前缀树
前缀树别名单词查找树、字典树,结构图为: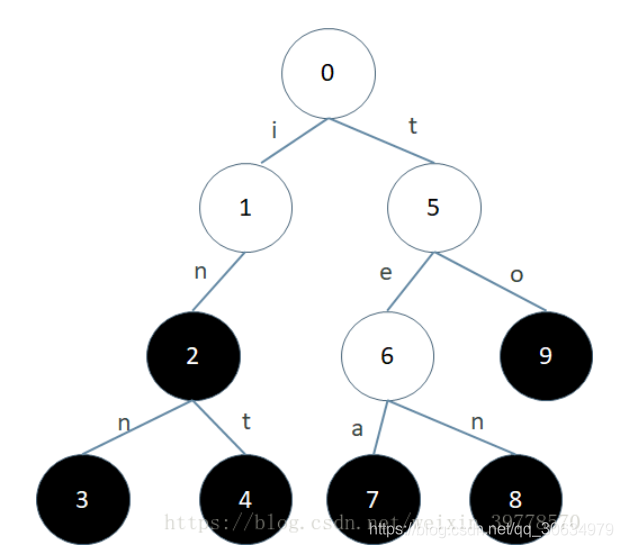
结构特性为:
根节点不存储值,除根节点外每一个节点都只包含一个字符(也可以说是在字符存在路径上)。
对应某一个节点,其子节点的值各不相同
从根节点到某一个节点,路径上经过的字符连接起来,为该叶子节点对应的字符串
应用场景:
前缀匹配
字符串检索
词频统计
优缺点:
查找效率高,耗费内存,典型的以空间换时间。
前缀树:
- 名称:Trie 字典树 查找树
- 特点:查找效率高 消耗内存大
- 应用:字符串检索 词频统计 字符串排序等
敏感词过滤器:
- 定义前缀树
- 根据敏感词 初始化前缀树
- 编写过滤敏感词的方法
过滤敏感词的检索原理
利用词的公共前缀缩小查词范围,提高检索效率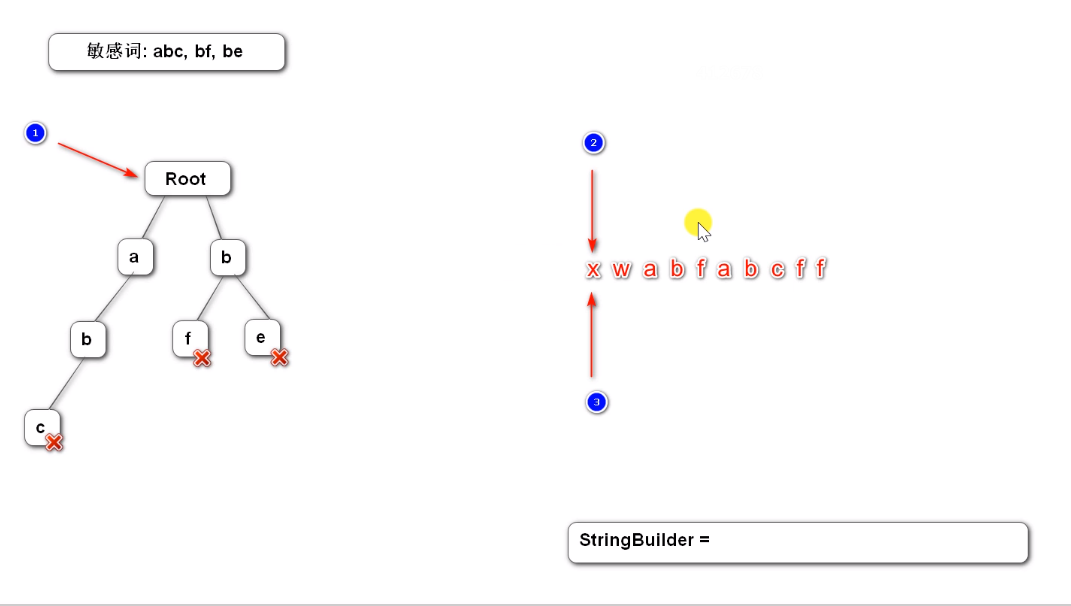
定义三个指针 :指针1 指向敏感词前缀树
指针2 指向疑似敏感词的开始位置
指针3 指向疑似敏感词的当前遍历部分
2,3指针指向字符x,1指针在树找,树中没有x,则x字符不是敏感词,将x记录到StringBuilder
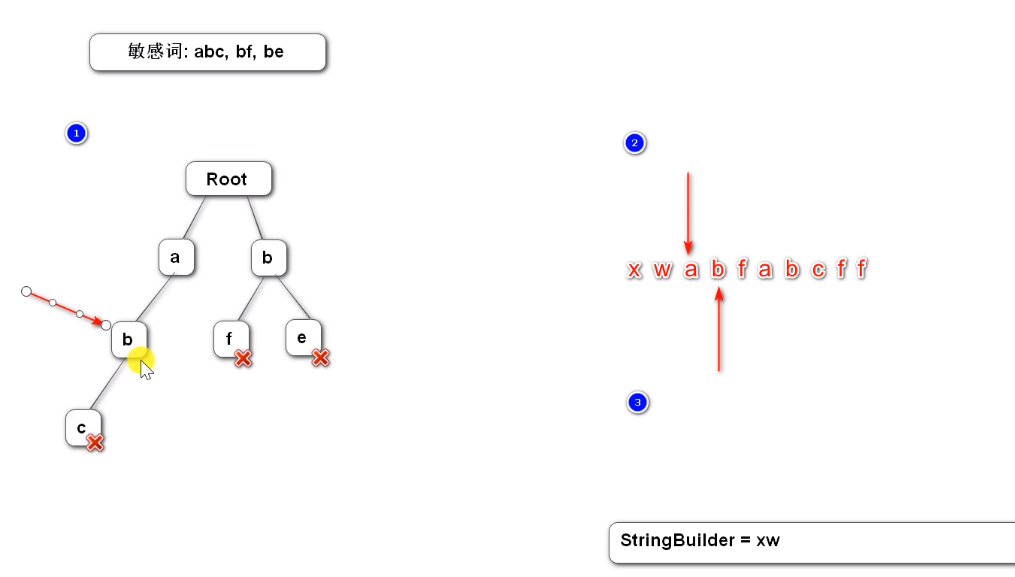
2,3指针向后移,判断w也不是敏感词,将其记录到StringBuilder中
移动到a时,疑似敏感词,2指针不动,1,3指针后移进行判断,c与f不同,故abf不是敏感词,指针3退回到指针2处,指针1退回到根节点处
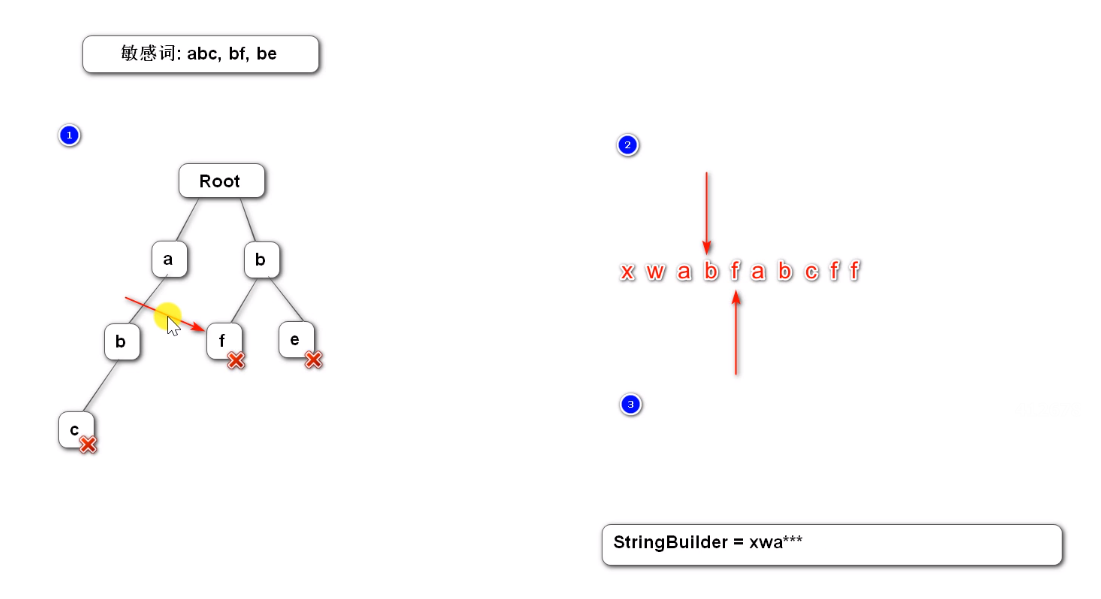
2,3指针继续向后移一位进行判断,按照上述步骤可以判断bf为敏感词,将其替换为*
2,3指针移动到a继续判断,直到结束
过滤敏感词的实现
1.定义一个前缀树的结构
private class TireNode{// 结尾的标记,判断是不是到达了前缀树的叶子节点,如果到达了,代表这是一个敏感词private boolean isKeyWord = false;// 存放节点和其子节点 为什么用mapprivate Map<Character, TireNode> subNodes = new HashMap<>();public boolean isKeyWord() {return isKeyWord;}public void setKeyWord(boolean keyWord) {isKeyWord = keyWord;}// 为某个节点添加子节点,构造敏感词的前缀树的时候使用public void setSubNodes(Character c, TireNode tireNode) {subNodes.put(c, tireNode);}// 获取子节点public TireNode getSubNode(Character c) {return subNodes.get(c);}}
2.根据设定的敏感词构造敏感词前缀树
// 声明一个不存值的根节点private TireNode rootNode = new TireNode();// 构造敏感词前缀树private void addKey(String keyWord) {TireNode tempNode = rootNode;for (int i = 0; i < keyWord.length(); i++) {char c = keyWord.charAt(i);TireNode subNode = tempNode.getSubNode(c);// 判断当前字符有没有子节点if (subNode == null) { // 没有子节点就初始化一个subNode = new TireNode();subNode.setSubNodes(c, subNode);}// tempNode 移动到 subNode 上,构建下一个字符tempNode = subNode;// 设置结束标志if (i == keyWord.length() - 1) {tempNode.setKeyWordEnd(true);}}}
什么意思呢?也就是说如果定义的敏感词是abc、bda、abd这三个,那么构造出来的敏感词前缀树的结构为: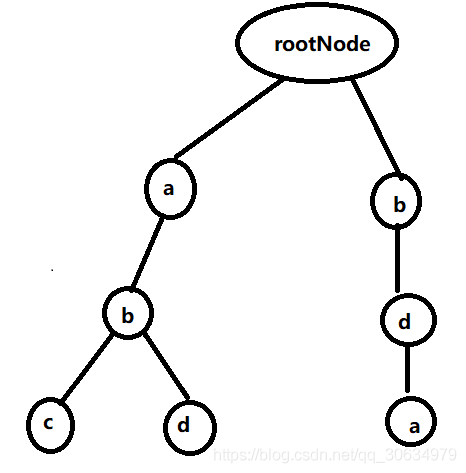
3. 根据输入内容,过滤其中的敏感词
// 过滤public String filter(String text) {if (text == null || text.length() == 0) {return null;}int length = text.length();// 指针1 指向敏感词前缀树TireNode tempNode = rootNode;// 指针2 指向疑似敏感词的开始位置int begin = 0;// 指针3 指向疑似敏感词的当前遍历部分int cur = 0;// 存放结果StringBuilder sb = new StringBuilder();while (cur < length) {char c = text.charAt(cur);// 检查前缀树的节点tempNode = tempNode.getSubNode(c);// 以begin位置的元素开头的字符串不是敏感词if (tempNode == null) {sb.append(c);tempNode = rootNode; // tempNode 重新指向根节点cur = ++begin; // begin 向前挪一个,cur 也回到begin 位置} else { // begin ~ cur 疑似是敏感词if (tempNode.isKeyWordEnd) { // tempNode 指向结尾 就是敏感词sb.append("***");tempNode = rootNode;begin = ++cur;} else {// 没到结尾,检查下一个字符cur++;}}}sb.append(text.substring(begin));return sb.toString();}
4. 测试
public static void main(String[] args) {MySensitiveFilter sensitiveFilter = new MySensitiveFilter();String text = "你好啊,赛利亚";sensitiveFilter.addKeyWord("好啊");String result = sensitiveFilter.filter(text);System.out.println(result);}


若有收获,就点个赞吧
0 人点赞
