数据库引擎
- mysql5.5前使用的是 MyISAM 引擎,5.5以后使用的是InnoDB引擎
MyIsam 是高性能的引擎,但不支持事务
InnoDB 引擎支持事务
缓存
mysql 8.0 后移除
mysql有缓存查询结果的功能,但是默认关闭,需要手动开启,并设置缓存大小,一般默认设置30M左右。
my.cnf加⼊以下配置,重启MySQL开启查询缓存
query_cache_type=1query_cache_size=60000
MySQL执⾏以下命令也可以开启查询缓存
set global query_cache_type=1;set global query_cache_size=600000
缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做⼀ 次缓存操作,失效后还要销毁。 因此,开启缓存查询要谨慎,尤其对于写密集的应⽤来说更是如 此。如果开启,要注意合理控制缓存空间⼤⼩,⼀般来说其⼤⼩设置为⼏⼗MB合适。此 外,还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存
select sql_no_cache count(*) from usr
索引
mysql5.7常用索引类型
- Normal 普通索引 表示普通索引,大多数情况下都可以使用
- Unique 唯一索引 表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,可设置为unique
- Full Text 全文索引 表示全文收索,在检索长文本的时候,效果最好,短文本建议使用Index,但是在检索的时候数据量比较大的时候,现将数据放入一个没有全局索引的表中,然后在用Create Index创建的Full Text索引,要比先为一张表建立Full Text然后在写入数据要快的很多
- SPATIAL 空间索引 空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NUL
索引方法-数据结构
Hash Hash 索引不支持顺序和范围查询,只适合等值查询
BTREE 默认查询索引
事务
什么是事务
一组操作要么全成功,要么全失败,事务的目的是最终一致性
事务的四大特性
- 原子性 一组操作要么全部成功,要么全部失败
- 最终一致性: 使用事务的目的, ⽽「隔离性」「原⼦性」「持久 性」均是为了保障「⼀致性」的⼿段,保证⼀致性需要由应⽤程序代码来保证
- 隔离性: 事务并发执行时,内部操作不能互相干扰
- 持久性: 对数据库修改是永久性的
Mysql(事务)的四大隔离级别:
隔离级别越低,并发性能越强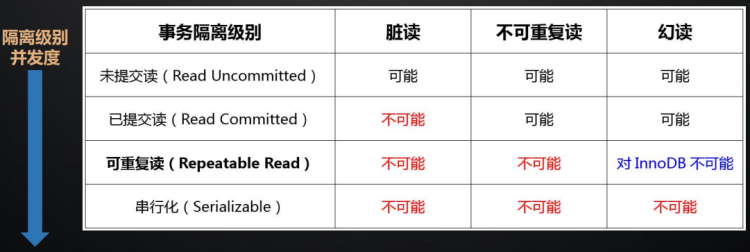
- 读未提交 会有脏读问题,读到未提交数据
- 读已提交 会有不可重复读问题, ⼀个事务读取到另外 ⼀个事务已经提交的数据,也就是说⼀个事务可以看到其他事务所做的修改。
- 可重复读 存在幻读问题,读取到别的事务插入的数据,导致前后读取不一致
- 串行读
不同隔离级别可以解决掉由于并发事务 所造成的问题,⽽隔离级别实际上就是由MySQL锁来实现的 频繁加锁会导致数据库性能低下,引⼊了MVCC多版本控制来实现读写不阻塞,提⾼数据库性能
事务问题:
- 脏读: 同时有两个事务操作数据,第一个事务修改未提交,第二个事务这时候读到的是未提交的内容
- 丢失修改: 两个事务同时操作数据,第一个事务修改内容后提交,第二个事务修改内容也提交,就会覆盖第一个事务提交的内容
- 不可重复读: 一个事务多次读取数据,这时第二个事务修改了数据,第一个事务读取到的内容就不一致
- 幻读: 一个事务多次读取数据,这时第二个事务增删了数据,第一个事务读到的内容就会多或少,像是发生了幻觉
MVCC 多版本并发控制
通过对比版本来实现读写不堵塞,
MVCC原理
undo log: 记录修改数据之前的信息 ,例如inster 就记录 dele 语句
调优
最左匹配原则与回表
查询默认会走两次,第一次先从左边索引走起(最左),直到碰到非索引字段,查询非索引字段(回表)。
如 >、<、between 和 以%开头的like查询 等条件会停止匹配
开发规范和索引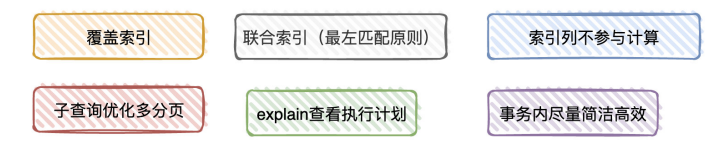
- 只要有查询都建立索引
- 常用查询字段,建议都建立索引. 避免回表问题(索引与其他列不在一个数据结构,查询出索引后需通过索引重复查询普通字段)
- 考虑是否组建[组合索引],将区分度最高的放左边, 最左匹配原则(查询从左边索引走起)
- 对索引进行函数操作或表达式会导致 索引失效
- 利⽤⼦查询优化超多分⻚场景。⽐如 limit offset , n 在MySQL是获取 offset + n的记录,再返回n条。 ⽽利⽤⼦查询则是查出n条,通过ID检索对应的记录出来,提⾼查询效率 (id必须是递增的)
- 通过explain命令来查看SQL的执⾏计划,看看⾃⼰写的SQL是否⾛了索引,⾛了什么索引。通过show profile 来查看SQL对系统资源的损耗情况(不过⼀般还是⽐较少⽤到的)
- 在开启事务后,在事务内尽可能只操作数据库,并有意识地减少锁的持有时间(⽐如在事务内需要插⼊ &&修改数据,那可以先插⼊后修改。因为修改是更新操作,会加⾏锁。如果先更新,那并发下可能会导致多个事 务的请求等待⾏锁释放)
假设走了索引,查询还是很慢
- 数据移除 或数据 移动
- 数据是否能走缓存 ,走缓存的话,业务能不能能忍受读取 [非实时] 数据
- 是否因为[字符串]检索导致 查询低, 考虑把表的数据导⼊⾄ Elasticsearch类的搜索引擎 ( MySQL->Elasticsearch需要有对应的同步程序(⼀般就是监听MySQL的binlog,解析binlog后导⼊到 Elasticsearch )
- 根据查询维度,增加聚合表
写数据 存在性能瓶颈
- 数据库是单库的话, 升级主从架构,实现读写分离( 从库的数据由主库发送的binlog进⽽更新 )
- 主从架构下,仍存在瓶颈..考虑分库分表
分库分表-迁移过程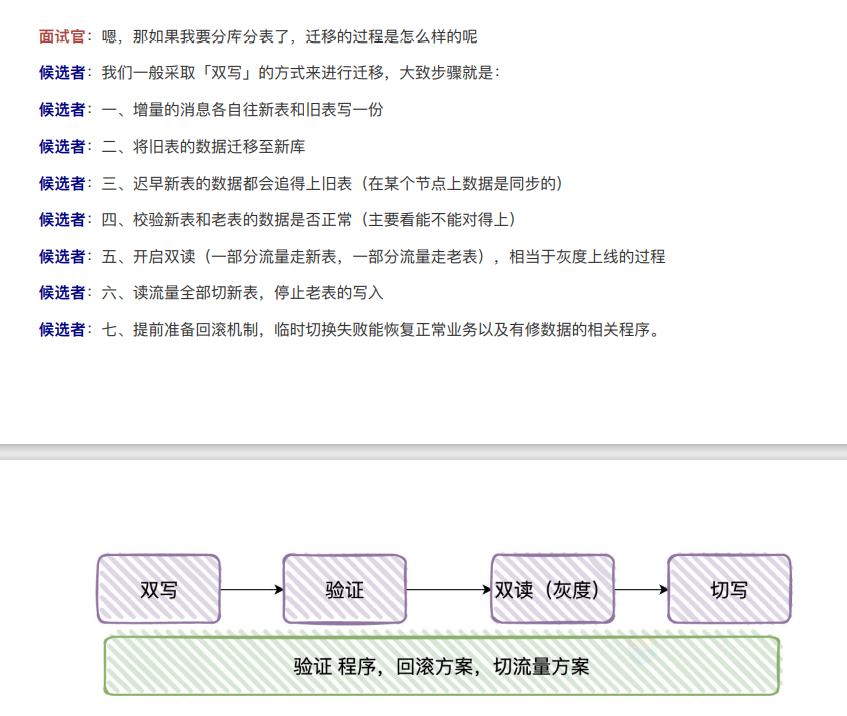
其他优化
你就分小型服务和大型服务区分讲被,小型服务一般属于传统性质的,sql语句都比较长,这个时候考虑看执行计划,表数据归档,走索引巴拉巴拉,如果是大型服务,就考虑读写分离,库的水平垂直拆分,业务拆分,根据业务模型提前架构好建表模型,然后再扯数据库集群等等

若有收获,就点个赞吧
0 人点赞
