%0A#card=math&code=R%20%3D%20round%28S%20%2A%20%28Q-Z%29%29%0A)
其中表示float32数据,
表示量化偏移量,
示缩放因子,
#card=math&code=round%28%29)表示四舍五入函数,
表示量化后的整数。根据量化偏移量
是否为零可将线性量化分为对称、非对称量化。
对称量化:将浮点数量化至int8。


非对称量化:将浮点数量化至uint8。

%20%2B%20Z%5C%20%EF%BC%88%E5%9B%9B%E8%88%8D%E4%BA%94%E5%85%A5%EF%BC%89%5C%5C%0AxQ%20%3D%20clamp(0%2C%20N%7Blevels%7D-1%2C%20x%7Buint8%7D)%0A#card=math&code=scale%20%3D%20%5Cfrac%7Brmax-rmin%7D%7B255%7D%20%5C%5C%0AZ%20%3D%20-%5Cfrac%7Br%7Bmin%7D%7D%7Bscale%7D%20%5C%5C%0Ax%7Buint8%7D%20%3D%20round%28%5Cfrac%7Bx%7Bf32%7D%7D%7Bscale%7D%29%20%2B%20Z%5C%20%EF%BC%88%E5%9B%9B%E8%88%8D%E4%BA%94%E5%85%A5%EF%BC%89%5C%5C%0AxQ%20%3D%20clamp%280%2C%20N%7Blevels%7D-1%2C%20x_%7Buint8%7D%29%0A&height=141&width=724)
为何需要零点z(偏移):
1、因为原始浮点数中的0有实际意义。加上零点z ,浮点0量化之后映射到 0 ~ 255中间的一个数字,这样量化之后更精确;否则浮点0量化后映射到0。
2、让映射后区间整体偏移,让对应0。
3、为什么神经网络可以量化?
(一篇博客的理论分析:量化误差可接受。)

那么如果使用低精度的数据来表示网络参数以及中间值的话,虽然会存在误差,但这个误差某种程度上可认为是一种噪声。其低精度数据引进的差异是在网络的容忍度之内的,所以对结果不会产生太大影响。
根据是否需要训练划分,神经网络中的量化分为:
- 从头训练(scratch)
- 微调训练(Finetune)
- 后训练(post-training)
三者造成的最终区别是量化误差程度,主要介绍后训练量化。
后训练量化指对预训练后的浮点模型选择合适的量化操作和校准操作,以实现量化损失的最小化,该过程不需要训练。
4、信息论
4.1、信息量
假设我们听到了两件事,分别如下:
事件A:巴西队进入了2018世界杯决赛圈。
事件B:中国队进入了2018世界杯决赛圈。
请问哪个事件信息量大,为什么?
答案:B的信息量大。
原因:因为事件A发生的概率很大,事件B发生的概率很小,当越不可能的事件发生了,我们获取到的信息量就越大;越可能发生的事件发生了,我们获取到的信息量就越小。
结论:信息量应该和事件发生的概率有关。
假设是一个离散型随机变量,其取值集合为,其概率分布函为
#card=math&code=p%28x%29),则定义事件
的信息量为:
%3D-log(p(x%7B0%7D))%0A#card=math&code=I%28x%7B0%7D%29%3D-log%28p%28x_%7B0%7D%29%29%0A)
概率取值范围[0.0, 1.0],绘制图形如下:

该函数符合人类对信息的直觉。
4.2、熵
期望值
在概率论和统计学中,一个离散性随机变量的期望值(或数学期望,亦简称期望,物理学中称为期待值)是试验中每次可能的结果乘以其结果概率的总和。换句话说,期望值是该变量输出值的加权平均。

问题:拿出电脑按下开关,会有以下三种可能性,表中列出每一事件对应的概率及其信息熵。
| 序号 | 事件 | 概率p | 信息量I |
|---|---|---|---|
| A | 电脑正常开机 | 0.7 | -log(p(A))=0.36 |
| B | 电脑无法开机 | 0.2 | -log(p(B))=1.61 |
| C | 电脑爆炸了 | 0.1 | -log(p(C))=2.30 |
熵用来表示所有信息量的期望,即:
%3D-%5Csum%7Bi%3D1%7D%5E%7Bn%7Dp(x%7Bi%7D)log(p(x%7Bi%7D))%0A#card=math&code=H%28X%29%3D-%5Csum%7Bi%3D1%7D%5E%7Bn%7Dp%28x%7Bi%7D%29log%28p%28x%7Bi%7D%29%29%0A)
交叉熵
交叉熵可认为是对预测分布Q用真实分布P来进行编码时所需要的信息量大小。
%20%3D%20%5Csum%7Bx%7Dp(x)log%5Cfrac%7B1%7D%7Bq(x)%7D%20%0A%09%20%20%20%3D%20-%5Csum%20p(x)log(q(x))%0A%09%20%20%20%3D%20H(p)%2BD%7BKL%7D(p%7C%7Cq)%0A#card=math&code=H%28p%2Cq%29%20%3D%20%5Csum%7Bx%7Dp%28x%29log%5Cfrac%7B1%7D%7Bq%28x%29%7D%20%0A%09%20%20%20%3D%20-%5Csum%20p%28x%29log%28q%28x%29%29%0A%09%20%20%20%3D%20H%28p%29%2BD%7BKL%7D%28p%7C%7Cq%29%0A)
KL散度/相对熵
KL散度的定义是建立在熵(Entropy)的基础上的。若有两个随机变量P、Q,且其概率分布分别为𝑝(𝑥)、𝑞(𝑥)p(x)、q(x),则p相对q的相对熵为:
%3D%5Csum%7Bi%3D1%7D%5E%7Bn%7Dp(x)log%5Cfrac%7Bp(x)%7D%7Bq(x)%7D%0A#card=math&code=D%7BKL%7D%28p%7C%7Cq%29%3D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Dp%28x%29log%5Cfrac%7Bp%28x%29%7D%7Bq%28x%29%7D%0A)
相对熵是两个概率分布P和Q差别的非对称性的度量,使用基于Q的分布来编码服从P的分布的样本所需的额外的平均比特数,通常情况下P表示数据的真实分布,Q表示数据的近似分布。
量化过程中KL散度的意义:
用于衡量两个向量在分布上的差异,为向量和
统计直方图(两者bin数需要一致),然后进行归一化操作,使所有bin上的数值相加后和为1,也即得到概率分布图
#card=math&code=p%28a%29)和
#card=math&code=p%28b%29),那么向量
和
的KL散度的距离为可利用上面公式计算得到。
但是由于衡量分布差异的误差函数对数据分布比较敏感,故通常需要较大的数据量来保证收集的分布与真实分布足够接近。
二、TensorRT INT8后训练量化算法
神经网络的计算主要集中在卷积层层,量化也主要是针对这个层。可表示为:
表示激活,
表示权重。TensorRT 的量化思路就是用 INT8 代替 FP32 进行两个矩阵相乘计算。
1、DP4A-INT8数据格式
2、饱和量化、不饱和量化举例

使得很多数集中在INT8的某几个数字上,精度损失小。

3、为什么激活是饱和而权值是不饱和
- 权重分布较为均匀
- 激活值通常分布不均匀
4、激活统计分布
以下图为例,展示了不同网络结构的不同layer的激活值分布,有卷积层,有池化层,他们之间的分布很不一样,因此合理的量化方式应该适用于不同的激活值分布,并且减小信息损失。
- 横坐标激活值,纵坐标数量归一化表示
- 激活值是batch数据统计的并不是单一图片
- 红色虚线可认为激活的分布是相似的(重合度),但当激活较大时红色实线区域不再具有相似分布,分布不集中,较为混乱。
- 混乱分布占比较小。因此在量化时可考虑保留激活值的主要分布,即饱和映射,寻找合适的|T|,使得精度损失最小。
5、为什么实际量化过程中将权值、激活量化到[-127, 127]而不是int8的取值范围[-128, 127]?
- 8bit 取值区间是
,两个8bit相乘之后取值区间是
,累加两次就到了
,所以最多只能累加两次而且第二次也有溢出风险。比如相邻两次乘法结果都恰好是
会超了
(int16数据类型取值范围
)。
- 所以把量化之后的权值限制在
之间,那么一次乘法运算得到结果
%7D#card=math&code=%7B%28-2%5E%7B14%7D%2C%202%5E%7B14%7D%29%7D),永远会小于
,不存在溢出。
6、校准操作

假设最后使得KL散度最小的|T|值是第200组的中间值,那么就把原来第0-200组的数值线性映射到0-128之间,超出范围的直接映射到128。
首先为什么阈值遍历要从 128 开始呢?
因为 INT8 可以表示的整数个数(正值,0~127)有128个,小于这个数值则直接一一对应即可。
7、例程
// fp32 的统计直方图,8个binP=[1 0 2 3 5 3 1 7]// 假设只量化到两个 bins,即量化后的值只有 -1/0/+1 三种,4个一组合并Q=[1+0+2+3, 5+3+1+7] = [6, 16]// P 和 Q 现在没法做 KL 散度,所以要将 Q 扩展到和 P 一样的长度// P 中有 0 时,不算在内Q_expand = [6/3, 0, 6/3, 6/3, 16/4, 16/4, 16/4, 16/4] = [2 0 2 2 4 4 4 4]// P、Q归一化P /= sum(P)、Q /= sum(Q)// 计算 KL 散度D = KL(P||Q_expand)
这个扩展的操作,就像图像的上采样一样,将低精度的统计直方图(Q),上采样的高精度的统计直方图上去(Q_expand)。由于 Q 中一个 bin 对应 P 中的 4 个bin,因此在 Q 上采样的 Q_expand 的过程中,所有的数据要除以 4。但若分布P 中有 bin 值为 0 时,是不算在内的,所以 6 只需要除以 3。
8、INT8卷积计算
INT8卷积的计算过程:
- 输入Tensor均为INT8;
- 卷积计算过程采用DP4A过程,得到INT32输出;
- INT32转F32
- 偏置按输出量化因子量化后与F32输出相加
- F32激活
- FP32转INT8
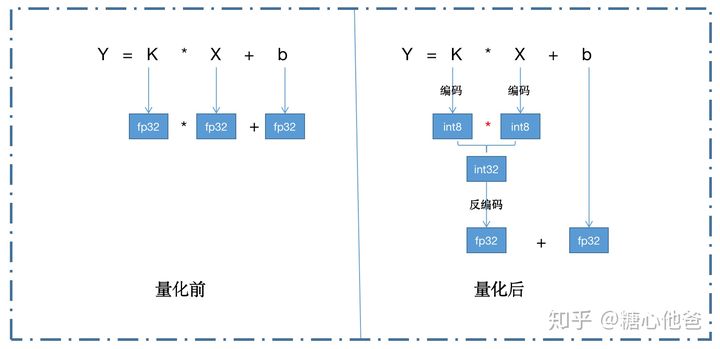
F32计算过程:
INT8计算过程:
%5C%5C%0A#card=math&code=%EF%BC%880.1%20%2A%2010%EF%BC%89%2A%20%EF%BC%880.2%20%2A%2010%EF%BC%89%3D%202%20%5Cneq%280.02%2A10%29%5C%5C%0A)
其中10分别表示输入、输出的量化因子。
为保证缩放程度匹配需要除以两输入量化因子再乘以输出量化因子:
%20%20(0.2%20%2010)%20%2F%20(10%20%2010)%20%2010%20%3D%20(0.02%20*%2010)%5C%5C%0A#card=math&code=%280.1%20%2A%2010%29%20%2A%20%280.2%20%2A%2010%29%20%2F%20%2810%20%2A%2010%29%20%2A%2010%20%3D%20%280.02%20%2A%2010%29%5C%5C%0A)
偏置量化因子(属于f32的计):
(0.210)%20%2B%20(0.1%20%20%3F)%3D(0.12100)%20%5C%5C%0A%3F%3D10*10%0A#card=math&code=0.1%2A0.2%20%2B%200.1%20%3D%200.12%20%5C%5C%0A%280.1%2A10%29%2A%280.2%2A10%29%20%2B%20%280.1%20%2A%20%3F%29%3D%280.12%2A100%29%20%5C%5C%0A%3F%3D10%2A10%0A)
三、MNN离线量化
1、使用方法
# 源码编译的量化工具产物、f32-MNN模型、量化模型、量化配置文件./quantized.out origin.mnn quan.mnn pretreatConfig.json# Python APImnnquant origin.mnn quan.mnn pretreatConfig.json# 量化配置文件{# 图片统一按照RGBA读取,然后转换到format格式# "RGB", "BGR", "RGBA", "GRAY""format":"RGB",# dst = (src - mean) * normal"mean":[127.5,127.5,127.5],"normal":[0.00784314,0.00784314,0.00784314],"width":224,"height":224,"path":"path/to/images/","used_image_num":500,"feature_quantize_method":"KL", # 100~1000张"weight_quantize_method":"MAX_ABS" # 权值的绝对最大值进行对称量化}
2、ops分析
以dpv3plus_pro_f32模型(pb)为例。
2.1 mnn模型转换
- 支持转换浮点型tensorflow(pb)、tflite模型,大部分op均支持,MNN op手册
- 支持转换uint8量化的tflite模型转换,但仅支持部分算子,遇到不支持算子即转换失败| TFLite op | MNN op | Inputs | Outputs | | —- | —- | —- | —- | | QuantizedConv2D | tfQuantizedConv2D | uint8(NC4HW4) | uint8 | | QuantizedReshape | QuantizedReshape | uint8(NHWC) | uint8 | | QuantizedMaxPool | QuantizedMaxPool | uint8(NHWC) | uint8 | | QuantizedAvgPool | QuantizedAvgPool | uint8(NHWC) | uint8 | | QuantizedSoftmax | QuantizedSoftmax | uint8(NHWC) | uint8 | | QuantizeDepthwise | QuantizedDepthwiseConv2D | uint8(NC4HW4) | uint8 | | QuantizedAdd | QuantizedAdd | uint8(NC4HW4)2 | uint8 | | QuantizedLogistic | QuantizedLogistic | uint8(NC4HW4) | uint8 | | QuantizedConcat | QuantizedConcat | uint8(NHWC)3 | uint8 |
- 若使用pb模型转换浮点型mnn,转换过程中会存在算子融合,比如Cov/ConvDepthwise+BN+ReLU融合为一个算子
- 若使用tflite模型转换为没有算子融合过程,因为pb模型转tflite时已经进行了算子融合
统计dpv3plus_pro_f32 ops:
| TF op | MNN op | Inputs | Outputs |
|---|---|---|---|
| Conv2D | Convolution | float32/int8(NC4HW4) | float32 |
| DepthwiseConv2dNative | ConvolutionDepthwise | float32/int8(NC4HW4) | float32 |
| ReLU6 | ReLU6 | float32(NHWC|NC4HW4) | float32 |
| FusedBatchNorm | Scale | float32(NC4HW4|NHWC) | float32 |
| Addv2(点加) | Eltwise | float32(NC4HW4|NHWC) | float32 |
| ResizeBilinear | Interp | float32(NC4HW4)、int32(optional) | float32 |
| MaxPool/AvgPool | Pooling | float32(NC4HW4|NHWC) | float32 |
| Concat/ConcatV2 | Concat | float32(NC4HW4|NHWC) | float32 |
| SpaceToBatchND | SpaceToBatchND | float32/int8(NC4HW4) | float32 |
| BatchToSpaceND | BatchToSpaceND | float32/int8(NC4HW4) | float32 |
| Mul… | Binary | float32|int32 | float32 |
| Softmax | Softmax | float32(NC4HW4|NHWC) | float32 |
注意⚠️:
(1)MNN模型中可能会有ConvertTensor算子,这是因为MNN不同算子的数据结构要求不一样,NHWC或者NC4HW4,可能需要类型转换。
(2)TF模型和TFLITE浮点模型具体的op名字可能会有差异,不再介绍。
(3)使用pb转的话此部分没有融合BN和ReLu,可能是因为这两个算子只能和Conv或者ConvDepthwise融合?但是tflite没有SpaceToBatc、BatchNDToBatchND、BN、ReLu6,已经融合了吗??


2.2 mnn模型量化
支持量化的算子
- Convolution
- ConvolutionDepthwise
- Eltwise
量化前后模型大小

输入输出
输入输出均为F32数据类型。
量化过程
- 将支持量化的op进行量化;
- 若遇到不支持量化的op,此op之前如果是q_op则需要进行反量化操作int8ToFloat,否则不需要;若此op下一个op是支持量化的op,则需要进行FloatToint8量化操作。看量化的模型结构中….
模型分析工具
- MNN2Basic.out:测试每个op的性能、执行时间、输出结果。
- timeProfile.out:Op 总耗时统计工具和模型运算量估计。
四、参考
[1]. caffe-int8-convert-tools.py
[2]. TensorRT INT8量化原理
[6]. 交叉熵博客
[7]. KL散度
[8]. 量化基础视频介绍b站
[9]. 后训练量化
[10]. int8量化
[11]. MNN量化工具分析
[12]. MNN量化介绍
[13]. alibaba/MNN
[14]. MNN官方文档
五、扩展
模型优化:QAT、剪枝、压缩。

若有收获,就点个赞吧
0 人点赞
