语言模型与词嵌入:https://www.yuque.com/yzxm/rt4zp3/qq6plm#gI5WZ
向量空间模型(Vector Space Model, VSM)
向量空间模型的基本思想:将一个文本映射到由多个文本构成的向量空间,用向量来表示。一个文本通常由多个词组成,每个词在决定句子含义的重要程度,即词权重,是不一样的。如何计算词的权重呢?
词集模型(Set of Word, SoW)
不考虑词频,只考虑单词是否在文本中出现。即出现对应位置设为 1,否则置 0 。
词袋模型 (Bag of Word, BOW)
考虑词表(vocabulary)中单词在文档中出现的次数。将每个词在文档中出现的次数作为对应位置的值。
TF-IDF
词频(Term Frequency, TF):单词  在文档 Di 中出现的频率:
在文档 Di 中出现的频率:
逆文本频率(Inverse Document Frequency, IDF):需要统计出现单词 w的文档数,越多的文档包含这个词则说明这个单词越普遍,其IDF值就越低:
其中,N 为文档总数, 表示文档
表示文档  是否包含单词
是否包含单词  , 若包含则为 1, 否则为 0 。考虑到如果词
, 若包含则为 1, 否则为 0 。考虑到如果词  在所有文档中均未出现,为了避免 IDF 公式中的分母为 0 ,对 IDF 做了平滑(smooth)处理。
在所有文档中均未出现,为了避免 IDF 公式中的分母为 0 ,对 IDF 做了平滑(smooth)处理。
TF-IDF:
# -*- coding: utf-8 -*-import osimport randomimport mathfrom collections import defaultdictimport numpy as npclass TFIDF(object):"""docstring for TFIDF"""def __init__(self):self.word2idx = {"<pad>": 0, "<unk>": 1}self.word2df = defaultdict(int)#self.type2idx = {}self.tf_dict = {}self.text_lists = []def process_data(self, datas, vocab_list):for word in vocab_list:if word not in self.word2idx:self.word2idx[word] = len(self.word2idx)for data in datas:self.text_lists.append(data['text'])for word in set(data['text']):if word in self.word2idx:self.word2df[word] += 1else:self.word2df["<unk>"] += 1def get_tf(self):"""获得文档的 TF 向量"""tf_vec = []for text in self.text_lists:vec = [0] * len(self.word2idx)words = set(text)for word in words:if word in self.word2idx:vec[self.word2idx[word]] = text.count(word) / len(text)else:vec[self.word2idx["<unk>"]] = 0tf_vec.append(vec)return np.array(tf_vec)def get_idf(self):"""获得文档的 idf 向量"""total = len(self.text_lists)idf_vec = []for text in self.text_lists:vec = [0] * len(self.word2idx)words = set(text)for word in words:if word in self.word2idx:vec[self.word2idx[word]] = math.log(total + 1.0) - math.log(self.word2df[word] + 1.0)else:vec[self.word2idx["<unk>"]] = 0idf_vec.append(vec)return np.array(idf_vec)def get_tfidf(self, datas, vocab_list):self.process_data(datas, vocab_list)tf = self.get_tf()idf = self.get_idf()tfidf = tf * idfreturn tfidf
BM25
BM25 算法是一种常见用来做相关度打分的公式,它是 TF-IDF 算法的优化。给定查询语句  和一篇文档
和一篇文档 ,
, 为查询语句的第
为查询语句的第  个词。BM25 主要就是计算
个词。BM25 主要就是计算  里面所有词和文档的相关度,然后乘以词相应的权重,最后再把分数累加操作,计算公式:
里面所有词和文档的相关度,然后乘以词相应的权重,最后再把分数累加操作,计算公式:
其中, 是查询语句
是查询语句 中每个词
中每个词  和文档
和文档  的相关度值,
的相关度值, 是每个词所对应的权重,
是每个词所对应的权重, 为查询语句中词的个数。
为查询语句中词的个数。 相当于 TF-IDF 算法中的 IDF 值,即逆向文档频率,计算公式:
相当于 TF-IDF 算法中的 IDF 值,即逆向文档频率,计算公式:
其中, 是文档总数,
是文档总数, 是包含该词的文档数,为了避免分子分母为 0 ,做了平滑处理。
是包含该词的文档数,为了避免分子分母为 0 ,做了平滑处理。 相当于 TF-IDF 算法中的 TF,其计算公式:
相当于 TF-IDF 算法中的 TF,其计算公式:

其中 
 ,
,  ,
,  都是调节因子,一般
都是调节因子,一般  ,
, ,
, 。(
。( 越大,则文档长度所占的影响因素越大)
越大,则文档长度所占的影响因素越大)
 为词
为词  在查询语句
在查询语句  中出现的频率;
中出现的频率; 为词
为词  在文档
在文档  中的出现频率;
中的出现频率; 为文档
为文档  的长度;
的长度; 为所有文档的平均长度。即文档长度和平均长度比值越大,则
为所有文档的平均长度。即文档长度和平均长度比值越大,则  越大,则相关度越小。
越大,则相关度越小。
由于绝大多数情况下,一条简短的查询语句  中,词
中,词  只会出现一次,即
只会出现一次,即  ,因此公式最终可简化为:
,因此公式最终可简化为:

优缺点
适用于在文档包含查询词的情况下,或者说查询词精确命中文档的前提下,计算相似度或者对内容进行排序。
不适用于:基于传统检索模型的方法会存在一个固有缺陷,就是检索模型只能处理 Query 与 Document 有重合词的情况,无法处理词语的语义相关性。
# -*- coding: utf-8 -*-import numpy as npfrom collections import Counterimport jiebaclass BM25(object):"""docstring for BM25"""def __init__(self, documents_list, k1=2, k2=1, b=0.5 ):self.documents_list = documents_listself.documents_N = len(documents_list)self.avg_documents_len = sum(len(document) for document in documents_list) / self.documents_Nself.f = []self.idf = {}self.k1 = k1self.k2 = k2self.b = bself.init()def init(self):df = {}for document in self.documents_list:tmp = {}for word in document:tmp[word] = tmp.get(word, 0) + 1#print("tmp>>>", tmp)self.f.append(tmp)for key in tmp.keys():df[key] = df.get(key, 0) + 1for key, value in df.items():self.idf[key] = np.log((self.documents_N - value + 0.5)) / (value + 0.5)def get_score(self, index, query):score = 0.0document_len = len(self.f[index])#print("The length of doucument_{} is {} >>>".format(index, document_len))qf = Counter(query)for q in query:if q not in self.f[index]:continuescore += self.idf[q] * (self.f[index][q] * (self.k1 + 1) / (self.f[index][q] + self.k1 * (1 - self.b + self.b * document_len / self.avg_documents_len))) * (qf[q] * (self.k2 + 1) / (qf[q] + self.k2))return scoredef get_scores(self, query):score_list = []for i in range(self.documents_N):score_list.append(self.get_score(i, query))return score_listif __name__ == "__main__":documents_corpus = ["5月15日17:17,薛之谦第十张实体专辑《尘》正式开启预售。","薛之谦将音乐性与艺术性相结合,以其具有文学性的思考和饱含故事性的细腻声线,将他对音乐的探索与积淀注入其中,呈现出属于个人风格的独特味道。","专辑封面由几何图形构成,概念化处理的“沙丘”、突出的“鹿”和“马”元素,黑色与红色的色彩碰撞,则寓意尘世的繁复庞杂与现实是非混淆的境况,矛盾但充满希望。","稻草华文官博发布公告,宣布2020蔡依林UglyBeauty演唱会深圳站将延期举行。据悉,此次蔡依林深圳站演唱会原计划将于2月28日-29日举办,基于保障观众的健康和安全的考量,决定延期举办该次演唱会,具体演出时间将另行通知。","从歌曲的选择及整张专辑的主题上来看,《尘》通过将音乐与各种艺术性相结合,多维度展现出了于现实与理想、理智与感性中穿梭的音乐内涵,由旋律而起,追寻真谛、解构情绪、拥抱感动。","以抽象风格点缀视觉创意,以思辨语言传递音乐思考,薛之谦发行的第十张实体专辑《尘》融合美学与艺术,诉说着他十年以来的音乐故事。"]documents_list = [list(jieba.cut(document)) for document in documents_corpus]print(documents_list)bm25 = BM25(documents_list)#print(bm25.documents_list)#print("文档总数>>>", bm25.documents_N)#print("平均文档长度>>>", bm25.avg_documents_len)print("f>>>", bm25.f)print("idf>>>", bm25.idf)query = "薛之谦发表的专辑是什么"query = list(jieba.cut(query))scores = bm25.get_scores(query)print("scores>>>", scores)

One-hot
One-hot编码,又称为一位有效编码,主要是采用 N 位状态寄存器来对 N 个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
词向量的维度为整个词词汇表  的大小
的大小  ,将词汇表中的每个词看作一个特征,如果这个词出现,则这个特征的值为 1,否则为 0 。
,将词汇表中的每个词看作一个特征,如果这个词出现,则这个特征的值为 1,否则为 0 。
比如有四个词“白”,“黑”,“狗”,“猫”,词汇表大小为 4。它们向量可表示为
v白 = [1 0 0 0]T
v黑 = [0 1 0 0]T
v狗 = [0 0 1 0]T
v猫 = [0 0 0 1]T
one-hot 类型的词向量维度与词表的大小成正比,是一种高维稀疏的表示方法,这种表示方法导致其在计算上具有比较低效率。缺点:
- 计算效率低(0太多,而 1 只有 1 个);
- 词与词之间的编码是正交的不含语义信息。
为了避免这个问题,可以将高维的局部表示向量空间R|V|映射到一个非常低维的空间Rd。d 一般取值范围在 [20,500]。这个低维空间中的表示就是分布式表示。
词嵌入(Word Embedding):对于词的分布式表示(即低维稠密向量表示)
Word2vec
漫谈Word2vec之skip-gram模型
word2vec 是基于分布式的假设。skip-gram 模型的本质是计算输入 word 的 input vector 与目标 word 的 output vector 之间的余弦相似度,并进行 d=softmax 归一化。

- 输入层:用 one-hot 编码表征的,高维稀疏,维度一般是 [1, vocab_size].
- 隐藏层:随机初始化的词嵌入层(一般用正态分布初始化),没有激活函数, 维度一般是[vocab_size, embed_size],词嵌入层矩阵中每一行代表一个词的词向量。通过共享权值训练得到一张含有先验知识的词嵌入层,从而可用于语义计算和迁移学校等任务,隐藏层是我们最终要使用的权重矩阵。
- 输出层:其实就是一个 softmax 分类器,它的分类空间大小为词典大小。

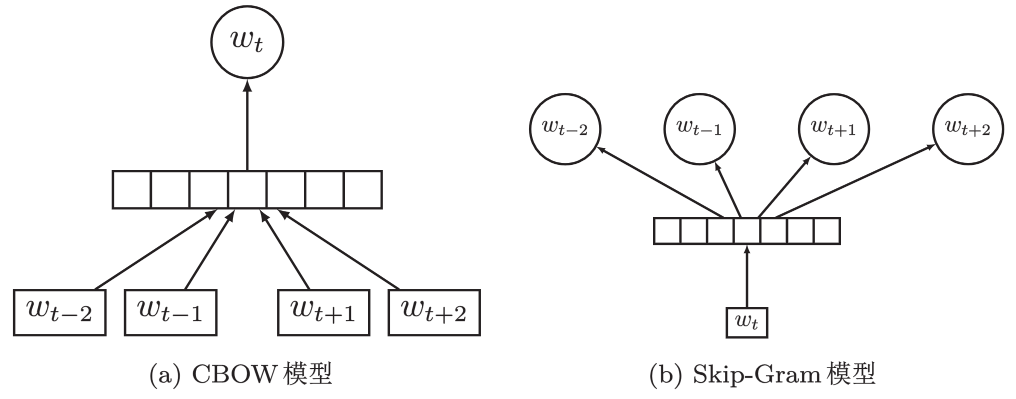
CBOW
给定一个词  的其上下文
的其上下文  连续词袋模型(Continuous Bags-of-Words, CBOW)是该词
连续词袋模型(Continuous Bags-of-Words, CBOW)是该词  出现的条件概率:
出现的条件概率:
其中, 表示上下文信息
表示上下文信息
在 CBOW 模型中,直接将隐藏层去掉,大大减少了计算量,提高了计算速度。给定一个训练文本训练  ,CBOW 的目标函数为:
,CBOW 的目标函数为:
Skip-Gram
给定一个词  ,预测词汇表中每个词出现在其上下文的概率。
,预测词汇表中每个词出现在其上下文的概率。
其中, 表示词
表示词  在输入词嵌入矩阵中的词向量,
在输入词嵌入矩阵中的词向量, 表示词
表示词  在输出词嵌入矩阵中的词向量。Skip-Gram 模型没有隐藏层,
在输出词嵌入矩阵中的词向量。Skip-Gram 模型没有隐藏层, 直接等于词嵌入
直接等于词嵌入  。给定一个训练文本训练
。给定一个训练文本训练  ,skip-gram 的目标函数为:
,skip-gram 的目标函数为:
在 Word2Vec 中,CBOW 和 Skip-Gram 模型都可以通过两种训练方法来加速训练:
- 层次化 softmax。在 Word2Vec 中采样了 Huffman 树来进行词汇表的层次化。
- 负采样(Negative Sampling)方法可以看成是噪声对比估计方法的一个简化版本。
Word2Vec 加速技巧:
- 删除隐藏层,得到上下文c的表示后,直接输入到 softmax 分类器来预测输出。也就是说,整个网络的参数只有两个词嵌入表:输入词嵌入表和输出词嵌入表;
- 使用层次化 softmax 或负采样进行加速训练;
- 去除低频词。出现次数小于一个预设值 minCount 的词直接去除。
- 对高频词进行降采样。
- 动态上下文窗口大小。
- 噪声分布使用一元语言模型
 的
的  ,
,  为归一化因子。相当于对高频词进行降采样,对低频词进行上采样。
为归一化因子。相当于对高频词进行降采样,对低频词进行上采样。
Fasttext
fastText原理及实践
word2vec把语料库中的每个单词当成原子的,它会为每个单词生成一个向量。这忽略了单词内部的形态特征,比如:“apple” 和“apples”,例子中,两个单词都有较多公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的id丢失了。
为了克服这个问题,fastText使用了字符级别的n-grams来表示一个单词。对于单词“apple”,假设n的取值为3,则它的 trigram 有:
其中,<表示前缀,>表示后缀。可以用这5个 trigram 的向量的叠加求和来表示 “apple”的词向量。
fasttext 和 CBOW 的相同点:fastText 模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的 target,隐含层都是对多个词向量的叠加平均。
fasttext 和 CBOW 的不同之处:CBOW 的输入是目标单词的上下文,fastText 的输入是多个单词及其 n-gram 特征,这些特征用来表示单个文档;CBOW 的输入单词被onehot 编码过,fastText 的输入特征是被 embedding 过;CBOW 的输出是目标词汇,fastText 的输出是文档对应的类标。
fastText在输入时,将单词的字符级别的n-gram向量作为额外的特征;在输出时,fastText采用了分层Softmax,大大降低了模型训练时间。GloVe
GloVe 本质是加权最小二乘回归模型,引入了共现概率矩阵。
基本思想:首先引入词-词共现矩阵 ,
, 表示在语料库中
表示在语料库中  的上下文中出现
的上下文中出现  的次数。
的次数。
| Patio = Pik/Pjk | 单词 j 和单词 k 相关 | 单词 j 和单词 k 不相关 |
|---|---|---|
| 单词 i 和单词 k 相关 | 趋近 1 | 很大 |
| 单词 i 和单词 k 不相关 | 很小 | 趋近1 |
GloVe模型的目标就是获取每个词的向量表示  。GloVe 认为,
。GloVe 认为, 通过某种函数
通过某种函数  的作用后呈现出来的规律和
的作用后呈现出来的规律和  具有一致性,或者说相等,这样子也就可以认为词向量中包含了共现概率矩阵中的信息。
具有一致性,或者说相等,这样子也就可以认为词向量中包含了共现概率矩阵中的信息。
此,对于任意一对词 i 和 j,用它们的词向量表达共现概率比值最终可以被简化为表达他们共现词频的对数:
上式中的共现词频是直接在训练数据上统计得到的,为了学习词向量和相应的偏移项,我们希望上式中的左边与右边越接近越好,给定词典大小 和权重函数
和权重函数  ,我们定义损失函数为
,我们定义损失函数为
对于权重 ,一个建议的选择是,当x
,一个建议的选择是,当x
- 训练快;可以扩展;
- 因为考虑了很多统计资讯,即使在小数据库上、小向量上也能表现得很好。

若有收获,就点个赞吧
0 人点赞
