概述
从本文开始,我们将会进入 ElasticSearch 的相关学习。
本文作为 ElasticSearch 的开篇文章,将会首先讲解如何快速安装一个可练习的ElasticStack的环境(包括ElasticSearch,Logstash以及Kibana)。
ElasticSearch安装
目前,ElasticSearch 支持多种安装方式,包括二进制安装、Docker镜像安装,Helm Chart 安装等。
首先,我们来了解最基本的安装方式:二进制安装。
进入 ElasticSearch 的下载页面。
下载对应的版本的程序包即可,我们以 Linux 系统为例进行演示: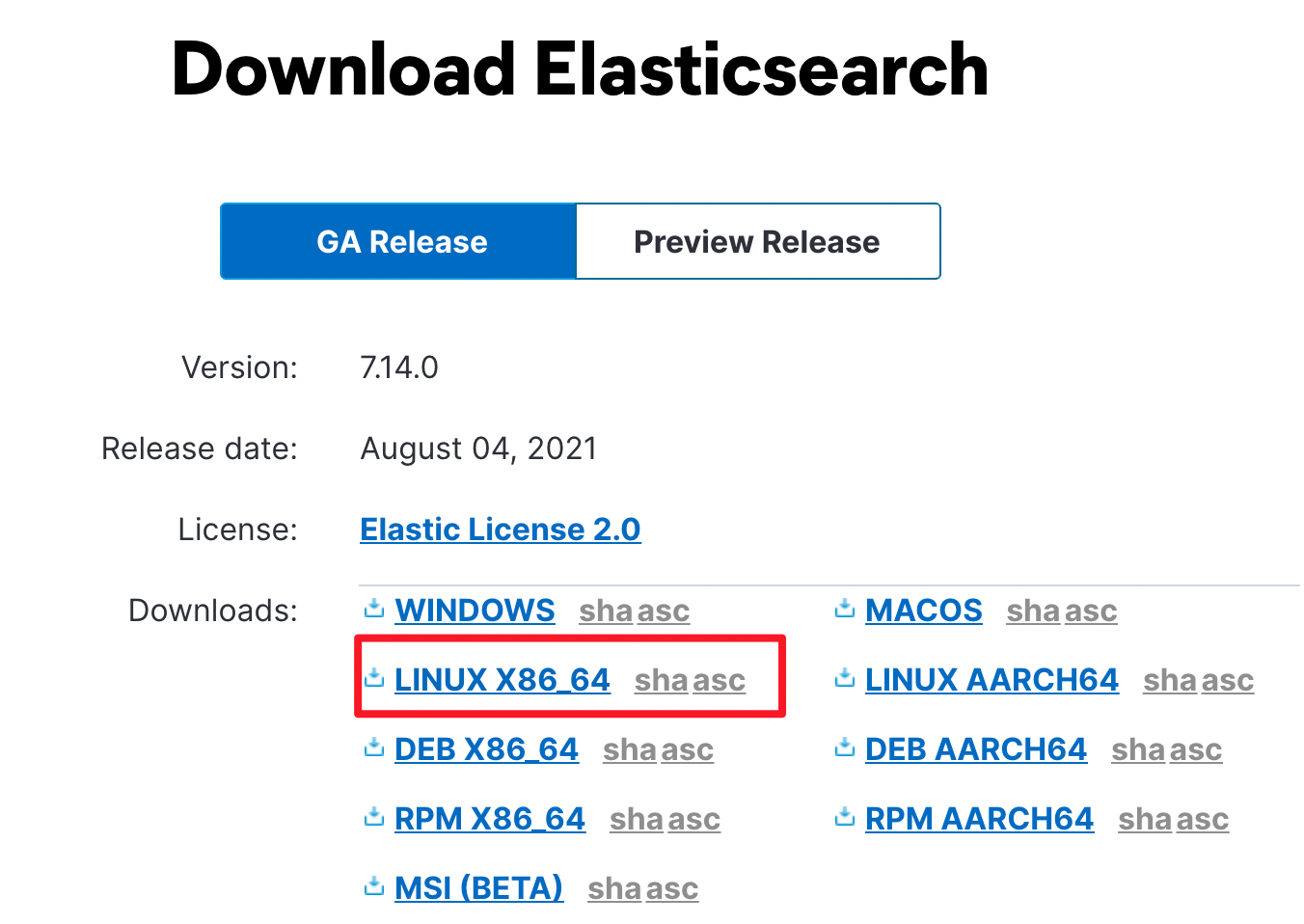
我们先对下载包进行解压:
tar -zxvf elasticsearch-7.14.0-linux-x86_64.tar.gz
目录结构说明
我们来了解一下解压后得到的目录结构和各个目录的功能:
total 640-rw-r--r-- 1 work work 2710 Jul 30 04:47 README.asciidoc-rw-r--r-- 1 work work 3860 Jul 30 04:47 LICENSE.txtdrwxr-xr-x 2 work work 4096 Jul 30 04:51 plugins-rw-r--r-- 1 work work 615722 Jul 30 04:51 NOTICE.txtdrwxr-xr-x 2 work work 4096 Jul 30 04:51 logsdrwxr-xr-x 3 work work 4096 Jul 30 04:52 libdrwxr-xr-x 2 work work 4096 Jul 30 04:52 bindrwxr-xr-x 9 work work 4096 Jul 30 04:52 jdkdrwxr-xr-x 59 work work 4096 Jul 30 04:53 modulesdrwxr-xr-x 3 work work 4096 Aug 28 08:38 config
- bin 目录下包含了 ElasticSearch 的一些启动执行文件。
- config 目录下包含了 ElasticSearch 的一些配置文件,其中关于ElasticSearch最重要的配置就是elasticsearch.yml文件了。另外,jvm.options 中是JVM的一些相关配置,其中包含一些推荐的建议:Xms和Xmx建议配置成相同的值,且不要超过30G,也不要超过整机内存的一半。不过,根据目前ElasticSearch官方的介绍,ElasticSearch会根据机器状态和节点的角色自动设置Xms和Xmx的配置,用户通常可以直接忽略。如果想要主动指定的话,建议不要直接修改 config/jvm.options 文件,而是在 config/jvm.options.d 目录下新建一个 .options 后缀的文件进行配置重写。
- jdk 目录下包括了一个完整的Java环境依赖。
- lib 目录中包含了ElasticSearch依赖的一些Java Lib库。
- data 目录包含了 ElasticSearch 中实际存储的相关数据。
- logs 目录是日志打印的目录。
- modules 目录是 ElasticSearch 内置的模块相关存放目录。
- plugins 目录是用于存放 ElasticSearch 扩展的插件存放目录。
ElasticSearch 配置介绍
在之前目录结构介绍中,我们已经简单提到了 config/elasticsearch.yml 是 ElasticSearch 的核心配置文件,下面,我们来看一下它的配置文件中的一些核心字段吧。
在 ElasticSearch 中,主要需要用到两个端口:
- HTTP端口:对外提供HTTP服务的端口,默认端口为9200,如果需要修改,可以修改配置文件中 http.port 字段。
- TCP端口:和 TCP 客户端交互的端口,同时用于集群节点间内部通信,默认端口为 9300,如果需要修改,可以修改配置文件中 transport.tcp.port 字段。
与端口相关的还有 network 配置,它表示了允许哪些网段的机器访问 ElasticSearch ,默认情况下,ElasticSearch 仅允许 localhost 访问,即只允许本机访问。如果想要调整可以修改如下配置:
- network.host: 例如,可以修改为 0.0.0.0 允许所有机器访问。
下面,我们来介绍一些和 ElasticSearch 部署模式相关的一些配置:
- cluster.name: 该字段用于指定集群名称,默认为 elasticsearch 。在生产环境中,最好提前修改该名称。因为ElasticSearch会根据集群名称来自动发现并构建集群,因此,修改一个名称是非常有必要的。
- node.name: 该字段用于指定节点名称,为了方便分析和问题定位,最好也给每一个节点都设置一个节点名称。
- cluster.initial_master_nodes: 用于设置集群启动时,初始master节点的名称。
服务启动和效果演示
ElasticSearch 的启动非常简单,仅需要执行如下命令即可启动:
./bin/elasticsearch
稍等片刻后,我们就可以看到服务已经正常启动了。
下面,我们来访问 ElasticSearch 的 HTTP 端口看一下吧: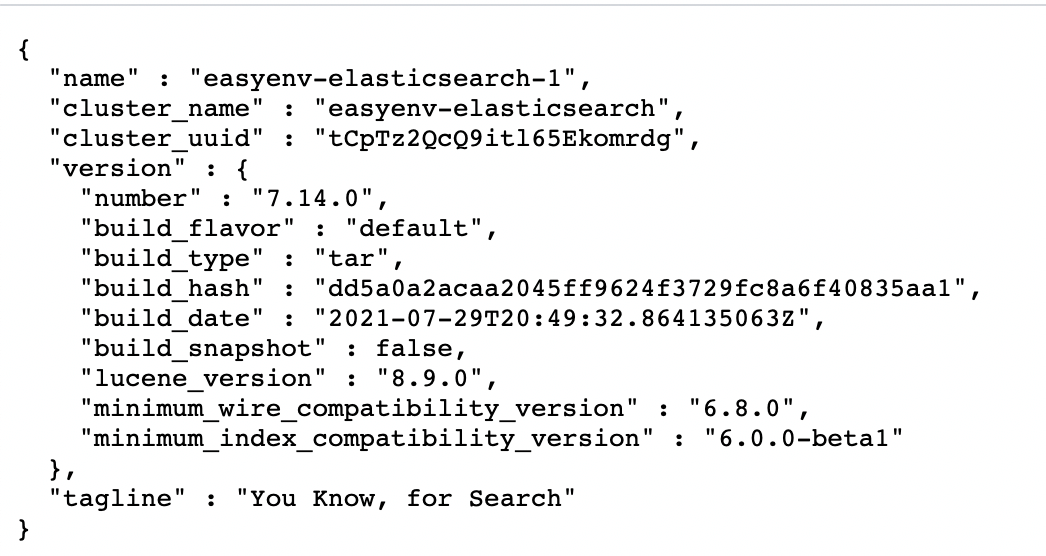
怎么样?是不是看到了这个页面?是的,你的ElasticSearch服务已经正常启动了。
ElasticSearch 插件安装
ElasticSearch 支持根据用户自己的需求来安装相关的插件。
其中,ElasticSearch 提供了如下命令行工具来进行插件管理:
./bin/elasticsearch-plugin# A tool for managing installed elasticsearch plugins## Non-option arguments:# command## Option Description# ------ -----------# -E <KeyValuePair> Configure a setting# -h, --help Show help# -s, --silent Show minimal output# -v, --verbose Show verbose output
例如,我们可以通过如下命令来安装一个 ElasticSearch 的插件:
./bin/elasticsearch-plugin install analysis-icu
该命令将会自动从插件仓库下载对应的插件并安装到本地。
此时,如果你查看 plugins 目录的话,你就会发现已经可以看到对应的插件了,重启ElasticSearch服务,你就会发现对应的插件已经生效了。
Kibana安装
同样,Kibana 的安装方案也支持很多种,我们同样还是以二进制的方式先来进行安装。
首先下载 Kibana 的二进制压缩包: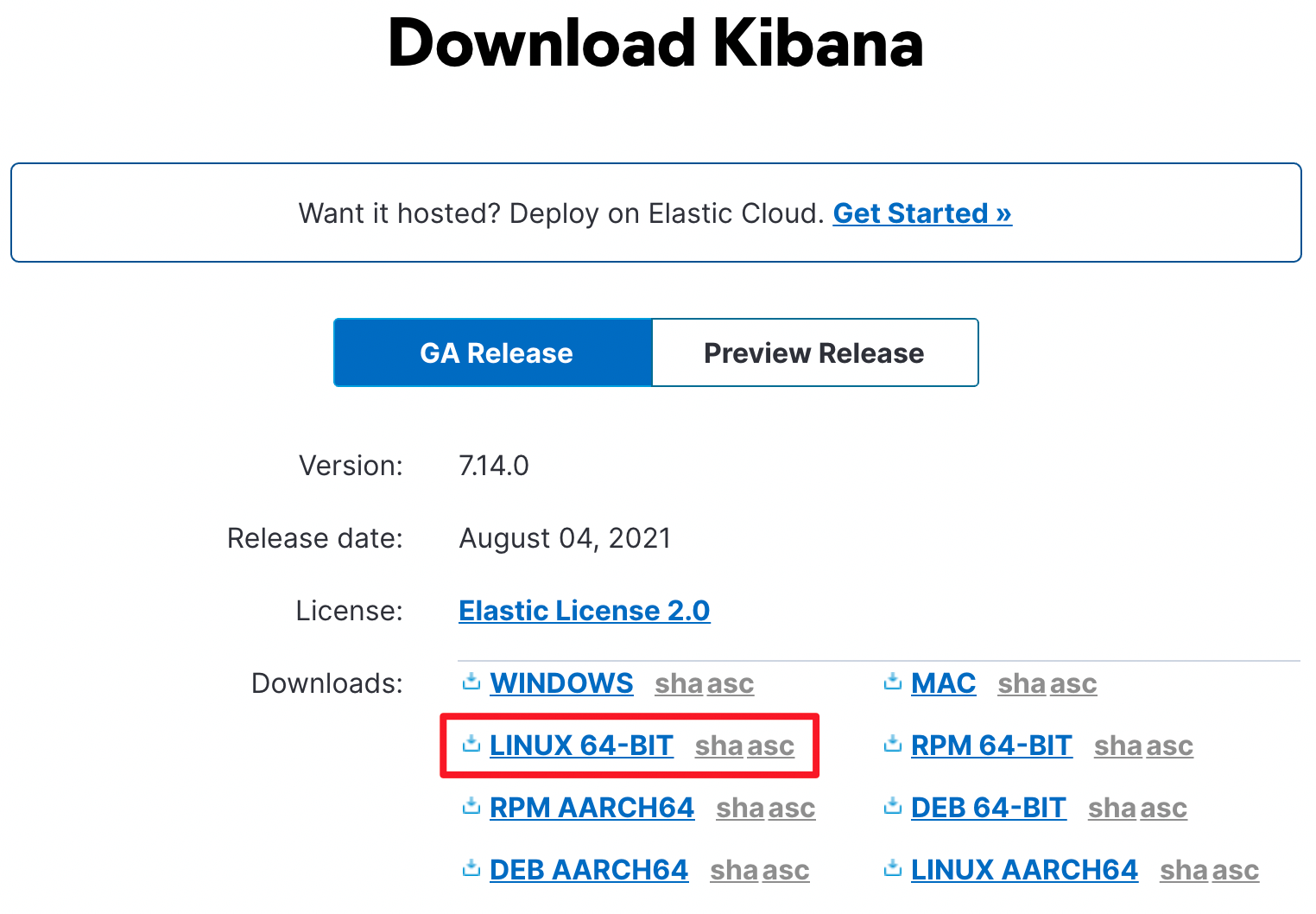
Ps: Kibana 的版本与 ElasticSearch 的版本务必要一致。
然后,我们解压对应的压缩包:
tar -zxvf kibana-7.14.0-linux-x86_64.tar.gz
目录结构说明
还是一样,我们先来看一下 Kibana 的相关目录吧:
drwxr-xr-x 3 work work 4096 Jul 30 04:09 x-packdrwxr-xr-x 10 work work 4096 Jul 30 04:09 src-rw-r--r-- 1 work work 3968 Jul 30 04:09 README.txtdrwxr-xr-x 2 work work 4096 Jul 30 04:09 plugins-rw-r--r-- 1 work work 740 Jul 30 04:09 package.json-rw-r--r-- 1 work work 1436057 Jul 30 04:09 NOTICE.txtdrwxr-xr-x 807 work work 32768 Jul 30 04:09 node_modules-rw-r--r-- 1 work work 3860 Jul 30 04:09 LICENSE.txtdrwxr-xr-x 2 work work 4096 Jul 30 04:09 datadrwxr-xr-x 2 work work 4096 Jul 30 04:09 configdrwxr-xr-x 6 work work 4096 Jul 30 04:09 nodedrwxr-xr-x 2 work work 4096 Jul 30 04:09 bin
其中,我们重点关注如下几个目录:
- bin: 可执行的启动文件目录。
- config: 配置文件目录。
- data: 数据存放目录。
- node: 完成的node.js环境。
- node_modules: 依赖的node.js的第三方依赖库。
- plugins: 插件存放目录。
Kibana 配置介绍
下面,我们来看一下 Kibana 中,我们重点要关注哪些配置文件项。
- server.port: 服务端口,默认为5601
- server.host: 服务可以被哪些地址访问,默认为localhost,即只允许本机访问。
- server.name: 服务的名称。
- elasticsearch.hosts: 对应后端的 ElasticSearch 地址,默认为 http://localhost:9200 。
- elasticsearch.username: ElasticSearch 用户名。
- elasticsearch.password: ElasticSearch 密码。
- i18n.locale: 语言版本,默认为en,汉化可以设置为 zh-CN 。
服务启动和效果演示
Kibana 的启动也非常简单,可以直接执行如下命令来启动:
./bin/kibana
稍等片刻后,我们就可以看到服务已经正常启动了。
下面,我们来访问 Kibana 的地址看一下吧:
可以看到,Kibana的服务已经正常启动了。
首次启动 Kibana 后,会提示我们可以添加一些数据来演示相关的功能。
例如,我们可以添加一些样例数据:
点击添加数据按钮后,稍等片刻数据就已经成功添加好了。
其实,我们就可以通过样例自带的仪表盘来查询数据了: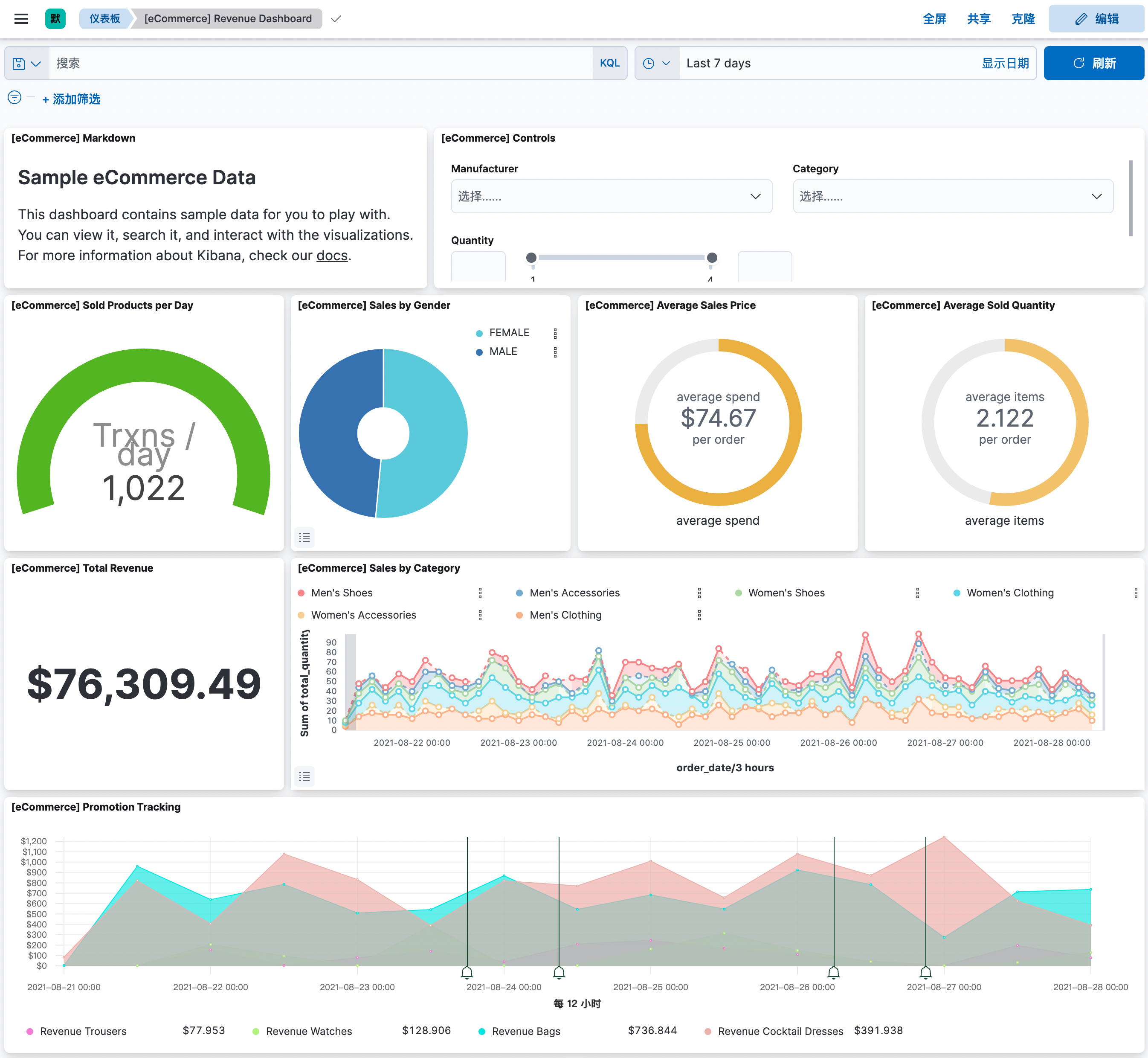
DevTool(开发工具)
Kibana 提供了一个很有用的开发工具页面,回到Kibana首页后,点击开发工具即可进入该页面:
开发工具页面如下图所示: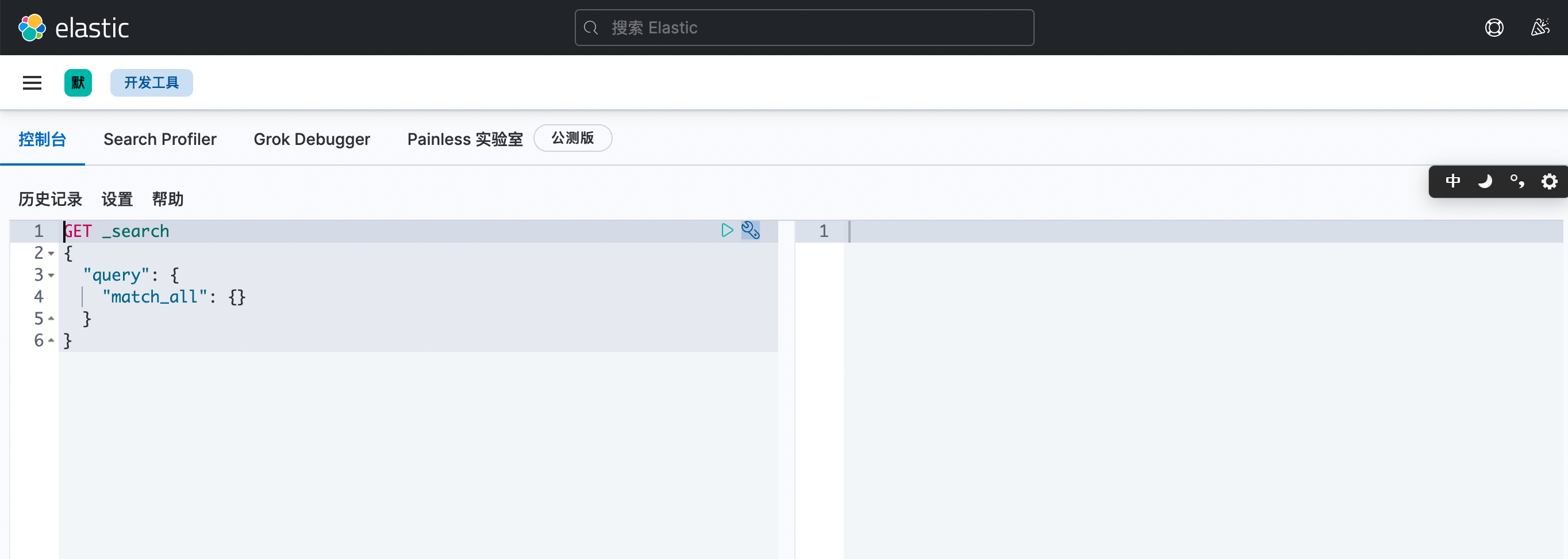
在该页面中,我们可以快捷的调用ElasticSearch相关的接口并进行一些相关的调试工作。
Kibana插件安装
Kibana 和 ElasticSearch 一样,也支持根据用户自己的需求来安装相关的插件。
其中,Kibana 提供了如下命令行工具来进行插件管理:
./bin/kibana-plugin# Usage: bin/kibana-plugin [command] [options]## The Kibana plugin manager enables you to install and remove plugins that provide additional functionality to Kibana## Commands:# list list installed plugins# install [options] <plugin/url> install a plugin# remove [options] <plugin> remove a plugin# help <command> get the help for a specific command
Logstash 安装
最后,作为 ElasticStack 的最后一部分,我们来演示一下 Logstash 的安装和使用。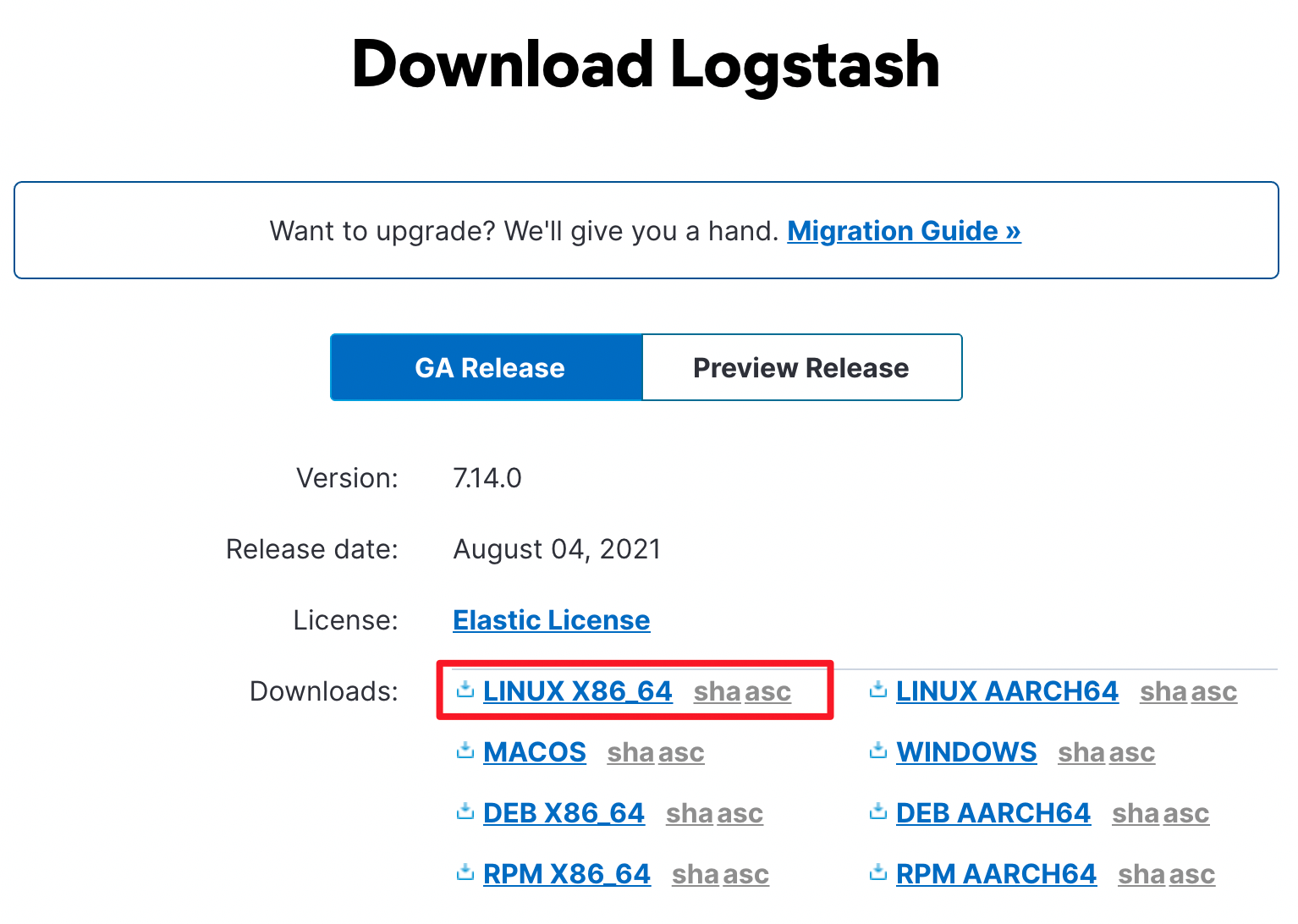
下载对应的二进制包并解压:
tar -zxvf logstash-7.14.0-linux-x86_64.tar.gz
目录结构说明
还是一样,我们先来看一下 Logstash 的相关目录吧:
drwxr-xr-x 2 work work 4096 Jul 30 03:41 datadrwxrwxr-x 2 work work 4096 Aug 28 11:34 configdrwxrwxr-x 2 work work 4096 Aug 28 11:34 bindrwxrwxr-x 4 work work 4096 Aug 28 11:34 modulesdrwxrwxr-x 6 work work 4096 Aug 28 11:34 libdrwxrwxr-x 3 work work 4096 Aug 28 11:34 toolsdrwxrwxr-x 3 work work 4096 Aug 28 11:34 logstash-core-plugin-apidrwxrwxr-x 4 work work 4096 Aug 28 11:34 logstash-coredrwxrwxr-x 4 work work 4096 Aug 28 11:34 vendordrwxrwxr-x 9 work work 4096 Aug 28 11:34 x-packdrwxrwxr-x 9 work work 4096 Aug 28 11:34 jdk-rw-r--r-- 1 work work 2276 Jul 30 03:41 CONTRIBUTORS-rw-r--r-- 1 work work 424030 Jul 30 03:41 NOTICE.TXT-rw-r--r-- 1 work work 13675 Jul 30 03:41 LICENSE.txt-rw-r--r-- 1 work work 24806 Jul 30 03:41 Gemfile.lock-rw-r--r-- 1 work work 4053 Jul 30 03:41 Gemfile
其中,我们重点关注如下几个目录:
- bin: 可执行的启动文件目录。
- config: 配置文件目录。
- data: 数据存放目录。
- jdk: 目录下包括了一个完整的Java环境依赖。
- lib 目录中包含了依赖的一些Java Lib库。
- data 目录包含了实际存储的相关数据。
- modules 目录是内置的模块相关存放目录。
服务启动和效果演示
在演示 Logstash 的演示之前,我们还需要做一些准备工作。
首先,我们需要创建一个 logstash.conf 配置文件:
input {file {path => "/home/work/dataset/movies.csv"start_position => "beginning"sincedb_path => "/dev/null"}}filter {csv {separator => ","columns => ["id","content","genre"]}mutate {split => { "genre" => "|" }remove_field => ["path", "host","@timestamp","message"]}mutate {split => ["content", "("]add_field => { "title" => "%{[content][0]}"}add_field => { "year" => "%{[content][1]}"}}mutate {convert => {"year" => "integer"}strip => ["title"]remove_field => ["path", "host","@timestamp","message","content"]}}output {elasticsearch {hosts => "http://localhost:9200"index => "movies"document_id => "%{id}"}stdout {}}
另外,我们需要下载一个测试需要用的的 movies.csv 测试数据文件。
movies.csv
Logstash 的启动也非常简单,可以直接执行如下命令来启动:
bin/logstash -f ./config/logstash.conf
观察其日志输出内容,我们就可以看到它已经将csv文件的内容进行了解析并写入到了ElasticSearch 中。
Cerebro 安装与介绍
Cerebro 是一款 ElasticSearch 的监控管理工具。
安装
首先,我们需要下载 Cerebro 的二进制软件包:下载地址。
下载完成后,我们可以解压该压缩包:
tar -zxvf cerebro-0.9.4.tgz
服务启动与效果演示
Cerebro 的启动很简单,直接执行如下命令即可:
bin/cerebro -Dhttp.port=8505 -Dhttp.address=0.0.0.0
其中:
- http.port 表示服务绑定的端口
- http.address 表示服务绑定的网卡地址
Ps: 需要注意的是,Cerebro 依赖于 Java 11 以上的 Java 版本。
访问 Cerebro 地址看一下:
首先需要用户传入 ElasticSearch 的地址,输入地址并点击 Connect 操作。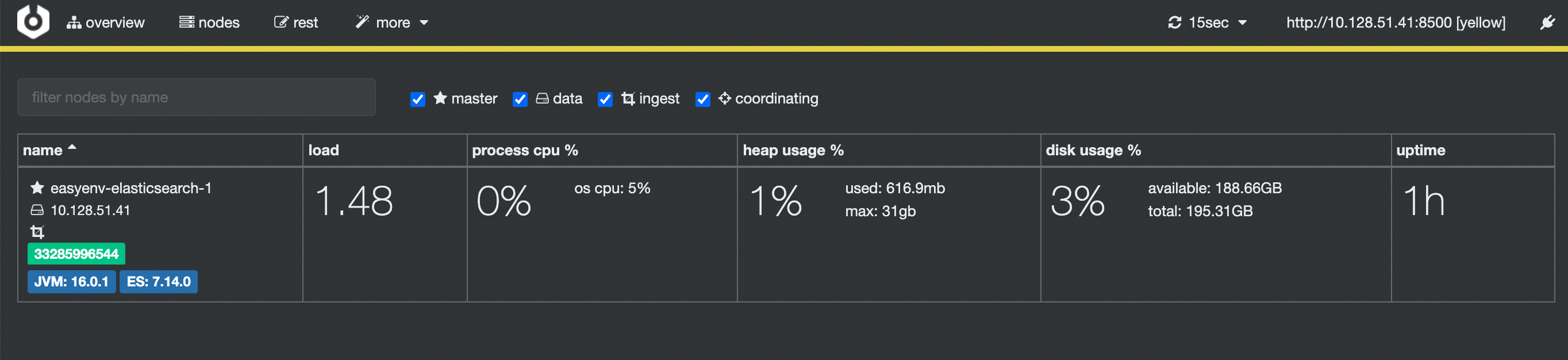
此时,我们就可以看到对应的 ElasticSearch 的集群信息和状态了!

若有收获,就点个赞吧
0 人点赞
