1 NN
1.1 概念
神经网络就是一个”万能的模型+误差修正函数“,每次根据训练得到的结果与预想结果进行误差分析,进而修改权值和阈值,一步一步得到能输出和预想结果一致的模型。<br /> 举一个例子:比如某厂商生产一种产品,投放到市场之后得到了消费者的反馈,根据消费者的反馈,厂商对产品进一步升级,优化,从而生产出让消费者更满意的产品。这就是神经网络的核心。
1.2 神经网络的本质
机器学习可以看做是数理统计的一个应用,在数理统计中一个常见的任务就是拟合,也就是给定一些样本点,用合适的曲线揭示这些样本点随着自变量的变化关系。<br /> 深度学习同样也是为了这个目的,只不过此时,样本点不再限定为(x, y)点对,而可以是由向量、矩阵等等组成的广义点对(X,Y)。而此时,(X,Y)之间的关系也变得十分复杂,不太可能用一个简单函数表示。然而,人们发现可以用多层神经网络来表示这样的关系,而多层神经网络的本质就是一个多层复合的函数。<br /> 说白了,深度学习就是弄出来一个超级大的函数,这个函数含有海量的权值参数、偏置参数,再通过一系列复合的复杂运算,得到结果。<br /> 时间万物,可以抽象成数学模型,用数字来表示,深度学习网络就是对这些数字进行各种数学运算,计算得到人们期望的结果。
1.3 反向传播
前向传递输入信号直至输出产生误差,反向传播误差信息更新权重矩阵。<br /> 其根本就是求偏导以及高数中的链式法则。<br /><br />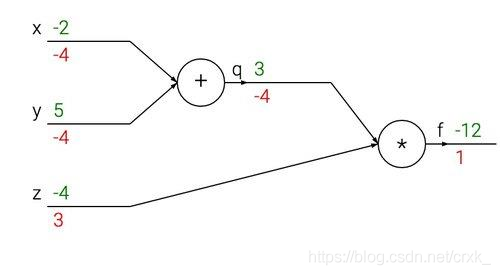
1.4 梯度下降与反向传播
梯度下降 是 找损失函数极小值的一种方法,<br /> 反向传播 是 求解梯度的一种方法。
1.4.1 关于损失函数:
在训练阶段,深度神经网络经过前向传播之后,得到的预测值与先前给出真实值之间存在差距。我们可以使用损失函数来体现这种差距。损失函数的作用可以理解为:当前向传播得到的预测值与真实值接近时,取较小值。反之取值增大。并且,损失函数应是以参数(w 权重, b 偏置)为自变量的函数。
1.4.2 训练神经网络,“训练”的含义:
它是指通过输入大量训练数据,使得神经网络中的各参数(w 权重, b 偏置)不断调整“学习”到一个合适的值。使得损失函数最小。
1.4.3 如何训练?
采用 梯度下降 的方式,一点点地调整参数,找损失函数的极小值(最小值)
1.4.4 为啥用梯度下降?
由浅入深,我们最容易想到的调整参数(权重和偏置)是穷举。即取遍参数的所有可能取值,比较在不同取值情况下得到的损失函数的值,即可得到使损失函数取值最小时的参数值。然而这种方法显然是不可取的。因为在深度神经网络中,参数的数量是一个可怕的数字,动辄上万,十几万。并且,其取值有时是十分灵活的,甚至精确到小数点后若干位。若使用穷举法,将会造成一个几乎不可能实现的计算量。<br /> 第二个想到的方法就是微分求导。通过将损失函数进行全微分,取全微分方程为零或较小的点,即可得到理想参数。(补充:损失函数取下凸函数,才能使得此方法可行。现实中选取的各种损失函数大多也正是如此。)可面对神经网络中庞大的参数总量,纯数学方法几乎是不可能直接得到微分零点的。<br /> 因此我们使用了梯度下降法。既然无法直接获得该点,那么我们就想要一步一步逼近该点。一个常见的形象理解是,爬山时一步一步朝着坡度最陡的山坡往下,即可到达山谷最底部。(至于为何不能闪现到谷底,原因是参数数量庞大,表达式复杂,无法直接计算)我们都知道,向量场的梯度指向的方向是其函数值上升最快的方向,也即其反方向是下降最快的方向。计算梯度的方式就是求偏导。<br /> 这里需要引入一个步长的概念。个人理解是:此梯度对参数当前一轮学习的影响程度。步长越大,此梯度影响越大。若以平面直角坐标系中的函数举例,若初始参数x=10,步长为1 。那么参数需要调整十次才能到达谷底。若步长为5,则只需2次。若为步长为11,则永远无法到达真正的谷底。<br />[参考文献](https://blog.csdn.net/crxk_/article/details/97137789)
2 CNN
3 GNN
来自哔哩哔哩的零基础多图详解图神经网络(GNN/GCN)【论文精度】
3.1 distill博客中博客的四个部分
①什么数据可以表示成一张图
②图跟别的数据有什么不一样的地方
③构建一个GNN,看一下各个模块是什么样子
④提供一个GNN的playground(游乐场、操场)
3.2 博客的目录
- 前言
- 什么是图
- 图神经网络
- 实验
- 相关技术
- 评论
3.2 GNN的应用
可以应用于药物的发展 、物理的模拟、虚假新闻的检测、车流量的预测和推荐系统等。

若有收获,就点个赞吧
0 人点赞
