案例问题
描述这个项目是我调优过两次的项目。我介入这个项目之后,和同事们一起从 100TPS 调到 1000TPS。但是调到这个阶段,也只是在测试环境中调的,并没有按生产的架构调优。从测试部署架构上来说,就是 Tomcat+Redis+MySQL,负载均衡的 Nginx 部分还没有加进去。本来想着如果只是加个 Nginx,也复杂不到哪里去。于是,我就撤了。但是当我离开一周之后,那个项目组同事又给我打电话,说这个项目仍然有问题,加了 Nginx 之后,TPS 达不到 1000 了。啊,这还得了,要砸我招牌呀。于是我又介入这个项目了,直到再次解决这个新的性能问题。在今天的内容里,我会将记忆中所有的细节都记录下来,有些是同事调的步骤,有些是我调的步骤。在这个久远的项目中,希望我能写的完整。下面来看这个具体的问题分析过程。这个系统的简单架构图如下所示: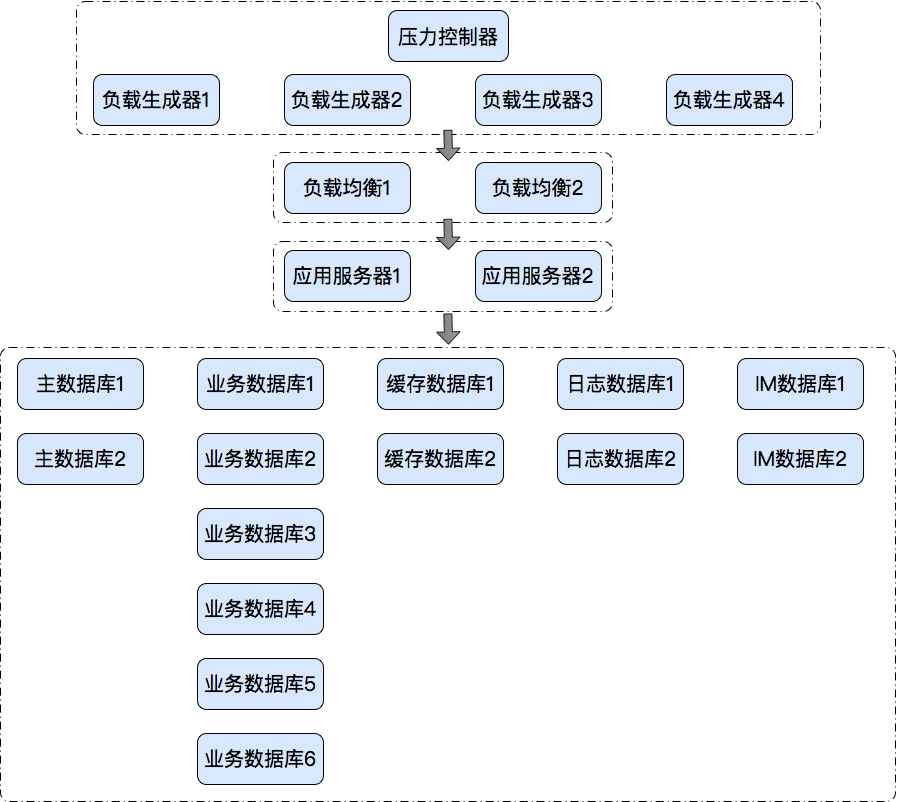
压力工具图照例,我们先看压力工具中给出来的重要曲线。用户递增图
tps图
响应时间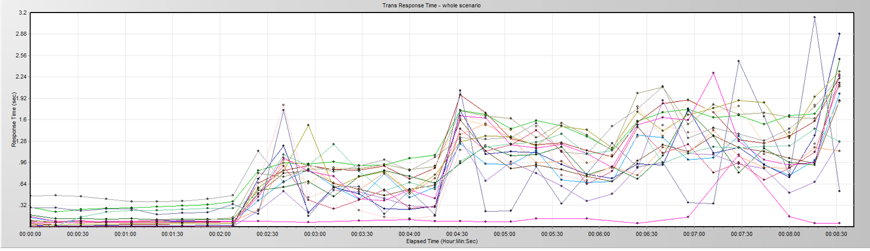
从上面的曲线可以看到,TPS 在上升到一个量级的时候就会掉下来,然后再上到同样的量级再掉下来,非常规律。而响应时间呢,在第一次 TPS 掉下来之后,就变得乱七八糟了。响应时间不仅上升了,而且抖动也很明显。这是什么情况?从来没见过呀。分析过程我们需要经过一系列的工作——看操作系统的 CPU、I/O、Memory、NET 等资源;看数据库、Tomcat、Nginx 监控数据等等。经过分析,我们觉得其他数据显示正常,网络连接状态是有问题的。如下所示:
tcp 0 0 ::ffff:192.168.1.12:59103 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:59085 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:59331 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:46381 ::ffff:192.168.1.104:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:59034 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:59383 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:59138 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:59407 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:59288 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:58905 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:58867 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:58891 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:59334 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:46129 ::ffff:192.168.1.100:3306 TIME_WAIT timewait (0.00/0/0)tcp 0 0 ::ffff:192.168.1.12:59143 ::ffff:192.168.1.11:3306 TIME_WAIT timewait (0.00/0/0)
从这里我们可以看到,网络中有大量的 timewait 存在,这是有价值的信息了,但也只是现象。尝试优化。
尝试一:为 TIME_WAIT 修改 TCP 参数
通过检查 sysctl.conf我们看到所有的配置均为默认,于是尝试如下修改。其实这个修改,应该说是在分析得不够精准的情况下做的判断。因为在服务端出现大量的 timewait,说明是服务端主动断开的 TCP 连接。而我们处理这样的连接,无非就是释放服务端的句柄和内存资源,但是不能释放端口,因为服务端只开了一个 listen 端口。
net.ipv4.tcp_tw_recycle = 1net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_fin_timeout = 3net.ipv4.tcp_keepalive_time = 3
回归测试,问题依旧。
尝试二:修改 Nginx 的 proxy_ignore_client_abort考虑到当客户端主动断开时,服务器上也会出现大量的 timewait,所以我们打开 proxy_ignore_client_abort,让 Nginx 忽略客户端主动中断时出现的错误。proxy_ignore_client_abort on;修改后,重启 Nginx,问题依旧。这个操作纯属根据经验做的猜测。因为是加了 Nginx 之后才出现的问题。但是这个调整并没有起到作用,可见不是压力端主动断开连接而导致的问题,也就是说,和压力机无关了。
尝试三:换 Nginx 和 Nginx 所在的服务器因为这个案例是通过 Nginx 服务器才看到 TPS 上到 300 就会下降,所以我们考虑是 Nginx 的问题。但是查来查去,也没看到 Nginx 有什么明显的问题,于是我们就下载了 Nginx 的源码,重新编译一下,什么模块都不加,只做转发。通过回归测试发现,并没有解决问题。到这里,那就显然和 Nginx 本身没什么关系了,那么我们就换个服务器吧。于是我们在另一台机器上重新编译了 Nginx,但是问题依旧。服务器和 Nginx 都换了,但还是没有解决问题,那么问题会在哪呢?想来想去,还是在操作系统层面,因为 Nginx 实在是没啥可调的,只做转发还能复杂到哪去。但是操作系统层面又有什么东西会影响 TPS 到如此规律的状态呢?在考虑了应用发送数据的逻辑之后(请参考《18 丨 CentOS:操作系统级监控及常用计数器解析(下)》中的网络部分中的“数据发送过程”和“数据接收过程”),我觉得操作系统本身应该不会存在这样的限制,网络配置参数我也看过,不会导致这样的问题。那么在操作系统发送和接收数据的过程中,只有一个大模块我们还完全没有涉及到,那就是防火墙。于是我查了一下系统的防火墙状态。激活状态的防火墙是如下这样的:[root@node-1 zee]# systemctl status firewalld.service● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor p
从上面的“active (running)”可以看到防火墙确实是开着的。那怎么办?果断地先停掉再说。
总结:
现象:
测试环境压测曲线正常,线上环境曲线杂乱
“TPS 在上升到一个量级的时候就会掉下来,然后再上到同样的量级再掉下来,非常规律”
“响应时间,在第一次 TPS 掉下来之后,就变得乱七八糟了。响应时间不仅上升了,而且抖动也很明显”
检查过程:
1. 问题检查
看操作系统CPU/io/memory/net
看数据库、tomcat/nginx
2. 第1阶段结论: 网络连接有问题
发现了大量timewait
3. 尝试优化
timewait是发起断开后的一个状态,修改服务端TCP相关配置
1. timewait资源允许重用+快速回收 等
修改nginx,只做转发,去除其它逻辑
将nginx部署到另一台服务器上
上述都没发现问题===》防火墙还没看
关闭防火墙,服务TPS正常
4. 第2阶段结论:瓶颈在防火墙
5. 问题分析
dmesg 查下系统日志
发现 nf_conntrack 数据满了
查文档,知道其是干什么的;怎么改
* 修改配置,重新打开防火墙==》服务正常
6. 结束:瓶颈处理完成

若有收获,就点个赞吧
0 人点赞
