
激活函数性质:
- 连续可导(允许少数点不可导)的非线性函数;
- 激活函数及其导函数的值要尽可能简单,有利于提高网络计算效率;
- 激活函数的导函数的值域要在合适的区间内,不能太大也不能太小,否则会影响训练的效率和效果。
Sigmoid 型
Sigmoid 型函数是指一类 S 型曲线函数,为两端饱和函数。饱和:对于函数 ,若
,若  时,其导数
时,其导数  ,则其成为左饱和。若
,则其成为左饱和。若  时,其导数
时,其导数  ,则其成为右饱和。当然同时满足左、右饱和时,就称为两端饱和。
,则其成为右饱和。当然同时满足左、右饱和时,就称为两端饱和。
由于 Sigmoid 型函数的饱和性,饱和区的导数更是接近于 0。这样,误差经过每一层传递都会不断衰减。当网络层数很深时,梯度就会不停的衰减,甚至消失,使得整个网络很难训练。这就是所谓的梯度消失问题(Vanishing Gradient Problem),也叫梯度弥散问题。
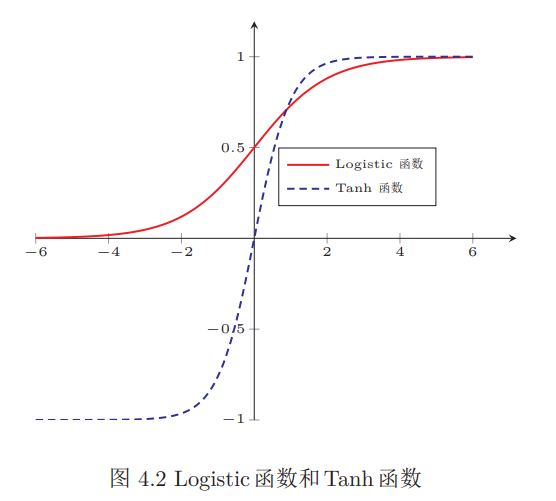

Logistic 函数

Tanh 函数

值域是 (-1,1)。
Tanh 函数的输出是零中心化的 (Zero-Centered) ,而 Logistic 函数的输出恒大于 0 。非零中心化的输出会使得其后一层的神经元的输入发生偏置转移,并进一步使得梯度下降的收敛速度变慢。
缺点:Logistic 函数和 Tanh 函数都是 Sigmoid 型函数,具有饱和性,但是计算开销较大。因为这两个函数都是在中间(0附近)近似线性,两端饱和。
Hard-Logistic 函数
Logistic 函数  的导数为
的导数为  ,在 0 附近的一阶泰勒展开为
,在 0 附近的一阶泰勒展开为 
用分段来近似 Logistic 函数得到
Hard-Tanh 函数
Tanh 函数在 0 附近的一阶泰勒展开为 
用分段 函数 hard-tanh(x) 来近似:

ReLU
修正线性单元(RectifiedLinearUnit,ReLU),也叫 rectifier 函数,是目前深层神经网络中经常使用的激活函
数。ReLU实际上是一个斜坡(ramp)函数,定义为
优点:
- ReLU却具有很好的稀疏性,大约50%的神经元会处于激活状态。
- 相比于Sigmoid型函数的两端饱和,ReLU函数为左饱和函数,且在x>0时导数为1,在一定程度上缓解了神经网络的梯度消失问题,加速梯度下降的收敛速度。
缺点:
- ReLU函数的输出是非零中心化的,给后一层的神经网络引入偏置偏移,会影响梯度下降的效率。
- ReLU神经元在训练时比较容易“死亡”。在训练时,如果参数在一次不恰当的更新后,第一个隐藏层中的某个ReLU神经元在所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是 0,在以后的训练过程中永远不能被激活。这种现象称为死亡 ReLU 问题(Dying ReLUProblem),并且也有可能会发生在其它隐藏层。
- 产生死亡 ReLU 现象的原因:参数初始化问题;learning rate 太高导致在训练过程中参数更新太大。解决方法:采用 Xavier 初始化方法,以及避免将learning rate 设置太大或使用adagrad等自动调节 learning rate 的算法。

Leaky ReLU
泄露的ReLU(Leaky ReLU)在输入x<0时,保持一个很小的梯度 λ。这样当神经元非激活时也能有一个非零的梯度可以更新参数,避免永远不能被激活。Leaky ReLU定义如下:
Parametric ReLU
带参数的 ReLU(ParametricReLU,PReLU)引入一个可学习的参数,不同神经元可以有不同的参数。对于第i个神经元,其 PReLU 的定义为
其中 PReLU可以允许不同神经元具有不同的参数,也可以一组神经元共享一个参数。
ELU
指数线性单元(ExponentialLinearUnit,ELU) 是一个近似
Softplus 函数
Softplus函数可以看作是rectifier函数的平滑版本,其定义为
Softplus函数虽然也有具有单侧抑制、宽兴奋边界的特性,却没有稀疏激活性。
Swish 函数


Maxout 单元
Maxout单元也是一种分段线性函数。Sigmoid 型函数、ReLU 等激活函数的输入是神经元的净输入z,是一个标量。而maxout 单元的输入是上一层神经元的全部原始输入,是一个向量x=[x1;x2;···,xd] 。
。

若有收获,就点个赞吧
0 人点赞
