
强化学习初印象
数学知识
- 高等数学
- 线性代数(向量空间的变换思维)
-
编程知识
python:numpy
-
机器学习知识
-
推荐资料
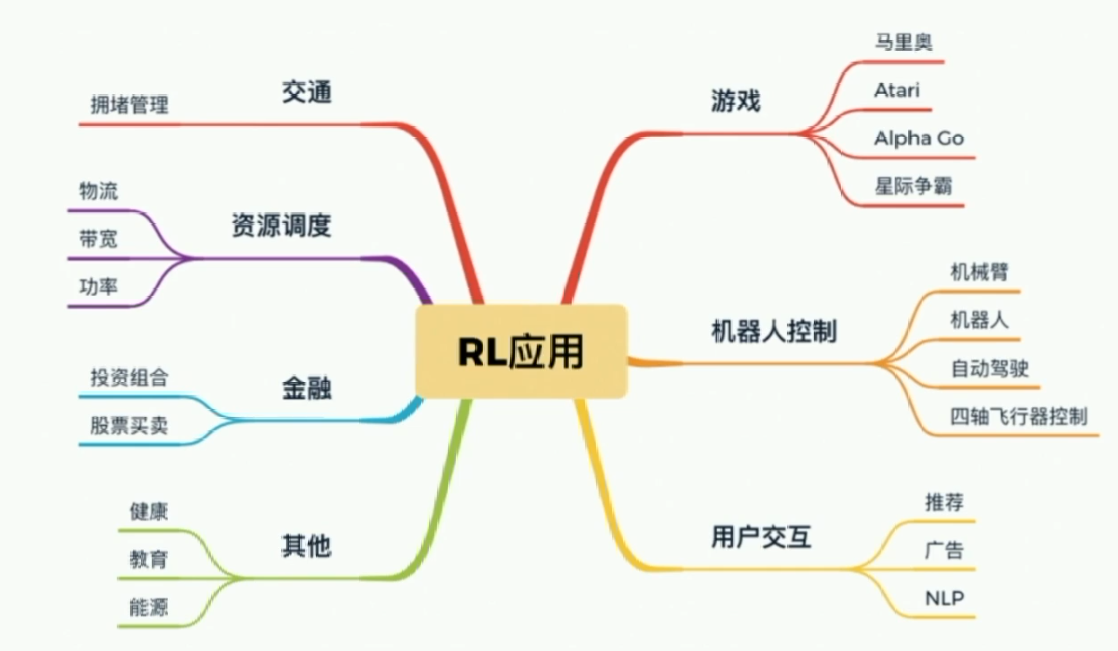
强化学习应用
强化学习与其他学习的关系
Agent的两种学习方案

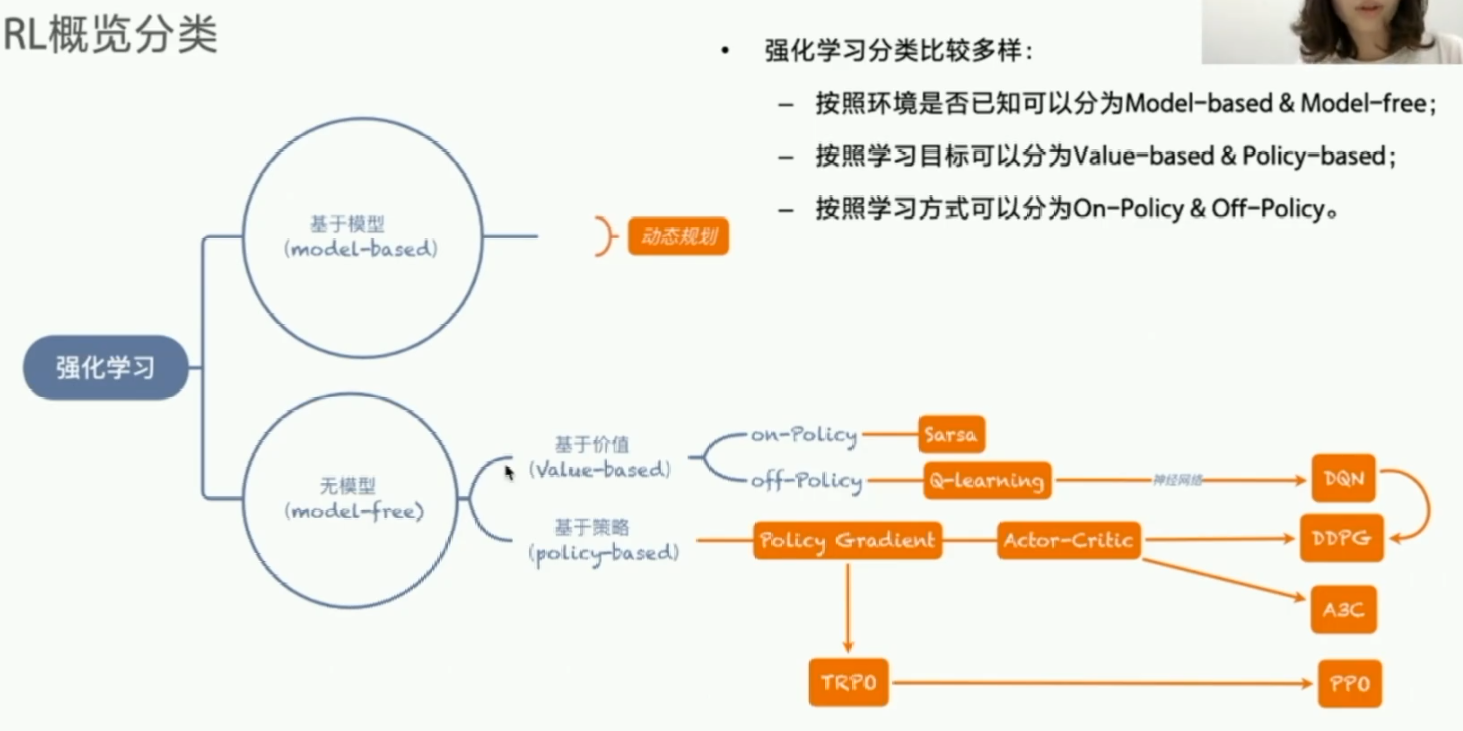
确定性策略
- Sarsa
- Q-Learning
- DQN
- 随机性策略
- Poicy gradient
强化学习算法分类
强化学习算法库和框架库

RL编程实践Gym
Gym:仿真平台、python开源库、RL测试平台
官网:https://gym.openai.com
离散控制场景:一般使用atari环境评估
连续控制场景: 一般使用mujoco环境游戏来评估Gym核心
核心是environment,提供了一下几个核心方法。
reset() 重置环境状态,回到初始环境。方便下一次训练
step(action) 推进一个时间步长,返回四个值:
observation 对环境的一次观察
reward 奖励
done 是否需要重置环境
info 用于调试的诊断信息
render() 重回环境的一帧图像Hide and Seek
- Poicy gradient


基于表格型方法求解RL
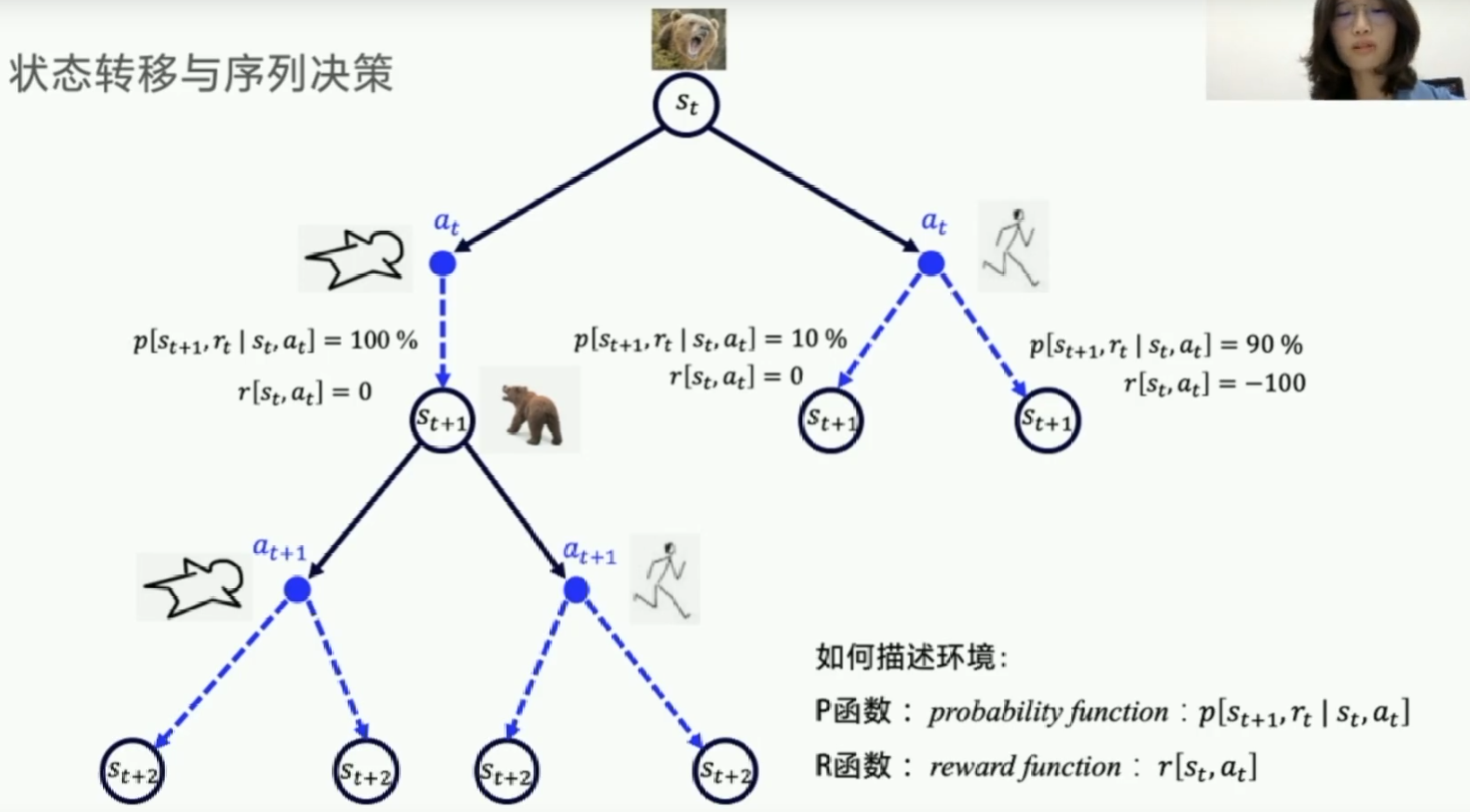

方法:MDP、状态价值、Q表格
实践:Sarsa、Q-Learning
基于神经网络方法求解RL
基于策略梯度求解RL
连续动作空间上求解RL

若有收获,就点个赞吧
0 人点赞
