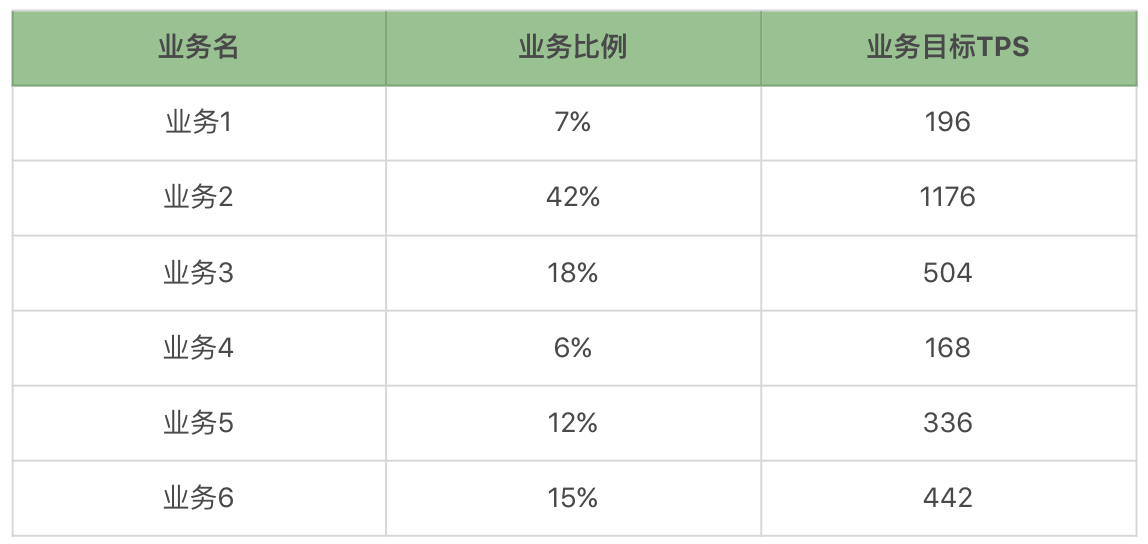
基准性能场景
有很多人做接口测试的时候,觉得接口的 TPS 真是高呀,于是就按照最高的 TPS 跟老板汇报。但我们一定要知道的是,接口的 TPS 再高,都无法说明容量场景的情况,除非这个服务只有这一个接口,并且也只为了测试服务,这时就不必有混合的情况了。首先,我们要知道,每个业务在系统中的最大容量是多少。那么接下来,我们用上面的业务一个一个地做基准,看看结果如何。
业务 1场景执行时长:17 分钟。先看 Statistics。
很多人喜欢用这个表中的数据来做报告,特别是 90th pct、95th pct、99th pct。我不是说不能用,但是,我们要先知道这个场景是什么样,再来确定这些值是不是可以用。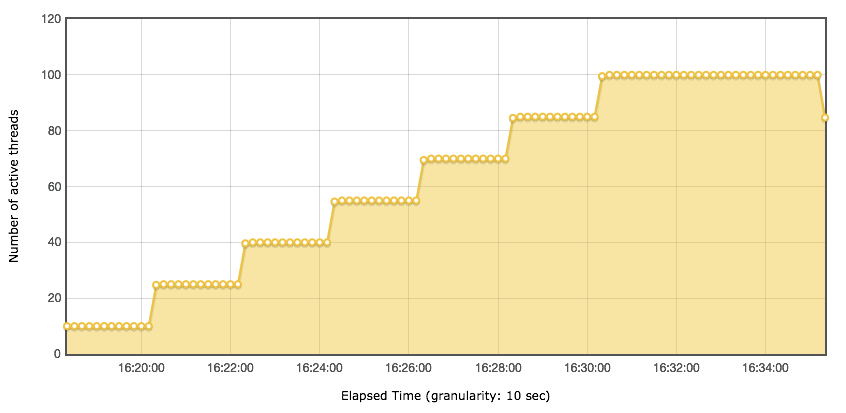
以每分钟 15 个用户的速度往上递增。对应的响应时间图是下面这样的。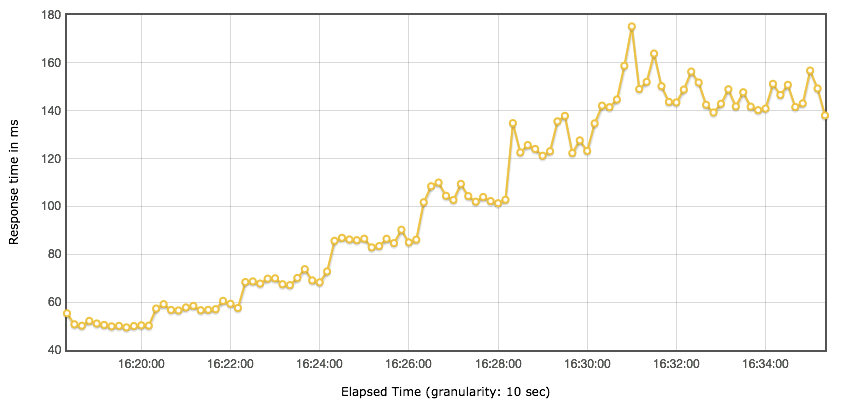
随着用户的增加,响应时间一直都在增加,显然瓶颈已经出现了。我们再结合 Statistics 表格中几个和时间有关的值来想想一想,90th pct、95th pct、99th pct、平均响应时间还可以用吗? Statistics 的平均响应时间是 109.83ms,但是你从响应时间图和线程图比对就可以看到,在不同的线程阶梯,响应时间是有很大差别的。所以 Statistics 中的响应时间都是针对整个场景来说的,然而在梯度加压的过程中,用 Statistics 中的数据是不合理的。接着我们再来看下 TPS 图: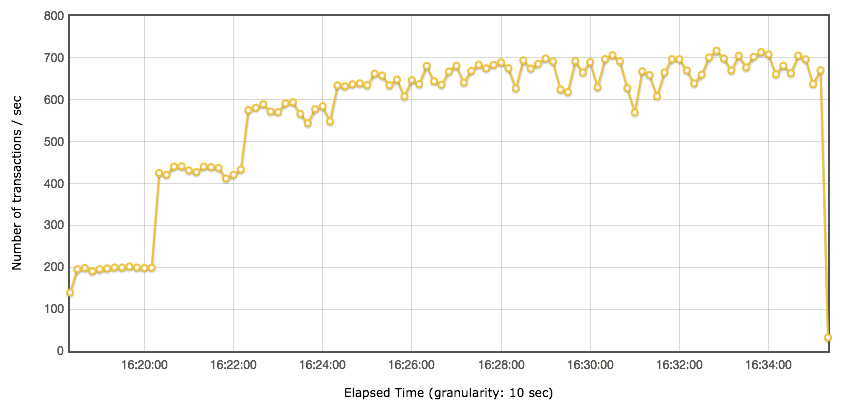
我们可以从 TPS 图上看到,最大 TPS 能达到 680 左右。我再啰嗦一句,请你不要再用所谓的”最大 TPS 拐点“这样的描述来说明 TPS 曲线,
结合上面四个图,我们就有了如下的判断:场景是递增的。压力线程上升到 55(第四个阶梯)时,TPS 达到上限 680 左右,但是明显的,性能在第三个阶梯就已经接近上限了,在压力线程达到 55 时,响应时间达到 85ms 左右,这个值并不高。除此之外,其他的似乎不需要我们再做什么判断了。
有了上面这些单业务的容量结果,我们就可以做一个表格了: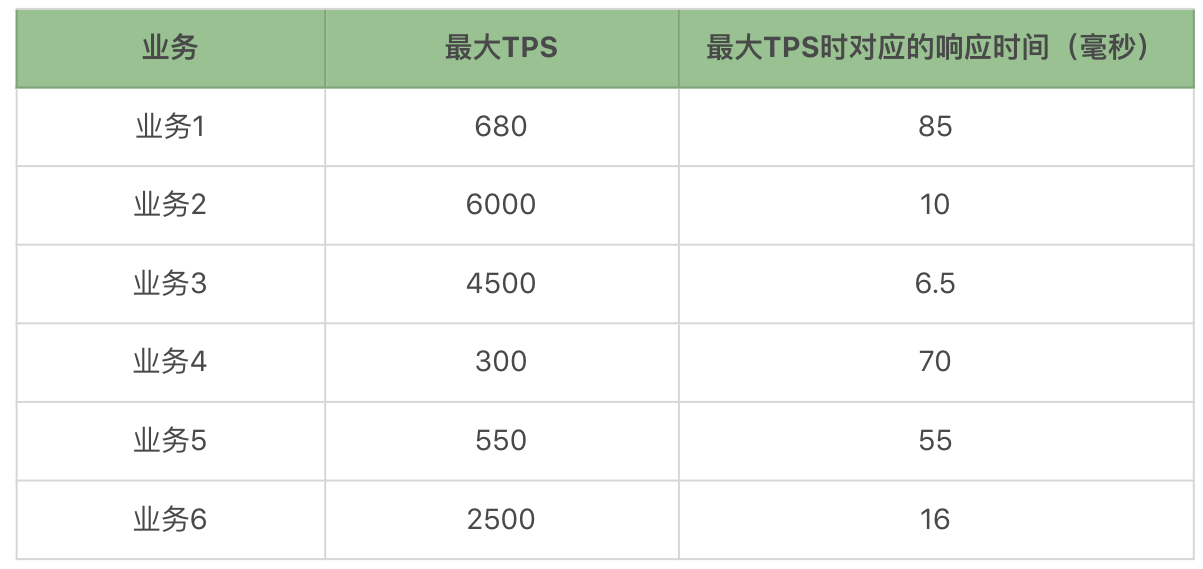
还记得我们前面提到响应时间都不能大于 100ms 吧。通过测试结果我们可以看到,业务 1 已经接近这个指标了,也就是说这个业务如果在活动或促销期,有可能出现峰值最大 TPS 超过承受值的情况,超过了前面制定的响应时间指标。
容量性能场景
我们希望得到的容量场景在本文的一开始就已经给出。下面我们通过设计线程来得到这个容量场景的结果。你需要记住我们的重点:场景不断。控制比例。我们这里只说一个容量性能场景,并且这个场景是峰值业务场景。如果在你的项目中,有特定的业务日,那就要根据业务日的业务比例,重新做一个针对性的场景。在满足了最开始提到的业务比例之后,我们不断增加压力,得到如下结果
线程数: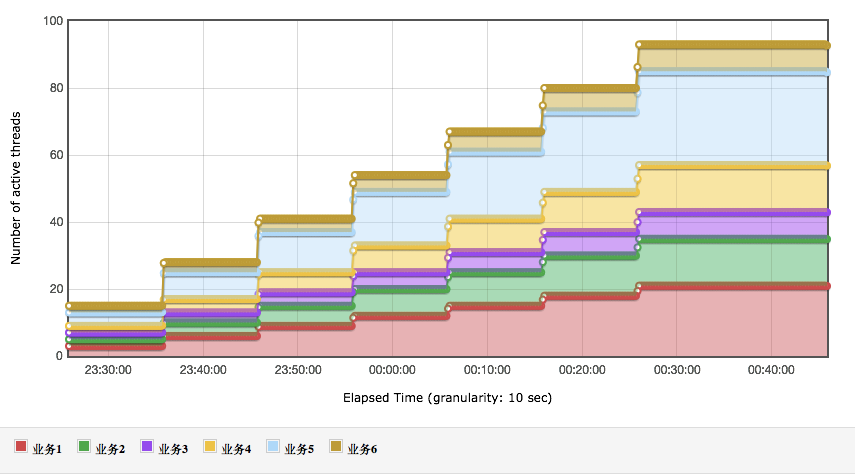
响应时间图: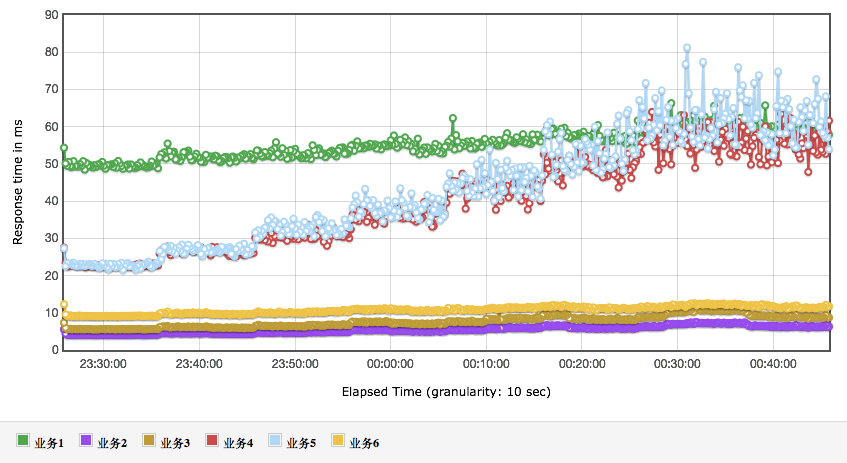
TPS 图: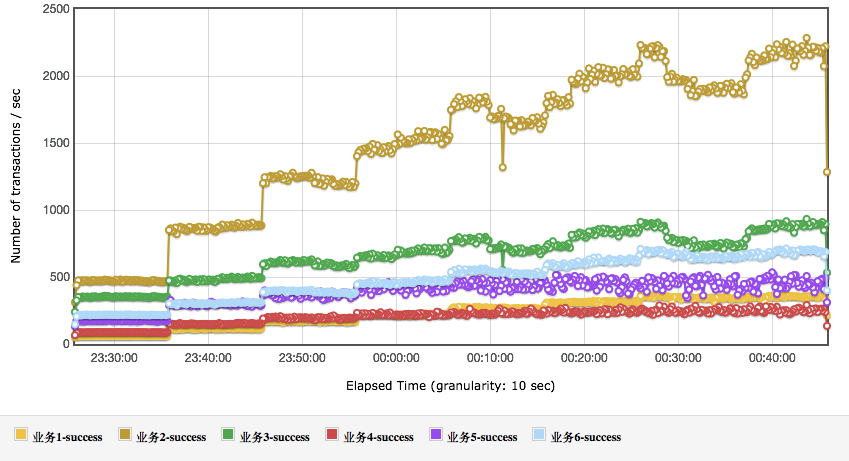
从上面的结果可以看到,业务 4 和业务 5 的响应时间,随着业务的增加而增加,这显然在容量上会影响整体的性能。在具体的项目中,这就是我们要分析调优的后续方向。还有一点请你注意,并不是说,看到了性能瓶颈就一定要解决,事实上,只要业务指标可控,不调优仍然可以上线。这一点也是很多做性能测试的人会纠结的地方,感觉看到这种有衰减趋势的,就一定要把它给调平了。其实这是没有必要的。我们做性能是为了让系统能支持业务,即使性能衰减已经出现,性能瓶颈也在了,只要线上业务没有超出容量场景的范围,那就仍然可以上线。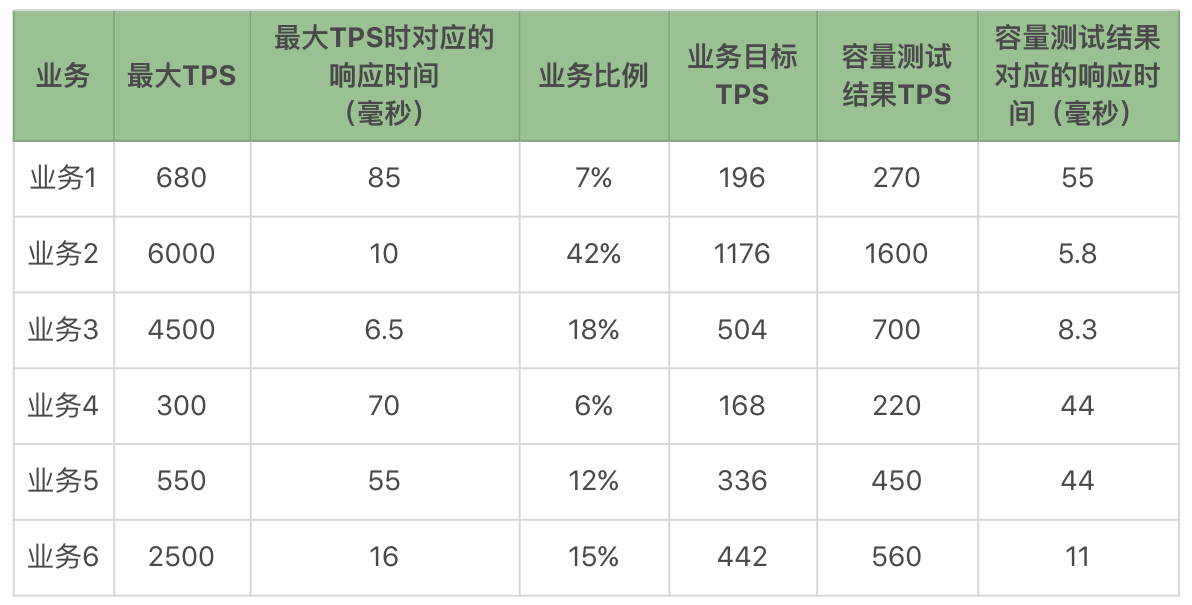
我们可以从上面的数据中看到,业务目标 TPS 已经达到,响应时间也没有超过指标。很好,这个容量就完全满足业务需求了。但是!如果业务要扩展的话,有两个业务将会先受到影响,那就是业务 4 和业务 5,因为它们的测试 TPS 和最大 TPS 最为接近。这是在我们推算业务扩展之后,再做架构分析时要重点考虑的内容。如果是在实际的项目中,这里会标记一个业务扩展风险。请你注意,根据架构,性能测试组需要根据当前的测试状态整理架构的关键配置给线上系统做为参考,并且每个项目都会不一样,所以并不是固定的内容。
稳定性性能场景
我在第 1 篇文章就提到过,稳定性场景的时间长度取决于系统上线后的运维周期。
在这个示例中,业务 + 运维部门联合给出了一个指标,那就是系统要稳定运行一周,支持 2000 万业务量。运维团队每周做全面系统的健康检查。当然谁没事也不用去重启系统,只要检查系统是否还在健康运行即可。大部分时候运维是等着系统警告的。那么针对前面给出的容量结果,容量 TPS 能达到 3800(业务 1 到业务 6 的容量测试结果 TPS 总和)。所以稳定性场景时间应该是:20000000/3800 = 1.46 小时。下面是两小时的稳定性场景运行情况,我在这里只做一下大概的说明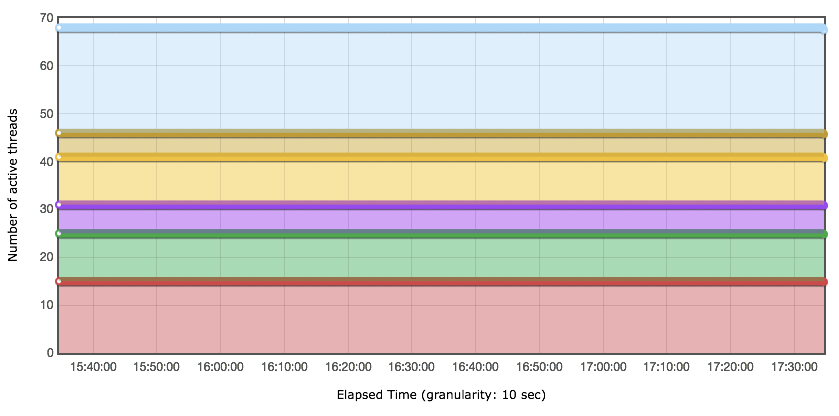
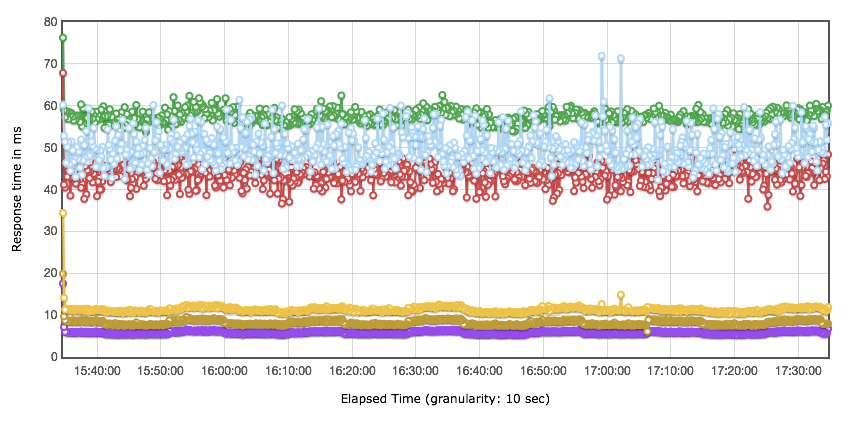
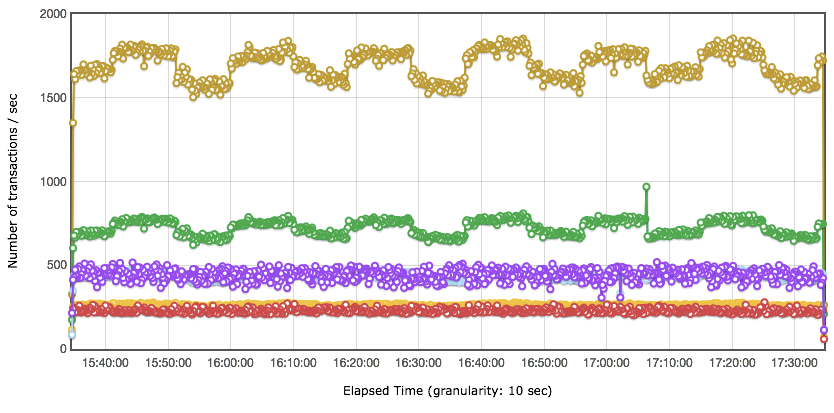
从上面几张图可以看出,业务 2 和业务 3 对总 TPS 的动荡产生了影响,但系统并没有报错。这种周期性的影响,你可以去分析具体的原因,由于本篇是场景篇,所以这里不写分析过程,直接给出原因,这种影响是参数化数据周期性使用所导致的。
其他的业务都比较正常,也比较稳定,没有报错。总体业务量达到 27299712,也达到了稳定性业务量级的要求。有一点,估计会有人提出疑问,你这个稳定性的总体 TPS,看起来和容量测试场景中差不多呀,有必要用容量测试中的最大 TPS 来跑稳定性吗?这里就涉及到另一个被误解的稳定性知识点了。有很多人在资料中看到,稳定性测试应该用最大 TPS 的 80% 来跑。看到没有,这似乎又是一个由 28 原则导致的惯性思维。
异常性能场景
我之前有提到过,异常性能场景要看架构图,但是涉及到职业素养的问题,我这里只能画个示意图来说明此系统的架构,以此来实现逻辑的完整性。示意图如下所示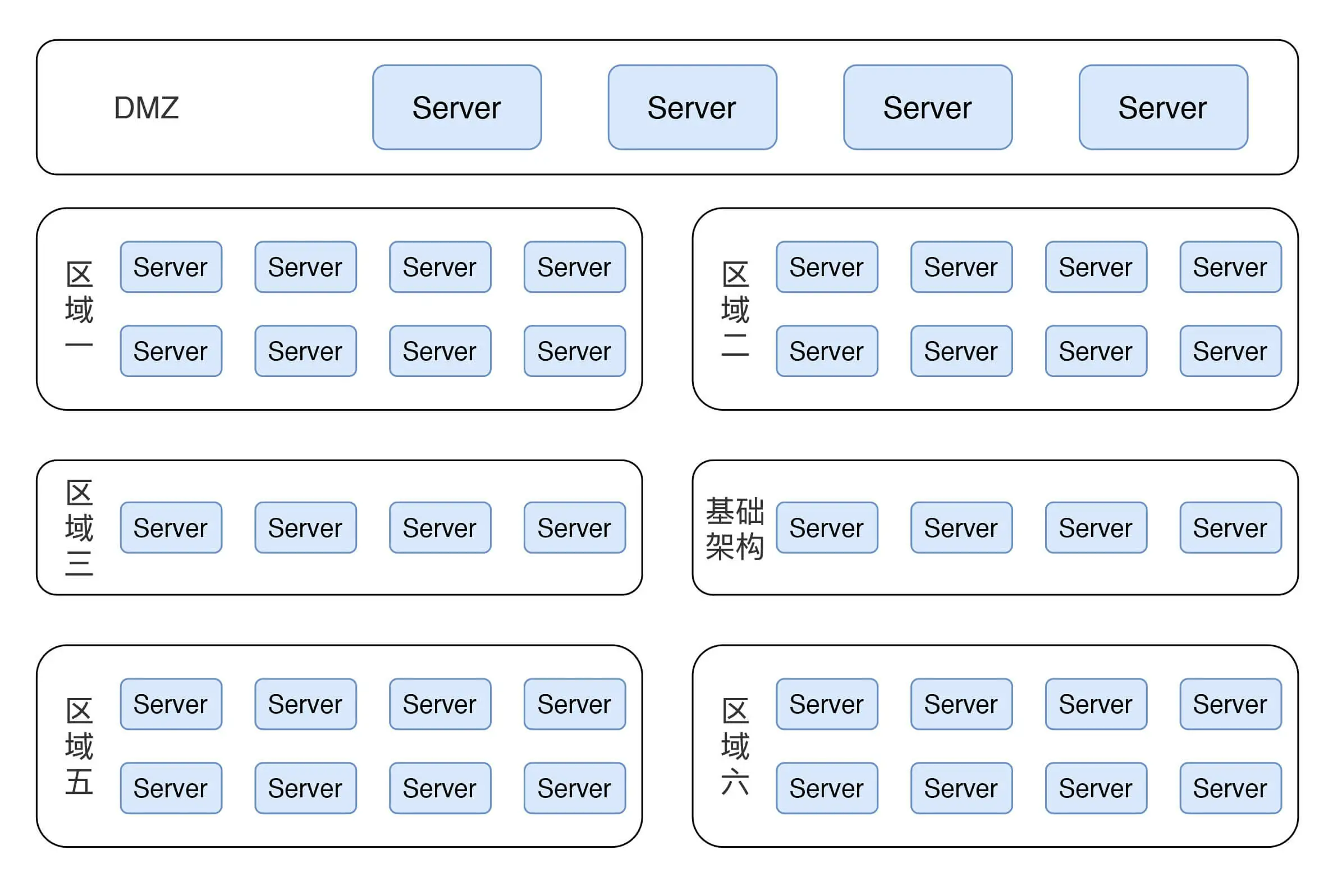
这是一个完全按生产架构来的示意图,在真实的测试过程中,也是这样搭建的。在这里有六个业务区域(包含基础架构区),也有 DMZ 区。其实在每个区域中,根据架构中用到的技术组件,异常测试都有细化的场景设计,而在这里,我给你展示一个全局架构层的场景,用来说明异常场景。这里运行的场景是:用容量场景中最大 TPS 的 50% 来做异常的压力背景。咦,是不是会有人问:这里为什么只用 50% 了?稳定性性能场景不是还用 100% 的压力背景嘛?这里我就要再说一遍,看目标!异常性能场景的目标是为了判断所要执行的操作对系统产生的影响,如果 TPS 不稳定,怎么能看出来异常点?当然是稳定无抖动的 TPS 是最容易做出异常动作产生的影响了。所以这里的 50% 是为了得到更为平稳的 TPS 曲线,以便做出正确的判断。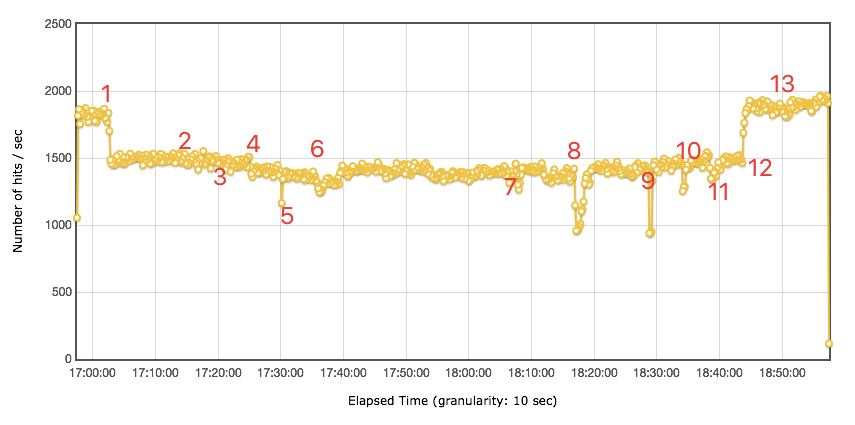
从图上看,并不是所有的 TPS 都在步骤 1 的时候受到了影响。受影响的只有业务 2 和业务 3。显然只有业务 2 和业务 3 走到了这个区域。但是这仍然是一个 BUG!!!理论上,用一半的压力,停了一半的服务器,即便当前正在运行在被停掉的服务器上的 session 受到了影响,那 TPS 也应该会恢复的,但是 TPS 没恢复。所以先这里提个 BUG。另外,停掉区域一、二、五的一半应用服务器,影响不大,TPS 有些许下降,但并没有报错,这个结果还可以接受。停掉基础架构服务器时,TPS 有下降,但很快恢复了,非常好。

若有收获,就点个赞吧
0 人点赞
