如何学习使用
- 从 List 的操作开始,先尝试把遍历 List 来筛选数据和转换数据的操作,使用 Stream 的 filter 和 map 实现,这是 Stream 最常用、最基本的两个 API。你可以重点看 看接下来两节的内容来入门
- 利用IDea 配置检测规则,将匿名类型 使用 Lambda 替换的检测规则,设置为 Error 级别严 重程度:
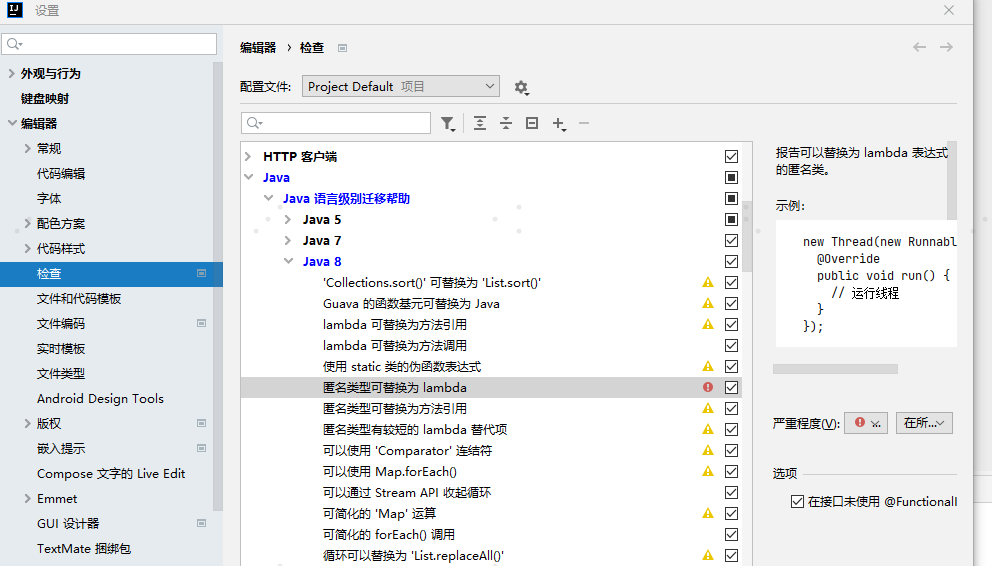
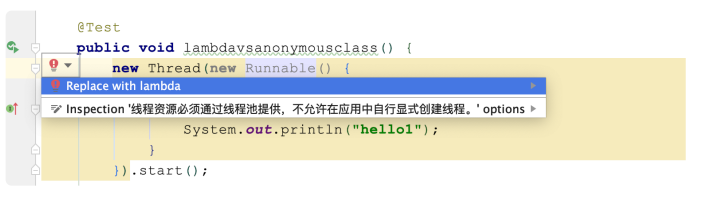
- 如果你不知道如何把匿名类转换为 Lambda 表达式,可以借助 IDE 来重构:
lambda 表达式
简化匿名类的语法, 使 Java 走向函数式编程。对于匿名类,虽然没有类名,但还是要给 出方法定义。
//匿名类new Thread(new Runnable(){@Overridepublic void run(){System.out.println("hello1");}}).start();//Lambda表达式new Thread(() -> System.out.println("hello2")).start();
,Lambda 表达式通过 函数式接口 匹配 Java 的类型系统
函数式接口
java.util.function 包中定义了各种函数式接口。
函数式接口是一种只有单一抽象方法的接口,使用 @FunctionalInterface 来描述,可以隐 式地转换成 Lambda 表达式。使用 Lambda 表达式来实现函数式接口,不需要提供类名和 方法定义,通过一行代码提供函数式接口的实例,就可以让函数成为程序中的头等公民,可 以像普通数据一样作为参数传递,而不是作为一个固定的类中的固定方法。
@FunctionalInterfacepublic interface Supplier<T> {/*** Gets a result.** @return a result*/T get();}//以使用 Lambda 表达式或方法引用,来得到 Supplier 接口的实例://使用Lambda表达式提供Supplier接口实现,返回OK字符串Supplier<String> stringSupplier = ()->"OK";//使用方法引用提供Supplier接口实现,返回空字符串Supplier<String> supplier = String::new;
Predicate、Function 等函数式接口,还使用 default 关键字实现了几个默认方法。这样一 来,它们既可以满足函数式接口只有一个抽象方法,又能为接口提供额外的功能:
@FunctionalInterfacepublic interface Function<T, R> {R apply(T t);default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {Objects.requireNonNull(before);return (V v) -> apply(before.apply(v));}default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {Objects.requireNonNull(after);return (T t) -> after.apply(apply(t));}static <T> Function<T, T> identity() {return t -> t;}}
方法引用 ::
::调用 已经存在的方法
Stream 简化集合操作
- map 方法传入的是一个 Function,可以实现对象转换;
- filter 方法传入一个 Predicate,实现对象的布尔判断,只保留返回 true 的数据;
- mapToDouble 用于把对象转换为 double;
- 通过 average 方法返回一个 OptionalDouble,代表可能包含值也可能不包含值的可空 double。
Optional 简化判空逻辑
类似 OptionalDouble、OptionalInt、OptionalLong 等,是服务于基本类型的可 空对象。此外,Java8 还定义了用于引用类型的 Optional 类。使用 Optional,不仅可以 避免使用 Stream 进行级联调用的空指针问题;更重要的是,它提供了一些实用的方法帮我 们避免判空逻辑。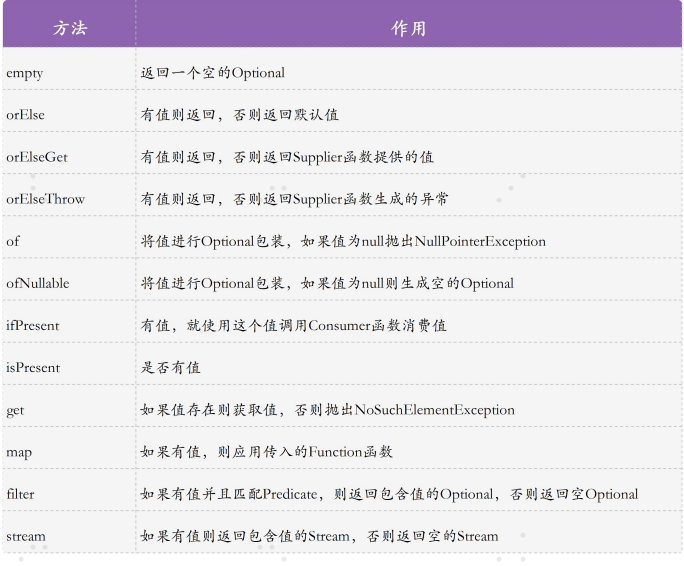
并行流操作
通过 parallel 方法,一键把 Stream 转换为并行操作提交到线程 池处理。
```java
IntStream.rangeClosed(1,100).parallel().forEach(i->{ System.out.println(LocalDateTime.now() + “ : “ + i); try { Thread.sleep(1000); } catch (InterruptedException e) { } });
<a name="JfaQ1"></a>### 多线程操作常用的五种实现方式:一般而言,使用线程池(第二种)和直接使用并行流(第四种)的方式在业务代码中比较常用。但需要注意的是,我们通常会重用线程池,而不会像 Demo 中那样在业务逻辑中直接声明新的线程池,等操作完成后再关闭。<a name="yCHt3"></a>#### 一:使用线程。直接把任务按照线程数均匀分割,分配到不同的线程执行,使用 CountDownLatch 来阻塞主线程,直到所有线程都完成操作```javaprivate int thread(int taskCount, int threadCount) throws InterruptedException {//总操作次数计数器AtomicInteger atomicInteger = new AtomicInteger();//使用CountDownLatch来等待所有线程执行完成CountDownLatch countDownLatch = new CountDownLatch(threadCount);//使用IntStream把数字直接转为ThreadIntStream.rangeClosed(1, threadCount).mapToObj(i -> new Thread(() -> {//手动把taskCount分成taskCount份,每一份有一个线程执行IntStream.rangeClosed(1, taskCount / threadCount).forEach(j -> increment(atomicInteger));//每一个线程处理完成自己那部分数据之后,countDown一次countDownLatch.countDown();})).forEach(Thread::start);//等到所有线程执行完成countDownLatch.await();//查询计数器当前值return atomicInteger.get();}
二: 使用 Executors.newFixedThreadPool 来获得固定线程数的线程池,使用 execute 提交所有任务到线程池执行,最后关闭线程池等待所有任务执行完成:
private int threadpool(int taskCount, int threadCount) throws InterruptedException {//总操作次数计数器AtomicInteger atomicInteger = new AtomicInteger();//初始化一个线程数量=threadCount的线程池ExecutorService executorService = Executors.newFixedThreadPool(threadCount);//所有任务直接提交到线程池处理IntStream.rangeClosed(1, taskCount).forEach(i -> executorService.execute(() -> increment(atomicInteger)));//提交关闭线程池申请,等待之前所有任务执行完成executorService.shutdown();executorService.awaitTermination(1, TimeUnit.HOURS);//查询计数器当前值return atomicInteger.get();}
三: 使用 ForkJoinPool 而不是普通线程池执行任务。
ForkJoinPool 和传统的 ThreadPoolExecutor 区别在于,前者对于 n 并行度有 n 个独立队列,后者是共享队列。如果有大量执行耗时比较短的任务,ThreadPoolExecutor 的单队列就可能会成为瓶颈。这时,使用 ForkJoinPool 性能会更好。因此,ForkJoinPool 更适合大任务分割成许多小任务并行执行的场景,而 ThreadPoolExecutor 适合许多独立任务并发执行的场景。
private int forkjoin(int taskCount, int threadCount) throws InterruptedException {//总操作次数计数器AtomicInteger atomicInteger = new AtomicInteger();//自定义一个并行度=threadCount的ForkJoinPoolForkJoinPool forkJoinPool = new ForkJoinPool(threadCount);//所有任务直接提交到线程池处理forkJoinPool.execute(() -> IntStream.rangeClosed(1, taskCount).parallel().forEach(i -> increment(atomicInteger)));//提交关闭线程池申请,等待之前所有任务执行完成forkJoinPool.shutdown();forkJoinPool.awaitTermination(1, TimeUnit.HOURS);//查询计数器当前值return atomicInteger.get();}
四:直接使用并行流,并行流使用公共的 ForkJoinPool,也就是 ForkJoinPool.commonPool()。
公共的 ForkJoinPool 默认的并行度是 CPU 核心数 -1,原因是对于 CPU 绑定的任务分配超过 CPU 个数的线程没有意义。由于并行流还会使用主线程执行任务,也会占用一个 CPU 核心,所以公共 ForkJoinPool 的并行度即使 -1 也能用满所有 CPU 核心。这里,我们通过配置强制指定(增大)了并行数,但因为使用的是公共 ForkJoinPool,所以可能会存在干扰,你可以回顾下第 3 讲有关线程池混用产生的问题:
private int stream(int taskCount, int threadCount) {//设置公共ForkJoinPool的并行度System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", String.valueOf(threadCount));//总操作次数计数器AtomicInteger atomicInteger = new AtomicInteger();//由于我们设置了公共ForkJoinPool的并行度,直接使用parallel提交任务即可IntStream.rangeClosed(1, taskCount).parallel().forEach(i -> increment(atomicInteger));//查询计数器当前值return atomicInteger.get();}
五: 使用 CompletableFuture 来实现。CompletableFuture.runAsync 方法可 以指定一个线程池,一般会在使用 CompletableFuture 的时候用到:
private int completableFuture(int taskCount, int threadCount) throws InterruptedException, ExecutionException {//总操作次数计数器AtomicInteger atomicInteger = new AtomicInteger();//自定义一个并行度=threadCount的ForkJoinPoolForkJoinPool forkJoinPool = new ForkJoinPool(threadCount);//使用CompletableFuture.runAsync通过指定线程池异步执行任务CompletableFuture.runAsync(() -> IntStream.rangeClosed(1, taskCount).parallel().forEach(i -> increment(atomicInteger)), forkJoinPool).get();//查询计数器当前值return atomicInteger.get();}
Stream 操作
Stream 操作汇总
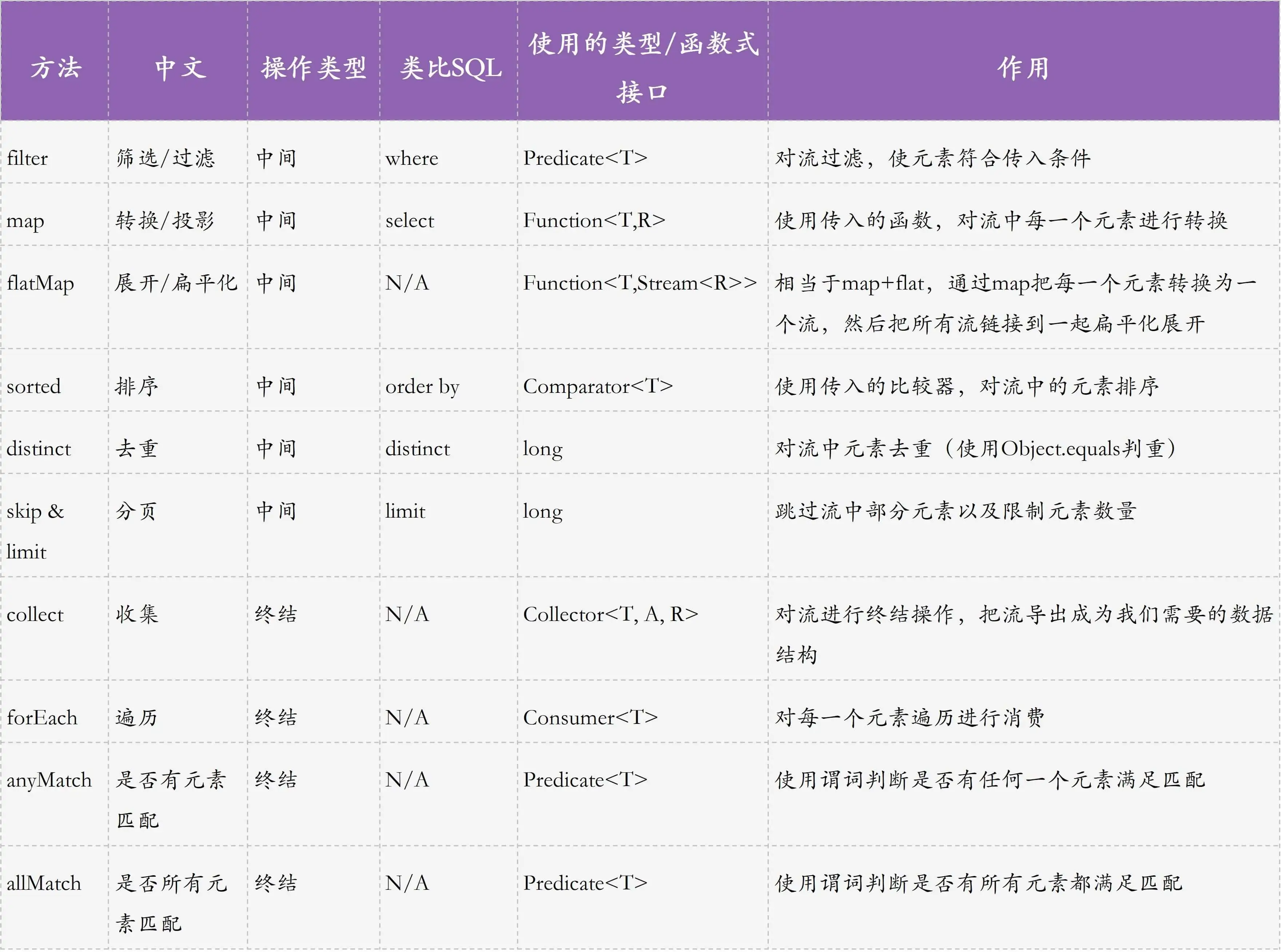
创建流
要使用流-需要先创建流,创建流一般有五种方式
- 通过 stream 方法把 List 或数组转换为流;
- 通过 Stream.of 方法直接传入多个元素构成一个流;
- 通过 Stream.iterate 方法使用迭代的方式构造一个无限流,然后使用 limit 限制流元素个数
- 通过 Stream.generate 方法从外部传入一个提供元素的 Supplier 来构造无限流,然后使用 limit 限制流元素个数;
- 通过 IntStream 或 DoubleStream 构造基本类型的流。 ```java
//通过stream方法把List或数组转换为流 @Test public void stream() { Arrays.asList(“a1”, “a2”, “a3”).stream().forEach(System.out::println); Arrays.stream(new int[]{1, 2, 3}).forEach(System.out::println); }
//通过Stream.of方法直接传入多个元素构成一个流 @Test public void of() { String[] arr = {“a”, “b”, “c”}; Stream.of(arr).forEach(System.out::println); Stream.of(“a”, “b”, “c”).forEach(System.out::println); Stream.of(1, 2, “a”).map(item -> item.getClass().getName()).forEach(System.out::println); }
//通过Stream.iterate方法使用迭代的方式构造一个无限流,然后使用limit限制流元素个数 @Test public void iterate() { Stream.iterate(2, item -> item * 2).limit(10).forEach(System.out::println); Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.TEN)).limit(10).forEach(System.out::println); }
//通过Stream.generate方法从外部传入一个提供元素的Supplier来构造无限流,然后使用limit限制流元素个数 @Test public void generate() { Stream.generate(() -> “test”).limit(3).forEach(System.out::println); Stream.generate(Math::random).limit(10).forEach(System.out::println); }
//通过IntStream或DoubleStream构造基本类型的流 @Test public void primitive() { //演示IntStream和DoubleStream IntStream.range(1, 3).forEach(System.out::println); IntStream.range(0, 3).mapToObj(i -> “x”).forEach(System.out::println);
IntStream.rangeClosed(1, 3).forEach(System.out::println);DoubleStream.of(1.1, 2.2, 3.3).forEach(System.out::println);//各种转换,后面注释代表了输出结果System.out.println(IntStream.of(1, 2).toArray().getClass()); //class [ISystem.out.println(Stream.of(1, 2).mapToInt(Integer::intValue).toArray().getClass()); //class [ISystem.out.println(IntStream.of(1, 2).boxed().toArray().getClass()); //class [Ljava.lang.Object;System.out.println(IntStream.of(1, 2).asDoubleStream().toArray().getClass()); //class [DSystem.out.println(IntStream.of(1, 2).asLongStream().toArray().getClass()); //class [J//注意基本类型流和装箱后的流的区别Arrays.asList("a", "b", "c").stream() // Stream<String>.mapToInt(String::length) // IntStream.asLongStream() // LongStream.mapToDouble(x -> x / 10.0) // DoubleStream.boxed() // Stream<Double>.mapToLong(x -> 1L) // LongStream.mapToObj(x -> "") // Stream<String>.collect(Collectors.toList());
}
<a name="bBSoc"></a>### Filter 过滤filter 方法可以实现过滤操作,类似 SQL 中的 where。```java//最近半年的金额大于40的订单orders.stream().filter(Objects::nonNull) //过滤null值.filter(order -> order.getPlacedAt().isAfter(LocalDateTime.now().minusMonths(6))) //最近半年的订单.filter(order -> order.getTotalPrice() > 40) //金额大于40的订单.forEach(System.out::println);
map 转换
map 操作可以做转换(或者说投影),类似 SQL 中的 select。为了对比,我用两种方式统计订单中所有商品的数量,前一种是通过两次遍历实现,后一种是通过两次 mapToLong+sum 方法实现:
//计算所有订单商品数量//通过两次遍历实现LongAdder longAdder = new LongAdder();orders.stream().forEach(order ->order.getOrderItemList().forEach(orderItem -> longAdder.add(orderItem.getProductQuantity())));//使用两次mapToLong+sum方法实现assertThat(longAdder.longValue(), is(orders.stream().mapToLong(order ->order.getOrderItemList().stream().mapToLong(OrderItem::getProductQuantity).sum()).sum()));
flatMap 扁平化操作
相当于 map+flat,通过 map 把每一个元素替换为一个流,然后展开这个流。
//直接展开订单商品进行价格统计System.out.println(orders.stream().flatMap(order -> order.getOrderItemList().stream()).mapToDouble(item -> item.getProductQuantity() * item.getProductPrice()).sum());//另一种方式flatMap+mapToDouble=flatMapToDoubleSystem.out.println(orders.stream().flatMapToDouble(order ->order.getOrderItemList().stream().mapToDouble(item -> item.getProductQuantity() * item.getProductPrice())).sum());
sorted 行内排序
sorted 操作可以用于行内排序的场景,类似 SQL 中的 order by。比如,要实现大于 50 元订单的按价格倒序取前 5,可以通过 Order::getTotalPrice 方法引用直接指定需要排序的依据字段,通过 reversed() 实现倒序:
//大于50的订单,按照订单价格倒序前5orders.stream().filter(order -> order.getTotalPrice() > 50).sorted(comparing(Order::getTotalPrice).reversed()).limit(5).forEach(System.out::println);
distinct 去重
distinct 操作的作用是去重,类似 SQL 中的 distinct。比如下面的代码实现:查询去重后的下单用户。使用 map 从订单提取出购买用户,然后使用 distinct 去重。查询购买过的商品名。使用 flatMap+map 提取出订单中所有的商品名,然后使用 distinct 去重。
//去重的下单用户System.out.println(orders.stream().map(order -> order.getCustomerName()).distinct().collect(joining(",")));//所有购买过的商品System.out.println(orders.stream().flatMap(order -> order.getOrderItemList().stream()).map(OrderItem::getProductName).distinct().collect(joining(",")));
skip & limit 用于分页
skip 和 limit 操作用于分页,类似 MySQL 中的 limit。其中,skip 实现跳过一定的项,limit 用于限制项总数。
collect 收集操作
collect 是收集操作,对流进行终结(终止)操作,把流导出为我们需要的数据结构。“终结”是指,导出后,无法再串联使用其他中间操作,比如 f**ilter、map、flatmap、sorted、distinct、limit、skip**。在 Stream 操作中,collect 是最复杂的终结操作,比较简单的终结操作还有 **forEach、toArray、min、max、count、anyMatch** 等,我就不再展开了,你可以查询JDK 文档,搜索 terminal operation 或 intermediate operation。<br />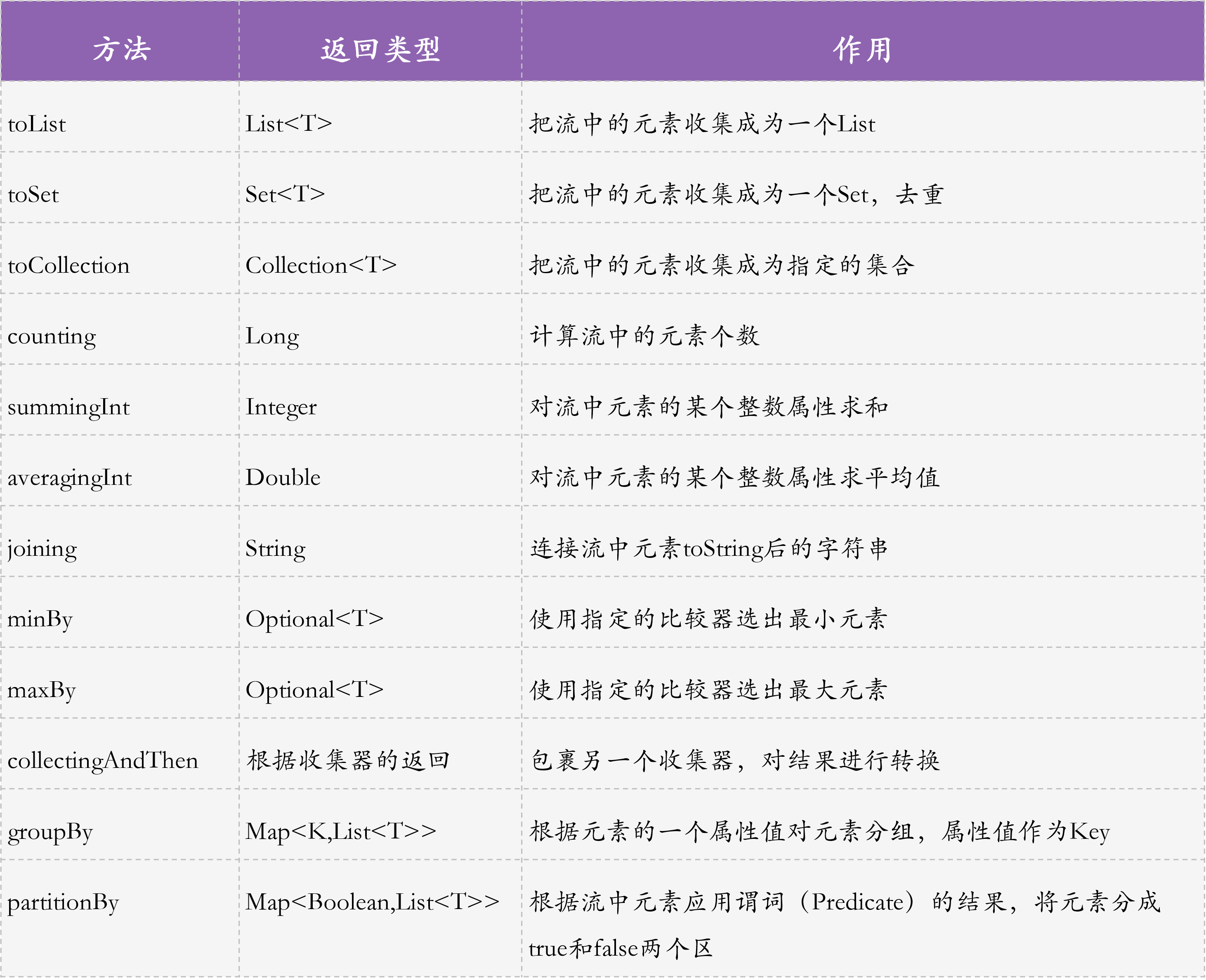
groupBy
groupBy 是分组统计操作,类似 SQL 中的 group by 子句。它和后面介绍的 partitioningBy 都是特殊的收集器,同样也是终结操作。分组操作比较复杂,
//按照用户名分组,统计下单数量System.out.println(orders.stream().collect(groupingBy(Order::getCustomerName, counting())).entrySet().stream().sorted(Map.Entry.<String, Long>comparingByValue().reversed()).collect(toList()));//按照用户名分组,统计订单总金额System.out.println(orders.stream().collect(groupingBy(Order::getCustomerName, summingDouble(Order::getTotalPrice))).entrySet().stream().sorted(Map.Entry.<String, Double>comparingByValue().reversed()).collect(toList()));//按照用户名分组,统计商品采购数量System.out.println(orders.stream().collect(groupingBy(Order::getCustomerName,summingInt(order -> order.getOrderItemList().stream().collect(summingInt(OrderItem::getProductQuantity))))).entrySet().stream().sorted(Map.Entry.<String, Integer>comparingByValue().reversed()).collect(toList()));//统计最受欢迎的商品,倒序后取第一个orders.stream().flatMap(order -> order.getOrderItemList().stream()).collect(groupingBy(OrderItem::getProductName, summingInt(OrderItem::getProductQuantity))).entrySet().stream().sorted(Map.Entry.<String, Integer>comparingByValue().reversed()).map(Map.Entry::getKey).findFirst().ifPresent(System.out::println);//统计最受欢迎的商品的另一种方式,直接利用maxByorders.stream().flatMap(order -> order.getOrderItemList().stream()).collect(groupingBy(OrderItem::getProductName, summingInt(OrderItem::getProductQuantity))).entrySet().stream().collect(maxBy(Map.Entry.comparingByValue())).map(Map.Entry::getKey).ifPresent(System.out::println);//按照用户名分组,选用户下的总金额最大的订单orders.stream().collect(groupingBy(Order::getCustomerName, collectingAndThen(maxBy(comparingDouble(Order::getTotalPrice)), Optional::get))).forEach((k, v) -> System.out.println(k + "#" + v.getTotalPrice() + "@" + v.getPlacedAt()));//根据下单年月分组,统计订单ID列表System.out.println(orders.stream().collect(groupingBy(order -> order.getPlacedAt().format(DateTimeFormatter.ofPattern("yyyyMM")),mapping(order -> order.getId(), toList()))));//根据下单年月+用户名两次分组,统计订单ID列表System.out.println(orders.stream().collect(groupingBy(order -> order.getPlacedAt().format(DateTimeFormatter.ofPattern("yyyyMM")),groupingBy(order -> order.getCustomerName(),mapping(order -> order.getId(), toList())))));
partitionBy
partitioningBy 用于分区,分区是特殊的分组,只有 true 和 false 两组。比如,我们把用户按照是否下单进行分区,给 partitioningBy 方法传入一个 Predicate 作为数据分区的区分,输出是 Map
public static <T>Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {return partitioningBy(predicate, toList());}
测试一下,partitioningBy 配合 anyMatch,可以把用户分为下过订单和没下过订单两组
//根据是否有下单记录进行分区System.out.println(Customer.getData().stream().collect(partitioningBy(customer -> orders.stream().mapToLong(Order::getCustomerId).anyMatch(id -> id == customer.getId()))));
流式编程如何测试
debug 工具窗口如何打开 ⌘ 5
此功能仅对项目文件可用。Java Stream调试器不能使用库或反编译代码。
- 在函数式编程中打断点
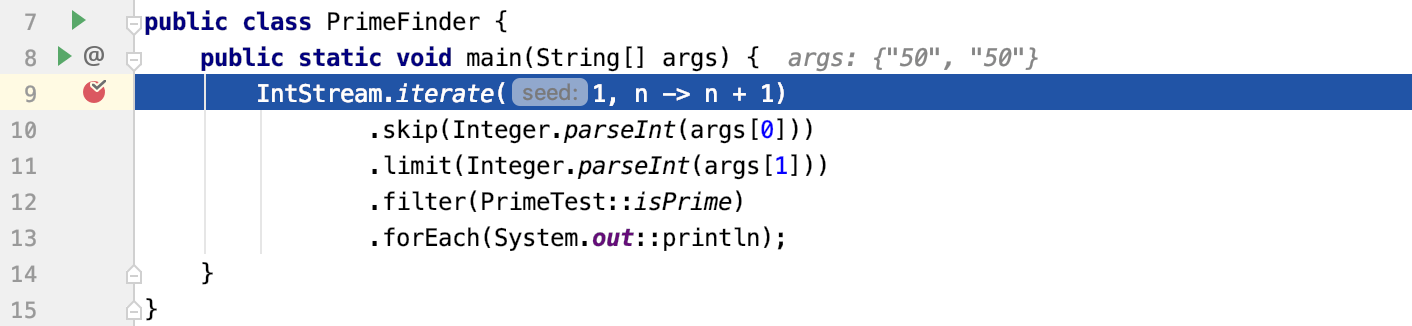
- 在调试工具窗口中单击“跟踪当前流链”按钮。
- 使用流跟踪对话框来分析流内部的操作。顶部的选项卡允许您在特定操作之间切换,并查看值如何随每个操作进行转换。
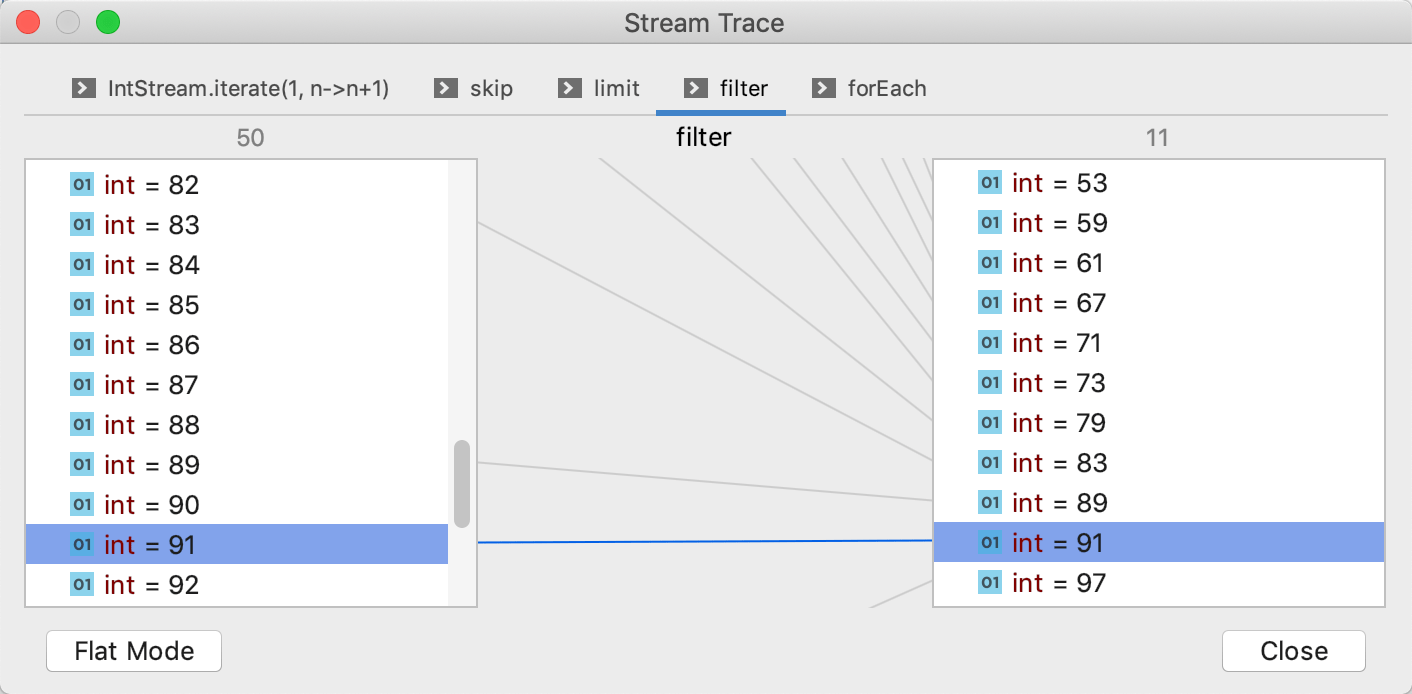

若有收获,就点个赞吧
0 人点赞
