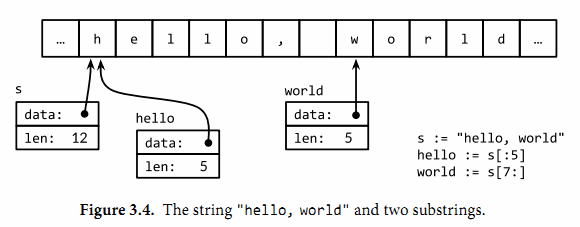
字符串是一个不可改变的字节序列。字符串可以包含任意的数据,但是通常是用来包含可读的文本。
Go 语言的字符串
Go 语言的字符串 是一个 不可改变 的 UTF-8 字符序列。
Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。
Unicode标准为全球各种人类语言中的每个字符制定了一个独一无二的值。 Unicode标准中的基本单位不是字符,而是码点(code point)。 大多数的码点实际上就对应着一个字符,但也有少数一些字符是由多个码点组成的。 码点值在Go中用rune值来表示。 内置rune类型为内置int32类型的一个别名。
一个 ASCII 码占用 1个字节,其它字符根据需要占用 2-4 个字节。
这样设计的好处有两个:
- 减少内存的使用,节约硬盘空间
统一编码格式(UTF-8)有助于减少读取文件时的编码和解码工作
字符串
声明与初始化
- 长度
- 遍历
- 字符串可以为空,但不能为nil
- 且字符串的值是不能改变的
- 截取 ```c package main
import ( “fmt” “unicode/utf8” )
func init() { str := “hello, 世界”
println("hello, 世界 length: ", len(str)) // 13fmt.Println("hello, 世界 length: ", utf8.RuneCountInString(str)) // 9r := []rune(str)fmt.Println("hello, 世界 length: ", len(r)) //9/*hello, 世界 length: 13hello, 世界 length: 9hello, 世界 length: 9*/// 错误,字符串是不能更改的// str := "hello, world"
}
func init() { str2 := “hello, world”
println("\nhello, world length: ", len(str2)) // 12fmt.Println("hello, world length: ", utf8.RuneCountInString(str2)) // 12r2 := []rune(str2)fmt.Println("hello, world length: ", len(r2)) //9/*hello, world length: 12hello, world length: 12hello, world length: 12*/
}
/* 每一次调用DecodeRuneInString函数都返回一个r和长度,r对应字符本身,长度对应r采用UTF8编码后的编码字节数目 / func init() { str := “hello, 世界” for i := 0; i < len(str); { r, size := utf8.DecodeRuneInString(str[i:]) fmt.Printf(“%d \t %c\n”, i, r) i += size }
/**0 h1 e2 l3 l4 o5 ,67 世10 界*/
}
func init() { str := “hello, world”
str = str[7:]fmt.Println(str) // world
}
func main() {
}
<br /><a name="USO55"></a># 字符串和Byte切片在看go一些库源码中会有很多地方使用 `[]byte`<a name="KCDkh"></a>## char & byte 对应关系> [https://www.yuque.com/ueumd/blog/zo8lcn](https://www.yuque.com/ueumd/blog/zo8lcn)| **C语言类型** | **CGO类型** | **Go语言类型** || --- | --- | --- || char | C.char | byte || ... | ... | ... |<a name="oQzEW"></a>## 体会下C语言中的字符串C 语言没有原生的字符串类型,而是使用字符数组来表示字符串,并以字符指针来传递字符串。<br />C中的 字符、字符数组 、 字符串定义> [https://www.yuque.com/ueumd/clang/gazmtm](https://www.yuque.com/ueumd/clang/gazmtm)```c// 定义 字符char c = 'a'// 定义 字符数组char charArr[] = {'a','b','c','d','e'}// 定义 字符串char str[11] = "I am happy"; // 用数组的形式修改定义的字符串值char str[] = "I am happy"; // 自动分配内存空间char *pStr = "I am happy"; // 指针方式
Go 字符串定义
Go源码中 src/runtime/string.go,string定义如:
type stringStruct struct {str unsafe.Pointerlen int}
可以看到 str 是一个指针,指向某个数组的首地址。
继续看代码可以找到,实例化这个stringStruct的方法。
//go:nosplitfunc gostringnocopy(str *byte) string {ss := stringStruct{str: unsafe.Pointer(str), len: findnull(str)}s := *(*string)(unsafe.Pointer(&ss))return s}
其实就是byte数组,而且 string其实就是个struct!
何为[]byte?
Go,byte是uint8的别名。slice结构在go的源码中 src/runtime/slice.go定义如:
type slice struct {array unsafe.Pointerlen intcap int}
- array 数组的指针
- len 长度
- cap 容量
除了cap,和string的结构很像。
但其实他们差别真的很大
字符串的值是不能改变的
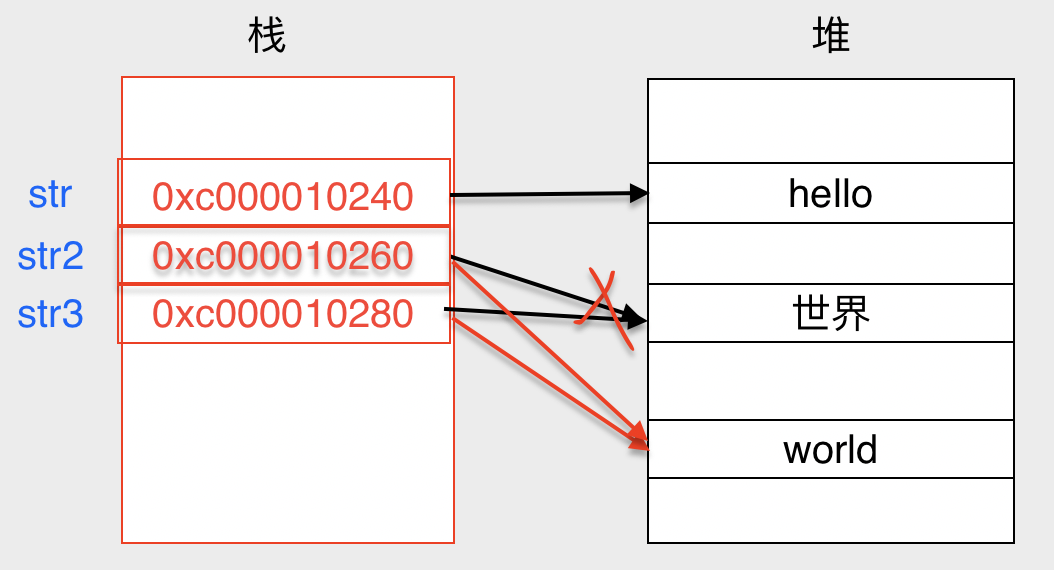
func main() {str := "hello"fmt.Printf("&str: %p \t str: %v", &str, str)str2 := "世界"fmt.Printf("\n&str2: %p \t str2: %v", &str2, str2)str3 := str2fmt.Printf("\n&str3: %p \t str3: %v", &str3, str3)str3 = "world"fmt.Printf("\n&str3: %p \t str3: %v", &str3, str3)str2 = "world"fmt.Printf("\n&str2: %p \t str2: %v", &str2, str2)/**&str: 0xc000010240 str: hello&str2: 0xc000010260 str2: 世界&str3: 0xc000010280 str3: 世界&str3: 0xc000010280 str3: world&str2: 0xc000010260 str2: world*/}
因为string的指针指向的内容是不可以更改的,所以每更改一次字符串,就得重新分配一次内存,之前分配空间的还得由gc回收,这也是导致string操作低效的根本原因。
我们定义了
str2, 指向堆中的 一块地址中的内容 “世界”
str3 也指向了str2中的内容
str3 重新赋值 开辟新空间,内容为world
str2 指向了str3新空间
原来的 “世界” 还会在堆中,中是变成了垃圾内容,被回收。
参考:

若有收获,就点个赞吧
0 人点赞
