MNN是一个轻量级的深度神经网络推理引擎,在端侧加载深度神经网络模型进行推理预测。
一、整体特点
1、轻量性
- Android平台:so大小500KB左右,OpenCL库300KB左右,Vulkan库300KB左右。
2、通用性
- 支持
Tensorflow、Caffe、ONNX等主流模型文件格式,支持CNN、RNN、GAN等常用网络。 - 支持 149 个
TensorflowOp、47 个CaffeOp、74 个ONNXOp。 - 各计算设备支持的MNN Op数:CPU 110个,Metal 55个,OpenCL 29个,Vulkan 31个。
3、高性能
- 不依赖任何第三方计算库,依靠大量手写汇编实现核心运算,充分发挥ARM CPU的算力。
- Android上提供了
OpenCL、Vulkan、OpenGL三套方案,尽可能多地满足设备需求。 卷积、转置卷积算法高效稳定,对于任意形状的卷积均能高效运行。
4、易用性
有高效的图像处理模块,一般情况下,无需额外引入libyuv或opencv库处理图像。
- 支持回调机制,可以在网络运行中插入回调,提取数据或者控制运行走向。
- 支持只运行网络中的一部分,或者指定CPU和GPU间并行运行。
二、MNN架构设计
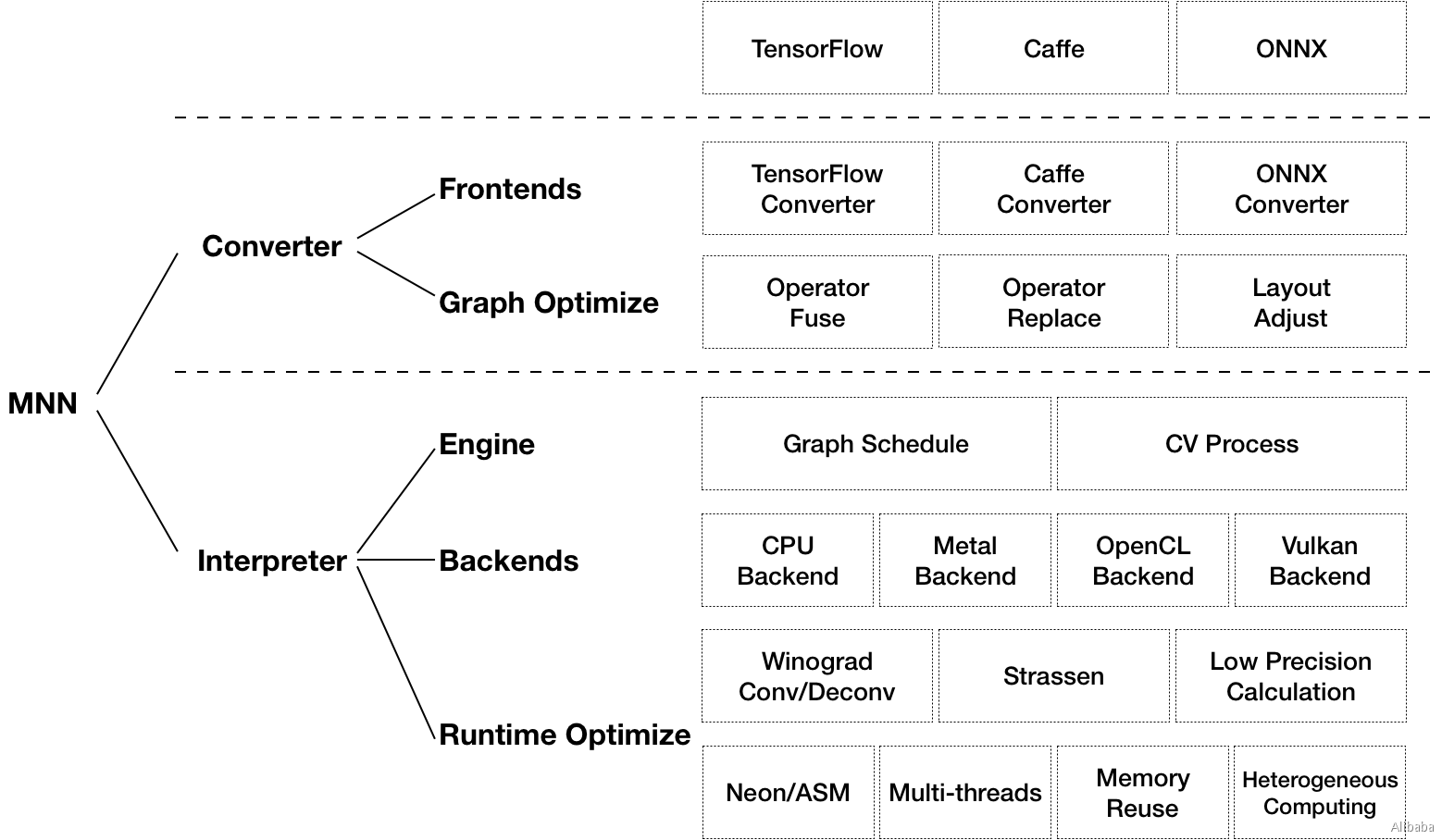
MNN可以分为Converter和Interpreter两部分。
1、Frontends
负责支持不同的训练框架。TensorFlow(Lite)、Caffe和ONNX(PyTorch/MXNet->ONNX)。
2、Graph Optimize
3、Engine
4、Backends
5、MNN优化方案举例
- 卷积和反卷积中应用Winograd算法
- 矩阵乘法中应用Strassen算法
- 低精度计算
- Neon优化
- 手写汇编
- 多线程优化
- 内存复用
- 异构计算
三、MNN框架工作流程

在端侧应用MNN,大致可以分为三个阶段。1、训练
在训练框架上,根据训练数据训练出模型的阶段。
MNN也提供了训练模型的能力,不完善,但主要用于端侧训练或模型调优。在数据量较大时,依然建议使用成熟的训练框架,如TensorFlow、PyTorch等。除了自行训练外,也可以直接利用开源的预训练模型。
FineTuneTrain、QuantTrain、DistillationTrain。2、转换
将其他训练框架模型转换为MNN模型的阶段。
MNN提供模型转换工具,支持Tensorflow(Lite)、Caffe和ONNX的模型转换。3、推理
在端侧加载MNN模型进行推理的阶段。端侧运行库平台包括:IOS、Android、Linux/macOS/Ubuntu、Windows。
四、推理框架
1、Android编译
环境要求
默认关闭,关闭时,不保留符号,开启优化。
- MNN_USE_THREAD_POOL
默认开启,使用 MNN 内部的无锁线程池实现多线程优化。关闭后,视MNN_OPENMP开关选择OpenMP或关闭多线程优化。
注:MNN 的无锁线程池最多允许两个实例同时使用,即最多供两个模型同时推理使用。参考代码 source/backend/cpu/ThreadPool.cpp 中 MNN_THREAD_POOL_MAX_TASKS 宏的定义。
- MNN_OPENMP
默认开启,在 MNN_USE_THREAD_POOL 关闭时生效,依赖OpenMP实现多线程优化。关闭后,禁用OpenMP。
- MNN_OPENCL
默认关闭,开启后,编译OpenCL部分,可以通过指定MNN_FORWARD_OPENCL利用GPU进行推理。
- MNN_OPENGL
默认关闭,开启后,编译OpenGL部分,可以通过指定MNN_FORWARD_OPENGL利用GPU进行推理。
需要android-21及以上,亦即脚本中指定 -DANDROID_NATIVE_API_LEVEL=android-21
- MNN_VULKAN
默认关闭,开启后,编译Vulkan部分,可以通过指定MNN_FORWARD_VULKAN利用GPU进行推理。
- MNN_ARM82
默认关闭,开启后,编译Arm8.2部分,用Arm8.2+扩展指令集实现半精度浮点计算(fp16)和int8(sdot)加速
编译用CMake参数总览:https://www.yuque.com/mnn/cn/cmake_opts
2、编译Android动态库步骤
Step1: cd /path/to/MNNStep2: ./schema/gene``rate.shStep3: cd project/androidStep4(armv7动态库): mkdir build_32 && cd build_32 && ../build_32.shStep5(armv8动态库): mkdir build_64 && cd build_64 && ../build_64.sh
3、编译Android静态库步骤
Step1: cd /path/to/MNNStep2: ./schema/gene``rate.shStep3: cd project/androidStep4(armv7动态库): mkdir build_32 && cd build_32 && ../build_32.sh -DMNN_SEP_BUILD=false -DMNN_BUILD_SHARED_LIBS=falseStep5(armv8动态库): mkdir build_64 && cd build_64 && ../build_64.sh -DMNN_SEP_BUILD=false -DMNN_BUILD_SHARED_LIBS=false
4、执行推理
使用MNN推理时,有两个层级的概念,分别是解释器Interpreter和会话Session。Interpreter是模型数据的持有者;Session通过Interpreter创建,是推理数据的持有者。
多个推理可以共用同一个模型,即,多个Session可以共用一个Interpreter。
// UNNEngine MNN Wrapper// Step1: 通过内存数据,创建Interpreter//model = std::unique_ptr<MNN::Interpreter>(MNN::Interpreter::createFromBuffer((const char*)info->ld.model_buffer, info->ld.model_size));// Step1: 通过磁盘文件,创建Interpretermodel = std::unique_ptr<MNN::Interpreter>(MNN::Interpreter::createFromFile(info->ld.model_name));// 注意:函数返回的Interpreter实例是通过new创建的,不再需要时通过delete释放,以免造成内存泄漏。// Step2: 调度配置MNN::ScheduleConfig config;// Set ForwardType,当主选后端不支持模型中的算子时,默认为CPUconfig.type = (MNNForwardType) info->param.forword_type;// Set threads: 设置并发数if( info->param.number_of_threads > 0)config.numThread = info->param.number_of_threads;// Step3: Create Session,会根据模型结构自动识别session = model->createSession(config);// Step4: 获取输入Tensor{auto tensors = model->getSessionInputAll(session);for (auto iter = tensors.cbegin(); iter != tensors.end(); iter++){inputs.push_back(iter->first);}}// Step4: 获取输出Tensor{auto tensors = model->getSessionOutputAll(session);for (auto iter = tensors.cbegin(); iter != tensors.end(); iter++){outputs.push_back(iter->first);}}// Step5: 填充输入数据,返回Tensor对象inputfor (int id = 0; id < inOut->inputs_count; id++) {// 根据输入Tensor节点名称获取到指定Tensorauto t = model->getSessionInput(session, inputs[id].c_str());// 获取输入Tensor Shape信息auto t_shape = t->shape();// NCHW or NHWCprintf("Inputs t_shape: (%d,%d,%d,%d ).\n",t_shape[0],t_shape[1],t_shape[2],t_shape[3]);MNN::Tensor _in(t, t->getDimensionType(), false);_in.buffer().host = (uint8_t *)inOut->inputs[id].data;// 拷贝数据至输入Tensort->copyFromHostTensor(&_in);}// Executemodel->runSession(static_cast< MNN::Session *>(session));// Step6: GetOutputLOGD("Get Network Outputs.\n");for (int id = 0; id < inOut->outputs_count; id++) {auto t = model->getSessionOutput(session, outputs[id].c_str());auto t_shape = t->shape();// NCHW or NHWCprintf("Inputs t_shape: (%d,%d,%d,%d ).\n",t_shape[0],t_shape[1],t_shape[2],t_shape[3]);MNN::Tensor _out(t, t->getDimensionType(), false);_out.buffer().host = (uint8_t *)inOut->outputs[id].data;//拷贝输出数据t->copyToHostTensor(&_out);}
五、训练框架
1、编译
编译训练框架之前,先按照指示编译相应平台的推理框架。cmake .. -DMNN_BUILD_TRAIN=ON -MNN_BUILD_TRAIN_MINI=OFF -MNN_USE_OPENCV=OFF
编译产物
- MNNTrain:训练框架库
- runTrainDemo.out:运行训练框架demo的入口程序
2、获取可训练模型
1、其他框架
如TensorFlow,Pytorch训练得到的模型转成MNN可训练模型。2、从零搭建
使用MNN从零开始搭建一个模型,并使用MNN进行训练,这可以省去模型转换的步骤,并且也可以十分容易地转换为训练量化模型。3、应用场景
3.1 MNN Finetune
参考例程./pymnn/examples/MNNTrain/mobilenet_finetune/深度模型可以看做一种特征提取器,例如卷积神经网络(CNN)可以看做一种视觉特征提取器。但是这种特征提取器需要进行广泛的训练才能避免过拟合数据集,取得较好的泛化性能。如果我们直接搭建一个模型然后在我们自己的小数据集上进行训练的话,很容易过拟合。这时候我们就可以用在一些相似任务的大型数据集上训练得到的模型,在我们自己的小数据集上进行Finetune,即可省去大量训练时间,且获得较好的性能表现。
from __future__ import print_functionimport timeimport argparseimport numpy as npfrom finetune_dataset_copy import FinetuneDatasetimport MNNnn = MNN.nnF = MNN.exprdef load_feature_extractor(model_file):var_dict = F.load_as_dict(model_file)# input_var = var_dict['input']# output_var = var_dict['MobilenetV2/Logits/AvgPool']input_var = var_dict['image']output_var = var_dict['dpv3plus_dsp/IBNNoExpansion_1/SeparableConv2d/Relu6']# 'False' means the parameters int this module will not update during trainingfeature_extractor = nn.load_module([input_var], [output_var], False) # Truefeature_extractor = nn.FixModule(feature_extractor) # fix feature extractorreturn feature_extractorclass Net(nn.Module):def __init__(self, feature_extractor, num_classes):super(Net, self).__init__()self.feature_extractor = feature_extractor# use conv to implement fcself.fc = nn.conv(64, num_classes, [1, 1])def forward(self, x):x = self.feature_extractor(x)x = self.fc(x)x = F.resize(x, 2, 2)x = F.convert(x, F.NCHW)x = F.softmax(x)return xdef train_func(net, train_dataloader, opt, num_classes):net.train(True)train_dataloader.reset()t0 = time.time()for i in range(train_dataloader.iter_number):example = train_dataloader.next()input_data = example[0]output_target = example[1]data = input_data[0] # which input, model may have more than one inputslabel = output_target[0] # also, model may have more than one outputs# need to convert data to NC4HW4, because the input format of feature extractor is NC4HW4predict = net.forward(F.convert(data, F.NC4HW4))target = F.one_hot(F.cast(label, F.int), num_classes, 1, 0)predict = F.reshape(predict, (320*320, num_classes))target = F.reshape(target, (320*320, num_classes))loss = nn.loss.cross_entropy(predict, target)opt.step(loss)if i % 10 == 0:print("train loss: ", loss.read())t1 = time.time()cost = t1 - t0print("Epoch cost: %.3f s." % cost)F.save(net.parameters, "temp.mobilenet_finetune.snapshot")feature_extractor = load_feature_extractor(model_file)net = Net(feature_extractor, num_classes)opt = MNN.optim.SGD(1e-3, 0.9, 0.00004)opt.append(net.parameters)for epoch in range(10):train_func(net, train_dataloader, opt, num_classes) // 自定义class,封装成MNN.data.DataLoader()# save modelfile_name = '%d.dpv3plus_finetune.mnn' % epochnet.train(False)predict = net.forward(F.placeholder([1, 3, 320, 320], F.NC4HW4))print("Save to " + file_name)F.save([predict], file_name)test_func(net, test_dataloader)
3.2 MNN训练量化
与离线量化不同,训练量化需要在训练中模拟量化操作的影响,并通过训练使得模型学习并适应量化操作所带来的误差,从而提高量化的精度。
因此训练量化也称为Quantization-aware Training(QAT),意指训练中已经意识到此模型将会转换成量化模型。


Int8量化训练
• feature->int8,weight/bias->int8,output->f32/int8 取决与卷积模块的后面一个op
• 两种FakeQuant区别是:特征由于其范围是随输入动态变化的,因此对每一次Forward计算的scale进行累积更新;权值不需要。
• 支持分通道/不分通道的scale统计方法。建议weight->分通道。
Test阶段
将BatchNorm合进权值,使用训练过程得到的特征scale和此时权值的scale(每次重新计算得到)对特征和权值进行量化,并真实调用MNN中的 _FloatToInt8 和 _Int8ToFloat 来进行推理,以保证测试得到的结果和最后转换得到的全int8推理模型的结果一致。
Save
自动保存test阶段的模型,并去掉一些冗余的算子,所以直接保存出来即是全int8推理模型。./pymnn/examples/MNNTrain/quantization_aware_training/
from __future__ import print_functionimport timeimport argparseimport numpy as npimport MNNfrom imagenet_dataset import ImagenetDatasetnn = MNN.nnF = MNN.expr// float or int8,在模型转换过程中建议使用 MNNConverter 的 --forTraining 选项,保留BatchNorm,Dropout等训练过程中会用到的算子。net = nn.load_module_from_file(model_file, for_training=True)# turn net to quant-aware-training modulenn.compress.train_quant(net, quant_bits=8)opt = MNN.optim.SGD(1e-5, 0.9, 0.00004) // 保证超参数一致,学习率低opt.append(net.parameters)for epoch in range(5):train_func(net, train_dataloader, opt, num_classes)# save modelfile_name = '%d.mobilenet.mnn' % epochnet.train(False)predict = net.forward(F.placeholder([1, 3, 320, 320], F.NC4HW4))print("Save to " + file_name)F.save([predict], file_name)
3.3 蒸馏训练
将一个模型所学到的知识蒸馏转移到另外一个模型上,因此前一个模型常被称为教师模型,后面一个模型常被称为学生模型。如果学生模型比教师模型小,那么蒸馏也成为一种模型压缩方法。
MobilenetV2的蒸馏训练量化
/tools/train/source/demo/``distillTrainQuant.cpp- 取出输入到模型Softmax节点的logits
- 加上温度参数
- 计算蒸馏loss进行训练
六、转换工具
1、转换工具Linux/Windows 编译
1.1 基础依赖
- cmake(3.10 以上)
- protobuf (3.0 以上)
- 指protobuf库以及protobuf编译器。版本号使用
protoc --version打印出来。 - 在某些Linux发行版上这两个包是分开发布的,需要手动安装
- Ubuntu需要分别安装
libprotobuf-dev以及protobuf-compiler两个包
- 指protobuf库以及protobuf编译器。版本号使用
C++编译器
- GCC推荐版本4.9以上,同样以Ubuntu为例,需要分别安装
gcc和g++1.2 编译步骤
cd MNN/./schema/generate.shmkdir buildcd buildcmake .. -DMNN_BUILD_CONVERTER=true && make -j4
2、模型转换
2.1 参数说明
```bash Usage: MNNConvert [OPTION…]
-h, —help Convert Other Model Format To MNN Model
-v, —version 显示当前转换器版本
-f, —framework arg 需要进行转换的模型类型, ex: [TF,CAFFE,ONNX,TFLITE,MNN]
--modelFile arg 需要进行转换的模型文件名, ex: *.pb,*caffemodel--prototxt arg caffe模型结构描述文件, ex: *.prototxt--MNNModel arg 转换之后保存的MNN模型文件名, ex: *.mnn--fp16 将float32参数保存为float16,模型将减小一半,精度基本无损--benchmarkModel 不保存模型中conv/matmul/BN等层的参数,减小转换的模型文件大小,运行时随机初始化参数,仅用于benchmark测试--bizCode arg MNN模型Flag, ex: MNN--debug 使用debug模型显示更多转换信息--forTraining 保存训练相关算子,如BN/Dropout,default: false--weightQuantBits arg arg=2~8,此功能仅对conv/matmul/LSTM的float32权值进行量化,仅优化模型大小,加载模型后会解码为float32,量化位宽可选2~8,运行速度和float32模型一致。8bit时精度基本无损,模型大小减小4倍default: 0,即不进行权值量化--compressionParamsFile arg使用MNN模型压缩工具箱生成的模型压缩信息文件--saveStaticModel 固定输入形状,保存静态模型, default: false--inputConfigFile arg 保存静态模型所需要的配置文件, ex: ~/config.txt
- GCC推荐版本4.9以上,同样以Ubuntu为例,需要分别安装
<a name="QHbTi"></a>### 2.1 转换命令```bash./MNNConvert -f TF --modelFile XXX.pb --MNNModel XXX.mnn --bizCode biz./MNNConvert -f TFLITE --modelFile XXX.tflite --MNNModel XXX.mnn --bizCode biz./MNNConvert -f ONNX --modelFile XXX.onnx --MNNModel XXX.mnn --bizCode biz
七、MNN模型分析工具
1、MNN、ONNX模型对比工具
Step1: pip install onnxruntimeStep2: cd build/Step3: python fastTestOnnx.py xxxx.onnx
2、预编译的MNN python工具
mnn、mnnops、mnnquant、mnnvisual。<br />`pip install mnn==1.1.0`<br />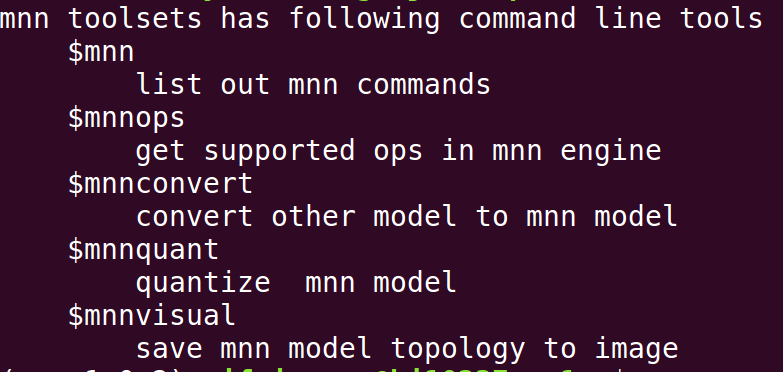
3、MNN模型打印工具 MNNDump2Json
将MNN模型bin文件 dump 成可读的类json格式文件,以方便对比原始模型参数。
4、可视化工具 Netron
5、测试工具
5.1 MNNV2Basic.out
测试性能、输出结果,可检查与输入模型的预期结果是否匹配。
注意:
- 对非CPU后端来说,只有总耗时是准确的,单个op耗时和op耗时占比都是不准确的
- 仅支持单一输入、单一输出 ```bash ./MNNV2Basic.out temp.mnn 10 0 0 4 1x3x224x224
-第一个参数指定 待测试模型的二进制文件。 -第二个参数指定 性能测试的循环次数,10就表示循环推理10次。 -第三个参数指定 是否输出推理中间结果,0为不输出; 1为只输出每个算子的输出结果({opname}.txt); 2为输出每个算子的输入(Input{op_name}.txt)和输出({op_name}.txt)结果; 默认输出当前目录的output目录下(使用工具之前要自己建好output目录)。 -第四个参数指定 执行推理的计算设备,有效值为 0(CPU)、1(Metal)、3(OpenCL)、6(OpenGL),7(Vulkan) -第五个参数为线程数,默认为4,仅对CPU有效 -第六个参数指定 输入tensor的大小,一般不需要指定。
<a name="umpeW"></a>### 5.2 checkFile.out检查两个tensor文本文件是否一致。```bash./checkFile.out XXX.txt YYY.txt 0.1-0.1 表示绝对阈值,不输入则为 0.0001-比对值超过绝对阈值时,会直接输出到控制台
5.3 checkDir.out
比对两个文件夹下同名文件是否一致。
./checkDir.out output android_output 1-1 表示绝对阈值,不输入则为 0.0001-比对值超过绝对阈值时,会直接输出到控制台
5.4 timeProfile.out
Op 总耗时统计工具和模型运算量估计。
注意:
不要用这个工具测非CPU后端的性能,需要的话请用MNNV2Basic工具。
```bash
./timeProfile.out temp.mnn 10 0 1x3x448x448
第一个参数 指定模型文件名 第二个参数 指定运行次数,默认 100 第三个参数 指定 执行推理的计算设备,有效值为 0(浮点 CPU)、1(Metal)、3(浮点OpenCL)、6(OpenGL),7(Vulkan)。(当执行推理的计算设备不为 CPU 时,Op 平均耗时和耗时占比可能不准) 第四个参数 指定输入大小,一般可不设
Op类型 评价耗时 耗时占比 Node Type Avg(ms) % Called times Softmax 0.018100 0.022775 1.000000 Pooling 0.080800 0.101671 1.000000 ConvolutionDepthwise 14.968399 18.834826 13.000000 Convolution 64.404617 81.040726 15.000000 total time : 79.471924 ms, total mflops : 2271.889404
5.5 backendTest.out对比指定计算设备和CPU执行推理的结果。```bash./backendTest.out temp.mnn 3 0.15 1-该工具默认读取当前目录下的 input_0.txt 作为输入-第一个参数:模型文件-第二个参数:执行推理的计算设备-第三个参数:误差容忍率-第四个参数:精度,0 表示 normal ,1 为high,2 为low
6、Benchmark工具
6.1 Linux/macOS/Ubuntu, 在MNN根目录下编译
mkdir buildcd buildcmake .. -DMNN_BUILD_BENCHMARK=true && make -j4
6.2 Android 平台编译armv7/armv8
./benchmark.out models_folder loop_count forwardtype
./benchmark.out models_folder loop_count forwardtype-models_folder: benchmark models文件夹,benchmark models在此。-loop_count: 可选,默认是10-forwardtype: 可选,默认是0,即CPU,forwardtype有0->CPU,1->Metal,3->OpenCL,6->OpenGL,7->Vulkan
7、离线量化工具
7.1 离线量化编译
mkdir buildcd buildcmake .. -DMNN_BUILD_QUANTOOLS=on
./quantized.out origin.mnn quan.mnn pretreatConfig.json-第一个参数为原始模型文件路径,即待量化的浮点模-第二个参数为目标模型文件路径,即量化后的模型-第三个参数为预处理的配置项,参考pretreatConfig.json{"format":"RGB", # 图片统一按RGBA读取,然后转换到format指定格式,"RGB", "BGR", "RGBA", "GRAY"# dst = (src - mean) * normal"mean":[127.5,127.5,127.5],"normal":[0.00784314,0.00784314,0.00784314],# 模型输入的宽高"width":224,"height":224,# 存放校正特征量化系数的图片目录"path":"path/to/images/",# 用于指定使用上述目录下多少张图片进行校正,默认使用path下全部图片"used_image_num":500,# 指定计算特征量化系数的方法"feature_quantize_method":"KL",# 指定权值量化方法"weight_quantize_method":"MAX_ABS","feature_clamp_value":127,"weight_clamp_value":127,"skip_quant_op_names":["skip_quant_op_name1", "skip_quant_op_name2"],"debug":false}"KL": 使用KL散度进行特征量化系数的校正,一般需要100 ~ 1000张图片(若发现精度损失严重,可以适当增减样本数量,特别是检测/对齐等回归任务模型,样本建议适当减少)"ADMM": 使用ADMM(Alternating Direction Method of Multipliers)方法进行特征量化系数的校正,一般需要一个batch的数据"MAX_ABS": 使用权值的绝对值的最大值进行对称量化"ADMM": 使用ADMM方法进行权值量化x输入输出:F32
7.2 训练量化改离线量化
原因
离线量化精度不够、MNN训练框架训练不起来模型。
具体办法
去掉训练量化中solver.step(loss)这一步骤,直接在train阶段灌预处理数据来finetune量化scale参数,test阶段保持的模型就是量化模型。
8、模型在线量化工具convertmodel


若有收获,就点个赞吧
0 人点赞
