YoloV1
论文地址
https://arxiv.org/pdf/1506.02640.pdf
论文思想
YOLO把目标检测看作一个回归问题,直接用一个网络进行分类和框回归。
具体做法是:将image划分为SS个网格,每个网格预测B个bbox的位置 、置信度(confidence为交并比)、类别概率。输出维度为SS(B5+C),C为类别数。无论网格中包含多少个boxes,每个网格只预测一组类概率。测试时,将条件类概率和预测框的置信度乘起来,表示每个box包含某类物体的置信度,这个分数可以将box中的类别可能性和预测精确度同时表示出来。
、置信度(confidence为交并比)、类别概率。输出维度为SS(B5+C),C为类别数。无论网格中包含多少个boxes,每个网格只预测一组类概率。测试时,将条件类概率和预测框的置信度乘起来,表示每个box包含某类物体的置信度,这个分数可以将box中的类别可能性和预测精确度同时表示出来。
网络架构

网络模型受到GoogleNet的激发设计的,但是没有使用inception模块。而是交替使用1x1和3x3卷积层。卷积层负责提取图像特征,全连接层负责类别预测和框参数回归。整个网络共有24个卷积层和2个全连接层。再Fast Yolo中是9个卷积层,没个卷积层使用个数更少的卷积器。其他参数与Yolo一样。
网络架构源码
net = tf.pad(images, np.array([[0, 0], [3, 3], [3, 3], [0, 0]]),name='pad_1')net = slim.conv2d(net, 64, 7, 2, padding='VALID', scope='conv_2')net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_3')net = slim.conv2d(net, 192, 3, scope='conv_4')net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_5')net = slim.conv2d(net, 128, 1, scope='conv_6')net = slim.conv2d(net, 256, 3, scope='conv_7')net = slim.conv2d(net, 256, 1, scope='conv_8')net = slim.conv2d(net, 512, 3, scope='conv_9')net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_10')net = slim.conv2d(net, 256, 1, scope='conv_11')net = slim.conv2d(net, 512, 3, scope='conv_12')net = slim.conv2d(net, 256, 1, scope='conv_13')net = slim.conv2d(net, 512, 3, scope='conv_14')net = slim.conv2d(net, 256, 1, scope='conv_15')net = slim.conv2d(net, 512, 3, scope='conv_16')net = slim.conv2d(net, 256, 1, scope='conv_17')net = slim.conv2d(net, 512, 3, scope='conv_18')net = slim.conv2d(net, 512, 1, scope='conv_19')net = slim.conv2d(net, 1024, 3, scope='conv_20')net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_21')net = slim.conv2d(net, 512, 1, scope='conv_22')net = slim.conv2d(net, 1024, 3, scope='conv_23')net = slim.conv2d(net, 512, 1, scope='conv_24')net = slim.conv2d(net, 1024, 3, scope='conv_25')net = slim.conv2d(net, 1024, 3, scope='conv_26')net = tf.pad(net, np.array([[0, 0], [1, 1], [1, 1], [0, 0]]),name='pad_27')net = slim.conv2d(net, 1024, 3, 2, padding='VALID', scope='conv_28')net = slim.conv2d(net, 1024, 3, scope='conv_29')net = slim.conv2d(net, 1024, 3, scope='conv_30')net = tf.transpose(net, [0, 3, 1, 2], name='trans_31')net = slim.flatten(net, scope='flat_32')net = slim.fully_connected(net, 512, scope='fc_33')net = slim.fully_connected(net, 4096, scope='fc_34')net = slim.dropout(net, keep_prob=keep_prob, is_training=is_training,scope='dropout_35')net = slim.fully_connected(net, num_outputs, activation_fn=None, scope='fc_36')
目标损失函数
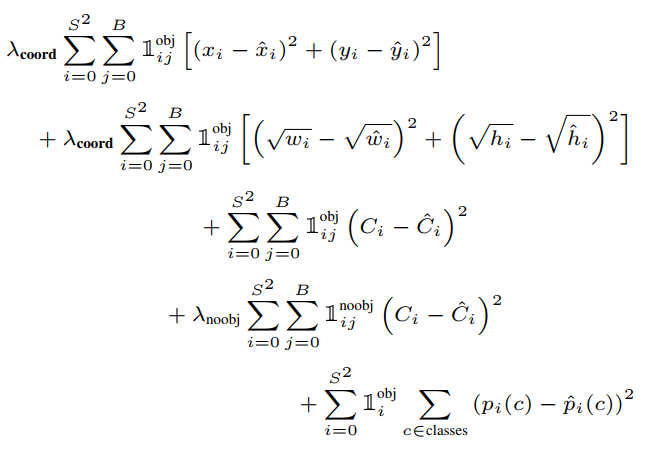
对输出采用平方和进行优化,因为它更容易操作,但是:
(1)它认为定位误差和分类误差的权重相等,而每个图像中许多网格不包含任何物体,这会使得这些网格的置信度为0从而压倒那些包含物体的网格的梯度,导致模型不稳定。为了解决这个问题,我们提高框回归预测的损失,降低那些不含物体的boxes的损失,使用2个参数调节,其中  ,
, 。
。
(2)它认为大boxes和小boxes的loss也有同样的权重,在我们的网格设计中,很明显大boxes的loss比小boxes的loss重要的多。为了解决这个问题,预测边界框的时候,不是直接使用宽/高,而是使用宽/高的平方根。
每个网格可以预测到多个bounding boxes,训练时指定一个和真值有最高IoU的box,来负责预测这个目标,这会使每个predictor在预测特定大小、长宽比、对象类别方面做的更好。
损失函数定义为(预测框中心位置x,y损失 + 预测框宽高w,h损失 + 置信度confidence损失 + 分类损失):
并不是网络的所有输出都要计算loss:
- 有物体中心落入的cell,需要计算分类损失,
- 两个predictor都要计算置信度损失,
- 预测的bounding box与groud truth IOU较大的那个predictor需要计算xywh损失。
- 最关键的部分,没有物体中心落入的cell,只需要计算置信度(confidence)损失。

损失函数计算源码
# class_lossclass_delta = response * (predict_classes - classes)class_loss = tf.reduce_mean(tf.reduce_sum(tf.square(class_delta), axis=[1, 2, 3]),name='class_loss') * self.class_scale# object_lossobject_delta = object_mask * (predict_scales - iou_predict_truth)object_loss = tf.reduce_mean(tf.reduce_sum(tf.square(object_delta), axis=[1, 2, 3]),name='object_loss') * self.object_scale# noobject_lossnoobject_delta = noobject_mask * predict_scalesnoobject_loss = tf.reduce_mean(tf.reduce_sum(tf.square(noobject_delta), axis=[1, 2, 3]),name='noobject_loss') * self.noobject_scale# coord_losscoord_mask = tf.expand_dims(object_mask, 4)boxes_delta = coord_mask * (predict_boxes - boxes_tran)coord_loss = tf.reduce_mean(tf.reduce_sum(tf.square(boxes_delta), axis=[1, 2, 3, 4]),name='coord_loss') * self.coord_scale
超参数设定
batch_size = 64,momentum = 0.9,weight decay = 0.0005
first epochs,learning rate从0.001慢慢增加到0.01,如果从高的学习率开始,可能会由于梯度不稳定,导致模型diverges。再用0.01的learning rate训练75个迭代,再用0.001训练30个迭代,再用0.0001训练30个迭代。
为了防止过拟合,采用dropout和数据增强,dropout比例为0.5
Yolo-V1优缺点
YOLO1优点
(1)速度快。因为我们把它看作一个回归问题,而不需要复杂的pipeline,测试时,只需要把新图像放入神经网络中运行即可。它可以达到实时的效果,mAP也更高。
(2)对图像有全局的理解。不像是基于滑动窗口和region proposal的技术,YOLO会隐式地编码目标所属类别及其外观的上下文信息,而Fast RCNN不能看到更大的上下文信息。YOLO用整个图像的特征去预测每个bounding box,同时预测图像中所有类别的bounding box,也就是说,对图像有着全局的理解。
(3)对目标的学习更具有一般性。
(4)精确度高且能快速定位图像中的目标和位置,即使是很小的目标。
(5)网格单元的设计方案,可以减轻对同一对象多次检测的问题。
(6)提供了更少的bounding boxes,每个图像仅98个,而selective search大约2000个。
(7)将这些单独的组件组合成一个单一的联合优化的模型。
(8)YOLO是一个更通用的检测器,可以同时检测多种物体。
YOLO1缺点
(1)由于每个网格只预测2个bounding boxes,这限制了模型可以预测的物体的数量
(2)多次使用下采样,所以预测模型边界框使用的是相对粗糙的特征

若有收获,就点个赞吧
0 人点赞
