TC 介绍
TC全称「Traffic Control」,直译过来是「流量控制」,在这个领域,你可能更熟悉的是Linux iptables或者netfilter,它们都能做packet mangling,而TC更专注于packet scheduler,所谓的网络包调度器,调度网络包的延迟、丢失、传输顺序和速度控制。
在测试领域里面可以通过linux tc 工具对指定接口进行流量配置,例如增加接口延迟,配置接口丢包率,这样可以模拟复杂网络环境提供工具。通过tc
TC 调度结构
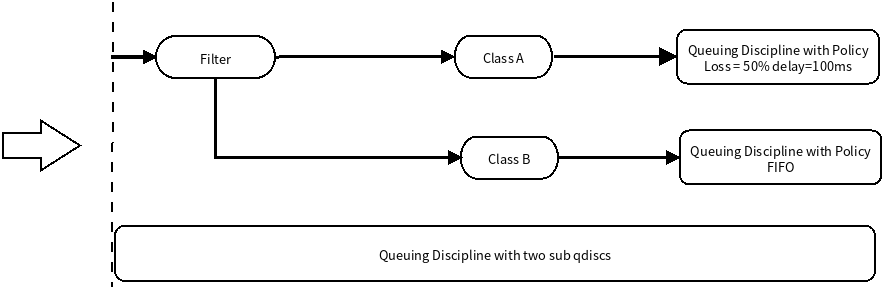
TC有4大组件:
- Queuing disciplines,简称为qdisc,直译是「队列规则」,它的本质是一个带有算法的队列,默认的算法是FIFO,形成了一个最简单的流量调度器。
- Class,直译是「种类」,它的本质是为上面的qdisc进行分类。因为现实情况下会有很多qdisc存在,每种qdisc有它特殊的职责,根据职责的不同,可以对qdisc进行分类。
- Filters,直译是「过滤器」,它是用来过滤传入的网络包,使它们进入到对应class的qdisc中去。
- Policers,直译是「规则器」,它其实是filter的跟班,通常会紧跟着filter出现,定义命中filter后网络包的后继操作,如丢弃、延迟或限速。
例如下面模拟网络延迟和丢包代码
#!/bin/bashinterface=loip=127.0.0.1# 延迟配置delay=100ms# 丢包配置loss=50%tc qdisc add dev $interface root handle 1: priotc filter add dev $interface parent 1:0 protocol ip prio 1 u32 match ip dst $ip flowid 2:1tc qdisc add dev $interface parent 1:1 handle 2: netem delay $delay loss $loss
那么TC是怎么和BPF联系在一起的呢?
从内核4.1版本起,引入了一个特殊的qdisc,叫做clsact,它为TC提供了一个可以加载BPF程序的入口,使TC和XDP一样,成为一个可以加载BPF程序的网络钩子。
TC vs XDP
这两个钩子都可以用于相同的应用场景,如DDoS缓解、隧道、处理链路层信息等。但是,由于XDP在任何套接字缓冲区(SKB)分配之前运行,所以它可以达到比TC上的程序更高的吞吐量值。然而,后者可以从通过 struct __sk_buff 提供的额外的解析数据中受益,并且可以执行 BPF 程序,对入站流量和出站流量都可以执行 BPF 程序,是 TX 链路上的能被操控的最一层。
对于在容器网络来说,是在容器网络接口对端 ,主机一端veth 上加入TC BPF。 对于这个BPF, RX是 from-container 数据, TX是 to-container 数据。在TX端对发送容器数据进行过滤,RX端是容器发送出数据进行过滤。同样XDP BPF也是配置在容器对端接口,XDP只能对容器发送外网,其他容器数据进行监控。
TC内核代码结构
TC接受单个输入参数,类型为struct __sk_buff。这个结构是一种UAPI(user space API of the kernel),允许访问内核中socket buffer内部数据结构中的某些字段。它具有与 struct xdp_md 相同意义两个指针,data和data_end,同时还有更多信息可以获取,这是因为在TC层面上,内核已经解析了数据包以提取与协议相关的元数据,因此传递给BPF程序的上下文信息更加丰富。结构 __sk_buff 的整个声明如下所说,可以在 include/uapi/linux/bpf.h 文件中看到,下面是结构体的定义,比XDP的要多出很多信息,这就是为什么说TC层的吞吐量要比XDP小了,因为实例化一堆信息需要很大的cost。
* user accessible mirror of in-kernel sk_buff.* new fields can only be added to the end of this structure*/struct __sk_buff {__u32 len;__u32 pkt_type;__u32 mark;__u32 queue_mapping;__u32 protocol;__u32 vlan_present;__u32 vlan_tci;__u32 vlan_proto;__u32 priority;__u32 ingress_ifindex;__u32 ifindex;__u32 tc_index;__u32 cb[5];__u32 hash;__u32 tc_classid;__u32 data;__u32 data_end;__u32 napi_id;/* Accessed by BPF_PROG_TYPE_sk_skb types from here to ... */__u32 family;__u32 remote_ip4; /* Stored in network byte order */__u32 local_ip4; /* Stored in network byte order */__u32 remote_ip6[4]; /* Stored in network byte order */__u32 local_ip6[4]; /* Stored in network byte order */__u32 remote_port; /* Stored in network byte order */__u32 local_port; /* stored in host byte order *//* ... here. */__u32 data_meta;__bpf_md_ptr(struct bpf_flow_keys *, flow_keys);__u64 tstamp;__u32 wire_len;__u32 gso_segs;__bpf_md_ptr(struct bpf_sock *, sk);};
TC输出参数
和XDP一样,TC的输出代表了数据包如何被处置的一种动作。它的定义在include/uapi/linux/pkt_cls.h找到。最新的内核版本里定义了9种动作,其本质是int类型的值,以下是5种常用动作:
| 0 | TC_ACT_OK | 允许网络包传送到TC queue |
|---|---|---|
| 2 | TC_ACT_SHOT | 丢弃网络包 |
| -1 | TC_ACT_USPEC | Use standard TC action |
| 3 | TC_ACT_PIPE | Perform the next action, if it exists |
| 1 | TC_ACT_RECLASSIFY | Restarts the classification from begining |
设计你的第一个TC程序
为了更贴近系列文章的初心——了解并学习容器网络Cilium的工作原理,我们这次拿容器实例作为流控目标。在实验环境上通过docker run运行一个Nginx服务:
$ docker run -d -p 80:80 --name=nginx-xdp nginx:alpine
下面获取容器接口
$ ip a | grep veth...9: vethf87805f@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default qlen 1000
TC 对发送到容器数据包过滤
设计一个TC BPF 程序对发送到容器包进行过滤,首先过滤条件如下
- 允许docker容器内部网段对这个容器进行访问
- 禁止外部主机访问对这个容器tcp进行访问
外网络访问容器时候,都是docker0 网桥转发到容器对端 veth 接口上,由于通过网桥做路由器所有在BPF上src 地址就是docker0网桥地址,只要是网桥地址发送过来的。 如图: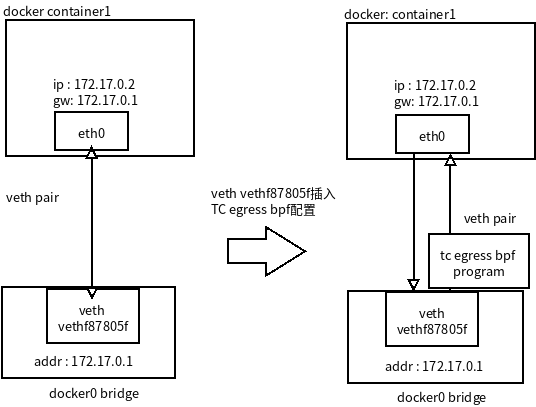
tc-ban-outside-network-vist-container-debug.c
#include <stdbool.h>#include <linux/bpf.h>#include <linux/if_ether.h>#include <linux/ip.h>#include <linux/in.h>#include <linux/pkt_cls.h>#include <stdio.h>#include "bpf_endian.h"#include "bpf_helpers.h"typedef unsigned int u32;#define bpfprint(fmt, ...) \({ \char ____fmt[] = fmt; \bpf_trace_printk(____fmt, sizeof(____fmt), \##__VA_ARGS__); \})/*check whether the packet is of TCP protocol*/static __inline bool ban_network_outside_to_visit(void *data_begin, void *data_end){bpfprint("Entering ban_network_outside_to_visit \n");struct ethhdr *eth = data_begin;// Check packet's size// the pointer arithmetic is based on the size of data type, current_address plus int(1) means:// new_address= current_address + size_of(data type)if ((void *)(eth + 1) > data_end) //return false;// Check if Ethernet frame has IP packetif (eth->h_proto == bpf_htons(ETH_P_IP)){struct iphdr *iph = (struct iphdr *)(eth + 1); // or (struct iphdr *)( ((void*)eth) + ETH_HLEN );if ((void *)(iph + 1) > data_end)return false;// Check if IP packet contains a TCP segmentif (iph->protocol != IPPROTO_TCP)return false;// extract src ip and destination ipu32 ip_src = iph->saddr;u32 ip_dst = iph->daddr;bpfprint("src ip addr1: %d.%d.%d\n",(ip_src) & 0xFF,(ip_src >> 8) & 0xFF,(ip_src >> 16) & 0xFF);bpfprint("src ip addr2:.%d\n",(ip_src >> 24) & 0xFF);bpfprint("dest ip addr1: %d.%d.%d\n",(ip_dst) & 0xFF,(ip_dst >> 8) & 0xFF,(ip_dst >> 16) & 0xFF);bpfprint("dest ip addr2: .%d\n",(ip_dst >> 24) & 0xFF);// docker0 addr 172.17.0.1u32 route_from_docker0_addr = bpf_htonl(0xac110001);// outsize network use docker0 route to container networkif (ip_src == route_from_docker0_addr) {return true;}}return false;}SEC("to-container")int tc_to_container(struct __sk_buff *skb){bpfprint("Entering to-container sec\n");void *data = (void *)(long)skb->data;void *data_end = (void *)(long)skb->data_end;if (ban_network_outside_to_visit(data, data_end))return TC_ACT_SHOT;elsereturn TC_ACT_OK;}char _license[] SEC("license") = "GPL";
头文件:
headers/bpf_endian.h
/* SPDX-License-Identifier: GPL-2.0 *//* Copied from $(LINUX)/tools/testing/selftests/bpf/bpf_endian.h */#ifndef __BPF_ENDIAN__#define __BPF_ENDIAN__#include <linux/swab.h>/* LLVM's BPF target selects the endianness of the CPU* it compiles on, or the user specifies (bpfel/bpfeb),* respectively. The used __BYTE_ORDER__ is defined by* the compiler, we cannot rely on __BYTE_ORDER from* libc headers, since it doesn't reflect the actual* requested byte order.** Note, LLVM's BPF target has different __builtin_bswapX()* semantics. It does map to BPF_ALU | BPF_END | BPF_TO_BE* in bpfel and bpfeb case, which means below, that we map* to cpu_to_be16(). We could use it unconditionally in BPF* case, but better not rely on it, so that this header here* can be used from application and BPF program side, which* use different targets.*/#if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__# define __bpf_ntohs(x)__builtin_bswap16(x)# define __bpf_htons(x)__builtin_bswap16(x)# define __bpf_constant_ntohs(x)___constant_swab16(x)# define __bpf_constant_htons(x)___constant_swab16(x)# define __bpf_ntohl(x)__builtin_bswap32(x)# define __bpf_htonl(x)__builtin_bswap32(x)# define __bpf_constant_ntohl(x)___constant_swab32(x)# define __bpf_constant_htonl(x)___constant_swab32(x)#elif __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__# define __bpf_ntohs(x)(x)# define __bpf_htons(x)(x)# define __bpf_constant_ntohs(x)(x)# define __bpf_constant_htons(x)(x)# define __bpf_ntohl(x)(x)# define __bpf_htonl(x)(x)# define __bpf_constant_ntohl(x)(x)# define __bpf_constant_htonl(x)(x)#else# error "Fix your compiler's __BYTE_ORDER__?!"#endif#define bpf_htons(x)\(__builtin_constant_p(x) ?\__bpf_constant_htons(x) : __bpf_htons(x))#define bpf_ntohs(x)\(__builtin_constant_p(x) ?\__bpf_constant_ntohs(x) : __bpf_ntohs(x))#define bpf_htonl(x)\(__builtin_constant_p(x) ?\__bpf_constant_htonl(x) : __bpf_htonl(x))#define bpf_ntohl(x)\(__builtin_constant_p(x) ?\__bpf_constant_ntohl(x) : __bpf_ntohl(x))#endif /* __BPF_ENDIAN__ */
headers/bpf_helper.h
/* SPDX-License-Identifier: GPL-2.0 *//* Copied from $(LINUX)/tools/testing/selftests/bpf/bpf_endian.h */#ifndef __BPF_ENDIAN__#define __BPF_ENDIAN__#include <linux/swab.h>/* LLVM's BPF target selects the endianness of the CPU* it compiles on, or the user specifies (bpfel/bpfeb),* respectively. The used __BYTE_ORDER__ is defined by* the compiler, we cannot rely on __BYTE_ORDER from* libc headers, since it doesn't reflect the actual* requested byte order.** Note, LLVM's BPF target has different __builtin_bswapX()* semantics. It does map to BPF_ALU | BPF_END | BPF_TO_BE* in bpfel and bpfeb case, which means below, that we map* to cpu_to_be16(). We could use it unconditionally in BPF* case, but better not rely on it, so that this header here* can be used from application and BPF program side, which* use different targets.*/#if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__# define __bpf_ntohs(x)__builtin_bswap16(x)# define __bpf_htons(x)__builtin_bswap16(x)# define __bpf_constant_ntohs(x)___constant_swab16(x)# define __bpf_constant_htons(x)___constant_swab16(x)# define __bpf_ntohl(x)__builtin_bswap32(x)# define __bpf_htonl(x)__builtin_bswap32(x)# define __bpf_constant_ntohl(x)___constant_swab32(x)# define __bpf_constant_htonl(x)___constant_swab32(x)#elif __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__# define __bpf_ntohs(x)(x)# define __bpf_htons(x)(x)# define __bpf_constant_ntohs(x)(x)# define __bpf_constant_htons(x)(x)# define __bpf_ntohl(x)(x)# define __bpf_htonl(x)(x)# define __bpf_constant_ntohl(x)(x)# define __bpf_constant_htonl(x)(x)#else# error "Fix your compiler's __BYTE_ORDER__?!"#endif#define bpf_htons(x)\(__builtin_constant_p(x) ?\__bpf_constant_htons(x) : __bpf_htons(x))#define bpf_ntohs(x)\(__builtin_constant_p(x) ?\__bpf_constant_ntohs(x) : __bpf_ntohs(x))#define bpf_htonl(x)\(__builtin_constant_p(x) ?\__bpf_constant_htonl(x) : __bpf_htonl(x))#define bpf_ntohl(x)\(__builtin_constant_p(x) ?\__bpf_constant_ntohl(x) : __bpf_ntohl(x))#endif /* __BPF_ENDIAN__ */[root@node20 tc-xdp]# cat headers/bpf_bpf_endian.h bpf_helpers.h[root@node20 tc-xdp]# cat headers/bpf_helpers.h/* SPDX-License-Identifier: GPL-2.0 *//* Copied from $(LINUX)/tools/testing/selftests/bpf/bpf_helpers.h */#ifndef __BPF_HELPERS_H#define __BPF_HELPERS_H/* helper macro to place programs, maps, license in* different sections in elf_bpf file. Section names* are interpreted by elf_bpf loader*/#define SEC(NAME) __attribute__((section(NAME), used))#ifndef __inline# define __inline \inline __attribute__((always_inline))#endif/* helper functions called from eBPF programs written in C */static void *(*bpf_map_lookup_elem)(void *map, void *key) =(void *) BPF_FUNC_map_lookup_elem;static int (*bpf_map_update_elem)(void *map, void *key, void *value,unsigned long long flags) =(void *) BPF_FUNC_map_update_elem;static int (*bpf_map_delete_elem)(void *map, void *key) =(void *) BPF_FUNC_map_delete_elem;static int (*bpf_probe_read)(void *dst, int size, void *unsafe_ptr) =(void *) BPF_FUNC_probe_read;static unsigned long long (*bpf_ktime_get_ns)(void) =(void *) BPF_FUNC_ktime_get_ns;static int (*bpf_trace_printk)(const char *fmt, int fmt_size, ...) =(void *) BPF_FUNC_trace_printk;static void (*bpf_tail_call)(void *ctx, void *map, int index) =(void *) BPF_FUNC_tail_call;static unsigned long long (*bpf_get_smp_processor_id)(void) =(void *) BPF_FUNC_get_smp_processor_id;static unsigned long long (*bpf_get_current_pid_tgid)(void) =(void *) BPF_FUNC_get_current_pid_tgid;static unsigned long long (*bpf_get_current_uid_gid)(void) =(void *) BPF_FUNC_get_current_uid_gid;static int (*bpf_get_current_comm)(void *buf, int buf_size) =(void *) BPF_FUNC_get_current_comm;static unsigned long long (*bpf_perf_event_read)(void *map,unsigned long long flags) =(void *) BPF_FUNC_perf_event_read;static int (*bpf_clone_redirect)(void *ctx, int ifindex, int flags) =(void *) BPF_FUNC_clone_redirect;static int (*bpf_redirect)(int ifindex, int flags) =(void *) BPF_FUNC_redirect;static int (*bpf_perf_event_output)(void *ctx, void *map,unsigned long long flags, void *data,int size) =(void *) BPF_FUNC_perf_event_output;static int (*bpf_get_stackid)(void *ctx, void *map, int flags) =(void *) BPF_FUNC_get_stackid;static int (*bpf_probe_write_user)(void *dst, void *src, int size) =(void *) BPF_FUNC_probe_write_user;static int (*bpf_current_task_under_cgroup)(void *map, int index) =(void *) BPF_FUNC_current_task_under_cgroup;static int (*bpf_skb_get_tunnel_key)(void *ctx, void *key, int size, int flags) =(void *) BPF_FUNC_skb_get_tunnel_key;static int (*bpf_skb_set_tunnel_key)(void *ctx, void *key, int size, int flags) =(void *) BPF_FUNC_skb_set_tunnel_key;static int (*bpf_skb_get_tunnel_opt)(void *ctx, void *md, int size) =(void *) BPF_FUNC_skb_get_tunnel_opt;static int (*bpf_skb_set_tunnel_opt)(void *ctx, void *md, int size) =(void *) BPF_FUNC_skb_set_tunnel_opt;static unsigned long long (*bpf_get_prandom_u32)(void) =(void *) BPF_FUNC_get_prandom_u32;static int (*bpf_xdp_adjust_head)(void *ctx, int offset) =(void *) BPF_FUNC_xdp_adjust_head;/* llvm builtin functions that eBPF C program may use to* emit BPF_LD_ABS and BPF_LD_IND instructions*/struct sk_buff;unsigned long long load_byte(void *skb,unsigned long long off) asm("llvm.bpf.load.byte");unsigned long long load_half(void *skb,unsigned long long off) asm("llvm.bpf.load.half");unsigned long long load_word(void *skb,unsigned long long off) asm("llvm.bpf.load.word");/* a helper structure used by eBPF C program* to describe map attributes to elf_bpf loader*/struct bpf_map_def {unsigned int type;unsigned int key_size;unsigned int value_size;unsigned int max_entries;unsigned int map_flags;unsigned int inner_map_idx;};static int (*bpf_skb_load_bytes)(void *ctx, int off, void *to, int len) =(void *) BPF_FUNC_skb_load_bytes;static int (*bpf_skb_store_bytes)(void *ctx, int off, void *from, int len, int flags) =(void *) BPF_FUNC_skb_store_bytes;static int (*bpf_l3_csum_replace)(void *ctx, int off, int from, int to, int flags) =(void *) BPF_FUNC_l3_csum_replace;static int (*bpf_l4_csum_replace)(void *ctx, int off, int from, int to, int flags) =(void *) BPF_FUNC_l4_csum_replace;static int (*bpf_skb_under_cgroup)(void *ctx, void *map, int index) =(void *) BPF_FUNC_skb_under_cgroup;static int (*bpf_skb_change_head)(void *, int len, int flags) =(void *) BPF_FUNC_skb_change_head;#if defined(__x86_64__)#define PT_REGS_PARM1(x) ((x)->di)#define PT_REGS_PARM2(x) ((x)->si)#define PT_REGS_PARM3(x) ((x)->dx)#define PT_REGS_PARM4(x) ((x)->cx)#define PT_REGS_PARM5(x) ((x)->r8)#define PT_REGS_RET(x) ((x)->sp)#define PT_REGS_FP(x) ((x)->bp)#define PT_REGS_RC(x) ((x)->ax)#define PT_REGS_SP(x) ((x)->sp)#define PT_REGS_IP(x) ((x)->ip)#elif defined(__s390x__)#define PT_REGS_PARM1(x) ((x)->gprs[2])#define PT_REGS_PARM2(x) ((x)->gprs[3])#define PT_REGS_PARM3(x) ((x)->gprs[4])#define PT_REGS_PARM4(x) ((x)->gprs[5])#define PT_REGS_PARM5(x) ((x)->gprs[6])#define PT_REGS_RET(x) ((x)->gprs[14])#define PT_REGS_FP(x) ((x)->gprs[11]) /* Works only with CONFIG_FRAME_POINTER */#define PT_REGS_RC(x) ((x)->gprs[2])#define PT_REGS_SP(x) ((x)->gprs[15])#define PT_REGS_IP(x) ((x)->psw.addr)#elif defined(__aarch64__)#define PT_REGS_PARM1(x) ((x)->regs[0])#define PT_REGS_PARM2(x) ((x)->regs[1])#define PT_REGS_PARM3(x) ((x)->regs[2])#define PT_REGS_PARM4(x) ((x)->regs[3])#define PT_REGS_PARM5(x) ((x)->regs[4])#define PT_REGS_RET(x) ((x)->regs[30])#define PT_REGS_FP(x) ((x)->regs[29]) /* Works only with CONFIG_FRAME_POINTER */#define PT_REGS_RC(x) ((x)->regs[0])#define PT_REGS_SP(x) ((x)->sp)#define PT_REGS_IP(x) ((x)->pc)#elif defined(__powerpc__)#define PT_REGS_PARM1(x) ((x)->gpr[3])#define PT_REGS_PARM2(x) ((x)->gpr[4])#define PT_REGS_PARM3(x) ((x)->gpr[5])#define PT_REGS_PARM4(x) ((x)->gpr[6])#define PT_REGS_PARM5(x) ((x)->gpr[7])#define PT_REGS_RC(x) ((x)->gpr[3])#define PT_REGS_SP(x) ((x)->sp)#define PT_REGS_IP(x) ((x)->nip)#elif defined(__sparc__)#define PT_REGS_PARM1(x) ((x)->u_regs[UREG_I0])#define PT_REGS_PARM2(x) ((x)->u_regs[UREG_I1])#define PT_REGS_PARM3(x) ((x)->u_regs[UREG_I2])#define PT_REGS_PARM4(x) ((x)->u_regs[UREG_I3])#define PT_REGS_PARM5(x) ((x)->u_regs[UREG_I4])#define PT_REGS_RET(x) ((x)->u_regs[UREG_I7])#define PT_REGS_RC(x) ((x)->u_regs[UREG_I0])#define PT_REGS_SP(x) ((x)->u_regs[UREG_FP])#if defined(__arch64__)#define PT_REGS_IP(x) ((x)->tpc)#else#define PT_REGS_IP(x) ((x)->pc)#endif#endif#ifdef __powerpc__#define BPF_KPROBE_READ_RET_IP(ip, ctx) ({ (ip) = (ctx)->link; })#define BPF_KRETPROBE_READ_RET_IP BPF_KPROBE_READ_RET_IP#elif defined(__sparc__)#define BPF_KPROBE_READ_RET_IP(ip, ctx) ({ (ip) = PT_REGS_RET(ctx); })#define BPF_KRETPROBE_READ_RET_IP BPF_KPROBE_READ_RET_IP#else#define BPF_KPROBE_READ_RET_IP(ip, ctx) ({ \bpf_probe_read(&(ip), sizeof(ip), (void *)PT_REGS_RET(ctx)); })#define BPF_KRETPROBE_READ_RET_IP(ip, ctx) ({ \bpf_probe_read(&(ip), sizeof(ip), \(void *)(PT_REGS_FP(ctx) + sizeof(ip))); })#endif#endif
编译代码
跟XDP程序一样,可以使用clang进行编译,不同之处是由于引用了本地头文件,所以需要加上-I参数,指定头文件所在目录:
clang -I ./headers/ -O2 -target bpf -c tc-ban-outside-network-vist-container-debug.c -o tc-ban-outside-network-vist-container-debug.o
加载BPF到TC egress上
BPF可以通过 tc 工具加载到TC上,上文提到的了TC控制的单元是qdisc,用来加载BPF程序是个特殊的qdisc 叫clsact,示例命令如下所示:
# 为目标网卡创建 clsact
tc qdisc add dev [network-device] clsact
# 加载bpf程序
tc filter add dev [network-device] <direction> bpf da obj [object-name] sec [section-name]
# 查看
tc filter show dev [network-device] <direction>
# 帮助
tc filter help
简单说明下:
- 示例中有个参数,它表示将bpf程序加载到哪条网络链路上,它的值可以是ingress和egress。
- 还有一个不起眼的参数da,它的全称是direct-action。查看帮助文档:
下面是实现TC BPF控制Egress的真真实命令: ```basicdirect-action | da instructs eBPF classifier to not invoke external TC actions, instead use the TC actions return codes (TC_ACT_OK, TC_ACT_SHOT etc.) for classifiers.为目标网卡创建 clsact
$ tc qdisc add dev vethf87805f clasact加载bpf程序到esgress
$ tc filter add dev vethf87805f egress bpf da obj tc-ban-outside-network-vist-container-debug.o sec to-container
查看结果
$ tc filter show dev vethf87805f egress filter protocol all pref 49152 bpf chain 0 filter protocol all pref 49152 bpf chain 0 handle 0x1 tc-ban-outside-network-vist-container-debug.o:[to-container] direct-action not_in_hw id 32 tag f1ca072d3dd58af4 jited
<a name="vZlLx"></a>
#### 测试效果
在主机上访问容器端口
加入TC esgress bpf前
```bash
$ curl 172.17.0.2
$ curl 127.0.0.1
# 都是可以正常返回
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
加入TC esgress bpf 后
$ curl 172.17.0.2
$ curl 127.0.0.1
# 都会卡住
在容器里面可以正常返回的
$ sudo docker run -it --rm busybox sh
$ container> wget 172.17.0.2
Connecting to 172.17.0.2 (172.17.0.2:80)
saving to 'index.html'
index.html 100% |*******************************************************************************************************************************************************************| 612 0:00:00 ETA
'index.html' saved
可以实现禁止容器外部环境访问,同时允许容器网段内部访问这个nginx-xdp端口
卸载TC上 egress BPF
$ tc filter del dev vethf87805f egress
TC 对容器访问外网进行过滤
容器接口对端 veth ingress 对应接收容器接口发送出来数据 from-containter ,可以对容器对外访问进行控制。可以尝试下面限制
- 容器tcp可以访问172.17.0.1/16 容器网段所有节点。
- 容器不允许通过tcp访问容器网段外网络。
- 外部访问可以运行访问容器端口。
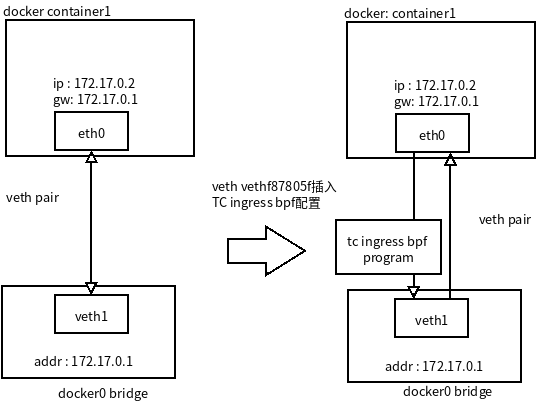
可能会有疑问,不允许容器访问外网,但是外网访问容器时候包怎么过去。外网访问容器时候是通过 docker0进行路由转发的:
$ ip route
...
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
...
所有外部网络访问容器网络时候src ip 172.17.0.1 (host机器网络需要通过docker0 网桥路由容器网络),返回时候dst ip 172.17.0.1 。如果容器直接访问,dst ip 就是外网ip地址, 同样可以判断dst ip 是否是容器网络可以了。代码tc-ban-container-visit-outsize-network-debug.c 如下:
#include <stdbool.h>
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
#include <stdio.h>
#include "bpf_endian.h"
#include "bpf_helpers.h"
typedef unsigned int u32;
#define bpfprint(fmt, ...) \
({ \
char ____fmt[] = fmt; \
bpf_trace_printk(____fmt, sizeof(____fmt), \
##__VA_ARGS__); \
})
/*
check whether the packet is of TCP protocol
*/
static __inline bool ban_container_visit_outsize_network(void *data_begin, void *data_end){
bpfprint("Entering ban_container_visit_outsize_network \n");
struct ethhdr *eth = data_begin;
// Check packet's size
// the pointer arithmetic is based on the size of data type, current_address plus int(1) means:
// new_address= current_address + size_of(data type)
if ((void *)(eth + 1) > data_end) //
return false;
// Check if Ethernet frame has IP packet
if (eth->h_proto == bpf_htons(ETH_P_IP))
{
struct iphdr *iph = (struct iphdr *)(eth + 1); // or (struct iphdr *)( ((void*)eth) + ETH_HLEN );
if ((void *)(iph + 1) > data_end)
return false;
// Check if IP packet contains a TCP segment
if (iph->protocol != IPPROTO_TCP)
return false;
// extract src ip and destination ip
u32 ip_src = iph->saddr;
u32 ip_dst = iph->daddr;
bpfprint("src ip addr1: %d.%d.%d\n",(ip_src) & 0xFF,(ip_src >> 8) & 0xFF,(ip_src >> 16) & 0xFF);
bpfprint("src ip addr2:.%d\n",(ip_src >> 24) & 0xFF);
bpfprint("dest ip addr1: %d.%d.%d\n",(ip_dst) & 0xFF,(ip_dst >> 8) & 0xFF,(ip_dst >> 16) & 0xFF);
bpfprint("dest ip addr2: .%d\n",(ip_dst >> 24) & 0xFF);
// net mask 255.255.255.0
u32 mask = bpf_htonl(0xffffff00);
// check dst if is container network
u32 dst_net_seg = ip_dst & mask;
// docker container network: 172.17.0.0
u32 container_net_seg = bpf_htonl(0xac110000);
// dst net segment is not in container network
if (dst_net_seg != container_net_seg) {
return true;
}
}
return false;
}
SEC("from-container")
int tc_to_container(struct __sk_buff *skb)
{
bpfprint("Entering from-container section\n");
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
if (ban_container_visit_outsize_network(data, data_end))
return TC_ACT_SHOT;
else
return TC_ACT_OK;
}
char _license[] SEC("license") = "GPL";
编译代码
$ clang -I ./headers/ -O2 -target bpf -c tc- -o tc-ban-outside-network-vist-container-debug.o
加载BPF到 TC ingress 上
这个把 BPF 加入到 tc ingress 链路上
# 为目标网卡创建 clsact [如果之前已经加入可以忽略这条命令]
$ tc qdisc add dev vethf87805f clasact
# 加载bpf程序到esgress
$ tc filter add dev vethf87805f egress bpf da obj tc-ban-outside-network-vist-container-debug.o sec to-container
# 查看结果
$ tc filter show dev vethf87805f egress
测试效果
xdp-nginx 容器访问外网服务
$ sudo docker exec -it nginx-xdp sh
container-nginx>$ curl baidu.com -vvv
* Trying 220.181.38.148:80...
* connect to 220.181.38.148 port 80 failed: Operation timed out
* Trying 39.156.69.79:80...
* After 83733ms connect time, move on!
* connect to 39.156.69.79 port 80 failed: Operation timed out
* Failed to connect to baidu.com port 80: Operation timed out
* Closing connection 0
curl: (28) Failed to connect to baidu.com port 80: Operation timed out
新启动nginx容器
$ sudo docker run -d --name nginx-test nginx:alpine
$ sudo docker exec -it nginx-test ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
14: eth0@if15: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
在容器里面访问nginx-test容器
container-nginx> / # curl 172.17.0.3
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
BPF 程序调试
BPF 程序通过ip工具/tc工具接入以后,都是在后台运行的,如果有bug,应用不符合要求时候怎么去调试。用gdb,这个内核无法跟踪,尝试通过打印日志方式看程序运行中间状态。下面介绍一下 bpf 怎么打印日志,日志输出到什么文件呢。
添加打印日志
在适当的位置添加printf函数,但由于这个函数需要在内核运行,而BPF中没有实现它,因此无法使用。事实上,BPF程序能的使用的C语言库数量有限,并且不支持调用外部库。
使用辅助函数(helper function)
为了克服这个限制,最常用的一种方法是定义和使用BPF辅助函数,即helper function。比如可以使用bpf_trace_printk()辅助函数,这个函数可以根据用户定义的输出,将BPF程序产生的对应日志消息保存在用来跟踪内核的文件夹(/sys/kernel/debug/tracing/),这样,我们就可以通过这些日志信息,分析和发现BPF程序执行过程中可能出现的错误。
下面代码封装打印函数代码
#include <stdbool.h>
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <linux/pkt_cls.h>
#include <stdio.h>
#include "bpf_endian.h"
#include "bpf_helpers.h"
typedef unsigned int u32;
#define bpfprint(fmt, ...) \
({ \
char ____fmt[] = fmt; \
bpf_trace_printk(____fmt, sizeof(____fmt), \
##__VA_ARGS__); \
})
查看调试信息
代码侧已经添加好日志打印函数,那如何观察到日志输出呢?上文提到了一个专门记录日志的文件夹,里面的文件就是保持不同trace日志的。我们的bpf程序日志可以通过读取这个文件/sys/kernel/debug/tracing/trace_pipe:
# 它是一个流,会不停读取信息
$ cat /sys/kernel/debug/tracing/trace_pipe
# 另一个种等价方式
$ tail -f /sys/kernel/debug/tracing/trace
参考
你的第一个TC BPF 程序:https://davidlovezoe.club/wordpress/archives/952
调试你的BPF程序: https://davidlovezoe.club/wordpress/archives/963

若有收获,就点个赞吧
0 人点赞
