概述
在 ElasticSearch 学习的开始,我们首先需要了解一些 ElasticSearch 中的一些最核心的基本概念。
包括:
- 文档
- 索引
- 节点
- 分片等
文档
首先,我们来了解 ElasticSearch 中一个最基础的概念:文档。
ElasticSearch 本身是面向文档的,文档是可搜索数据的最小单位。
例如:
- 日志文件中的一条日志记录
- 一部电影详细信息
- 一首MP3歌曲等
在 ElasicSearch 中,文档是以 JSON 格式进行保存的,JSON中可以包括多个字段,每个字段都有其对应的字段类型,包括字符串、数值、布尔、日期、二进制、范围等。
此外,每个文档都会有一个唯一标识 id,可以自己指定,也可以让 ElasticSearch 自动生成。
例如,对于一个如下的 CSV 文件记录而言:
将其转化至 ElasicSearch 存储后,得到的数据格式如下:
其中,ElasticSearch 中文档的格式可以不用预先定义,如果没有定义,ElasticSearch 会根据写入的数据自动进行推算并设置文档格式,它支持数组和嵌套类型。
一个文档在 ElasticSearch 中存储的完整数据如下所示:
{"_index" : ".kibana-event-log-7.14.0-000001","_type" : "_doc","_id" : "RpTDinsBHEYqSWTd01YF","_score" : 1.0,"_source" : {"@timestamp" : "2021-08-28T03:18:01.907Z","event" : {"provider" : "eventLog","action" : "starting"},"message" : "eventLog starting","ecs" : {"version" : "1.8.0"},"kibana" : {"server_uuid" : "a2a9736e-6b5e-4032-aeb0-4302a42e7412"}}}
可以看到,其最外层为一组以 _ 开头的Key,它们其实都有着特殊的作用和含义:
- _index 表示了文档所属的索引名
- _type 表示了文档所属的类型,目前仅支持 _doc 值的 type。
- _id 表示了文档的唯一ID
- _source 表示了文档的原始JSON数据
- _score 表示根据搜索条件进行的相关性打分
索引
了解了什么是文档之后,我们再看来一下 索引 是什么。
索引是文档的容器,是一类文档的结合:
- 每个索引都有自己的 Mapping 定义,用于定义其中包含的文档的字段名称和字段类型。
- 每个索引也都有自己的 Setting 配置,用于定义其对应的分片数和副本数等。
注意:索引(Index)这个词其实是有很多重含义的,这个对于初学 ElasticSearch 的同学而言,还是比较令人困惑的。具体来说:
- 在ES中,索引作为名词,表示的是一类文档的结合,即文档的容器,一个ElasticSearch中可以包含多个索引。
- 同样,在ES中,索引还可以作为动作,表示保存一个文档到ElasticSearch的动作,也叫做索引(indexing)。
- 此外,对于传统的数据库领域而言,索引是一个名词,例如B树索引或者倒排索引。
如果我们将 ES 与传统的关系型数据库进行对比,那么大致的对比关系如下:
| 关系型数据库 | ElasticSearch |
|---|---|
| Table | Index |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | DSL |
集群与节点
我们都知道,ElasticSearch 本身是一个分布式架构的服务,具有高可用和横向扩展的能力。
具体来说:
- 高可用包括:
- 服务高可用:部分节点故障后,整体服务可以正常访问。
- 数据高可用:部分节点故障后,数据不会丢失。
- 可扩展性体现在:
- 横向扩展后,可以支持更多的请求QPS
- 横向扩展后,可以存储更多的数据
在ElasticSearch的分布式架构中,需要注意的是:
- ElasticSearch 中不同的集群是用不同的名字来区分的,默认集群名称为 elasticsearch,可以通过配置文件或者命令行参数来修改。
- 一个集群中可以包含1个或多个节点。
- 每个节点就是一个 ElasticSearch 的实例,生产环境中,建议每台机器仅运行一个实例。
- 每个节点也都有自己的节点名称,可以在配置文件或者命令行参数中设置。
- 每个节点启动之后,都会随机分为一个UID并保存在data目录下。
节点类型
ElasticSearch 中的节点可以扮演不同的角色,即不同的节点可以有不同的节点类型,常用的节点类型包括:
- Master Node: Master 节点是整个集群的大脑,只有 Master 节点才能修改集群的状态信息。
- Master Eligible: Master Eligible 节点是 Master 节点的候选者,当当前的Master节点故障后,其他的Master Eligible节点将会通过选举的机制从当前的Master Eligible节点中选出新的Master节点。
- Data Node: 用于存放数据的节点,负责保存分片数据。
- Ingest Node: 用于通过 pipeline 的方式优化数据写入,建议作为数据写入的入口。
- Coordinate Node: 负责接收 Client 的请求,并分发到合适的节点查询数据,并将结果汇总后进行返回,默认每个节点都会充当 Coordinate Node 的角色。
- Hot && Warm Node: 用于将数据优先级进行分类,针对不同的数据存在不同硬件配置的Data Node,降低集群成本。
- MachineLearning Node: 负责跑机器学习任务的Node,用于异常检测等功能。
Ps: 在生产环境中,建议每个节点承担单一的角色,保证高性能和稳定性。
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| master eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| coordinating only | 无 | 每个节点默认都是 Coordinate 节点 |
| machine learning | node.ml | true(需要 x-pack 开启) |
分片与副本
分片
在 ElasticSearch 中,分片可以用于解决数据水平扩展的问题。具体来说,可以将一个索引中的数据拆分成多份,每一份就对应于一个分片。
实际上,一个分片就是一个运行的 Lucene 实例。
需要注意的是,分片数在创建索引时需要指定,后续除非Reindex,否则不允许修改。
在生产环境中,分片数量的设置不宜过大,如果配置过大,会导致:
- 影响搜索结果打分和统计结果的准确性。
- 单个节点上存在多个分片,导致性能降低。
从 ElasticSearch 7.0 开始,默认主分片数目为1。
副本
与分片同步,副本主要用于解决数据的高可用问题。
对于一个索引而言,如果是三副本,则表明将每份数据都保留三份,即存在三份一样的数据在持久化存储中。
副本数是可以动态调整的,增加副本数在一定程度上可以提高数据读取的吞吐量。
ElasticSearch API
ElasticSearch 一个最大的优点就是其提供了完善的 REST API,从而可以很容易的被各种语言调用。
各个语言客户端访问 ElasticSearch 的方式如下: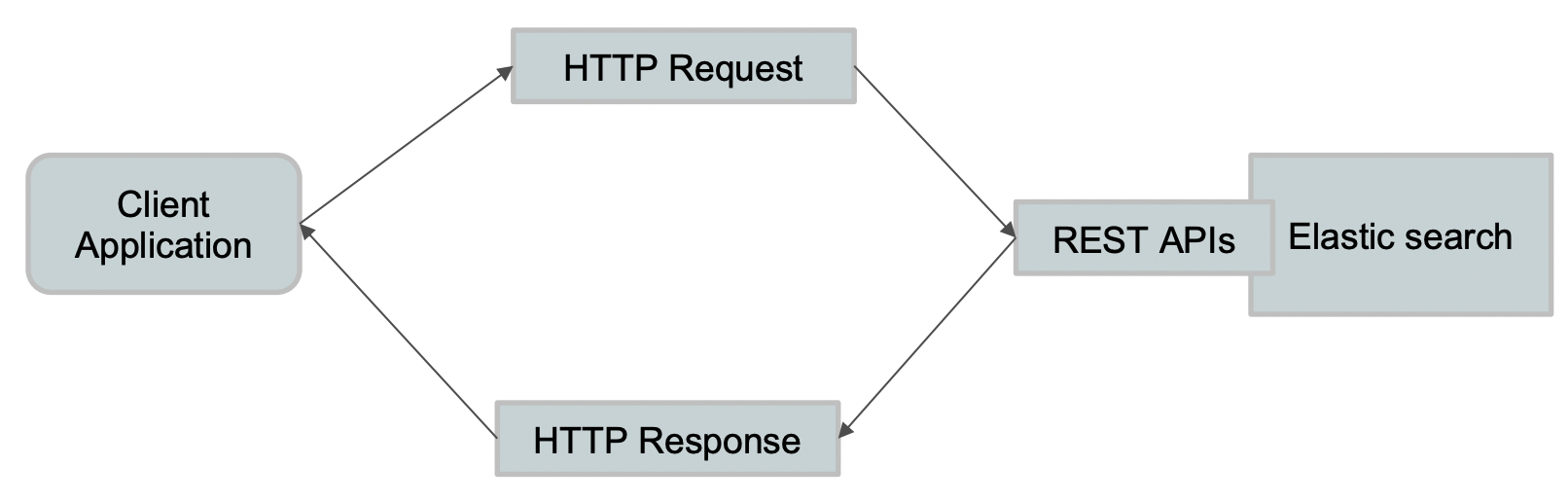
下面,我们先粗略的了解一下 ElasticSearch 中基本的 API 是如何调用的。
我们使用 Kibana 中提供的 DevTools 来测试 ElasticSearch 的 API 调用。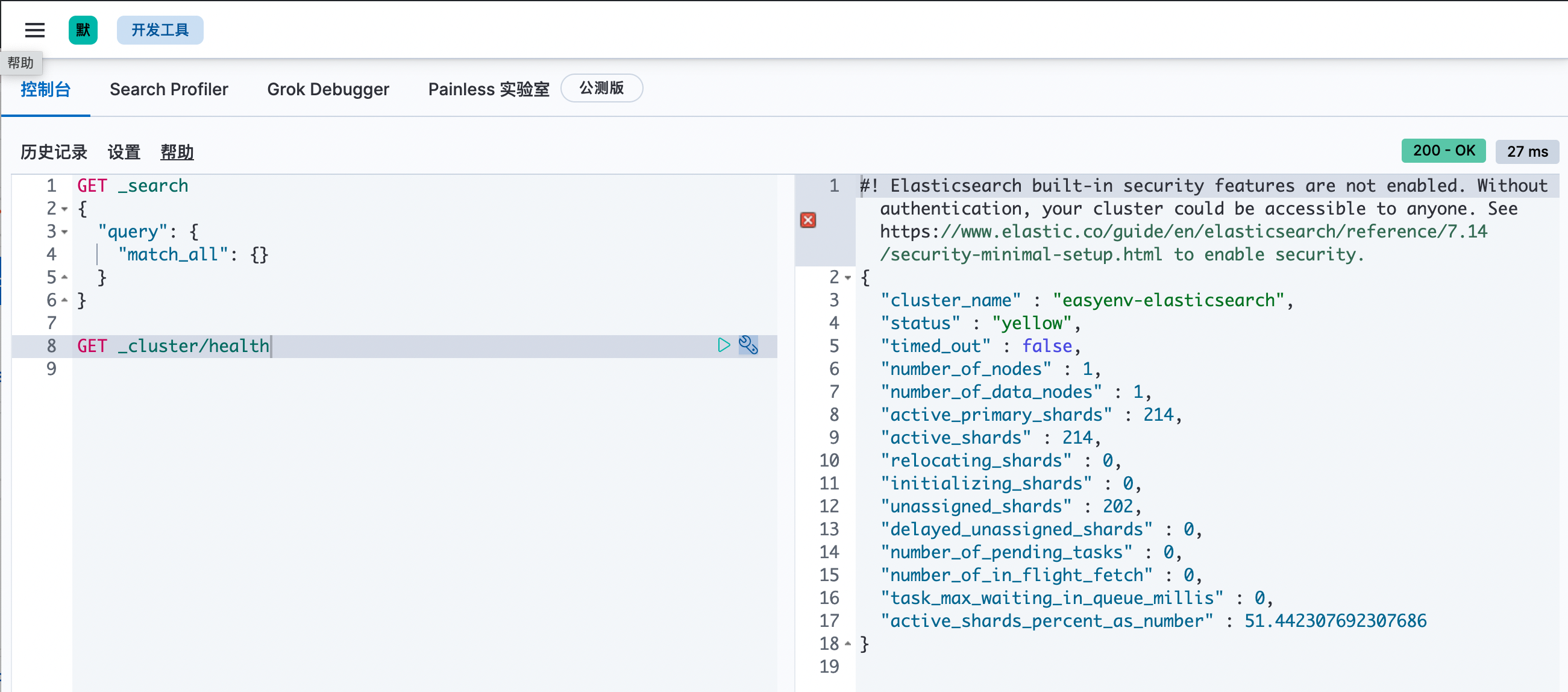
其中,对于 Kibana 的 DevTools 而言,有很多使用的小技巧,例如:
- 在某个 URL 下,按下 Command + / 键,就可以自动去打开一个新的窗口查询该 API 的接口文档。
indices
索引是 ElasticSearch 中最重要的概念之一了,下面,我们就来看一下如何查看和管理索引吧。
首先,Kibana 中提供了一个页面专门用于索引的管理。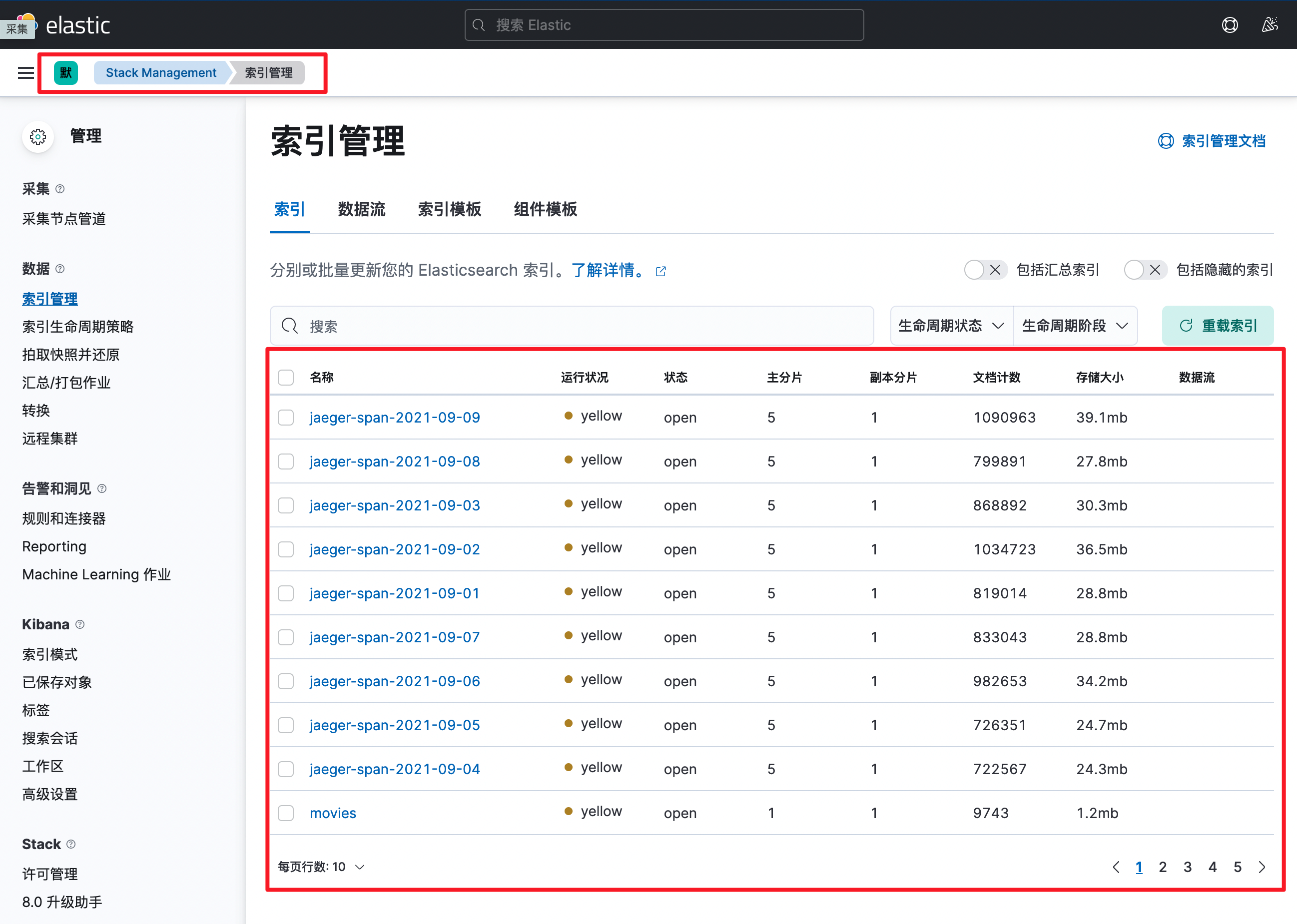
点击索引的名称,可以看到当前索引更加详细的信息: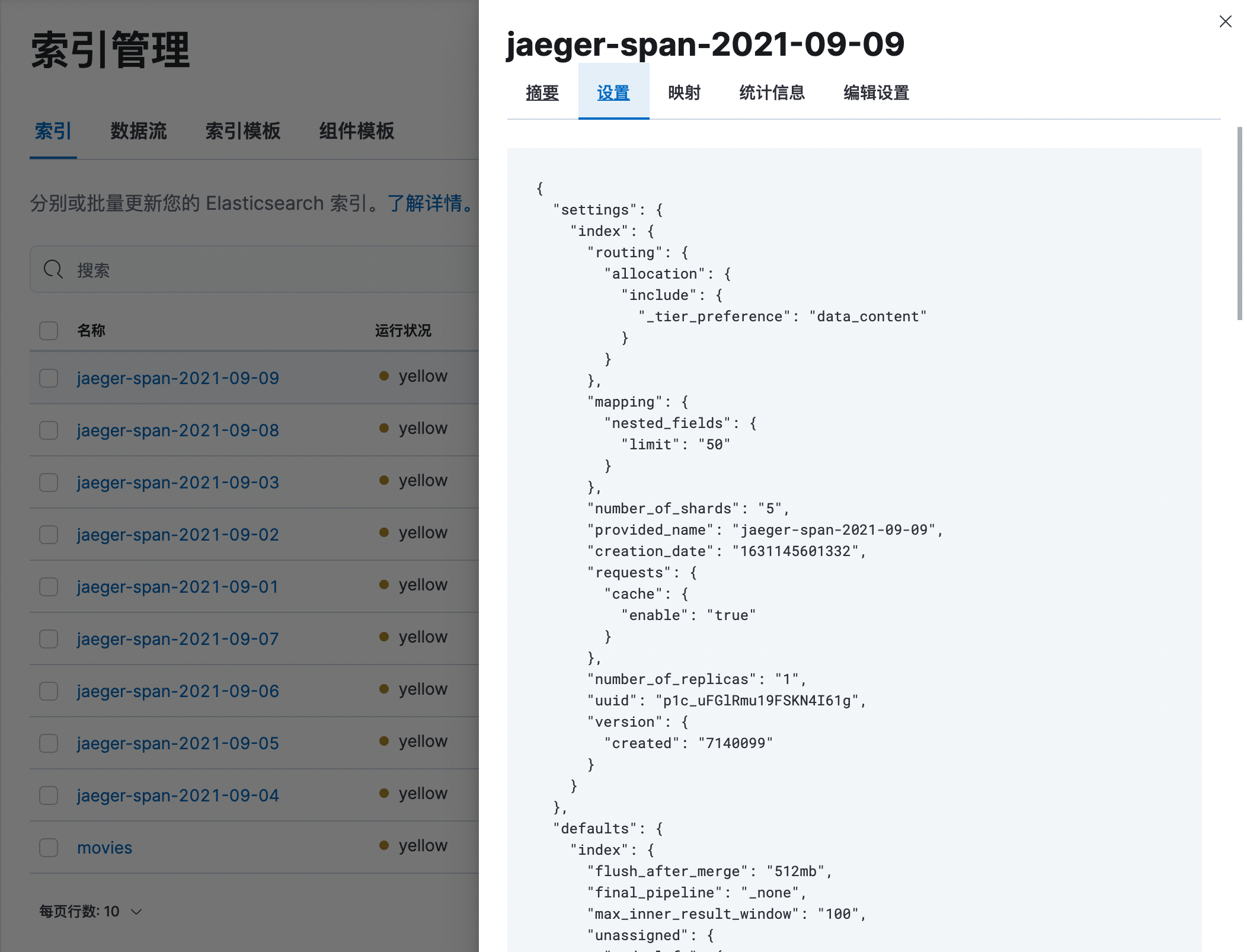
其中,包括了索引的Setting和Mapping等相关的配置和统计信息。
下面我们来看一下ElasticSearch 针对索引提供了哪些 API。
查询索引信息
ElasticSearch 查询索引信息的 URL 非常简单:
GET jaeger-span-2021-09-09{"jaeger-span-2021-09-09" : {"aliases" : { },"mappings" : {"dynamic_templates" : [{"span_tags_map" : {"path_match" : "tag.*","mapping" : {"ignore_above" : 256,"type" : "keyword"}}},{"process_tags_map" : {"path_match" : "process.tag.*","mapping" : {"ignore_above" : 256,"type" : "keyword"}}}],"properties" : {"duration" : {"type" : "long"},"flags" : {"type" : "integer"},"logs" : {"type" : "nested","dynamic" : "false","properties" : {"fields" : {"type" : "nested","dynamic" : "false","properties" : {"key" : {"type" : "keyword","ignore_above" : 256},"tagType" : {"type" : "keyword","ignore_above" : 256},"value" : {"type" : "keyword","ignore_above" : 256}}},"timestamp" : {"type" : "long"}}},"operationName" : {"type" : "keyword","ignore_above" : 256},"parentSpanID" : {"type" : "keyword","ignore_above" : 256},"process" : {"properties" : {"serviceName" : {"type" : "keyword","ignore_above" : 256},"tag" : {"type" : "object"},"tags" : {"type" : "nested","dynamic" : "false","properties" : {"key" : {"type" : "keyword","ignore_above" : 256},"tagType" : {"type" : "keyword","ignore_above" : 256},"value" : {"type" : "keyword","ignore_above" : 256}}}}},"references" : {"type" : "nested","dynamic" : "false","properties" : {"refType" : {"type" : "keyword","ignore_above" : 256},"spanID" : {"type" : "keyword","ignore_above" : 256},"traceID" : {"type" : "keyword","ignore_above" : 256}}},"spanID" : {"type" : "keyword","ignore_above" : 256},"startTime" : {"type" : "long"},"startTimeMillis" : {"type" : "date","format" : "epoch_millis"},"tag" : {"type" : "object"},"tags" : {"type" : "nested","dynamic" : "false","properties" : {"key" : {"type" : "keyword","ignore_above" : 256},"tagType" : {"type" : "keyword","ignore_above" : 256},"value" : {"type" : "keyword","ignore_above" : 256}}},"traceID" : {"type" : "keyword","ignore_above" : 256}}},"settings" : {"index" : {"routing" : {"allocation" : {"include" : {"_tier_preference" : "data_content"}}},"mapping" : {"nested_fields" : {"limit" : "50"}},"number_of_shards" : "5","provided_name" : "jaeger-span-2021-09-09","creation_date" : "1631145601332","requests" : {"cache" : {"enable" : "true"}},"number_of_replicas" : "1","uuid" : "p1c_uFGlRmu19FSKN4I61g","version" : {"created" : "7140099"}}}}}
对,直接访问索引的名称即可,它会返回索引相关的信息,包括setting, mapping等信息。
索引列表查询
ElasticSearch 除了支持指定索引名称的查询,还支持索引列表的查询:
GET _cat/indicesyellow open jaeger-span-2021-09-09 p1c_uFGlRmu19FSKN4I61g 5 1 1090963 0 39.1mb 39.1mbyellow open jaeger-span-2021-09-08 qsguXsAWSSG-7OiutgprYA 5 1 799891 0 27.8mb 27.8mbyellow open jaeger-span-2021-09-03 bGlo8vHXQ7Cf_rij4P-HCw 5 1 868892 0 30.3mb 30.3mbyellow open jaeger-span-2021-09-02 tt92ktDgThKIxr8tNNrEHw 5 1 1034723 0 36.5mb 36.5mbyellow open jaeger-span-2021-09-01 aqU1y7gYSVuAe1PHLSMhEQ 5 1 819014 0 28.8mb 28.8mbyellow open jaeger-span-2021-09-07 CEChzzADT8q9RI7QoUenGA 5 1 833043 0 28.8mb 28.8mbyellow open jaeger-span-2021-09-06 Ym9TB2yJRX2mS05hPrhHZQ 5 1 982653 0 34.2mb 34.2mbyellow open jaeger-span-2021-09-05 lrZkh5o7TuKzuVt777AS6w 5 1 726351 0 24.7mb 24.7mbyellow open jaeger-span-2021-09-04 JfSHo2SGQxu-y16Lc90cKA 5 1 722567 0 24.3mb 24.3mbyellow open movies pQ1c784tQtKWREvHnKFItA 1 1 9743 0 1.2mb 1.2mb
health
ElasticSearch 提供了如下 API 可以查询集群的健康状态:
GET _cluster/health{"cluster_name" : "easyenv-elasticsearch","status" : "yellow","timed_out" : false,"number_of_nodes" : 1,"number_of_data_nodes" : 1,"active_primary_shards" : 214,"active_shards" : 214,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 202,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 51.442307692307686}
其中,最核心的资源之一就是 status 了,它表示了集群的状态。
集群的状态可能是如下三种状态:
- Green: 主分片和副本都正常分配。
- Yellow: 主分片分配正常,有副本分片未能正常分配。
- Red: 有主分片未分配。
node
ElasticSearch 提供了如下 API 可以查询节点列表:
GET _cat/nodes10.128.51.41 47 19 5 2.47 2.26 1.94 cdfhilmrstw * easyenv-elasticsearch-1

若有收获,就点个赞吧
0 人点赞
