1.1翻转一个字符串
切蛋糕思维
def str_reverse(str,end):end-=1if end==0:return strt=list(str) #str[i]是错误的,和其他语言不一样return t[end]+str_reverse(str[:-1],end) #str[:-1]表示切取0至倒数第1个字符(不包括),所以就是丢掉最后一个字符str='abc'print(str_reverse(str,3))
1.2斐波拉契数
递推公式或者等价转换
def fei(n):if n==1 or n==2:return 1return fei(n-1)+fei(n-2)print(fei(5))
1.3求两个整数的最大公约数
递推公式
def max_com_divisor(m,n):if(n==0):return mreturn max_com_divisor(n,m%n)print(max_com_divisor(8,3))
1.4插入排序(o(n^2))

import randomimport timedef insert_sort(alist):for i in range(1,len(alist)):j=iwhile j>0:if alist[j]<alist[j-1]:alist[j-1],alist[j]=alist[j],alist[j-1] #交换使得赋值次数为3j-=1else:breakalist=random.sample(range(0,10000),10000)start=time.clock()insert_sort(alist)end=time.clock()print(end-start)
改进的插入排序
import randomimport timedef insert_sort(alist):for i in range(1,len(alist)):j=ie=alist[j] #将每次要插入的数赋给ewhile j>0:if e<alist[j-1]:alist[j]=alist[j-1] #不做交换,只做一次赋值j-=1else:breakalist=random.sample(range(0,10000),10000)start=time.clock()insert_sort(alist)end=time.clock()print(end-start)
用递归插入升序排序数组
def insert_sort(alist,n):n=n-1if n==0:returnif n>0:insert_sort(alist,n)k=nwhile (k>0)and(alist[k]<alist[k-1]):alist[k],alist[k-1]=alist[k-1],alist[k] #交换k=k-1return alistalist=[1,4,5,3,7,9,8,0,11,10,2,14]insert_sort(alist,len(alist))print(alist)
1.5 汉诺塔

def hannota(N,start,distination,assistance):count=0N=int(N)if N<=1:print("move"+str(N)+"from"+start+"to"+distination)return 1count+=hannota(N-1,start,assistance,distination)print("move"+str(N)+"from"+start+"to"+distination)count+=1count+=hannota(N-1,assistance,distination,start)return counta='A'b='B'c='C'print(hannota(3,a,b,c))move1fromAtoBmove2fromAtoCmove1fromBtoCmove3fromAtoBmove1fromCtoAmove2fromCtoBmove1fromAtoB7
1.7二分查找
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列
def erfensearch(alist,low,high,key):if low>high:return -1elif low==high:if alist[low]==key:return lowelse:mid = (low+high)>>1if alist[mid]>key:return erfensearch(alist,low,mid-1,key)elif alist[mid]<key:return erfensearch(alist,mid+1,high,key)else:return midalist=[1,2,3,4,5,6,7,8]print(erfensearch(alist,0,len(alist)-1,4))
1.8归并排序
借助辅助空间,时间复杂度为nlogn

import randomimport timedef merge(alist,left,mid,right):blist=[0]blist[0]=alist[left]for i in range(left+1,right+1):blist.append(alist[i]) #创建辅助数组i=leftj=mid+1for k in range(left,right+1):if i>mid: #i>mid,j>right都是溢出情况alist[k]=blist[j-left]j+=1elif j>right:alist[k]=blist[i-left]i+=1else:if blist[i-left]<blist[j-left]:alist[k]=blist[i-left]i+=1else:alist[k]=blist[j-left]j+=1def MergeSort(alist,left,right):if right>left:mid=(left+right)>>1MergeSort(alist,left,mid)MergeSort(alist,mid+1,right)merge(alist,left,mid,right)alist=random.sample(range(0,30000),30000)left=1000 #可以从alist中的任何索引开始排序right=len(alist)-1start=time.clock()MergeSort(alist,left,right)end=time.clock()print(end-start)#优化后的归并排序def MergeSort(alist,left,right):if right>left:mid=(left+right)>>1MergeSort(alist,left,mid)MergeSort(alist,mid+1,right)if alist[mid]>alist[mid+1]:merge(alist,left,mid,right)#当递归到数据量比较小的时候,可以采用插入排序,此时数据近乎有序的几率比较大,对于近乎有序的数据,#插入排序的时间比归并排序的时间短def MergeSort(alist,left,right):if right-left<=15:insert_sort(alist,left,right)returnmid=(left+right)>>1MergeSort(alist,left,mid)MergeSort(alist,mid+1,right)if alist[mid]>alist[mid+1]:merge(alist,left,mid,right)#自底向上的的归并排序def MergeSort(alist,n):sz=1i=0while sz<=n:while i+sz<n:#对alist[i...i+sz-1]和alist[i+sz...i+2*sz-1]进行归并merge(alist,i,i+sz-1,min(i+sz+sz-1,n-1))i+=sz^2sz+=sz
利用归并排序求逆序对
import randomimport timedef merge(alist,left,mid,right):blist=[0]blist[0]=alist[left]for i in range(left+1,right+1):blist.append(alist[i]) #创建辅助数组global ni=leftj=mid+1for k in range(left,right+1):if i>mid:alist[k]=blist[j-left]j+=1elif j>right:alist[k]=blist[i-left]i+=1else:if blist[i-left]<blist[j-left]:alist[k]=blist[i-left]i+=1else:alist[k]=blist[j-left]j+=1n=n+(mid-i+1) #求逆序对数print(alist)def MergeSort(alist,left,right):global nif right>left:mid=(left+right)>>1MergeSort(alist,left,mid)MergeSort(alist,mid+1,right)merge(alist,left,mid,right)alist=random.sample(range(0,8),8)n=0print(alist)print("----------")left=0right=len(alist)-1start=time.clock()MergeSort(alist,left,right)print(n)end=time.clock()print(end-start)
1.9快速排序
时间复杂度为nlogn
def sure_k(alist,low,high):k=lowx=alist[low]for i in range(low+1,high+1):if alist[i]<=x:k+=1if k!=i:alist[k],alist[i]=alist[i],alist[k]alist[low],alist[k]=alist[k],alist[low]print(alist,"---",alist[k])return kdef quicksort(alist,low,high):if high-low<=15:insert_sort(alist,low,high)k=sure_k(alist,low,high)quicksort(alist,low,k-1)quicksort(alist,k+1,high)else:returnalist=[5,1,3,8,0,4,7,2,7,9,6,10,14,13]print(alist)quicksort(alist,0,len(alist)-1)
快速二路排序
**
#采用赋值而不是交换的方式import randomimport timedef partition(alist,left,right):e=alist[left]if left>right:returnwhile (left<right):while (alist[right]>e)&(right>left):right-=1if (alist[right]<e)&(left<right):alist[left]=alist[right]while (alist[left]<e)&(left<right):left+=1if (alist[left]>e)&(left<right):alist[right]=alist[left]alist[left]=ek=leftreturn kdef partition_sort(alist,left,right):if left>right:returnk=partition(alist,left,right)partition_sort(alist,left,k-1)partition_sort(alist,k+1,right)alist=random.sample(range(0,10000),10000)print(alist)start=time.clock()partition_sort(alist,0,9999)end=time.clock()print(end-start)
三路快速排序:当一个数组中有比较多的相同数时适用
import randomimport timeimport syssys.setrecursionlimit(1000000)def quick_sort(alist,left,right):if right-left<1:returnv=alist[left]lt=leftgt=righti=left+1while i<gt:if alist[i]>v:alist[i],alist[gt]=alist[gt],alist[i]gt-=1elif alist[i]<v:alist[i],alist[lt+1]=alist[lt+1],alist[i]i+=1lt+=1else:i+=1alist[left],alist[lt]=alist[lt],alist[left]quick_sort(alist,left,lt-1)quick_sort(alist,gt,right)alist=random.sample(range(0,10000),10000)x=1000while x:alist.append(alist[0])x-=1start=time.clock()quick_sort(alist,0,len(alist)-1)end=time.clock()print(end-start)
利用快速排序查找数组中第k大的数
import randomimport timeimport syssys.setrecursionlimit(1000000)def partition(alist,left,right):e=alist[left]while (left<right):while (alist[right]>e)&(right>left):right-=1if (alist[right]<e)&(left<right):alist[left]=alist[right]while (alist[left]<e)&(left<right):left+=1if (alist[left]>e)&(left<right):alist[right]=alist[left]alist[left]=ek=leftreturn kdef partition_sort(alist,left,right,v):if (left>=right) & (left == v):return alist[v]k=partition(alist,left,right)if k>v:return partition_sort(alist,left,k-1,v)elif k<v:return partition_sort(alist,k+1,right,v)else:return alist[k]alist=random.sample(range(0,30000),30000)k=partition_sort(alist,0,len(alist)-1,10000)print(k)
1.10优先队列
概念
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。
实现
通常采用堆数据结构来实现。

堆的定义
堆其实就是一棵完全二叉树(若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边),
定义为:具有n个元素的序列(h1,h2,…hn),当且仅当满足(hi>=h2i,hi>=h2i+1)或(hi<=h2i,hi<=2i+1) (i=1,2,…,n/2)时称之为堆
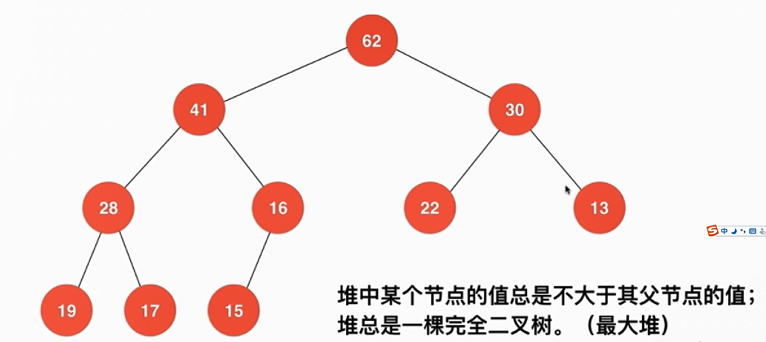
堆排序
import randomimport timeclass MaxHeap(object):def __init__(self):self._data = []self._count = len(self._data)def size(self):return self._countdef isEmpty(self):return self._count == 0def add(self, item):# 插入元素入堆self._data.append(item)self._count += 1self._shiftup(self._count-1) #堆的序号从0开始def pop(self):# 出堆if self._count > 0:ret = self._data[0]self._data[0] = self._data[self._count-1] #移除堆的最顶的元素self._count -= 1self._shiftDown(0) #对移除之后的堆进行排序,使之成为最大堆return retdef _shiftup(self, index):# 上移self._data[index],以使它不大于父节点parent = (index-1)>>1while index > 0 and self._data[parent] < self._data[index]:# swapself._data[parent], self._data[index] = self._data[index], self._data[parent]index = parentparent = (index-1)>>1def _shiftDown(self, index):# 上移self._data[index],以使它不小于子节点j = (index << 1) + 1while j < self._count :# 有子节点if j+1 < self._count and self._data[j+1] > self._data[j]:# 有右子节点,并且右子节点较大j += 1if self._data[index] >= self._data[j]:# 堆的索引位置已经大于两个子节点,不需要交换了breakself._data[index], self._data[j] = self._data[j], self._data[index]index = jj = (index << 1) + 1def MaxHeap1(self,alist,n): #n表示alist的长度self._data=n*[0]for i in range(0,n):self._data[i]=alist[i]self._count=ni=(self._count-1)>>2while i>=0:self._shiftDown(i)i-=1#通过将数组的数一个一个添加到堆中然后在移出堆的操作实现逆序def Heapsort1(alist):maxheap=MaxHeap()for i in range(0,len(alist)):maxheap.add(alist[i])i=maxheap._count-1while i>=0:alist[i]=maxheap.pop()i-=1#通过开辟一个与数组同长度的堆,然后赋值->shitfdown使得成为最大堆,最后移出堆操作实现逆序def Heapsort2(alist):#开辟新空间maxheapmaxheap=MaxHeap()maxheap.MaxHeap1(alist,len(alist))i=len(alist)-1while i>=0:alist[i]=maxheap.pop()i-=1#直接对alist逆排序,不创建堆空间def Heapsort3(alist):#对数组heapifyi=(len(alist)-1)>>1while i>=0:shiftdown(alist,len(alist),i)i-=1#对数组进行逆序k=len(alist)-1while k>0:#交换alist[k],alist[0]=alist[0],alist[k]shiftdown(alist,k,0)k-=1def shiftdown(alist,n,k):while 2*k+1<n: #当左孩子没有越界j=2*k+1if j+1<n and alist[j+1]>alist[j]:j+=1if alist[k]>=alist[j]:breakalist[k],alist[j]=alist[j],alist[k]k=jif __name__ == '__main__':alist=random.sample(range(0,10000),10000)start=time.clock()Heapsort3(alist)end=time.clock()print(end-start)
索引堆

import mathclass IndexMaxHeap(object):def __init__(self,capacity):self._indexes =capacity*[0]self._data=capacity*[0]self._reverse=capacity*[0]self._count = 0def size(self):return self._countdef isEmpty(self):return self._count == 0def IndexMaxHeap1(self,alist):for i in range(0,len(alist)):self._data[i]=alist[i]self._indexes[i]=iself._reverse[i]=iself._count+=1#进行最大堆排序i=(self._count-2)>>1 #求第一个不是叶子节点的元素的序号while i>=0:self._shiftDown(i)i-=1#传入的i对用户而言,是从0索引的def add(self, i,item):# 插入元素入堆self._data.append(item)self._indexes.append(i)self._reverse.append(self._count)self._count += 1self._shiftup(self._count-1) #堆的序号从0开始def pop(self):# 出堆,返回的是堆的最大元素if self._count > 0:ret = self._data[self._indexes[0]]self._indexes[0],self._indexes[self._count-1]= self._indexes[self._count-1],self._indexes[0] #移除堆的最顶的元素self._reverse[self._indexes[0]]=0self._reverse[self._indexes[count-1]]=0self._count -= 1self._shiftDown(0) #对移出之后的堆进行排序,使之成为最大堆return retdef popindex(self):#返回最大元素的索引if self._count>0:ret=self._indexes[0] #对于用户来说,返回的是从0开始列表最大元素的索引self._indexes[0],self._indexes[self._count-1]= self._indexes[self._count-1],self._indexes[0] #移除堆的最顶的元素self._count-=1self._shiftDown(0)return retdef contain(self,i):#验证用户传进的i(以0开始)的参数是不是在索引堆中if i>=0 and i+1<=self._count:return self._reverse[i]!=0def getItem(self,i):if self.contain(i):return self._data[i]def change(self,i,item): #将列表中的data[i]改为itemif self.contain(i):self._data[i]=item#找到indexes[j]=i,j表示data[i]在堆中的位置# for j in range(0,self._count):# if self._indexes[j]==i:# _shiftup(j)# _shiftDown(j)# returnj=self._reverse[i]self._shiftup(j)self._shiftDown(j)#上浮和下沉都是入堆与出堆的操作,与用户无关,可以设为私有方法def _shiftup(self, k):# 上移self._indexes[k],以使它不大于父节点while k > 0 and self._data[self._indexes[(k-1)>>1]] < self._data[self._indexes[k]]:# swapself._indexes[(k-1)>>1], self._indexes[k] = self._indexes[k], self._indexes[(k-1)>>1]self._reverse[self._indexes[(k-1)>>1]]=(k-1)>>1self._reverse[self._indexes[k]]=kk=(k-1)>>1def _shiftDown(self, k):# 上移self._data[index],以使它不小于子节点while (k <<1+1) <= self._count :j = k << 1 + 1# 有子节点if j+1 < self._count and self._data[self._indexes[j+1]] > self._data[self._indexes[j]]:# 有右子节点,并且右子节点较大j += 1if self._data[self._indexes[k]] >= self._data[self._indexes[j]]:# 堆的索引位置已经大于两个子节点,不需要交换了breakself._indexes[k],self._indexes[j]=self._indexes[j],self._indexes[k]self._reverse[self._indexes[k]]=kself._reverse[self._indexes[j]]=jk = jindexheap=IndexMaxHeap(5)alist=[30,90,3,6,40]indexheap.IndexMaxHeap1(alist)print(indexheap._indexes)indexheap.add(5,80)print(indexheap._indexes)print(indexheap.getItem(5)) #80
运行结果:
排序总结
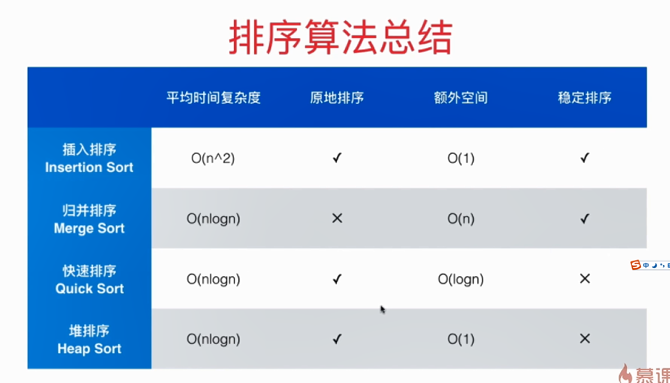
排序的稳定性


若有收获,就点个赞吧
0 人点赞
