前置说明
本文档参考 掘金 netty 入门与实战
使用netty 版本为:
<dependency><groupId>io.netty</groupId><artifactId>netty-all</artifactId><version>4.1.6.Final</version></dependency>
为什么使用Netty
Netty 封装了 JDK 的 NIO
io 读写是面对流的,一次只能读取一个或多个字节,并且读取完后流无法再读取,需要自己缓存,Nio 解决了上述问题,读写是面向Buffer,可以随意读取里面任何字节数据,不需要自己缓存.但Nio的JDK 原生操作太复杂,很多功能没有实现,自己书写容易出BUG.
使用Netty 不使用 JDK 原生NIO的原因
- 使用 JDK 自带的NIO需要了解太多的概念,编程复杂,一不小心 bug 横飞
- Netty 底层 IO 模型随意切换,而这一切只需要做微小的改动,改改参数,Netty可以直接从 NIO 模型变身为 IO 模型
- Netty 自带的拆包解包,异常检测等机制让你从NIO的繁重细节中脱离出来,让你只需要关心业务逻辑
- Netty 解决了 JDK 的很多包括空轮询在内的 Bug
- Netty 底层对线程,selector 做了很多细小的优化,精心设计的 reactor 线程模型做到非常高效的并发处理
- 自带各种协议栈让你处理任何一种通用协议都几乎不用亲自动手
- Netty 社区活跃,遇到问题随时邮件列表或者 issue
- Netty 已经历各大 RPC 框架,消息中间件,分布式通信中间件线上的广泛验证,健壮性无比强大
服务端如何启动
服务端启动不中
创建一个Netty服务端的步骤为:
1.指定线程组
2.指定读写模型
3 .指定消息处理
public class NettyServer {public static void main(String[] args) {NioEventLoopGroup bossGroup = new NioEventLoopGroup();NioEventLoopGroup workerGroup = new NioEventLoopGroup();ServerBootstrap serverBootstrap = new ServerBootstrap();serverBootstrap.group(bossGroup, workerGroup) //指定线程组.channel(NioServerSocketChannel.class) //指定读写模型.childHandler(new ChannelInitializer<NioSocketChannel>() {protected void initChannel(NioSocketChannel ch) {}}); //指定消息处理serverBootstrap.bind(8000);}}
- 我们创建了两个
NioEventLoopGroup,可以看做传统编程模型的两大线程组,bossGroup用来监听线程,workerGroup用来消费线程 ServerBootstrap用来启动服务端,.group用来指定两大线程组- 通过
.channel()来指定io模型, nio 模型为NioServerSocketChannel.classBio 模型为OioServerSocketChannel.class - 通过
childHandler给这个引导类创建一个ChannelInitializer ,主要是定义后面数据的读写 ChannelInitializer,这里主要就是定义后续每条连接的数据读写bind 遍历递增绑定端口
bind方法返回的是ChannelFuture,我们可以给ChannelFuture增加监听器, ```java private static void bind(final ServerBootstrap serverBootstrap, final int port) { serverBootstrap.bind(port).addListener(new GenericFutureListener
<a name="w9VAG"></a>### 其它常用方法<a name="Nnglg"></a>#### handler() 服务端启动中执行逻辑 与childHandle() 对应<a name="uQwKC"></a>#### attr() 方法 给服务端`channel`制定一些自定义属性通过`channel.attr() `取出```javaserverBootstrap.attr(AttributeKey.newInstance("serverName"), "nettyServer")
childAttr() 方法 给每一条连接指定自定义属性
通过channel.attr()取出
serverBootstrap.childAttr(AttributeKey.newInstance("clientKey"),"clientValue")
childOption() 方法 给连接设置一些TCP底层属性
例如:
- ChannelOption.SO_KEEPALIVE表示是否开启TCP底层心跳机制,true为开启
- ChannelOption.TCP_NODELAY表示是否开启Nagle算法,true表示关闭,false表示开启,通俗地说,如果要求高实时性,有数据发送时就马上发送,就关闭,如果需要减少发送次数减少网络交互,就开启。
serverBootstrap.childOption(ChannelOption.SO_KEEPALIVE, true) //开启Tcp 心跳机制.childOption(ChannelOption.TCP_NODELAY, true)//表示是否开启Nagle算法// 如果要求高实时性,有数据发送时就马上发送,就关闭,如果需要减少发送次数减少网络交互,就开启。
option() 方法 给服务端channel配置一些属性
```java //表示系统用于临时存放已完成三次握手的请求的队列的最大长度,如果连接建立频繁,服务器处理创建新连接 //较慢,可以适当调大这个参数 serverBootstrap.option(ChannelOption.SO_BACKLOG, 1024)
如果觉得过于简单可以看这门慕课课程[Java读源码之Netty深入剖析](https://coding.imooc.com/class/chapter/230.html#Anchor)<a name="PrCnv"></a>## 客户端如何启动客户端启动与服务端启动基本一致,但`serverBootstrap`更换为`Bootstrap`,且只需要增加一个线程组```javapublic class NettyClient {public static void main(String[] args) {NioEventLoopGroup workerGroup = new NioEventLoopGroup();Bootstrap bootstrap = new Bootstrap();bootstrap// 1.指定线程模型.group(workerGroup)// 2.指定 IO 类型为 NIO.channel(NioSocketChannel.class)// 3.IO 处理逻辑.handler(new ChannelInitializer<SocketChannel>() {@Overridepublic void initChannel(SocketChannel ch) {}});// 4.建立连接bootstrap.connect("juejin.im", 80).addListener(future -> {if (future.isSuccess()) {System.out.println("连接成功!");} else {System.err.println("连接失败!");}});}}
失败重连
失败隔秒重连调用的是bootstrap.config().group().schedule()
connect(bootstrap, "juejin.im", 80, MAX_RETRY);private static void connect(Bootstrap bootstrap, String host, int port,2019/6/12 4客户端启动流程.mdfile:///Users/pengtao/Downloads/Netty 入门与实战:仿写微信 IM 即时通讯系统/4客户端启动流程.html 3/4int retry) {bootstrap.connect(host, port).addListener(future -> {if (future.isSuccess()) {System.out.println("连接成功!");} else if (retry == 0) {System.err.println("重试次数已用完,放弃连接!");} else {// 第几次重连int order = (MAX_RETRY - retry) + 1;// 本次重连的间隔int delay = 1 << order;System.err.println(new Date() + ": 连接失败,第" + order + "次重连……");bootstrap.config().group().schedule(() -> connect(bootstrap,host, port, retry - 1), delay, TimeUnit.SECONDS);}});}
其他常用方法
attr() 给客户端 channel设定自定义属性
通过channel.attr() 取出属性
bootstrap.attr(AttributeKey.newInstance("clientName"), "nettyClient")
option 设置连接的一些TCP底层属性
Bootstrap.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000).option(ChannelOption.SO_KEEPALIVE, true).option(ChannelOption.TCP_NODELAY, true)
option() 方法可以给连接设置一些 TCP 底层相关的属性,比如上面,我们设置了三种 TCP 属性,其中
ChannelOption.CONNECT_TIMEOUT_MILLIS表示连接的超时时间,超过这个时间还是建立不上的 话则代表连接失败ChannelOption.SO_KEEPALIVE表示是否开启 TCP 底层心跳机制,true 为开启ChannelOption.TCP_NODELAY表示是否开始 Nagle 算法,true 表示关闭,false 表示开启,通俗地 说,如果要求高实时性,有数据发送时就马上发送,就设置为 true 关闭,如果需要减少发送次数减少网 络交互,就设置为 false 开启双端通信
总结
pipeline().addLast()添加逻辑处理器(参数为 集成了ChannelInboundHandlerAdapter 的类)
- new 一个类继承
ChannelInboundHandlerAdapter类重写方法 数据是以ByteBuf为单位, 所有需要处理的数据都需要塞到一个ByteBuf
客户端消息
增加逻辑处理器
客户端消息的读写是通过
Bootstrap的handler方法指定的,.handler(new ChannelInitializer<SocketChannel>() {@Overridepublic void initChannel(SocketChannel ch) {// 指定连接数据读写逻辑}});//我们可以给 initChannel 方法增加一个逻辑处理器,.handler(new ChannelInitializer<SocketChannel>() {@Overridepublic void initChannel(SocketChannel ch) {ch.pipeline().addLast(new FirstClientHandler());}});
ch.piepeline返回的是和连接相关的逻辑处理链-
创建逻辑处理器
继承
ChannelInboundHandlerAdapter类,重写 对应方法 channelActive 连接建立后调用
channelRead 连接收到消息后调用
public class FirstClientHandler extends ChannelInboundHandlerAdapter {@Overridepublic void channelActive(ChannelHandlerContext ctx) {System.out.println(new Date() + ": 客户端写出数据");// 1. 获取数据ByteBuf buffer = getByteBuf(ctx);2019/6/12 5实战:客户端与服务端双向通信.mdfile:///Users/pengtao/Downloads/Netty 入门与实战:仿写微信 IM 即时通讯系统/5实战:客户端与服务端双向通信.html 2/5// 2. 写数据ctx.channel().writeAndFlush(buffer);}private ByteBuf getByteBuf(ChannelHandlerContext ctx) {// 1. 获取二进制抽象 ByteBufByteBuf buffer = ctx.alloc().buffer();// 2. 准备数据,指定字符串的字符集为 utf-8byte[] bytes = "你好,闪电侠!".getBytes(Charset.forName("utf-8"));// 3. 填充数据到 ByteBufbuffer.writeBytes(bytes);return buffer;}}
netty 传递消息采用ByteBuf
先通过
ctx.alloc().buffer()获取二进制抽象ByteBuf- 再通过
buffer.writeBytes将字节数据写入到ByteBuf - 最后写入到连接中
ctx.channel().writeAndFlush(buffer)服务端读取客户端消息
增加逻辑处理器
指定逻辑处理器步骤与 客户端一致 ```java .childHandler(new ChannelInitializer() { protected void initChannel(NioSocketChannel ch) { // 指定连接数据读写逻辑 ch.pipeline().addLast(new FirstServerHandler()); } });
<a name="Bv7p7"></a>#### 创建逻辑处理器```javapublic class FirstServerHandler extends ChannelInboundHandlerAdapter {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) {ByteBuf byteBuf = (ByteBuf) msg;System.out.println(new Date() + ": 服务端读到数据 -> " +byteBuf.toString(Charset.forName("utf-8")));}}
服务端侧的逻辑处理器同样继承自 ChannelInboundHandlerAdapter,与客户端不同的是,这里覆盖的方 法是 channelRead(),这个方法在接收到客户端发来的数据之后被回调。
msg 就是Netty 里面数据读写的载体,暂时需要强转,其余后面会分析
服务端回显消息给客户端
服务端向客户端写数据逻辑与客户端侧的写数据逻辑一样,先创建一个 ByteBuf,然后填充二进制数据,最后 调用 writeAndFlush() 方法写出去,
。客户端的读取数据的逻辑和服务端读取数据的逻辑一样,同样是覆盖 ChannelRead() 方法
数据传输载体ByteBuf
数据结构
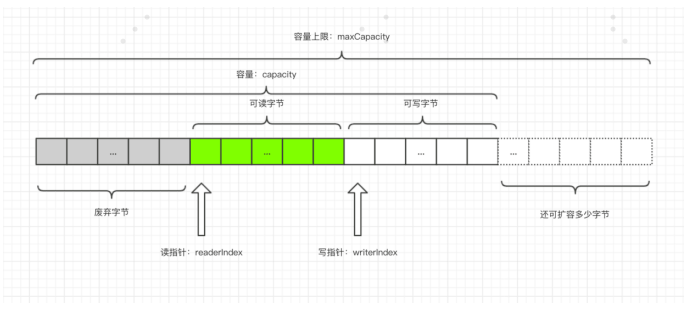
- ByteBuf 是字节容器,容器数据分为三部分: 第一个部分是已经丢弃的字节,这部分数据 是无效的;第二部分是可读字节,这部分数据是 ByteBuf 的主体数据, 从 ByteBuf 里面读取的数据都来 自这一部分;最后一部分的数据是可写字节,所有写到 ByteBuf 的数据都会写到这一段。最后一部分虚线 表示的是该 ByteBuf 最多还能扩容多少容量
- 以上三段内容是被两个指针给划分出来的,从左到右,依次是读指针(readerIndex)、写指针(writerIndex),然后还有一个变量 capacity,表示 ByteBuf 底层内存的总容量
- 从 ByteBuf 中每读取一个字节,readerIndex 自增1,ByteBuf 里面总共有 writerIndex-readerIndex 个字节 可读, 由此可以推论出当 readerIndex 与 writerIndex 相等的时候,ByteBuf 不可读
- 写数据是从 writerIndex 指向的部分开始写,每写一个字节,writerIndex 自增1,直到增到 capacity,这个 时候,表示 ByteBuf 已经不可写了
- ByteBuf 里面其实还有一个参数 maxCapacity,当向 ByteBuf 写数据的时候,如果容量不足,那么这个时 候可以进行扩容,直到 capacity 扩容到 maxCapacity,超过 maxCapacity 就会报错
常用Api
容量API
- capacity() :
表示 ByteBuf 底层占用了多少字节的内存(包括丢弃的字节、可读字节、可写字节)
- maxCapacity() :
表示 ByteBuf 底层最大能够占用多少字节的内存
- readableBytes() 与 isReadable() :
readableBytes() 表示 ByteBuf 当前可读的字节数,它的值等于 writerIndex-readerIndex,如果两者相等,则不可 读,isReadable() 方法返回 false
writableBytes()、 isWritable() 与 maxWritableBytes( )
writableBytes() 表示 ByteBuf 当前可写的字节数,它的值等于 capacity-writerIndex,如果两者相等,则表示不可 写,isWritable() 返回 false,但是这个时候,并不代表不能往 ByteBuf 中写数据了, 如果发现往 ByteBuf 中写数 据写不进去的话,Netty 会自动扩容 ByteBuf,直到扩容到底层的内存大小为 maxCapacity,而 maxWritableBytes() 就表示可写的最大字节数,它的值等于 maxCapacity-writerIndex
读写指针相关API
readerIndex() 与 readerIndex(int)
获取读指针与设置读指针
writeIndex() 与 writeIndex(int)
获取写指针与设置写指针
- markReaderIndex() 与 resetReaderIndex()
前者表示把当前的读指针保存起来,后者表示把当前的读指针恢复到之前保存的值
// 代码片段1int readerIndex = buffer.readerIndex();// .. 其他操作buffer.readerIndex(readerIndex);// 代码片段二buffer.markReaderIndex();// .. 其他操作buffer.resetReaderIndex();
推荐使用第二种,不需要自己定义变量,无论 buffer 当作参数传递到哪里,调用
resetReaderIndex() 都可以恢复到之前的状态,在解析自定义协议的数据包的时候非常常见,推荐大家使用这一
对 API
- markWriterIndex() 与 resetWriterIndex( )
与读指针相对的写指针
读写API
本质上,关于 ByteBuf 的读写都可以看作从指针开始的地方开始读写数据
- writeBytes(byte[] src) 与 buffer.readBytes(byte[] dst)
将数据写入到ByteBuf ,而 readBytes() 指的是把 ByteBuf 里面的数据全 部读取到 dst writeByte(byte b) 与 buffer.readByte()
writeByte() 表示往 ByteBuf 中写一个字节,而 buffer.readByte() 表示从 ByteBuf 中读取一个字节,类似的 API 还 有 writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble() 与 readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble()
release() 与 retain()
netty 使用的是堆外内存,不被jvm 直接管理.也就是说使用的内存无法直接被垃圾回收器回收.我们使用的内存必须字节手动回收
Netty 的 ByteBuf 是通过引用计数的方式管理的,如果一个 ByteBuf 没有地方被引用到,需要回收底层内存。默 认情况下,当创建完一个 ByteBuf,它的引用为1,然后每次调用 retain() 方法, 它的引用就加一, release() 方 法原理是将引用计数减一,减完之后如果发现引用计数为0,则直接回收 ByteBuf 底层的内存。
这三个方法通常情况会放到一起比较,这三者的返回值都是一个新的 ByteBuf 对象
- slice()、duplicate()、copy()
- slice() 从原始 ByteBuf 中截取一段
- duplicate() 方法把整个 ByteBuf 都截取出来,包括所有的数据,指针信息
- slice()、duplicate() 底层内存以及引用计数与原始ByteBuf共享,修改会影响到原始 的ByteBuf
- slice() 方法与 duplicate() 方法不会拷贝数据,它们只是通过改变读写指针来改变读写的行为,而最后一个 方法 copy() 会直接从原始的 ByteBuf 中拷贝所有的信息,包括读写指针以及底层对应的数据,因此,往 copy() 返回的 ByteBuf 中写数据不会影响到原始的 ByteBu
- slice() 和 duplicate() 不会改变 ByteBuf 的引用计数,所以原始的 ByteBuf 调用 release() 之后发现引用计数 为零,就开始释放内存,调用这两个方法返回的 ByteBuf 也会被释放,这个时候如果再对它们进行读 写,就会报错。因此,我们可以通过调用一次 retain() 方法 来增加引用,表示它们对应的底层的内存多了 一次引用,引用计数为2,在释放内存的时候,需要调用两次 release() 方法,将引用计数降到零,才会释 放内存
- 都不会影响 ByteBuf 的引用计数,我们需要自己手动增加和修改
retainedSlice() 与 retainedDuplicate( )
在截取内存片段的同时,增加内存的引用计数,分 别与下面两段代码等价
// retainedSlice 等价于slice().retain();// retainedDuplicate() 等价于duplicate().retain()
slice 和 duplicate 使用注意
使用时注意: 清理内存共享 , 引用计数共享,读写指针不共享
在一个函数体里面,只要增加了引用计数(包括 ByteBuf 的创建和手动调用 retain() 方法),就必须调用 release() 方法
使用时常见错误:
- 多次释放 ```java Buffer buffer = xxx; doWith(buffer); // 一次释放 buffer.release(); public void doWith(Bytebuf buffer) { // …
// 没有增加引用计数 Buffer slice = buffer.slice(); foo(slice); } public void foo(ByteBuf buffer) { // read from buffer
// 重复释放 buffer.release(); }
2. 不释放造成内存泄露```javaBuffer buffer = xxx;doWith(buffer);// 引用计数为2,调用 release 方法之后,引用计数为1,无法释放内存buffer.release()public void doWith(Bytebuf buffer) {// ...// 增加引用计数Buffer slice = buffer.retainedSlice();foo(slice);// 没有调用 release}public void foo(ByteBuf buffer) {// read from buffer}
客户端与服务端通信协议编解码
什么是服务端与客户端的通信协议
无论是使用 Netty 还是原始的 Socket 编程,基于 TCP 通信的数据包格式均为二进制,协议指的就是客户端与 服务端事先商量好的,每一个二进制数据包中每一段字节分别代表什么含义的规则。
通信协议结构

- 魔数为固定字节,用来判断请求是否属于自定义协议, 4字节
- 版本号,一般是预留字段,协议升级的时候可以用到 1字节
- 序列化算法:表示如何把java对象转为二进制数据 和 把二进制数据转为java对象 1字节
- 服务端或者客户端每收到一 种指令都会有相应的处理逻辑,这里,我们用一个字节来表示,最高支持256种指令, 1字节
- 数据长度, 4字节
- 数据内容: 每一种指令对应的数据是不一样的,比如登录的时候需要用户名密码,收消 息的时候需要用户标识和具体消息内容等等。
通信协议的实现
将java 对象根据协议封装为二进制数据包过程为编码,从二进制包解析出java对象过程为解码
定义通信java对象
// 所有指令包都需要继承的类@Datapublic abstract class Packet{//协议版本private Byte version =1 ;//指令 获取指令抽象方法public abstract Byte getCommand() ;}
继承java对象,定义登录请求数据包
public interface Command {Byte LOGIN_REQUEST = 1;}@Datapublic class LoginRequestPacket extends Packet {private Integer userId;private String username;private String password;@Overridepublic Byte getCommand() {return LOGIN_REQUEST;}}
实现序列化
定义序列化接口
public interface Serializer {/*** 序列化算法* 获取具体的序列化算法标识*/byte getSerializerAlgorithm();/*** java 对象转换成二进制*/byte[] serialize(Object object);/*** 二进制转换成 java 对象*/<T> T deserialize(Class<T> clazz, byte[] bytes);}
//使用FastJson 作为序列化框架public interface SerializerAlgorithm {/*** json 序列化标识*/byte JSON = 1;}public class JSONSerializer implements Serializer {@Overridepublic byte getSerializerAlgorithm() {return SerializerAlgorithm.JSON;}@Overridepublic byte[] serialize(Object object) {return JSON.toJSONBytes(object);}@Overridepublic <T> T deserialize(Class<T> clazz, byte[] bytes) {return JSON.parseObject(bytes, clazz);}}
编码:封装为 ByteBuf 对象 二进制对象
- 创建ByteBuf ,
- 将java 对象序列化为二进制数据包
- 按照协议的设计,往ByteBuf 中写入字段
private static final int MAGIC_NUMBER = 0x12345678;public ByteBuf encode(Packet packet) {// 1. 创建 ByteBuf 对象ByteBuf byteBuf = ByteBufAllocator.DEFAULT.ioBuffer();// 2. 序列化 Java 对象byte[] bytes = Serializer.DEFAULT.serialize(packet);// 3. 实际编码过程byteBuf.writeInt(MAGIC_NUMBER);byteBuf.writeByte(packet.getVersion());byteBuf.writeByte(Serializer.DEFAULT.getSerializerAlgorithm());byteBuf.writeByte(packet.getCommand());byteBuf.writeInt(bytes.length);byteBuf.writeBytes(bytes);return byteBuf;}
解码: 解析为java 对象
- 假定传入ByteBuf 是合法数据,调用 skipBytes 跳过这四个字节。
- 暂时不关注协议版本
- 我们调用 ByteBuf 的 API 分别拿到序列化算法标识、指令、数据包的长度。
根据拿到的数据包的长度取出数据,通过指令拿到该数据包对应的 Java 对象的类型,根据序 列化算法标识拿到序列化对象,将字节数组转换为 Java 对象,至此,解码过程结束。
public Packet decode(ByteBuf byteBuf) {// 跳过 magic numberbyteBuf.skipBytes(4);// 跳过版本号byteBuf.skipBytes(1);// 序列化算法标识byte serializeAlgorithm = byteBuf.readByte();// 指令byte command = byteBuf.readByte();// 数据包长度int length = byteBuf.readInt();byte[] bytes = new byte[length];byteBuf.readBytes(bytes);Class<? extends Packet> requestType = getRequestType(command);Serializer serializer = getSerializer(serializeAlgorithm);if (requestType != null && serializer != null) {return serializer.deserialize(requestType, bytes);}return null;}
实战: Netty 实现客户端登录
基本流程是:
客户端编码请求对象为ByteBuf,发送给服务端
- 服务端收到消息后进行解码校验,并将结果返回给客户端
- 客户端收到返回后,将消息展示
实战:客户端与服务端收发消息
判断客户端是否登录成功
通过 channel.attr(xxx).set(xx) 的方式,那么我们是否可以在登录成功之后,给 Channel 绑定一个登录成功 的标志位,然后判断是否登录成功的时候取出这个标志位
//public interface Attributes {AttributeKey<Boolean> LOGIN = AttributeKey.newInstance("login");}
public void channelRead(ChannelHandlerContext ctx, Object msg) {// ...if (loginResponsePacket.isSuccess()) {channel.attr(Attributes.LOGIN).set(true)System.out.println(new Date() + ": 客户端登录成功");} else {System.out.println(new Date() + ": 客户端登录失败,原因:" +Attribute<Boolean> loginAttr = channel.attr(Attributes.LOGIN);return loginAttr.get() != null;}// ...}
pipeline 与 channelHandler
为什么要使用pipeline 与 channelHandler
-避免channelRead() 中对指令处理的 if else 泛滥
Netty 中的 pipeline 和 channelHandler 正是用来解决这个问题的,通过责任链设计模式来组织代码逻辑,并 且能够支持逻辑的动态添加和删除
pipeline 与 channelHandler 的构成
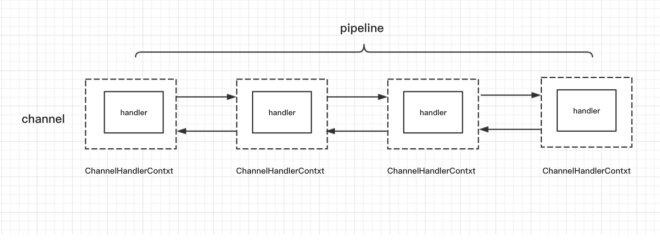
在Netty 框架中,一个连接对应着一个Channel, 这个Channel 所有的处理逻辑都在一个 ChannelPipeline 的对象中, ChannelPipeline 是双向链表结构, 它和 管道是一一对应的.ChannelPipeline里面每个节点都是 ChannelHandlerContext对象,这个对象能 这个对象能够拿到和 Channel 相关的所有的上下文信息,然后这个对象包着一个重要的对象,那就是逻辑处理器ChannelHandler。
channelHandler 的分类
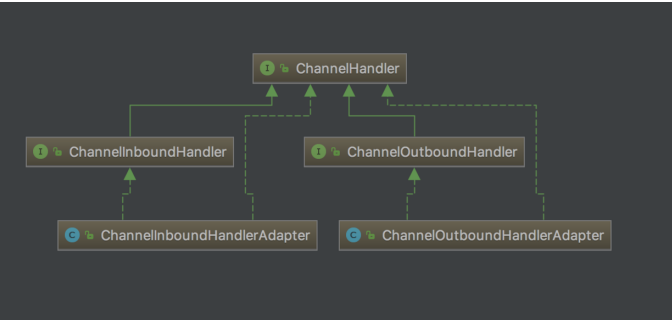
分为读写接口,和读写接口的实现类,继承实现类中的方法,会把读写方法传到下一个Handler
第一个子接口是 ChannelInboundHandler,从字面意思也可以猜到,他是处理读数据的逻辑,比如,我们 在一端读到一段数据,首先要解析这段数据,然后对这些数据做一系列逻辑处理,最终把响应写到对端, 在开 始组装响应之前的所有的逻辑,都可以放置在 ChannelInboundHandler 里处理,它的一个最重要的方法就 是 channelRead()。读者可以将 ChannelInboundHandler 的逻辑处理过程与 TCP 的七层协议的解析联 系起来,收到的数据一层层从物理层上升到我们的应用层。
第二个子接口 ChannelOutBoundHandler 是处理写数据的逻辑,它是定义我们一端在组装完响应之后,把 数据写到对端的逻辑,比如,我们封装好一个 response 对象,接下来我们有可能对这个 response 做一些其他 的特殊逻辑,然后,再编码成 ByteBuf,最终写到对端,它里面最核心的一个方法就是 write(),读者可以将 ChannelOutBoundHandler 的逻辑处理过程与 TCP 的七层协议的封装过程联系起来,我们在应用层组装响 应之后,通过层层协议的封装,直到最底层的物理层。
channelHandler-事件传播顺序
inBound 是按照添加顺序-顺序执行,outBound是按照添加顺序反向执行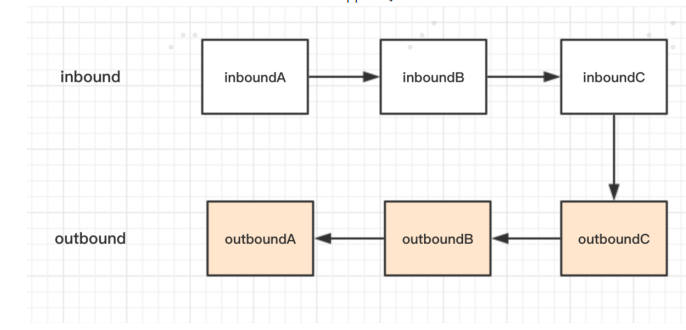
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {protected void initChannel(NioSocketChannel ch) {// inBound,处理读数据的逻辑链ch.pipeline().addLast(new InBoundHandlerA());ch.pipeline().addLast(new InBoundHandlerB());ch.pipeline().addLast(new InBoundHandlerC());// outBound,处理写数据的逻辑链ch.pipeline().addLast(new OutBoundHandlerA());ch.pipeline().addLast(new OutBoundHandlerB());ch.pipeline().addLast(new OutBoundHandlerC());}});//inBound类里 调用父类 super.channelRead(ctx, msg); 方法传递//outBound类里 调用父类 super.write(ctx, msg, promise); 方法传递public class InBoundHandlerA extends ChannelInboundHandlerAdapter {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throwsException {System.out.println("InBoundHandlerA: " + msg);super.channelRead(ctx, msg);}}public class OutBoundHandlerA extends ChannelOutboundHandlerAdapter {@Overridepublic void write(ChannelHandlerContext ctx, Object msg,ChannelPromise promise) throws Exception {System.out.println("OutBoundHandlerA: " + msg);super.write(ctx, msg, promise);}}
inBoundHandler 的事件 通常只会传播到下一个 inBoundHandler,outBoundHandler 的事件通常只会传播到下一个 outBoundHandler, 两者相互不受干扰。
实战: 构建客户端 与 服务端 pipeLine
Netty 内置了很多开箱即用的 ChannelHandler。下面,我们通过学习 Netty 内置的 ChannelHandler 来逐步构建 我们的 pipeline。
ChannelInboundHandlerAdapter 与ChannelOutboundHandlerAdapter
@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throwsException {//将handler 输出结果传递到下一个handlerctx.fireChannelRead(msg);}
@Overridepublic void write(ChannelHandlerContext ctx, Object msg, ChannelPromisepromise) throws Exception {ctx.write(msg, promise);}
ByteToMessageDecoder 解码类
public class PacketDecoder extends ByteToMessageDecoder {@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf in, List out) {out.add(PacketCodeC.INSTANCE.decode(in));}}
第三个参数为List ,第二个ByteBuf参数解码为对象,添加到list中
SimpleChannelInboundHandler 类型判断与对象传递
通过给 pipeline 添加多个 handler(ChannelInboundHandlerAdapter的子类) 来解决过多的 if else 问 题
if (packet instanceof XXXPacket) {// ...处理} else {ctx.fireChannelRead(packet);}
但有更优雅的方式,用SimpleChannelInboundHandler 来解决
public class LoginRequestHandler extends SimpleChannelInboundHandler<LoginRequestPacket> {@Overrideprotected void channelRead0(ChannelHandlerContext ctx, LoginRequestPacket loginRequestPacket) {// 登录逻辑}}
继承类时.给他传递一个泛型参数,然后channelRead0() 方法里面处理就好
MessageToByteEncoder 响应编码类
专门处理编码逻辑,我们不需要每一次将响应写到对端的时候调用一次编码逻辑进行编码,也不需要自行创建 ByteBuf,这个类叫做 MessageToByteEncoder,从字面意思也可以看出,它的功能就是将对象转换到二进制数据
public class PacketEncoder extends MessageToByteEncoder<Packet> {@Overrideprotected void encode(ChannelHandlerContext ctx, Packet packet, ByteBuf out) {PacketCodeC.INSTANCE.encode(out, packet);}}//PacketCodeC 定义也修改了public void encode(ByteBuf byteBuf, Packet packet) {// 1. 序列化 java 对象// 2. 实际编码过程}
PacketEncoder 继承自 MessageToByteEncoder,泛型参数 Packet 表示这个类的作用是实现 Packet 类型对象到二进制的转换。
使用方法: 将 第二个参数,写入到第三个参数中
实战: 拆包与沾包理论与解决
如果利用ByteBuf 直接传输数据不进行判断拆包,会存在数据粘包与粘包情况,输出情况如下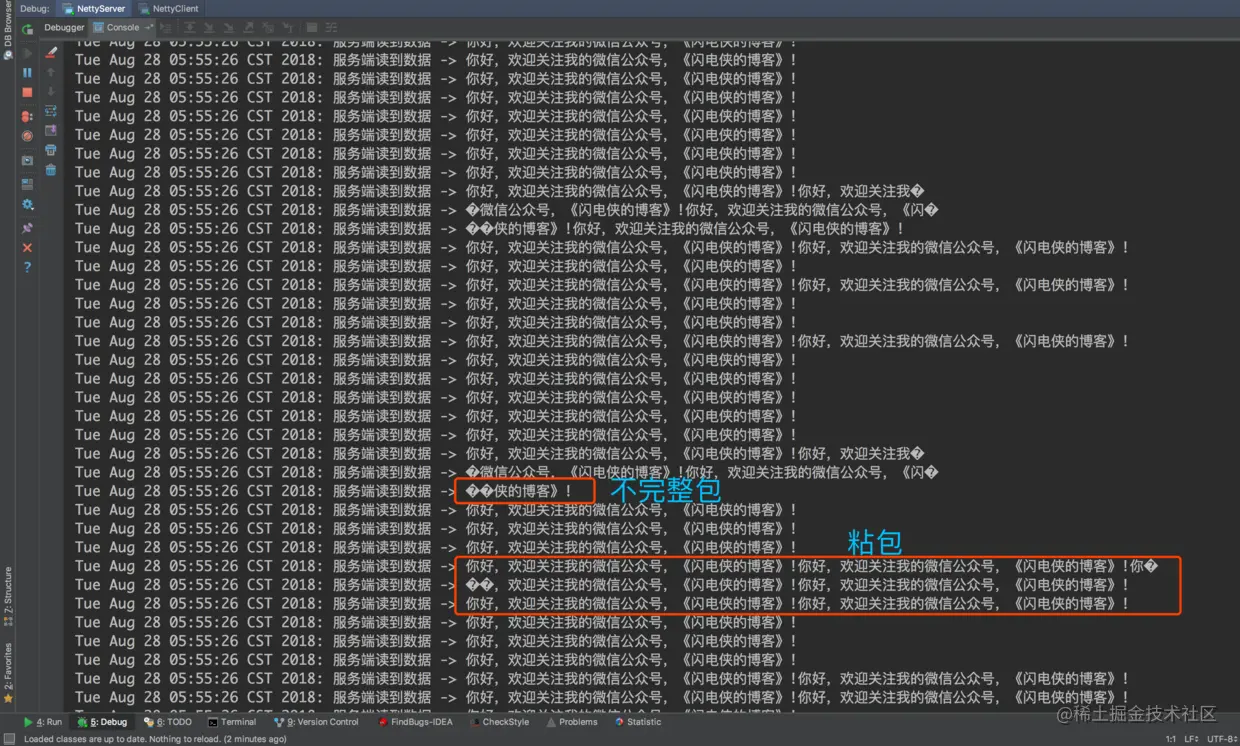
为什么会有粘包半包现象
尽管我们的应用 层是按照 ByteBuf 为 单位来发送数据,但是到了底层操作系统仍然是按照字节流发送数据,因此,数据到了服 务端,也是按照字节流的方式读入,然后到了 Netty 应用层面,重新拼装成 ByteBuf,而这里的 ByteBuf 与客户 端按顺序发送的 ByteBuf 可能是不对等的。
拆包的原理
在没有 Netty 的情况下,用户如果自己需要拆包,基本原理就是不断从 TCP 缓冲区中读取数据,每次读取完都需要判断是否是一个完整的数据包
- 如果当前读取的数据不足以拼接成一个完整的业务数据包,那就保留该数据,继续从 TCP 缓冲区中读取,直到得到一个完整的数据包。
- 如果当前读到的数据加上已经读取的数据足够拼接成一个数据包,那就将已经读取的数据拼接上本次读取的数据,构成一个完整的业务数据包传递到业务逻辑,多余的数据仍然保留,以便和下次读到的数据尝试拼接
自己实现拆包,会非常麻烦,netty自带的一些拆包工具已经足够我们使用了
Netty 自带的拆包器
1. 固定长度的拆包器 FixedLengthFrameDecoder
如果你的应用层协议非常简单,每个数据包的长度都是固定的,比如 100,那么只需要把这个拆包器加到 pipeline 中,Netty 会把一个个长度为 100 的数据包 (ByteBuf) 传递到下一个 channelHandler。
2. 行拆包器 LineBasedFrameDecoder
从字面意思来看,发送端发送数据包的时候,每个数据包之间以换行符作为分隔,接收端通过 LineBasedFrameDecoder 将粘过的 ByteBuf 拆分成一个个完整的应用层数据包。
3. 分隔符拆包器 DelimiterBasedFrameDecoder
DelimiterBasedFrameDecoder 是行拆包器的通用版本,只不过我们可以自定义分隔符。
4. 基于长度域拆包器 LengthFieldBasedFrameDecoder
最后一种拆包器是最通用的一种拆包器,只要你的自定义协议中包含长度域字段,均可以使用这个拆包器来实现应用层拆包。由于上面三种拆包器比较简单,读者可以自行写出 demo,接下来,
LengthFieldBasedFrameDecoder 的使用
回忆我们的自定义协议
- 在我们自定义协议中,我们长度域在数据包7位置上,专业术语来说就是长度域相对整个数 据包的偏移量是多少.
2.另外需要关注的就是,我们长度域的长度是多少,这里显然是 4。 有了长度域偏移量和长度域的长度, 我们就可以构造一个拆包器。
此类需要最大数据量\长度域偏移量\长度域长度
//构造一个拆包器new LengthFieldBasedFrameDecoder(Integer.MAX_VALUE, 7, 4);// 使用时只需要再pipeline的最前面加上这个拆包器ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(Integer.MAX_VALUE,7, 4));
拒绝本协议连接
继承自 LengthFieldBasedFrameDecoder 的 decode() 方 法,然后在 decode 之前判断前四个字节是否是等于我们定义的魔数 0x12345678
//继承类public class Spliter extends LengthFieldBasedFrameDecoder {private static final int LENGTH_FIELD_OFFSET = 7;private static final int LENGTH_FIELD_LENGTH = 4;public Spliter() {super(Integer.MAX_VALUE, LENGTH_FIELD_OFFSET, LENGTH_FIELD_LENGTH);}@Overrideprotected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {// 屏蔽非本协议的客户端if (in.getInt(in.readerIndex()) != PacketCodeC.MAGIC_NUMBER) {ctx.channel().close();return null;}return super.decode(ctx, in);}}//在责任链中替换一下 ,替换为//ch.pipeline().addLast(newLengthFieldBasedFrameDecoder(Integer.MAX_VALUE, 7, 4));ch.pipeline().addLast(new Spliter());
channelHandler 的声明周期(回调方法)
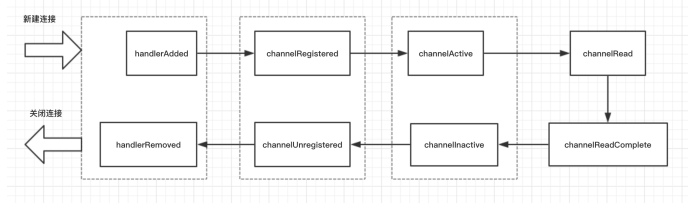
Channel 建立连接的生命周期
ChannelHandler 回调方法的执行顺序为 handlerAdded() -> channelRegistered() -> channelActive() -> channelRead() -> channelReadComplete()
- handlerAdded : 指的是当检测到新连接之后,调用
ch.pipeline().addLast(new LifeCyCleTestHandler()); 之后的回调, - channelRegistered : ,表示当前的 channel 的所有的逻辑处理已经和某个 NIO 线程 建立了绑定关系,
- channelActive 当 channel 的所有的业务逻辑链准备完毕(也就是说 channel 的 pipeline 中已经添 加完所有的 handler)以及绑定好一个 NIO 线程之后,这条连接算是真正激活了,接下来就会回调到此方 法。
- channelRead(): 客户端向服务端发来数据,每次都会回调此方法,表示有数据可读。
channelReadComplete():服务端每次读完一次完整的数据之后,回调该方法,表示数据读取完毕。
Channel 关闭连接的声明周期
channelInactive() -> channelUnregistered() -> handlerRemoved()
channelInactive(): 表面这条连接已经被关闭了,这条连接在 TCP 层面已经不再是 ESTABLISH 状 态了
- channelUnregistered(): 既然连接已经被关闭,那么与这条连接绑定的线程就不需要对这条连接负 责了,这个回调就表明与这条连接对应的 NIO 线程移除掉对这条连接的处理
handlerRemoved():最后,我们给这条连接上添加的所有的业务逻辑处理器都给移除掉。
生命周期回调各方法用例
handlerAdded() 与 handlerRemoved()
可以用在一些资源的申请和释放
channelActive() 与 channelInActive()
- 对我们的应用程序来说,这两个方法表明的含义是 TCP 连接的建立与释放,通常我们在这两个回调里面 统计单机的连接数,channelActive() 被调用,连接数加一,channelInActive() 被调用,连接 数减一
- 另外,我们也可以在 channelActive() 方法中,实现对客户端连接 ip 黑白名单的过滤,具体这里就 不展开了
- channelRead()
我们在前面小节讲拆包粘包原理,服务端根据自定义协议来进行拆包,其实就是在这个方法里面,每次读到一 定的数据,都会累加到一个容器里面,然后判断是否能够拆出来一个完整的数据包,如果够的话就拆了之后, 往下进行传递,
channelReadComplete()
我们在每次向客户端写数据的时候,都通过 writeAndFlush() 的方法写并刷新到底层,其实 这种方式不是特别高效,我们可以在之前调用 writeAndFlush() 的地方都调用 write() 方法,然后在这个 方面里面调用 ctx.channel().flush() 方法,相当于一个批量刷新的机制,当然,如果你对性能要求没那 么高,writeAndFlush() 足矣。
实战: 使用channelHandler 的热插拔实现客户端身份校验
定时发心跳怎么做
如何进行连接空闲检测

若有收获,就点个赞吧
0 人点赞
