向量和向量空间
内积
 维线性空间中的两个向量
维线性空间中的两个向量  和
和  ,内积为:
,内积为:
正交
如果向量空间中两个向量的内积为 0 ,则它们正交。如果向量空间中的一个向量  与子空间
与子空间  中每个向量都正交,那么向量
中每个向量都正交,那么向量  和子空间正交。
和子空间正交。
Hadamard 积

笛卡尔乘积
在集合论中表示 为  ,是所有可能的有序对组成的集合,其中有序对的第一个对象是
,是所有可能的有序对组成的集合,其中有序对的第一个对象是  的成员,第二个对象是
的成员,第二个对象是  的成员
的成员
常见函数
Logistic 函数
Logistic 函数是一种常用的 S 形函数,定义为
这里  函数表示自然对象,
函数表示自然对象, 是中心点,
是中心点, 是最大值,
是最大值, 是曲线的倾斜度。
是曲线的倾斜度。
标准 logistic 函数,记为 

经常用来将一个实数空间的数映射到 (0,1)区间。
Softmax 函数
softmax 函数是将多个标量映射为一个概率分布,对于  个标量
个标量  softmax 函数定义为
softmax 函数定义为
可以将  个标量
个标量  转换为一个分布:
转换为一个分布: , 满足
, 满足
当输入为  维向量
维向量  时,
时,
其中, 是
是  维的全 1 向量。
维的全 1 向量。
梯度下降法
梯度下降法(Gradient Descent Method),经常用来求解无约束的极小值问题。梯度下降法的过程:
曲线是等高线(水平集),即函数  为不同常数集合构成的曲线。红色箭头指向该点梯度的反方向(梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达函数
为不同常数集合构成的曲线。红色箭头指向该点梯度的反方向(梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达函数  值的局部最优解。
值的局部最优解。
梯度下降法为一阶收敛算法,当靠近极小值时梯度变小,收敛速度会变慢,并且可能以“之字形”的方式下降。如果目标函数为二阶连续可微,我们可以采用牛顿法。牛顿法为二阶收敛算法,收敛速度更快,但是每次迭代需要计算
Hessian矩阵的逆矩阵,复杂度较高。
梯度上升法(Gradient Ascent): 如果求解一个最大值,就需要向梯度正方向迭代进行搜索,逐渐接近函数的局部极大值点。
概率论
伯努利分布
在一次试验中,事件 A 出现的概率为  ,不出现的概率为
,不出现的概率为  。若用变量
。若用变量  表示事件 A 出现的次数,则
表示事件 A 出现的次数,则  的取值为 0 和 1,其相应的分布为
的取值为 0 和 1,其相应的分布为
这个分布为伯努利分布(Bernoulli Distribution),又叫两点分布或者 0-1 分布。
二项分布
在  次伯努利分布中,若以变量
次伯努利分布中,若以变量  表示事件 A 出现的次数,则 X 的取值为
表示事件 A 出现的次数,则 X 的取值为  ,其相应的分布为二项分布(Binominal Distribution)
,其相应的分布为二项分布(Binominal Distribution)
其中  为二项式系数,表示从
为二项式系数,表示从  个元素中取出
个元素中取出  个元素而不考虑其顺序的组合的总数。
个元素而不考虑其顺序的组合的总数。
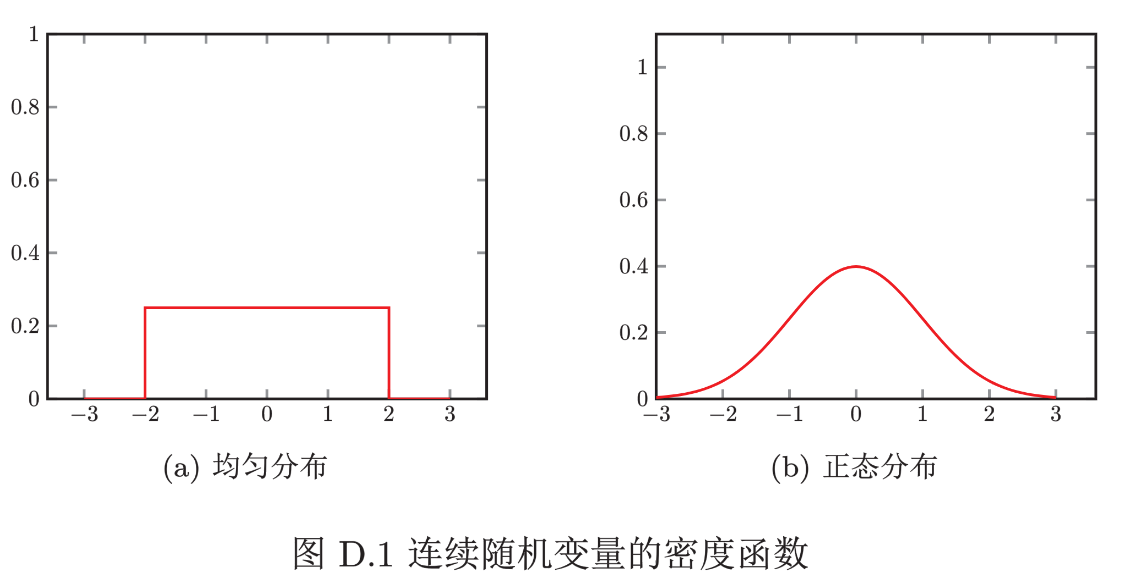
均匀分布
若 a,b 为有限数,[a,b]上的均匀分布的概率密度函数定义为
正态分布
正态分布式自然界最常见的一种分布,并且具有很多良好的性质,在很多领域都有非常重要的影响力,其概率密度函数为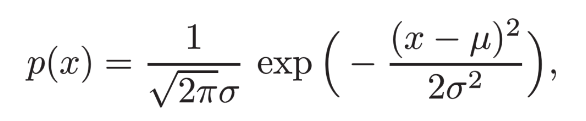
多项分布

若有收获,就点个赞吧
0 人点赞
