前馈神经网络

假设历史信息只包含前面  个词。首先将这
个词。首先将这  个词的词向量
个词的词向量 拼接为一个维度为
拼接为一个维度为  的向量
的向量  。
。
然后将  输入到由多层前馈神经网络构成的隐藏层,最后一层隐藏层的输出为
输入到由多层前馈神经网络构成的隐藏层,最后一层隐藏层的输出为  。比如,只含一层隐藏层的模型为:
。比如,只含一层隐藏层的模型为:
前馈神经网络也可以包含跳层连接(Skip-Layer Connections):
循环神经网络 RNN
RNN 是一类具有短期记忆能力的神经网络。当输入序列比较长时,会存在梯度爆炸和消失问题,也成为了长期依赖问题。如果  时刻的输出
时刻的输出 依赖于
依赖于  时刻的输入
时刻的输入  ,当间隔
,当间隔  比较大时,简单神经网络很难建模这种长距离的依赖关系,称为长期依赖问题(Long-Term Dependencies Problem)。
比较大时,简单神经网络很难建模这种长距离的依赖关系,称为长期依赖问题(Long-Term Dependencies Problem)。
与前馈神经网络不同,循环神经网络可以接受变长的输入序列,依次接受输入  得到
得到  时刻的隐藏状态
时刻的隐藏状态  :
:
其中  = 0。
= 0。 不仅和当前时刻的输入
不仅和当前时刻的输入  相关,也和上一时刻的隐藏状态
相关,也和上一时刻的隐藏状态  相关。
相关。 为状态=权重矩阵,
为状态=权重矩阵, 为状态-输入权重矩阵,
为状态-输入权重矩阵,  为偏置。
为偏置。
前馈网络语言模型和循环网络语言模型的不同之处:循环神经网络利用隐藏状态来记录以前所有时刻的信息,而前馈神经网络只能接受前 n−1 个时刻的信息。
- 输出层:
输出层大小为  ,输入为历史信息的向量表示
,输入为历史信息的向量表示  ,输出为每个词的后验概率。一般使用 softmax 分类器:
,输出为每个词的后验概率。一般使用 softmax 分类器:
其中,输出向量  为一个概率分布,其第
为一个概率分布,其第  维是词汇表中第
维是词汇表中第  个词出现的后验概率;
个词出现的后验概率; 是最后一层隐藏层到输出层直接的权重,也成为输出词嵌入矩阵,矩阵中每一行可以看作是一个词向量。
是最后一层隐藏层到输出层直接的权重,也成为输出词嵌入矩阵,矩阵中每一行可以看作是一个词向量。


LSTM

: 输入门 : 遗忘门 : 输出门<br />:当前时刻的输入 : 上一时刻的工作记忆 : 当前时刻的工作记忆<br />: 当前时刻的候选记忆 : 上一时刻的长期记忆 : 当前时刻的长期记忆

LSTM 有三个门, 三个门来控制信息的流动 ,有两个重要的记忆:长期记忆(cell state) 工作记忆(hidden state),两者的分工主要是:历史信息存储在 cell state 中,当下的决策如输出等在 hidden state 里面运行
LSTM 的工作过程主要有三个步骤:
- 选择性遗忘部分长期记忆:将记忆中不重要的记忆移除,通过遗忘门来控制

- 选择部分当前时刻的信息加入到长期记忆,通过输入门控制

- 从长期记忆中提取出工作记忆,由输出门控制

由以上三个过程可知当前时刻长期记忆由两部分组成,分别是步骤一和步骤二的结果,可得到公式 5 
GRU
在 LSTM 网络中,输入门和遗忘门是互补关系,用两个门比较冗余。GRU 将输入门与和遗忘门合并成一个门:更新门。同时,GRU 也不引入额外的记忆单元,直接在当前状态  和历史状态
和历史状态  之间引入线性依赖关系。
之间引入线性依赖关系。
应用模式
序列到类别模式
序列到类别模式主要用于序列数据的分类问题:输入为序列,输出为类别。比如在文本分类中,输入数据为单词的序列,输出为该文本的类别。假设一个样本  为一个长度为
为一个长度为  的序列,输出为一个类别
的序列,输出为一个类别  。
。
同步的序列到序列模式
同步的序列到序列模式主要用于序列标注(SequenceLabeling)任务,即每一时刻都有输入和输出,输入序列和输出序列的长度相同。比如词性标注(Part-of-SpeechTagging)中,每一个单词都需要标注其对应的词性标签。假设一个样本  为一个长度为
为一个长度为  的序列,输出为一个序列
的序列,输出为一个序列  。
。
异步序列到序列模式
异步的序列到序列模式也称为编码器-解码器(Encoder-Decoder)模型,即输入序列和输出序列不需要有严格的对应关系,也不需要保持相同的长度。比如在机器翻译中,输入为源语言的单词序列,输出为目标语言的单词序列。
输入为一个长度为  的序列
的序列  ,输出长度为
,输出长度为  为一个序列
为一个序列  。
。
通过先编码后解码的方式来实现。先将样本x按不同时刻输入到一个循环神经网络(编码器)中,并得到其编码 。然后使用另一个循环神经网络(解码器)中,得到输出序列
。然后使用另一个循环神经网络(解码器)中,得到输出序列  。
。
卷积神经网络 CNN
全连接前馈网络的缺点:
1)参数太多:随着隐藏神经元数量的增多,参数的规模也会急剧增加。会导致整个神经网络的训练效率会非常低,也很容易出现过拟合。
2)局部不变性特征:在尺度缩放、平移、旋转等操作不影响其语义信息。全连接前馈神经网络很难提取这些局部不变特征,一般需要数据增强来提高性能。
卷积神经网络有 3 个结构上的特性:局部连接、权重共享以及汇聚。和前馈神经网络相比,参数更少。
把  称为滤波器(Filter)或卷积核(ConvolutionKernel)。假设滤波器长度为m,它和一个信号序列
称为滤波器(Filter)或卷积核(ConvolutionKernel)。假设滤波器长度为m,它和一个信号序列  的卷积为
的卷积为
信号序列  和滤波器
和滤波器  的卷积定义为
的卷积定义为 
其中, 表示卷积运算。
表示卷积运算。
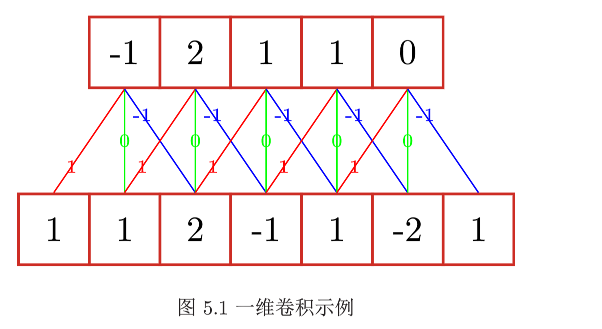
一维卷积
二维卷积
给定一个图像  , 和滤波器
, 和滤波器  ,一般
,一般  ,其卷积为
,其卷积为

互相关
互相关是一种衡量两个序列相关性的函数,通常用户滑动窗口的点积计算来实现。给定一个图像  , 和滤波器
, 和滤波器  ,其互相关为
,其互相关为
互相关和卷积的区别在于卷积核是否进行翻转。互相关也被成为不翻转卷积。
假设卷积层的输入神经元个数为  ,卷积大小为
,卷积大小为  ,步长为
,步长为  ,输入神经元两端各填补
,输入神经元两端各填补  个零(zero pading),那么卷积层的神经元数量为
个零(zero pading),那么卷积层的神经元数量为
CNN
卷积神经网络一般由卷积层、汇聚层和全连接层构成。
- 卷积层(Filter Layer):性质:局部连接和权重共享。作用:提取局部区域的特征
- 汇聚层(Pooling Layer):进行特征选择,降低特征数量,从而减少参数数量。
汇聚(Pooling) :指对每个区域进行下采样(Down Sampling) 得到一个值,作为这个区域的概率
常用的汇聚函数:
- 最大汇聚(Maxinum Pooling):取一个区域内所有神经元的最大值。

其中  为区域
为区域  内每个神经元的激活值。
内每个神经元的激活值。
- 平均汇聚(Mean Pooling):取区域内所有神经元的平均值:


- 全连接层:

残差网络 ResNet
残差网络是通过给非线性的卷积层增加直连边的方式来提高信息的传播效率。假设在一个深度网络中,我们期望一个非线性单元(可以为一层或多层的卷积层) 去逼近一个目标函数为
去逼近一个目标函数为  。
。
如果将目标函数拆分成两部分:恒等函数(IdentityFunction) 和残差函数(ResidueFunction)
和残差函数(ResidueFunction) 。
。
根据通用近似定理,一个由神经网络构成的非线性单元有足够的能力来近似逼近原始目标函数或残差函数,但实际中后者更容易学习[Heetal.,2016]。因此,原来的优化问题可以转换为:让非线性单元  去近似残差函数
去近似残差函数  ,并用
,并用  去逼近
去逼近  。
。
残差网络就是将很多个残差单元串联起来构成的一个非常深的网络。
图网络

若有收获,就点个赞吧
0 人点赞
