- 项目介绍
- 基础网络
- 基础知识
- 编程语言
- 基础数学知识
- 面试问题
- 问题 1: Batch_norm的具体细节
- 问题 2:对于softmax出现exp的爆炸该如何处理?
- 问题 3:L1和L2 regulizer的区别?
- 问题 4:模型欠拟合的时候怎么处理?
- 问题 5EM算法?
- 问题 6 Dice loss?
- 问题 7 sigmoid求导以及证明?
- 问题 8 二分类交叉熵求导?
- 问题 9 最大似然估计和贝叶斯估计的联系和区别?
- 问题 10 Batch norm和GN的差别?
- 问题 11 VGG的参数量,如何计算参数量,计算量,举例说明?
- 问题 12 介绍一下resnet?
- 问题 13 实现一下hasmap?
- 问题 14 k-means过程?
- 问题 15 PCA过程?
- 问题 16 评价指标计算,为什么这样计算?
- 问题 17 常见的边缘检测(传统方式)?
- 问题 18 CNN卷积层全连接层参数量和计算量?
- 问题 19 NMS的IOU计算?
- 问题 1: Batch_norm的具体细节
项目介绍
1、亿保杯算法设计大赛
背景:
医疗单据上因为底板和打印字体重叠问题,造成了单据信息难以批量化收集,检测到的文本无法进行高效识别,容易识别错,干扰大。
初赛:
VGG11作为baseline的Unet作为分割网络直接分割重叠数字目标区域,IoU 达到 0.956。
Bce Loss 和 Dice Loss,在这两个loss上分别对不同文本区域进行加权优化,重叠文本区域与非重叠文本区域比值为8:2.
分割重叠数字到两个独立数字:Unet+BN 结构作为 baseline,达到加权 IoU 为 0.956。分析分割结果,主要是重叠交界处、数字边缘分割效果不佳,存在重叠面积较小的样本影响加权 IoU 评价指标的稳定性。
动态标签匹配:网络输出为 2 通道mask,计算 loss 前首先以 IoU 为指标对预测结果与目标mask 配对,可以加速网络的收敛速度。
复赛:
考虑到现实场景票据背景复杂,文本模糊难以进行准确分割,并且准确分割也并不是目的,识别收集单据信息才是最终目的,因此我们提出了分割识别集成网络。
- 将分割和识别网络集成一体化,引入RNN序列信息对分割网络进行寓意增强,模拟人的‘逻辑推理能力’整个网络只需要识别label不需要分割label。
- 整个网络分为两个部分:1、分割网络:通过下采样和上采样得到对应的segmentation maps 2、识别网络:利用LSTM引入序列信息,加强网络的特征优化提取。
- 该分割识别网络在我们人工合成的重叠文本数据集(数据集背景采样于现实单据,重叠单词收集于学术论文, 颜色随机,大小仿照现实场景文本进行重叠合成)上达到了0.95的准确率和200FPS。
2、TextCohesion: Detecting Text for Arbitrary Shapes**
背景:
任务描述:传统的基于回归和分割的文本检测器难以拟合任意形状的文本,使用实例分割网络去检测不规则形状的文本
创新点:
对每个文本实例进行建模,分为TS (Text Skeleton)和(DPR)Directional pixel regions
(1)、提出了两个概念TS (Text Skeleton)和(DPR)Directional pixel regions。首先利用TS完美的区分开两个文本实例,同时每个文本实例靠近边缘的边缘像素区域DPR向着各自的TS进行连接,完美分割开文本分界
线边缘的像素点。对单个文本实例不同区域的像素进行加权,距离TS越近权重越小,因为中心像素的置信度最高。
(2)、引入TS的confidence机制,对低概率的TS文本进行滤波操作,除去了大部分FP现象。
pipeline:
采用VGG16作为Backbone进行特征提取,经过卷积运算得到五个feature maps,然后进行从底层逐步进行反卷积融合直至采样到原尺寸。预测文本轮廓和四个方向的区域像素(上下左右)然后进行后处理操作得到最终的检测结果。
3、Texts as Lines: Text Detection with Weak Supervision
背景:
提出了一个基于弱监督的场景文本检测算法
创新点:
(1)、首次提出了基于弱监督学习的场景文本检测器,在损失微量精度的前提下极大的节约标注成本。
(2)、提出了一个改进的交叉熵loss可以对含有距离信息的soft label进行优化。
(3)、充分利用了在人工合成数据集上的预训练模型来增强弱监督label的标注信息。
Method:
1、 首先与其他检测网络不同的是该检测算法是weak label,具体到每一个文本即是一条随意画在文本区域的线。
2、 Label Enhancement:使用在人工合成数据集上的预训练模型进行增强获取部分我们丢失掉的边缘像素信息,具体就是用预训练模型在真实场景下的激活区域进行预测增强。
3、 Soft Label:为了使label增强和后处理更加精准快速,soft label被采用在我们算法中,指的是文本实例中的每个像素label不仅包含类别信息,也包含距离信息,即到背景的距离,文本最中心的像素label为1越靠近边缘越趋向于0。
实验分析:
我们在四个常用数据集上进行了对比实验的验证,精度损失(F-measure)都可以控制在5个百分点以内,速度接近于最快的检测网络,平均fps大概在10左右。
基础网络
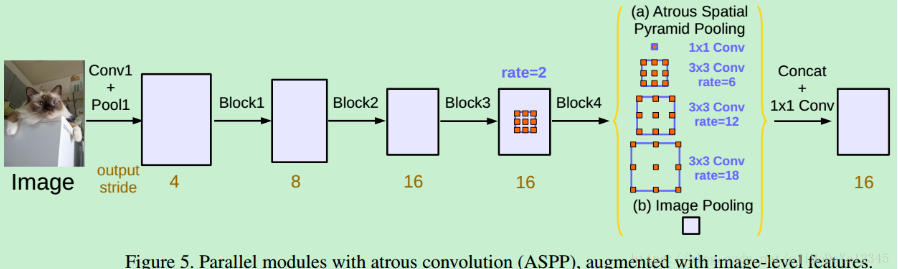
1、Deeplab
deeplab系列总结
由于语义分割是像素级别的分类,高度抽象的空间特征对low-level并不适用,因此必须要考虑feature分辨率和感受野。
feature map变小是因为stride的存在,stride>1是为了增加感受野的,如果stride=1,要保证相同的感受野,则必须是卷积核大小变大,因此,论文使用hole算法来增加核大小进而达到相同的感受野,也就是空洞卷积。
- deeplab_v1
DeeplabV1是在VGG16的基础上做了修改:
1、VGG16的全连接层转为卷积;
2、最后两个池化层去掉,后续使用空洞卷积。 - deeplab_v2
Deeplabv2是在v1上进行改进的:
1、 使用多尺度获得更好的分割效果(使用ASPP)
2、 基础层由VGG16转为ResNet
3、 使用不同的学习策略
- deeplab_v3
v3的主要创新点就是改进了ASPP模块,一个11的卷积和3个33的空洞卷积,每个卷积核有256个且都有BN层,包含图像及特征(全局平均池化)。
1、提出了更通用的框架,适用于任何网络;
2、复制了resnet最后的block,并级联起来
3、在ASPP中使用BN层
4、没有随机向量场
- deeplab_v3+
空间金字塔池化模块(SPP)和编码解码结构,用于语义分割的深度网络结构。SPP利用多种比例和多种有效感受野的不同分辨率特征处理,来挖掘多尺度的上下文内容信息,编解码结构逐步重构空间信息来更好的捕捉物体边界。
-
2、VGG
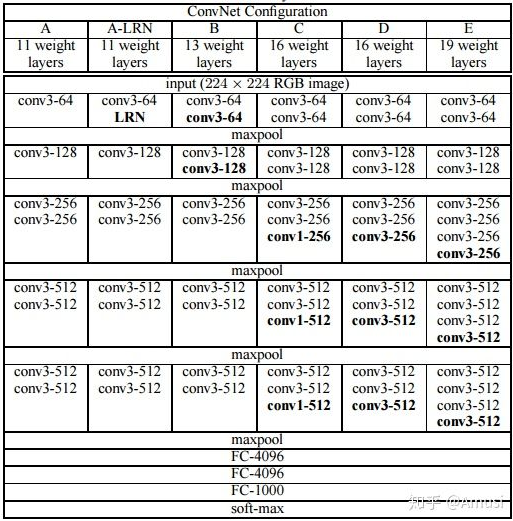
VGG优点
VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- 几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:
- 验证了通过不断加深网络结构可以提升性能。
VGG缺点
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
PS:有的文章称:发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。
3、Unet
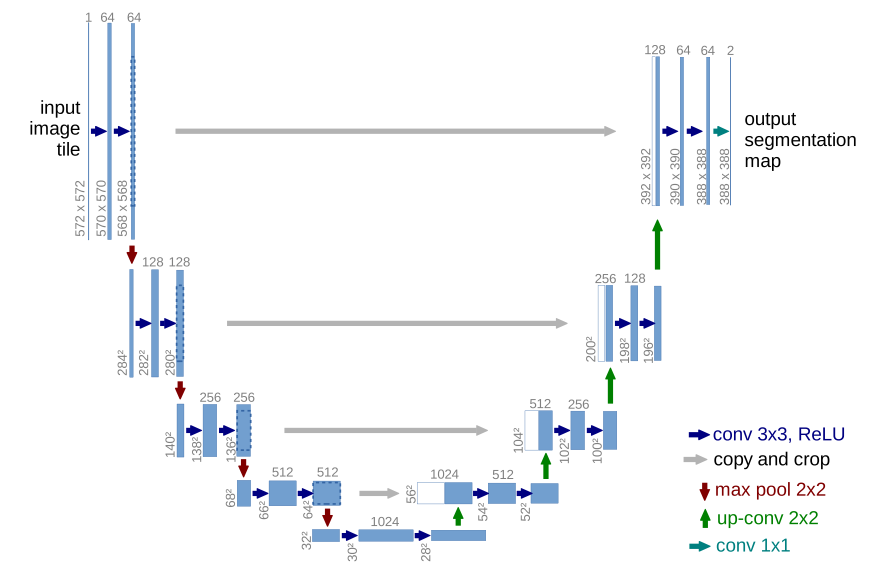
与FCN的不同是:U-net的上采样依然有大量的通道,这使得网络将上下文信息向更高分辨率传播,作为结果,扩展路径与收缩路径对称,形成一个U型的形状。
Unet和FCN的区别:**
1.与FCN逐点相加不同,U-Net采用将特征在channel维度拼接在一起,形成更“厚”的特征,实现方式是concat。
2.U-net的上采样依然有大量的通道,这使得网络将上下文信息向更高分辨率传播。
4、R-CNN到Faster-Rcnn
Faster RCNN详解结构介绍
从RCNN到Mask-RCNN
像玩乐高一样拆解Faster R-CNN:详解目标检测的实现过程
Anchors
Region Proposal Network
ROI Pooling
从RCNN到Mask-RCNN
像玩乐高一样拆解Faster R-CNN:详解目标检测的实现过程
理解R-CNN
(1).选择性搜索(Selective Search)一些区域提案(region proposal).
(2).使用AlexNet(ImageNet 2012 的冠军版本)进行特征提取,在 CNN 的最后一层,R-CNN 添加了一个支持向量机(SVM)进行分类。
(3).R-CNN 在区域提案上运行简单的线性回归,以生成更紧密的边界框坐标从而获得最终结果。
问题:如何进行产生region proposal? 如何具体的进行线性回归?
理解Fast R-CNN
R-CNN 性能很棒,但是因为下述原因运行很慢:
1. 它需要 CNN(AlexNet)针对每个单图像的每个区域提案进行前向传递(每个图像大约 2000 次向前传递)。
2. 它必须分别训练三个不同的模型 - CNN 生成图像特征,预测类别的分类器和收紧边界框的回归模型。pipeline复杂难以训练。
改进:
(1). ROI(兴趣区域)池化
让每个图像只运行一次 CNN,然后找到一种在 2000 个提案中共享计算. RoIPool 分享了 CNN 在图像子区域的前向传递, 从 CNN 的特征映射选择相应的区域来获取每个区域的 CNN 特征.
(2).将所有模型并入一个网络
在单一模型中联合训练卷积神经网络(CNN)、分类器(Softmax)和边界框回归器(线性回归层)。
理解Faster R-CNN
存在一个瓶颈问题——区域提案器(region proposer),这个过程相当缓慢。
提出使用CNN提取的特征映射用于生成区域提案:
Faster R-CNN 在 CNN 特征的顶部添加了一个简单的完全卷积网络,创建了所谓的区域提案网络。区域提案网络在 CNN 的特征上滑动一个窗口。在每个窗口位置,网络在每个锚点输出一个分值和一个边界框(因此,4k 个框坐标,其中 k 是锚点的数量)。
区域提案网络的输入和输出:
- 输入:CNN 特征图。
- 输出:每个锚点的边界框。分值表征边界框中的图像作为目标的可能性。
理解Mask R-CNN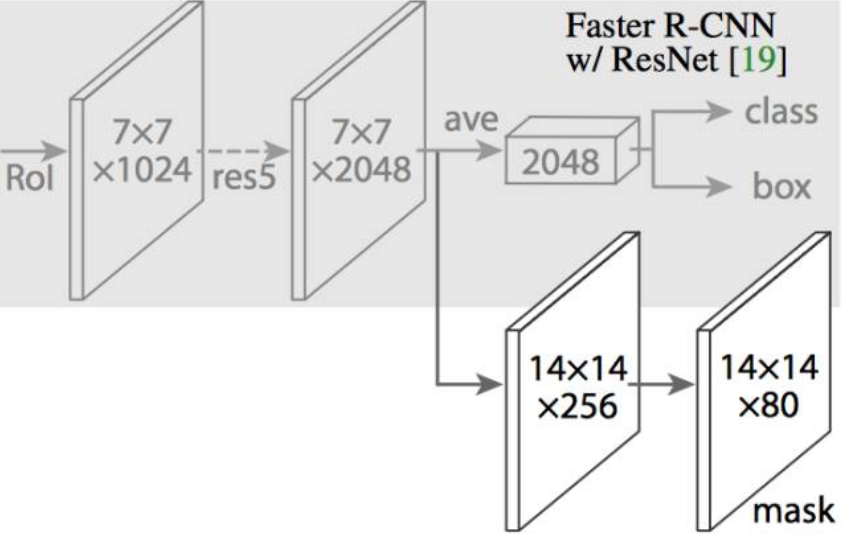
在 Mask R-CNN 中,在 Faster R-CNN 的 CNN 特征的顶部添加了一个简单的完全卷积网络(FCN),以生成 mask(分割输出)。
Faster R-CNN 的 RoIPool 选择的特征图的区域与原始图像的区域略不对齐:
对于一个尺寸大小为 128x128 的图像和大小为 25x25 的特征图。想要得到的是与原始图像中左上方 15x15 像素对应的区域(见上文)。
我们知道原始图像中的每个像素对应于原始图像中的〜25/128 像素。要从原始图像中选择 15 像素,我们只需选择 15 25/128〜=2.93 像素。
在 RoIPool,我们会舍弃一些,只选择 2 个像素,导致轻微的错位。然而,在 RoIAlign,我们避免了这样的舍弃。相反,*我们使用双线性插值来准确得到 2.93 像素的内容。这很大程度上,让我们避免了由 RoIPool 造成的错位。
5、SSD
SSD的原理以及实现
主要思路:均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡。
设计理念:
(1)采用了多尺度的特征图,比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标
(2)采用卷积进行检测
(3)设置了先验框,减少训练难度,每个单元会设置多个先验框,其尺度和长宽比存在差异
对于每个先验框,预测两部分: 1.类别或者置信度 2.先验框的location( ),分布表示中心坐标和宽高。实际预测的是offset。
),分布表示中心坐标和宽高。实际预测的是offset。
对于一个大小为 的特征图,共需要
的特征图,共需要 个预测值,
个预测值, 是每个单元先验框的数量。
是每个单元先验框的数量。
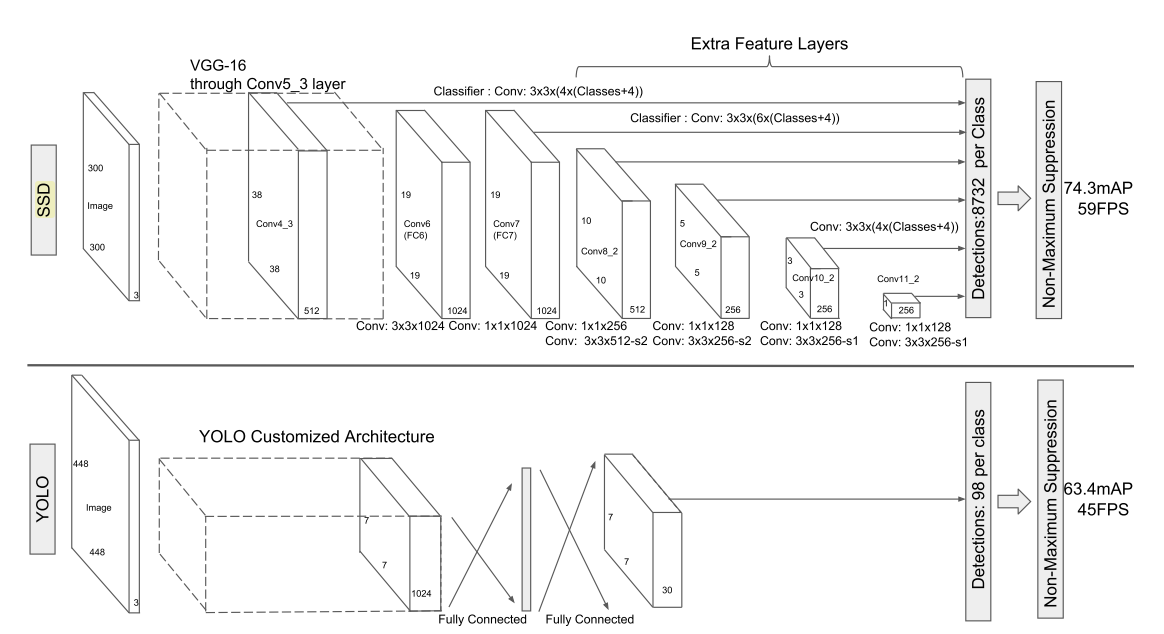
6、YOLO
7、Scene Text
EAST标签格式:5个geometry(4个location+1个angle) + 1个score ==6 × N × M<br />
RBOX, the geometry is represented by 4 channels of axis-aligned bounding box (AABB) R and 1 channel rotation angle θ.
CRNN
PseNet
Character Region Awareness for Text Detection
Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection
**
8、RNN和LSTM
一文读懂CRNN+CTC
基于RNN的文字识别主要有两个框架:
- CNN+RNN+CTC(CRNN+CTC)
- CNN+Seq2Seq+Attention
CRNN框架:
**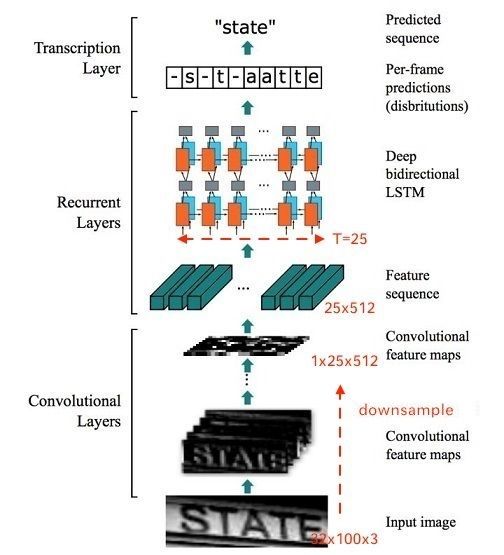
假设输入图像大小为  ,整个CRNN网络可以分为三个部分:
,整个CRNN网络可以分为三个部分:
- Convlutional Layers
一个的CNN网络,提取图像的feature maps,将大小为  的图像转换为
的图像转换为  大小的卷积特征矩阵
大小的卷积特征矩阵
- Recurrent Layers
这里的循环网络层是一个深层双向LSTM网络,在卷积特征的基础上继续提取文字序列特征。RNN,Seq2Seq, Attention
由于CNN输出的Feature map是 大小,所以对于RNN最大时间长度
大小,所以对于RNN最大时间长度  (即有25个时间输入,每个输入
(即有25个时间输入,每个输入  列向量有
列向量有  )。
)。
- Transcription Layers
将RNN输出做softmax后,为字符输出。
Connectionist Temporal Classification(CTC)详解
LSTM的每一个时间片后接softmax,输出  是一个后验概率矩阵,定义为:
是一个后验概率矩阵,定义为:
CTC是一种Loss计算方法,用CTC代替Softmax Loss,训练样本无需对齐。
CTC特点:
- 引入blank字符,解决有些位置没有字符的问题
- 通过递推,快速计算梯度
处理:
- 将标签在前面和中间分别插入空格blank,得到2*U+1长度的标签
- 令dp(t,u)表示t时刻对应第u个标签的合法路径的概率和
10、RNN、lstm、attention
完全解析RNN,seq to seq
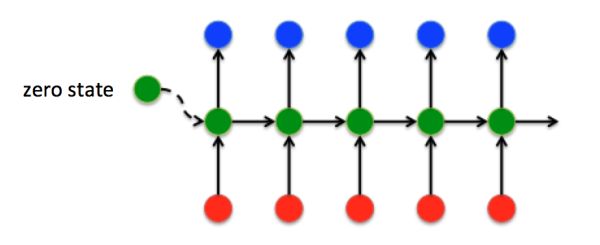
经典的RNN结构
- 输入和输出序列必有相同的时间长度
- 对于任意时刻
 ,所有的权值(包括
,所有的权值(包括  ,
,  ,
,  ,
,  ,
,  ,
,  )都相等,这也就是RNN中的“权值共享”,极大的减少参数量。
)都相等,这也就是RNN中的“权值共享”,极大的减少参数量。 - 对于
 时刻的输出,考虑时刻之前的输入。
时刻的输出,考虑时刻之前的输入。
RNN可以简单的表示为:
Sequence to Sequence模型
在Seq2Seq结构中,编码器Encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻  的输出作为后一个时刻
的输出作为后一个时刻  的输入,循环解码,直到输出停止符为止。
的输入,循环解码,直到输出停止符为止。
与经典RNN结构不同的是,Seq2Seq结构不再要求输入和输出序列有相同的时间长度!
Attention注意力机制
11、EfficientNet
新的模型缩放方法,它使用一个简单而高效的复合系数来以更结构化的方式放大 CNNs。 不像传统的方法那样任意缩放网络维度,如宽度,深度和分辨率,该论文的方法用一系列固定的尺度缩放系数来统一缩放网络维度。 通过使用这种新颖的缩放方法和 AutoML[5] 技术,作者将这种模型称为 EfficientNets ,它具有最高达10倍的效率(更小、更快)。
探究CNN的深度,宽度,分辨率的这三者的关系平衡从而达到更好的accuracy-efficiency tradeoff。
该论文的工作系统地研究了ConvNet对网络深度、宽度和分辨率这三个维度进行了缩放对网络的影响。
这里的  都是由一个很小范围的网络搜索得到的常量,直观上来讲,
都是由一个很小范围的网络搜索得到的常量,直观上来讲,  是一个特定的系数,可以控制用于资源的使用量。efficientnet是搜索到的,搜索目标是:
是一个特定的系数,可以控制用于资源的使用量。efficientnet是搜索到的,搜索目标是:

然后以EfficientNet-B0为baseline模型,我们将我们的复合缩放方法应用到它上面,分为两步:
- STEP 1:我们首先固定
 ,假设有相比于原来多了2倍的资源,我们基于等式(2)和(3)先做了一个小范围的搜索,最后发现对于EfficientNet-B0来说最后的值为
,假设有相比于原来多了2倍的资源,我们基于等式(2)和(3)先做了一个小范围的搜索,最后发现对于EfficientNet-B0来说最后的值为  ,在
,在  的约束下;
的约束下; - STEP 2:接着我们固定
 作为约束,然后利用不同取值的
作为约束,然后利用不同取值的  对baseline网络做放大,来获得Efficient-B1到B7;
对baseline网络做放大,来获得Efficient-B1到B7;
12、mobilenet
基础知识
1、cnn计算
- 一般卷积输出计算:

其中N为输入 图像的一边长、Pad为Padding填充数、kernal为卷积核(一般3×3)的单边数、stride为kernal的移动步长。
图像的一边长、Pad为Padding填充数、kernal为卷积核(一般3×3)的单边数、stride为kernal的移动步长。
- Dilated卷积输出计算:

其中dilaterate就为空洞数、核间隔(  )。就是k放大后计算一般卷积输出。
)。就是k放大后计算一般卷积输出。
- Transpose卷积输出计算:

这里需要注意的是TransCONV操作一般会指定 output_shape,因为例如对(3,3,1)做反卷还原,它的原始输入既可能是(5,5, 1)也可能为(6, 6, 1)
2、激活函数

3、Loss function
语义分割中的Loss
交叉熵loss
交叉熵就是用来判定实际的输出与期望的输出的接近程度!
神经网络的原始输出不是一个概率值,实质上只是输入的数值做了复杂的加权和与非线性处理之后的一个值而已,那么如何将这个输出变为概率分布?
这就是Softmax层的作用,假设神经网络的原始输出为y1,y2,….,yn,那么经过Softmax回归处理之后的输出为:
两种形式交叉熵表达:


交叉熵求导
我们要求导的是我们的loss对于神经元输出( )的梯度,即:
)的梯度,即:

这里为什么是 而不是,这里要看一下softmax的公式了,因为softmax公式的特性,它的分母包含了所有神经元的输出,所以,对于不等于i的其他输出里面,也包含着,所有的a都要纳入到计算范围中,并且后面的计算可以看到需要分为i=j和i≠j两种情况求导。
而不是,这里要看一下softmax的公式了,因为softmax公式的特性,它的分母包含了所有神经元的输出,所以,对于不等于i的其他输出里面,也包含着,所有的a都要纳入到计算范围中,并且后面的计算可以看到需要分为i=j和i≠j两种情况求导。
对于 :
:
对于 :
:
- 如果
 :
:
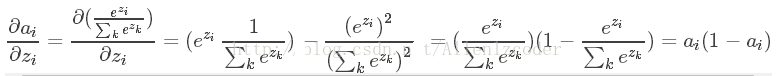
- 如果
 :
:
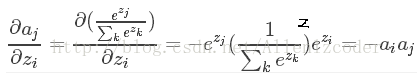
最后我们将上面组合: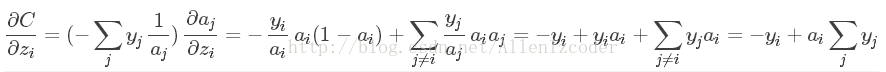
最后,针对分类问题,我们给定的结果 最终只会有一个类别是1,其他类别都是0,因此,对于分类问题,这个梯度等于
最终只会有一个类别是1,其他类别都是0,因此,对于分类问题,这个梯度等于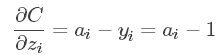
IoU loss
- IoU算法是使用最广泛的算法,大部分的检测算法都是使用的这个算法。
2. GIoU考虑到,当检测框和真实框没有出现重叠的时候IoU的loss都是一样的,因此GIoU就加入了C检测框(C检测框是包含了检测框和真实框的最小矩形框),这样就可以解决检测框和真实框没有重叠的问题。但是当检测框和真实框之间出现包含的现象的时候GIoU就和IoU loss是同样的效果了。
3. DIoU考虑到GIoU的缺点,也是增加了C检测框,将真实框和预测框都包含了进来,但是DIoU计算的不是框之间的交并,而是计算的每个检测框之间的欧氏距离,这样就可以解决GIoU包含出现的问题。
4. CIoU就是在DIoU的基础上增加了检测框尺度的loss,增加了长和宽的loss,这样预测框就会更加的符合真实框。
L1 and L2 loss
的收敛速度比更快,但对离群点更为敏感<br />: <br />: <br />Focal loss<br />**主要针对两个方面进行均衡:**<br />1、不同类别之间的不均衡,包含背景和前景<br />2、难学习hard sample和容易学习的样本easy sample进行均衡

 通常设置为2,用于均衡easy和hard sample,
通常设置为2,用于均衡easy和hard sample, 用于均衡不同类别。
用于均衡不同类别。
Dice soft loss
实质上是两个样本之间重叠的度量

总结:
交叉熵损失把每个像素都当作一个独立样本进行预测,而 dice loss 和 iou loss 则以一种更“整体”的方式来看待最终的预测输出。
这两类损失是针对不同情况,各有优点和缺点,在实际应用中,可以同时使用这两类损失来进行互补。
4、预防Overfitting
- (1)正则化
机器学习中的正则化(Regularization)
使用正则化,降低模型的复杂度,增强模型的泛化能力。在目标函数后面添加一个系数的“惩罚项”是正则化的常用方式,为了防止系数过大从而让模型变得复杂。
L1正则化时,对应惩罚项为 L1 范数 :
L2正则化时,对应惩罚项为 L2 范数:
L1正则化更容易造成特征的系数为0,引起特征稀疏,适用于特征选择,而L2正则化会使,系数按照一个比例缩放趋向于变小,而不会变成0,因此使模型更简单,更适用于防止模型过拟合。ps:具体看链接证明。
- (2)Early stopping
具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data的accuracy,当accuracy不再提高时,就停止训练。 - (3)数据增强
从数据源采集更多数, 复制原有数据并加上随机噪声,重采样,根据当前数据集估计数据分布参数,使用该分布产生更多数据等 (4) Dropout
随机得删除一些(可以设定为一半,也可以为1/3,1/4等)隐藏层神经元.5、优化器
机器学习:各种优化器Optimizer的总结与比较
1.GD(**Gradient Descent**)
两个缺点:**训练速度慢:每走一步都要要计算调整下一步的方向,下山的速度变慢。需要花费很长时间才能得到收敛解。
- 容易陷入局部最优解:由于是在有限视距内寻找下山的反向。当陷入平坦的洼地,会误以为到达了山地的最低点,从而不会继续往下走。
2.BGD**(Batch Gradient Descent)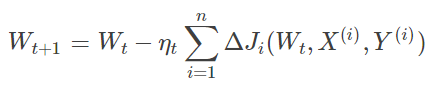
模型参数的调整更新与全部输入样本的代价函数的和(即批量/全局误差)有关。在下山之前掌握了附近的地势情况,选择总体平均梯度最小的方向下山。
3.SGD(Stochastic Gradient Descent)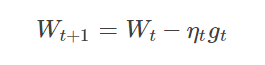
优点:**
- 虽然SGD需要走很多步的样子,但是对梯度的要求很低(计算梯度快)。而对于引入噪声,大量的理论和实践工作证明,只要噪声不是特别大,SGD都能很好地收敛。
缺点:
- SGD在随机选择梯度的同时会引入噪声,使得权值更新的方向不一定正确。
- SGD也没能单独克服局部最优解的问题。
4.Momentum(动量优化法)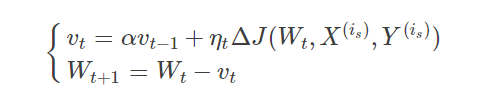
理解策略为:** 由于当前权值的改变会受到上一次权值改变的影响,类似于小球向下滚动的时候带上了惯性。这样可以加快小球向下滚动的速度。
动量主要解决SGD的两个问题:**
- 是随机梯度的方法(引入的噪声);
- 是Hessian矩阵病态问题(可以理解为SGD在收敛过程中和正确梯度相比来回摆动比较大的问题)。
5.RMSProp(自适应学习率)
思想:考虑了历史梯度平均值。具有代价函数最大梯度的参数相应地有个小的的学习率,而具有小梯度的参数有个较大的学习率。
RMSProp算法修改了AdaGrad的梯度积累为指数加权的移动平均,使得其在非凸设定下效果更好。
算法描述:RMSProp算法的一般策略可以表示为: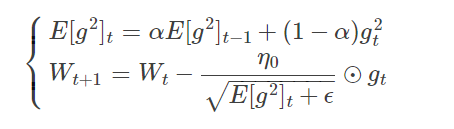
由于取了个加权平均,避免了学习率越来越低的的问题,而且能自适应地调节学习率。
6.Adam
Adaptive Moment Estimation
Adam 可以认为是 RMSprop 和 Momentum 的结合: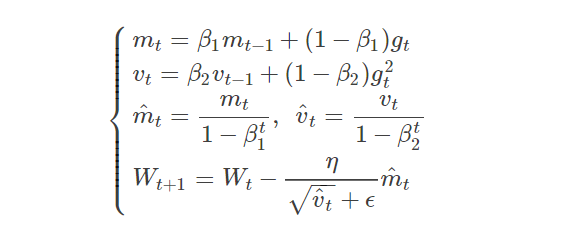
**其中, 和
和 分别为一阶动量项和二阶动量项。
分别为一阶动量项和二阶动量项。 和
和 为动力值大小通常分别取0.9和0.999;
为动力值大小通常分别取0.9和0.999; 和
和 分别为各自的修正值。
分别为各自的修正值。 表示时刻即第迭代模型的参数,
表示时刻即第迭代模型的参数, 表示次迭代代价函数关于
表示次迭代代价函数关于 的梯度大小;
的梯度大小; 是一个取值很小的数(一般为1e-8)为了避免分母为0.
是一个取值很小的数(一般为1e-8)为了避免分母为0.
6、评价指标计算
True Positive(真正,TP):将正类预测为正类数
True Negative(真负,TN):将负类预测为负类数
False Positive(假正,FP):将负类预测为正类数
False Negative(假负,FN):将正类预测为负类
准确率(accuracy)计算公式为: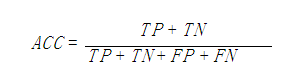
精确率(precision):
召回率(recall):
f-measure:
7、传统的机器学习
特征提取:
特征提取HOG方向梯度直方图
SVM
传统的边缘检测算子
Conditional Random Field (CRF)
1.**逻辑回归(Logistic regression)和线性回归(Linear regression)
浅析机器学习:线性回归 & 逻辑回归**
- 线性回归
 想要评价一个模型的优良,就需要一个度量标准。对于回归问题,最常用的度量标准就是均方差.
想要评价一个模型的优良,就需要一个度量标准。对于回归问题,最常用的度量标准就是均方差.
逻辑回归
逻辑回归使用的联系函数是Sigmoid函数(S形函数)中的最佳代表,即对数几率函数(Logistic Function):

将对数几率函数代入到之前得到的广义线性回归模型中,就可以得到逻辑回归的数学原型了:

2.传统**边缘检测算子
使用微分继续统计一幅图中边缘的强弱:
在连续函数里叫微分,因为图像是离散的,叫差分,和微分是一个意思,也是求变化率。
Roberts算子
Roberts算子是一种斜向偏差分的梯度计算方法。
- Canny算子
计算步骤:
(1)用高斯滤波器平滑图像;
(2)用一阶偏导的有限差分来计算梯度的幅值和方向;
(3)对梯度幅值进行非极大值抑制;
(4)用双阈值算法进行检测和链接边缘。
通俗说一下,
1.用高斯滤波主要是去掉图像上的噪声。
2.计算一阶差分,用 sobel 算子来算的。
3.算出来的梯度值,把不是极值的点,全部置0,去掉了大部分弱的边缘。
4.双阈值  ,
,  , 是这样的,
, 是这样的, ,大于 的点肯定是边缘,小于 的点肯定不是边缘。
,大于 的点肯定是边缘,小于 的点肯定不是边缘。
在  之间的点,通过已确定的边缘点,发起8领域方向的搜索(广搜),图中可达的是边缘,不可达的点不是边缘。
之间的点,通过已确定的边缘点,发起8领域方向的搜索(广搜),图中可达的是边缘,不可达的点不是边缘。
最后得出 canny 边缘图。
- Sobel算子
Sobel算子是一组方向算子,从不同的方向检测边缘。Sobel算子不是简单地求平均再差分,而是加强了中心像素上下左右4个方向像素的权值,运算结果是一幅边缘图。
使用 近似计算一阶差分。
近似计算一阶差分。
排好序:
提出系数:
分别计算偏 x 方向的 Gx,偏 y 方向的 Gy,求绝对值,压缩到 [0, 255]
区间,即 G(x, y) = Gx + Gy 就是 sobel 边缘检测后的图像了。**
8、Batch_norm的具体细节
问题:在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化叫做Internal Covariate Shift。
带来的影响:
(1)上层网络需要不停调整来适应输入数据分布的变化,导致网络学习速度的降低
(2)网络的训练过程容易陷入梯度饱和区,减缓网络收敛速度
直接进行白化的问题:
(1)由于改变了网络每一层的分布,因而改变了网络层中本身数据的表达能力。
(2)白化过程计算成本太高
(3)让每一层的输入分布均值为0,方差为1,会使得输入在经过sigmoid或tanh激活函数时,容易陷入非线性激活函数的线性区域。
BN(白化+线性变换):
BN又引入了两个可学习(learnable)的参数  与
与  。这两个参数的引入是为了恢复数据本身的表达能力,对规范化后的数据进行线性变换,即
。这两个参数的引入是为了恢复数据本身的表达能力,对规范化后的数据进行线性变换,即  。特别地,当
。特别地,当  时,可以实现等价变换(identity transform)并且保留了原始输入特征的分布信息。
时,可以实现等价变换(identity transform)并且保留了原始输入特征的分布信息。
测试阶段如何使用Batch Normalization?
利用BN训练好模型后,我们保留了每组mini-batch训练数据在网络中每一层的  与
与  。此时我们使用整个样本的统计量来对Test数据进行归一化,具体来说使用均值与方差的无偏估计。
。此时我们使用整个样本的统计量来对Test数据进行归一化,具体来说使用均值与方差的无偏估计。
Batch Normalization的优势
(1)BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度。
(2)BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定。
(3)BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
(4)BN具有一定的正则化效果
不同mini-batch的均值与方差会有所不同,这就为网络的学习过程中增加了随机噪音
9、梯度消失和梯度爆炸
面试中梯度消失和梯度爆炸
解释:
在反向传播过程中需要对激活函数进行求导,如果此部分大于1,那么层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸,如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。
梯度消失、爆炸的解决方案:
(1)预训练加微调,每次训练一层隐节点
(2)梯度剪切: 更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。可以防止梯度爆炸。另外一种解决梯度爆炸的手段是采用权重正则化(weithts regularization)。如果发生梯度爆炸,权值的范数就会变的非常大,通过正则化项,可以部分限制梯度爆炸的发生。
(3)relu、leakrelu、elu等激活函数
(4)batch normalization:通过对每一层的输出规范为均值和方差一致的方法,消除了w带来的放大缩小的影响,进而解决梯度消失和爆炸的问题。
(5)残差结构
10、IoU、GIoU、DIoU、CIoU
- IOU(Intersection over Union)
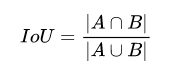
缺陷:(1)如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重合度)。同时因为loss=0,没有梯度回传,无法进行学习训练(2)IoU无法精确的反映两者的重合度大小。
- GIOU(Generalized Intersection over Union)

先计算两个框的最小闭包区域面积 (通俗理解:同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
(通俗理解:同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
优点:(1)与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度(2)IoU取值[0,1],但GIoU有对称区间,取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1,因此GIoU是一个非常好的距离度量指标。
缺点:GIoU对scale不敏感
- DIoU(Distance-IoU)
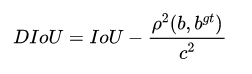
其中  ,
, 分别代表了预测框和真实框的中心点,且
分别代表了预测框和真实框的中心点,且 代表的是计算两个中心点间的欧式距离,
代表的是计算两个中心点间的欧式距离, 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
优点:(1)与GIoU loss类似,在与目标框不重叠时,仍然可以为边界框提供移动方向。(2)DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
缺点:GIoU对scale不敏感
- CIoU(Complete-IoU)
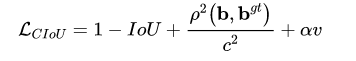
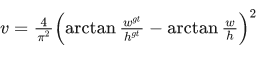
 用来度量长宽比的相似性,对scale敏感。
用来度量长宽比的相似性,对scale敏感。
编程语言
Python
- fun(*args,kwargs)中的args,*kwargs什么意思?
args和*kwargs主要用于函数定义,你可以将不定数量的参数传递给一个函数,即预先不知道函数使用者会传递多少个参数给你
C++
- 深拷贝和浅拷贝
浅拷贝:仅仅是指向被复制的内存地址,如果原地址中对象被改变了,那么浅复制出来的对象也会相应改变。
深复制:在计算机中开辟了⼀块新的内存地址⽤于存放复制的对象。
- 虚函数
定义他为虚函数是为了允许用基类的指针来调用子类的这个函数
虚函数的作用是什么?
哪些函数不能是虚函数:
(1)构造函数,构造函数初始化对象,派⽣类必须知道基类函数⼲了什么,才能进⾏构造;当有虚函数时,每⼀个类有⼀个虚表,每⼀个对象有⼀个虚表指针,虚表指针在构造函数中初始化;
(2)内联函数,内联函数表⽰在编译阶段进⾏函数体的替换操作,⽽虚函数意味着在 运⾏期间进⾏类型确定,所以内联函数不能是虚函数;
(3)静态函数,静态函数不属于对象属于类,静态成员函数没有this指针,因此静态函 数设置为虚函数没有任何意义;
虚函数和纯虚函数的区别在于:
1) 纯虚函数只有定义没有实现,虚函数既有定义又有实现;
2) 含有纯虚函数的类不能定义对象,含有虚函数的类能定义对象;
- 多态
(1).静态多态(重载,模板)
是在编译的时候,就确定调⽤函数的类型。
(2).动态多态(覆盖,虚函数实现)
在运⾏的时候,才确定调⽤的是哪个函数,动态绑定。运⾏基类指针指向派⽣类的对象,并调⽤派⽣类的函数。
- **Vector和List的区别
vector和数组类似,拥有⼀段连续的内存空间,vector的随机访问效率⾼。
list是由双向链表实现的,因此内存空间是不连续的,随机存取⾮常没有效率,但由于链表的特点,能⾼效地 进⾏插⼊和删除。**
基础数学知识
1. 方差、标准差、均方差、均方误差(MSE)
方差、标准差、均方差、均方误差(MSE)区别总结
方差是数据序列与均值(期望)的关系,如下图所示:

均方差(标准差),标准差是方差的平方根:

2. 矩估计和极大似然估计
矩估计和极大似然估计都是对函数参数的估计方法。
面试问题
问题 1: Batch_norm的具体细节
Batch Normalization原理与实战
为什么用BN层?BN层如何实现?训练集和测试集的BN层有什么不同?
问题 2:对于softmax出现exp的爆炸该如何处理?
关于Softmax的数值稳定性和梯度反向传播对所有指数项 做均值迁移,减去其中最大值。这个迁移不影响softmax之后的概率分布,详细看链接。
做均值迁移,减去其中最大值。这个迁移不影响softmax之后的概率分布,详细看链接。
问题 3:L1和L2 regulizer的区别?
问题 4:模型欠拟合的时候怎么处理?
1.添加其他特征项:组合,泛化,相关性,上下文特征,平台特征
2.添加多项式特征,例如将线性模型添加二次项或者三次项增强泛化能力
3.减少正则化参数。
问题 5EM算法?
最大期望算法(Expectation-maximization algorithm)
问题 6 Dice loss?
问题 7 sigmoid求导以及证明?
[sigmoid求导以及证明](https://www.jianshu.com/p/d4301dc529d9)<br />
问题 8 二分类交叉熵求导?
问题 9 最大似然估计和贝叶斯估计的联系和区别?
问题 10 Batch norm和GN的差别?
问题 11 VGG的参数量,如何计算参数量,计算量,举例说明?
问题 12 介绍一下resnet?
问题 13 实现一下hasmap?
问题 14 k-means过程?
问题 15 PCA过程?
问题 16 评价指标计算,为什么这样计算?
问题 17 常见的边缘检测(传统方式)?
问题 18 CNN卷积层全连接层参数量和计算量?
问题 19 NMS的IOU计算?

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}