脑图
代码篇
并发工具类
总结:
- 只知道使用并发工具,但并不清楚当前线程的来龙去脉,解决多线程问题却不了解线 程。比如,使用 ThreadLocal 来缓存数据,以为 ThreadLocal 在线程之间做了隔离不会有 线程安全问题,没想到线程重用导致数据串了。请务必记得,在业务逻辑结束之前清理 ThreadLocal 中的数据。
- 误以为使用了并发工具就可以解决一切线程安全问题,期望通过把线程不安全的类替 换为线程安全的类来一键解决问题。比如,认为使用了 ConcurrentHashMap 就可以解决 线程安全问题,没对复合逻辑加锁导致业务逻辑错误。如果你希望在一整段业务逻辑中,对 容器的操作都保持整体一致性的话,需要加锁处理。
- 没有充分了解并发工具的特性,还是按照老方式使用新工具导致无法发挥其性能。比 如,使用了 ConcurrentHashMap,但没有充分利用其提供的基于 CAS 安全的方法,还是 使用锁的方式来实现逻辑。你可以阅读一下ConcurrentHashMap 的文档,看一下相关 原子性操作 API 是否可以满足业务需求,如果可以则优先考虑使用。
没有了解清楚工具的适用场景,在不合适的场景下使用了错误的工具导致性能更差。 比如,没有理解 CopyOnWriteArrayList 的适用场景,把它用在了读写均衡或者大量写操 作的场景下,导致性能问题。对于这种场景,你可以考虑是用普通的 List。
锁
关注锁的粒度,避免粒度过大影响性能,
synchronized 锁的等级: 方法锁 > 实例锁 > 类锁
使用 synchronized 加锁虽然简单,但我们首先要弄清楚共享资源是类还是实例级别 的、会被哪些线程操作,synchronized 关联的锁对象或方法又是什么范围的。
- 加锁尽可能要考虑粒度和场景,锁保护的代码意味着无法进行多线程操作。对于 Web 类型的天然多线程项目,对方法进行大范围加锁会显著降级并发能力,要考虑尽可能 地只为必要的代码块加锁,降低锁的粒度;而对于要求超高性能的业务,还要细化考虑锁的 读写场景,以及悲观优先还是乐观优先,尽可能针对明确场景精细化加锁方案,可以在适当 的场景下考虑使用 ReentrantReadWriteLock、StampedLock 等高级的锁工具类。
- ,业务逻辑中有多把锁时要考虑死锁问题,通常的规避方案是,避免无限等待和循环等 待。 此外,如果业务逻辑中锁的实现比较复杂的话,要仔细看看加锁和释放是否配对,是否有遗 漏释放或重复释放的可能性;并且要考虑锁自动超时释放了,而业务逻辑却还在进行的情况 下,如果别的线线程或进程拿到了相同的锁,可能会导致重复执行。 你可能更容易忽略这点,并且也可能因为误用锁降低应用整体的吞吐。如果你的业务代 码涉及复杂的锁操作,强烈建议 Mock 相关外部接口或数据库操作后对应用代码进行压 测,通过压测排除锁误用带来的性能问题和死锁问题。
线程池
- Executors 类提供的一些快捷声明线程池的方法虽然简单,但隐藏了线程池的参数细 节。因此,使用线程池时,我们一定要根据场景和需求配置合理的线程数、任务队列、拒绝 策略、线程回收策略,并对线程进行明确的命名方便排查问题。
- 线程池的管理策略详情
- 不会初始化 corePoolSize 个线程,有任务来了才创建工作线程;
- 当核心线程满了之后不会立即扩容线程池,而是把任务堆积到工作队列中;
- 当工作队列满了后扩容线程池,一直到线程个数达到 maximumPoolSize 为止;
- 如果队列已满且达到了最大线程后还有任务进来,按照拒绝策略处理;
- 当线程数大于核心线程数时,线程等待 keepAliveTime 后还是没有任务需要处理的话, 收缩线程到核心线程数。
了解这些后: ,有助于我们根据实际的容量规划需求,为线程池设置合适的初始化参数。当 然,我们也可以通过一些手段来改变这些默认工作行为,比如:
- 声明线程池后立即调用 prestartAllCoreThreads 方法,来启动所有核心线程;
- 传入 true 给 allowCoreThreadTimeOut 方法,来让线程池在空闲的时候同样回收核心 线程
- 确认线程池本事是不是复用的
- 仔细斟酌线程池的混用策略
- 根据任务的“轻重缓急”来指定线程池的核心 参数,包括线程数、回收策略和任务队列
连接池
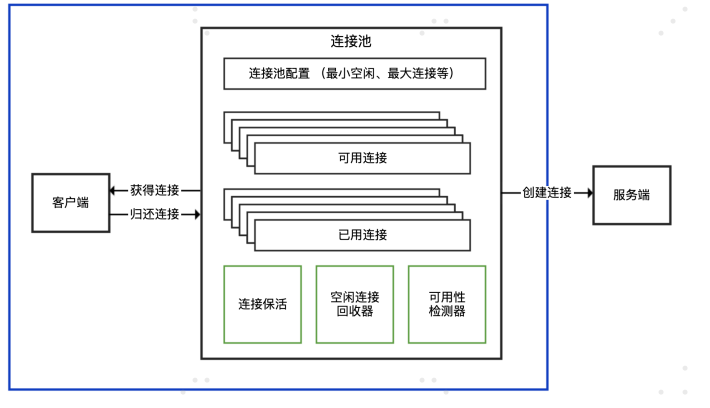
1.注意鉴别客户端SDK是否基于连接池
- 连接池和连接分离的 API: 有一个 XXXPool 类负责连接池实现,先从其获得连接 XXXConnection,然后用获得的连接进行服务端请求,完成后使用者需要归还连接。通 常,XXXPool 是线程安全的,可以并发获取和归还连接,而 XXXConnection 是非线程 安全的。 对应到连接池的结构示意图中,XXXPool 就是右边连接池那个框,左边的客户 端是我们自己的代码。
- 内部带有连接池的 API: 对外提供一个 XXXClient 类,通过这个类可以直接进行服务端 请求;这个类内部维护了连接池,SDK 使用者无需考虑连接的获取和归还问题。一般而 言,XXXClient 是线程安全的。对应到连接池的结构示意图中,整个 API 就是蓝色框包 裹的部分。
非连接池的 API: 一般命名为 XXXConnection,以区分其是基于连接池还是单连接的, 而不建议命名为 XXXClient 或直接是 XXX。直接连接方式的 API 基于单一连接,每次使 用都需要创建和断开连接,性能一般,且通常不是线程安全的。对应到连接池的结构示 意图中,这种形式相当于没有右边连接池那个框,客户端直接连接服务端创建连接。
2.注意连接池是否复用,尽可能在程序退出之前显式关闭连接池释放资源
3. 连接池配置根据使用更新
注意配置参数务必验证是否生效 , 并且在监控系统中确认参数是否生效、
- 对类似数据库连接池的重 要资源进行持续检测,并设置一半的使用量作为报警阈值,出现预警后及时扩容。
HTTP调用: 超时\重试\并发
配置连接超时参数
对于 HTTP 调用,虽然应用层走的是 HTTP 协议,但网络层面始终是 TCP/IP 协议。 TCP/IP 是面向连接的协议,在传输数据之前需要建立连接。几乎所有的网络框架都会提供 这么两个超时参数:
连接超时参数 ConnectTimeout,让用户配置建连阶段的最长等待时间;
读取超时参数 ReadTimeout,用来控制从 Socket 上读取数据的最长等待时间。
常见使用误区:
连接超时:
- 连接超时配置得特别长,比如 60 秒
- 排查连接超时问题,却没理清连的是哪里
读取超时参数与读取超时:
- 出现读取超时,服务端执行就会中断
- 为读取超时只是 Socket 网络层面的概念,是数据传输的最长耗时,故将其 配置得非常短,比如 100 毫秒。 实际上 大部分代表是服务端处理业务逻辑的时间
- 认为超时时间越长任务接口成功率就越高,将读取超时参数配置得太长。
Feign 和 Ribbon 配合使用
Feign 默认读取超时是一秒,一般建议修改
//如果只单独配置读取超时,并不会生效feign.client.config.default.readTimeout=3000feign.client.config.default.connectTimeout=3000//为单独的Feign Client设置超时时间,把 default 替换为Client 的 namefeign.client.config.default.readTimeout=3000feign.client.config.default.connectTimeout=3000feign.client.config.clientsdk.readTimeout=2000feign.client.config.clientsdk.connectTimeout=2000
重试
对于重试,因为 HTTP 协议认为 Get 请求是数据查询操作,是无状态的,又考虑到网络出 现丢包是比较常见的事情,有些 HTTP 客户端或代理服务器会自动重试 Get/Head 请求。
Ribbon 配置参数优先级低于Fegin,Ribbon默认存在自动重试设置
ribbon.ReadTimeout=4000ribbon.ConnectTimeout=4000// 禁用服务调用失败后,自动重试ribbon.MaxAutoRetriesNextServer=0
HttpClient 默认设置了最大并发
查看 PoolingHttpClientConnectionManager 源码,可以注意到有两个重要参数:
defaultMaxPerRoute=2,也就是同一个主机 / 域名的最大并发请求数为 2
maxTotal=20,也就是所有主机整体最大并发为 20
//例如配置:httpClient2 = HttpClients.custom().setMaxConnPerRoute(10).setMaxConnTotal(20).build();
Spring 声明式事务
@Transactional 生效原则
- 除非特殊配置(比如使用 AspectJ 静态织入实现 AOP),否则只有定义在 public 方法上的 @Transactional 才能生效
-
事务即便生效也不一定回滚
只有异常传播出了标记了 @Transactional 注解的方法,事务才能回滚。
- 自己方法内捕获异常时设置(手动请求回滚): TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
默认情况下,出现 RuntimeException(非受检异常)或 Error 的时候,Spring 才会回滚事务
事务中存父子逻辑,父子逻辑其实默认存在一个事务中,如果子逻辑出现异常,即使捕获.事务状态还会改变,整体事务无法提交.
- 让子逻辑在独立事务上运行
- 父逻辑捕获异常,防止异常传递导致主事务回滚 ```java //子逻辑 //为注解加上 propagation =Propagation.REQUIRES_NEW 来设置 REQUIRES_NEW 方式的事务传播策略, //执行到这个方法时需要开启新的事务,并挂起当前事务 @Transactional(propagation = Propagation.REQUIRES_NEW) public void createSubUserWithExceptionRight(UserEntity entity) { log.info(“createSubUserWithExceptionRight start”); userRepository.save(entity); throw new RuntimeException(“invalid status”); }
//父逻辑捕获异常 @Transactional public void createUserRight(UserEntity entity) { createMainUser(entity); try{ subUserService.createSubUserWithExceptionRight(entity); } catch (Exception ex) { // 捕获异常,防止主方法回滚 log.error(“create sub user error:{}”, ex.getMessage()); } }
<a name="iOdRf"></a>### 数据库索引Mysql将数据存储和查询操作抽象成了存储引擎,根据不同的存储引擎有不同的操作,我们现在比较流行使用InnDB引擎<br />InnDB引擎 引入**B+树**来保证快速查找数据, 分为** 聚簇索引** 和 **二级索引 **, **聚簇索引**索引保存的是行整体数据, **二级索引** 保存的是**聚簇索引 **位置,通过**二级索引** 查找**聚簇索引 **的过程 就是**回表, **为了保证查找速度,需要尽量避免回表操作.<a name="Add4B"></a>#### 二级索引的代价**维护代价:** 创建 N 个二级索引,就需要再创建 N 棵 B+ 树,新增数据时不仅要修改 聚簇索引,还需要修改这 N 个二级索引 <br />**空间代价:** 虽然二级索引不保存原始数据,但要保存索引列的数据,所以会占用更多 的空间。 <br />**回表代价:** 二级索引不保存原始数据,通过索引找到主键后需要再查询聚簇索引, 才能得到我们要的数据。<a name="cnjRm"></a>#### 索引开销使用建议** 第一,**无需一开始就建立索引,可以等到业务场景明确后,或者是数据量超过 1 万、查询 变慢后,再针对需要查询、排序或分组的字段创建索引。创建索引后可以使用 EXPLAIN 命 令,确认查询是否可以使用索引。我会在下一小节展开说明。 <br />**第二**,尽量索引轻量级的字段,比如能索引 int 字段就不要索引 varchar 字段。索引字段也 可以是部分前缀,在创建的时候指定字段索引长度。针对长文本的搜索,可以考虑使用 Elasticsearch 等专门用于文本搜索的索引数据库。<br />** 第三,**尽量不要在 SQL 语句中 SELECT *,而是 SELECT 必要的字段,甚至可以考虑使用联 合索引来包含我们要搜索的字段,既能实现索引加速,又可以避免回表的开销。<a name="jCAD5"></a>#### 索引使用失效情况** 第一,**索引只能匹配列前缀 <br />** 第二,**条件涉及函数操作无法走索引。<br /> **第三,**联合索引只能匹配左边的列。 <br />mysql 会自动计算查找成本来决定是否使用索引,如果觉得mysql 计算失误,可以用个` FORCE INDEX() ` 强制使用索引<br /> MySQL 5.6 及之后的版本中,我们可以使用 optimizer trace 功能查看优化器生成执行 计划的整个过程。如```java// 开启功能SET optimizer_trace="enabled=on";SELECT * FROM person WHERE NAME >'name84059' AND create_time>'2020-01-24 05:00SELECT * FROM information_schema.OPTIMIZER_TRACE;SET optimizer_trace="enabled=off";//关闭功能
判等问题
equals 和 == 的区别 , 针对基本类型只能 使用 ==,针对 Integer、String 在内的引用类型,需要使用 equals。Integer 和 String 的坑在于,使用 == 判等有时也能获得正确结果。
对于自定义类型,如果类型需要参与判等,那么务必同时实现 equals 和 hashCode 方法,并确保逻辑一致。如果希望快速实现 equals、hashCode 方法,我们可以借助 IDE 的代码生成功能,或使用 Lombok 来生成。如果类型也要参与比较,那么 compareTo 方 法的逻辑同样需要和 equals、hashCode 方法一致。
最后,Lombok 的 @EqualsAndHashCode 注解实现 equals 和 hashCode 的时候,默认 使用类型所有非 static、非 transient 的字段,且不考虑父类。如果希望改变这种默认行 为,可以使用 @EqualsAndHashCode.Exclude 排除一些字段,并设置 callSuper = true 来让子类的 equals 和 hashCode 调用父类的相应方法。
数值计算
第一,切记,要精确表示浮点数应该使用 BigDecimal。并且,使用 BigDecimal 的
Double 入参的构造方法同样存在精度丢失问题,应该使用 String 入参的构造方法或者
BigDecimal.valueOf 方法来初始化。
第二,对浮点数做精确计算,参与计算的各种数值应该始终使用 BigDecimal,所有的计算
都要通过 BigDecimal 的方法进行,切勿只是让 BigDecimal 来走过场。任何一个环节出现
精度损失,最后的计算结果可能都会出现误差。
第三,对于浮点数的格式化,如果使用 String.format 的话,需要认识到它使用的是四舍五
入,可以考虑使用 DecimalFormat 来明确指定舍入方式。但考虑到精度问题,我更建议使
用 BigDecimal 来表示浮点数,并使用其 setScale 方法指定舍入的位数和方式。
第四,进行数值运算时要小心溢出问题,虽然溢出后不会出现异常,但得到的计算结果是完
全错误的。我们考虑使用 Math.xxxExact 方法来进行运算,在溢出时能抛出异常,更建议
对于可能会出现溢出的大数运算使用 BigInteger 类。
集合类
数组转list集合
使用Arrays.asList把数据转换为List的坑
不能直接用Arrays.asList来转换基本类型
- 可以通过Arrays.stream 来转换
- int 转为Inter 类型
int[] arr = {1,2,3}List list = Arrays.asList(arr);//list 存储的元素为 int 数组,而不是int 类型//
Arrays.asList 返回的list 不支持增删改查操作
- Arrays.asList 返回的 List 并不是 我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList。ArrayList 内部类继承自 AbstractList 类,并没有覆写父类的 add 方法,而父类中 add 方法的实现,就是抛出 UnsupportedOperationException。
- 对原始数组的修改会影响到我们获取到的List
//通过New ArrayList 来修复List list = new ArrayList(Arrays.asList(arr))
对list进行切片操作会导致OOM
原因是sublist 返回的List 是强引用,导致list 一直无法被回收
修复方法:
- 不直接使用sublist返回的list,重新使用 new ArrayList,在构造函数中传入sublist 返回的list
使用 java8 中stream 的skip 和limit API来跳过流的中的元素,以及限制流中元素的个数,同样可以达到切片的目的
一定要让合适的数据结构做合适的事
误区:使用数据结构不考虑平衡时间与空间
例如: ArrayList get操作的复杂度是
O(n), Map get操作的复杂度是O(1)
但Map 的空间占用比 Arraylist 要大很多误区,过于迷信教科书的大 O 时间复杂度
抛开算法层面不谈,由于 CPU 缓存、内存连续性等问题,链表这种数 据结构的实现方式对性能并不友好,即使在它最擅长的场景都不一定可以发挥威力。
空值处理: null 与 空指针
日常排查空指针错误很困难,可以使用阿里云开源的Arthas ,定位java 生产问题
Arthas
watch 命令监控 方法的入参, 命令的参数包括类名表达式、方法表达式和观察表达式
stack 命令来查看 方法的调用栈空指针异常修复
最直白的方式是先判空后操作,但最常用的if else 会增加代码量,可以尝试利用Java 8的Option类来消除代替.
Optional.ofNullable(fooService).map(FooService::getBarService).filter(barService -> "OK".equals(barService.bar())).ifPresent(result -> log.info("OK"));
使用判空方式或 Optional 方式来避免出现空指针异常,不一定是解 决问题的最好方式,空指针没出现可能隐藏了更深的 Bug。因此,解决空指针异常,还是 要真正 case by case 地定位分析案例,然后再去做判空处理,而处理时也并不只是判断非 空然后进行正常业务流程这么简单,同样需要考虑为空的时候是应该出异常、设默认值还是 记录日志等。
POJO中属性的null 代表了什么
null 是指针没有任何指向,但结合业务逻辑会复杂很多
DTO 中字段的null 到底意味着什么,是客户端没有传么
- 为什么DTO 中字段要设默认值
如果数据库实体中的字段有null,那通过数据访问框架保存数据是否会覆盖数据库中的既有数据
<br /> <br /> <br /> <br />
日志
文件IO
序列化
java日期类
OOM问题
反射,注解,泛型 遇到OOP
spring框架
设计篇
安全篇
加餐

若有收获,就点个赞吧
0 人点赞
