https://mp.weixin.qq.com/s?__biz=MzI0NDc3ODE5OQ==&mid=2247485887&idx=2&sn=af4921239af612ec790722f696f0469f&chksm=e959dc07de2e5511f0c695e8b73d6ee642505e21171452ec9cdb3d67e2f677940372d405fb55&scene=178&cur_album_id=1744497649518493697#rd
为什么选择 Spring Boot?
1)从字面理解,Boot 是引导的意思,Spring Boot 可以帮助我们迅速的搭建 Spring 框架;
2)“约定大于配置”,一般来说,我们使用 Spring Boot 的时候只需要很少的配置,大部分情况下直接使用默认的配置即可;
3)Spring Boot 内嵌了 Web 容器,降低了对环境的要求,使得我们可以执行运行项目主程序的 main 函数;
4)最重要的,对于开发者来说,那当然是 Spring Boot 不需要编写大量的 XML 配置;
为什么选择 Kafka?
为什么使用消息队列
先来说一下为什么要使用消息队列,六个字总结:解耦、异步、消峰。
1)「解耦」
传统模式下系统间的耦合性太强。怎么说呢,举个例子:系统 A 通过接口调用发送数据到 B、C、D 三个系统,如果将来 E 系统接入或者 B 系统不需要接入了,那么系统 A 还需要修改代码,非常麻烦。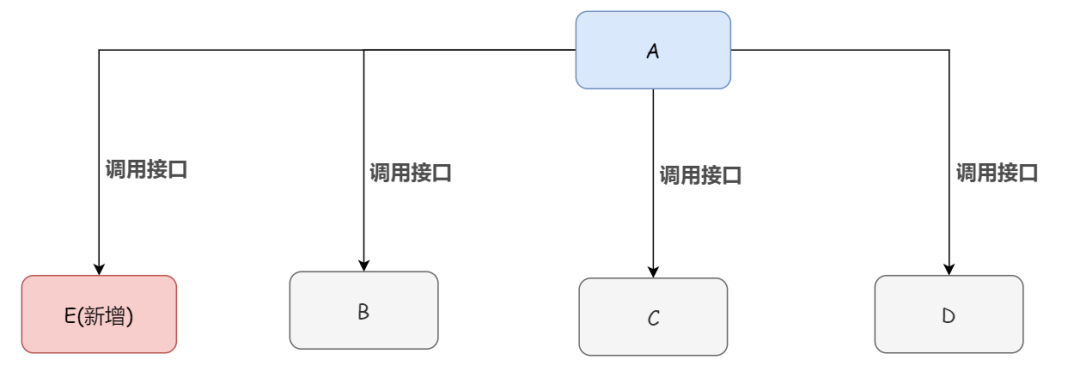
如果系统 A 产生了一条比较关键的数据,那么它就要时时刻刻考虑 B、C、D、E 四个系统如果挂了该咋办?这条数据它们是否都收到了?显然,系统 A 跟其它系统严重耦合。
而如果我们将数据(消息)写入消息队列,需要消息的系统直接自己从消息队列中消费。这样下来,系统 A 就不需要去考虑要给谁发送数据,不需要去维护这个代码,也不需要考虑其他系统是否调用成功、失败超时等情况,反正我只负责生产,别的我不管。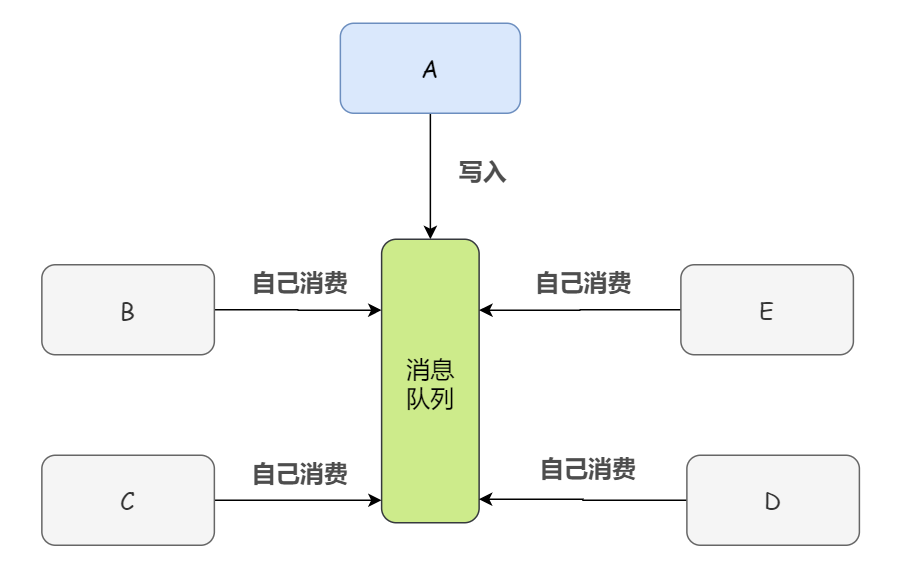
2)「异步」
先来看传统同步的情况,举个例子:系统 A 接收一个用户请求,需要进行写库操作,还需要同样的在 B、C、D 三个系统中进行写库操作。如果 A 自己本地写库只要 1ms,而 B、C、D 三个系统写库分别要 100ms、200ms、300ms。最终请求总延时是 1 + 100 + 200 + 300 = 601ms,用户体验大打折扣。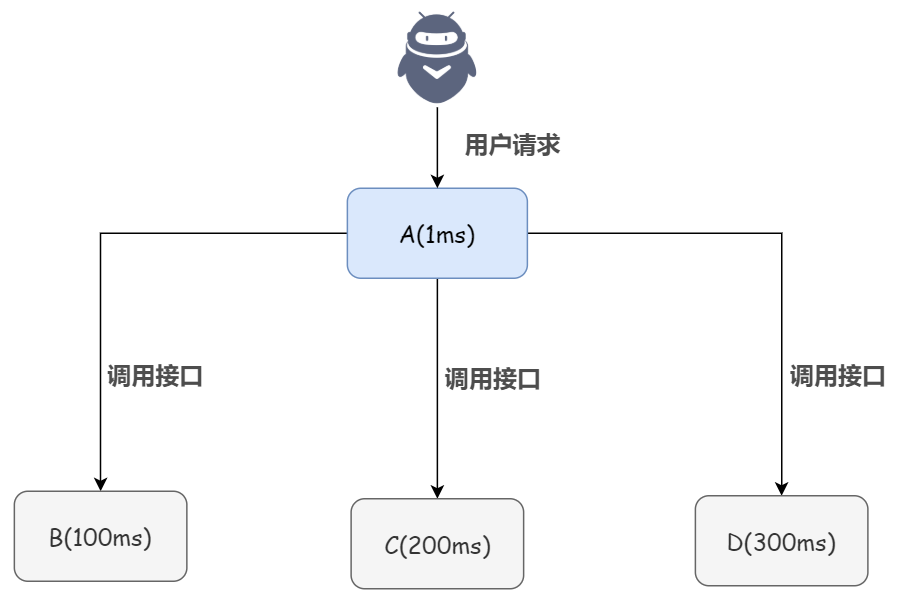
如果使用消息队列,那么系统 A 就只需要发送 3 条消息到消息队列中就行了,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 1 + 5 = 6ms,对于用户而言,体验好感度直接拉满。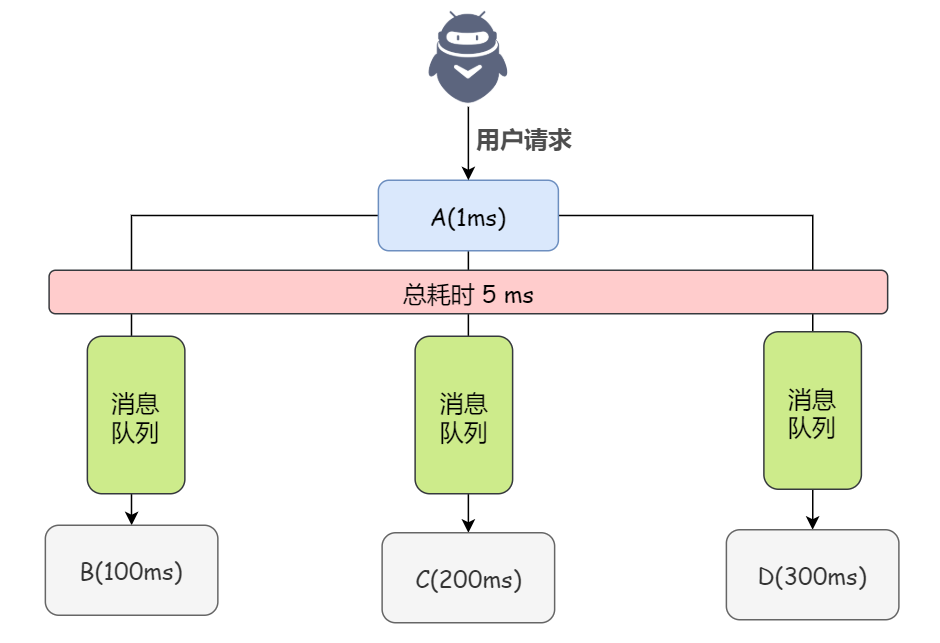
3)「消峰」
如果没有使用缓存或者消息队列,那么系统就是直接基于数据库 MySQL 的,如果有那么一个高峰期,产生了大量的请求涌入 MySQL,毫无疑问,系统将会直接崩溃。
那如果我们使用消息队列,假设 MySQL 每秒钟最多处理 1k 条数据,而高峰期瞬间涌入了 5k 条数据,不过,这 5k 条数据涌入了消息队列。这样,我们的系统就可以从消息队列中根据数据库的能力慢慢的来拉取请求,不要超过自己每秒能处理的最大请求数量就行。
也就是说消息队列每秒钟 5k 个请求进来,1k 个请求出去,假设高峰期 1 个小时,那么这段时间就可能有几十万甚至几百万的请求积压在消息队列中。不过这个短暂的高峰期积压是完全可以的,因为高峰期过了之后,每秒钟就没有那么多的请求进入消息队列了,但是数据库依然会按照每秒 1k 个请求的速度处理。所以只要高峰期一过,系统就会快速的将积压的消息给处理掉。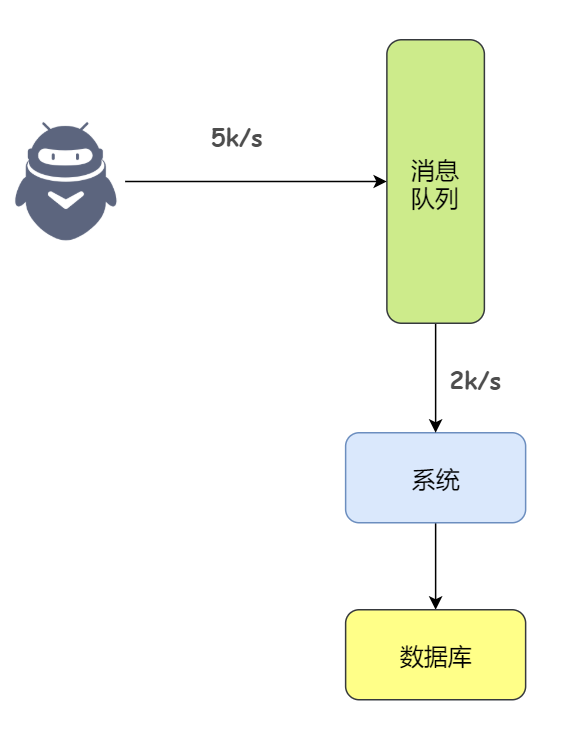
为什么选择 Kafka
再来看看在 Echo 这个项目中,哪些地方使用了消息队列也就是 Kafka: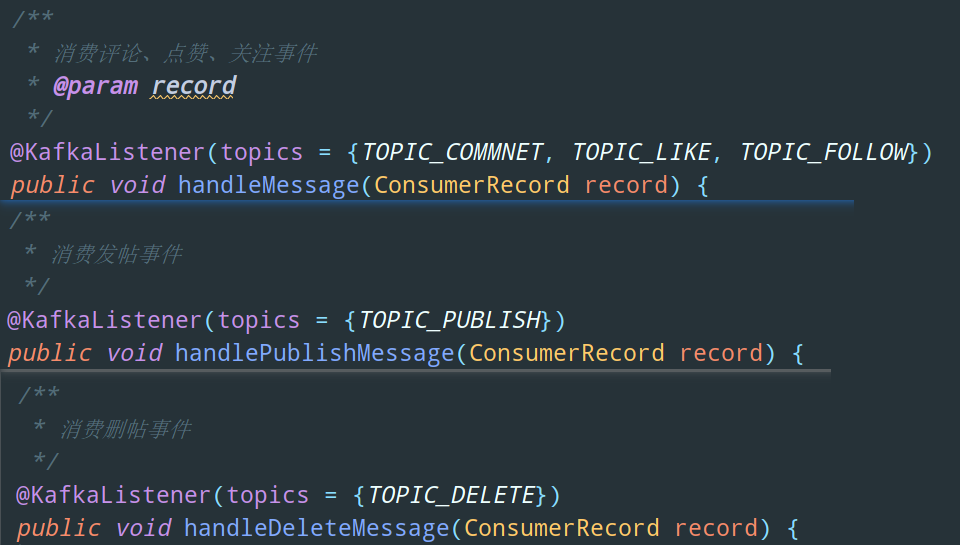
- 评论、点赞、关注事件触发通知
- 发帖事件触发 Elasticsearch 服务器中相应的数据更新
- 删帖事件触发 Elasticsearch 服务器中相应的数据更新
实际上在早期的时候 Kafka 并不是一个合格的消息队列,不过现在已经足够优秀。不说我们这个用户量比较小的论坛,从大体量的论坛项目来考虑,我觉得 Kafka 比较适合的原因有如下:
1)Kafka 天生支持分布式,Broker、Producer 和 Consumer 都原生自动支持分布式;
2)Kafka 拥有多分区(Partition)和多副本(Replica)机制,能提供比较好的并发能力(负载均衡)以及较高的可用性和可靠性,理论上支持消息无限堆积;
3)而且,在一众消息队列里,Kafka 的性能是比较高的。点赞、关注、私信等操作都会触发通知,在流量巨大的社交论坛网站中,这个系统通知的需求是非常庞大的,为保证系统的高性能,使用消息队列 Kafka 是个明智的选择。
kafka知识点及面试总结
kafka为什么性能高
页缓存
Kafka并不太依赖JVM内存大小,而是主要利用Page Cache,如果使用应用层缓存(JVM堆内存),会增加GC负担,增加停顿时间和延迟,创建对象的开销也会比较高。
读取操作可以直接在Page Cache上进行,如果消费和生产速度相当,甚至不需要通过物理磁盘直接交换数据,这是Kafka高吞吐量的一个重要原因。
这么做还有一个优势,如果Kafka重启,JVM内的Cache会失效,Page Cache依然可用。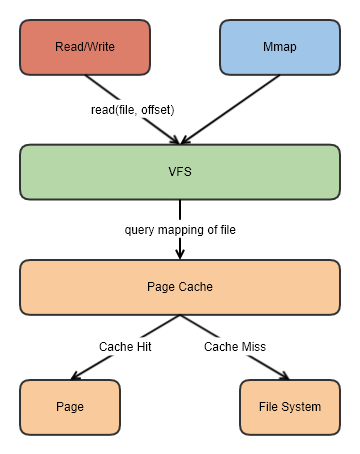
零拷贝
Kafka中存在大量的网络数据持久化到磁盘(Producer到Broker)和磁盘文件通过网络发送(Broker到Consumer)的过程。这一过程的性能直接影响Kafka的整体吞吐量。
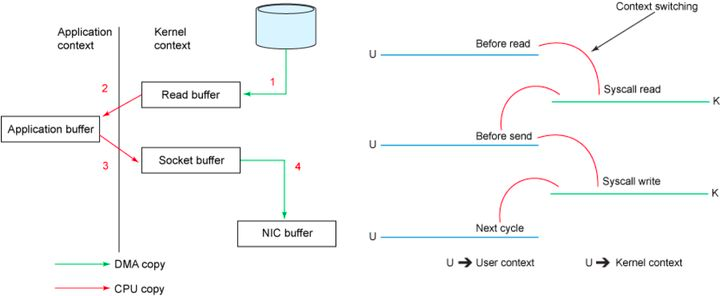
传统模式下的四次拷贝与四次上下文切换
以将磁盘文件通过网络发送为例。传统模式下,一般使用如下伪代码所示的方法先将文件数据读入内存,然后通过Socket将内存中的数据发送出去。
buffer = File.read Socket.send(buffer)
这一过程实际上发生了四次数据拷贝。首先通过系统调用将文件数据读入到内核态Buffer(DMA拷贝),然后应用程序将内存态Buffer数据读入到用户态Buffer(CPU拷贝),接着用户程序通过Socket发送数据时将用户态Buffer数据拷贝到内核态Buffer(CPU拷贝),最后通过DMA拷贝将数据拷贝到NIC Buffer。同时,还伴随着四次上下文切换。
sendfile和transferTo实现零拷贝
Linux 2.4+内核通过sendfile系统调用,提供了零拷贝。数据通过DMA拷贝到内核态Buffer后,直接通过DMA拷贝到NIC Buffer,无需CPU拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件-网络发送由一个sendfile调用完成,整个过程只有两次上下文切换,因此大大提高了性能。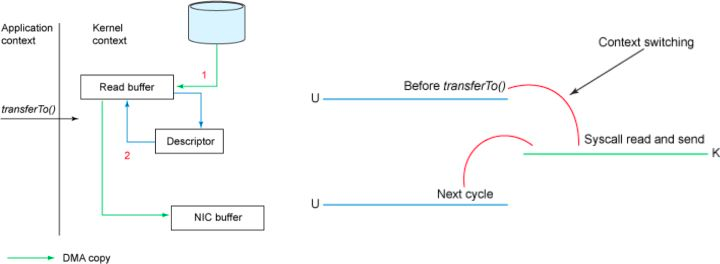
具体实现上,Kafka的数据传输通过TransportLayer来完成,其子类PlaintextTransportLayer通过Java NIO的FileChannel的transferTo和transferFrom方法实现零拷贝。
@Overridepubliclong transferFrom(FileChannel fileChannel, long position, long count) throws IOException {return fileChannel.transferTo(position, count, socketChannel);}
注: transferTo和transferFrom并不保证一定能使用零拷贝。实际上是否能使用零拷贝与操作系统相关,如果操作系统提供sendfile这样的零拷贝系统调用,则这两个方法会通过这样的系统调用充分利用零拷贝的优势,否则并不能通过这两个方法本身实现零拷贝。
磁盘顺序写入
即使是普通的机械磁盘,顺序访问速率也接近了内存的随机访问速率。
Kafka的每条消息都是append的,不会从中间写入和删除消息,保证了磁盘的顺序访问。
即使是顺序读写,过于频繁的大量小IO操作一样会造成磁盘的瓶颈,此时又变成了随机读写。Kafka的策略是把消息集合在一起,批量发送,尽可能减少对磁盘的访问。所以,Kafka的Topic和Partition数量不宜过多,可以看阿里云中间件团队的这篇文章:Kafka vs RocketMQ——多Topic对性能稳定性的影响,超过64个Topic/Partition以后,Kafka性能会急剧下降。
RocketMQ存储模型与Kafka有些差异,RocketMQ会把所有的数据存放在相同的日志文件,所以单机可以支持非常多的队列。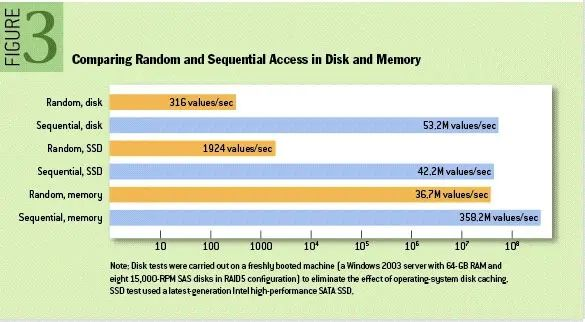
全异步
Kafka基本上是没有阻塞操作的,调用发送方法会立即返回,等待buffer满了以后交给轮询线程,发送和接收消息,复制数据也是都是通过NetworkClient封装的poll方式。
批量操作
结合磁盘顺序写入,批量无疑是非常有必要(如果用的时候每发送一条消息都调用future.get等待,性能至少下降2个数量级)。写入的时候放到RecordAccumulator进行聚合,批量压缩,还有批量刷盘等…
精妙的组件设计
Kafka里有不少精妙的设计,比如说DelayedOperationPurgatory和多层TimingWheel,保证了大量延迟任务的高性能。

若有收获,就点个赞吧
0 人点赞
